
数据采集第二次作业
代码链接:第二次数据采集实践作业码云链接
1 作业1
1.1 作业要求
-
在中国气象网(http://www.weather.com.cn)给定城市集的7日天气预报,并保存在数据库。(本次作业爬取福州、泉州、漳州、厦门的天气预报)
-
输出信息:Gitee文件夹链接
1.2 作业1 Gitee文件夹链接
1.3 代码思路和关键代码展示
1.3.1 城市编码映射
- 定义了一个字典citycode,负责将城市名称映射到该城市在中国气象局网站上的编码。
# 城市编码映射
citycode = {"福州": "58847", "泉州": "59132", "厦门": "59134", "漳州": "59126"}
1.3.2 创建数据库
-
定义了create_db函数,该函数会创建一个名为weathers.db的SQLite数据库文件,并在其中创建一个名为weather的表,用于存储天气数据。
-
如果数据库文件已存在,则会先删除它。
def create_db():
# 数据库文件路径
db_path = 'weathers.db'
# 如果数据库文件已存在,删除它
if os.path.exists(db_path):
os.remove(db_path)
# 创建或连接到数据库
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 创建天气表格
cursor.execute('''
CREATE TABLE IF NOT EXISTS weather (
city TEXT,
date TEXT,
weather TEXT,
temp TEXT
)
''')
# 提交事务
conn.commit()
# 关闭数据库连接
conn.close()
1.3.3 爬取天气信息
-
定义了foreweather函数,该函数接受一个城市名称作为参数,然后根据城市编码构建URL,使用urllib.request模块发送HTTP请求获取网页内容。
-
由于网页可能使用GBK编码,所以使用UnicodeDammit尝试正确解码网页内容。
-
然后使用BeautifulSoup解析HTML,提取天气信息,并将其插入到数据库中。
with urllib.request.urlopen(req) as data:
dammit = UnicodeDammit(data.read(), ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("div[class^='pull-left day']")
for li in lis:
try:
date = re.sub(r'\s+', ' ', li.select("div [class='day-item']")[0].text).strip()
weather = li.select("div [class='day-item']")[1].text.strip()
tem = li.select("div [class='low']")[0].text.strip() + "/" \
+ li.select("div [class='high']")[0].text.strip()
# 插入数据到数据库
with sqlite3.connect('weathers.db') as conn:
cursor = conn.cursor()
cursor.execute('INSERT INTO weather (city, date, weather, temp) VALUES (?, ?, ?, ?)',
(city, date, weather, tem))
conn.commit()
except IndexError as e:
print(f"IndexError: {e}")
except Exception as err:
print(f"Error: {err}")
except Exception as err:
print(f"Error fetching weather for {city}: {err}")
1.4 结果展示
- 控制台输出:
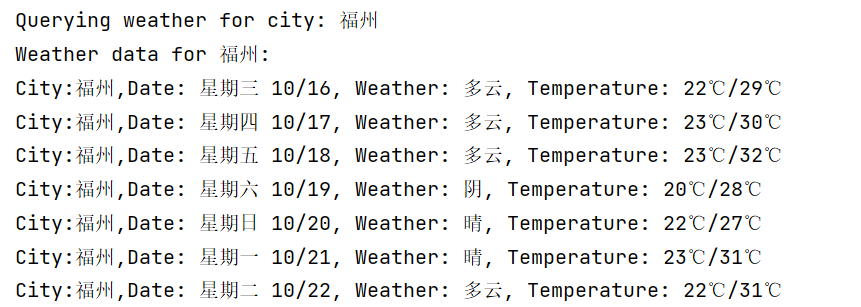
- 持久化存储:
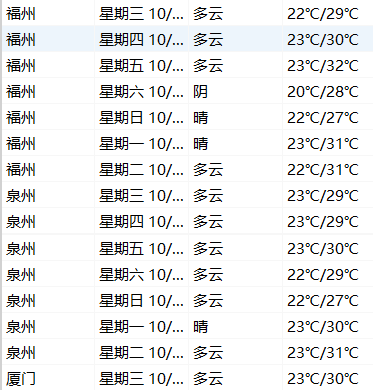
1.5 总结体会
-
编码处理:由于网页的编码可能不同,使用UnicodeDammit可以帮助我们正确解码网页内容,避免乱码问题。
-
数据库操作:通过sqlite3模块,我们可以方便地进行数据库的创建、数据的插入和查询等操作。这对于数据的持久化存储非常重要。
-
异常处理:在网络爬虫中,由于网络问题或数据问题,可能会出现各种异常。使用try-except块可以捕获并处理这些异常,提高程序的健壮性。
2 作业2
2.1 作业要求
-
用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
-
候选网站:东方财富网:https://www.eastmoney.com/,新浪股票:http://finance.sina.com.cn/stock/(本次作业爬取东方财富网)
-
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
-
输出信息:Gitee文件夹链接
2.2 作业2 Gitee文件夹链接
2.3 代码思路和关键代码展示
2.3.1 创建数据库
-
定义了create_db函数,该函数会创建一个名为stock_data.db的SQLite数据库文件,并在其中创建一个名为stocks的表,用于存储股票数据。
-
如果数据库文件已存在,则会先删除它。
def create_db():
# 数据库文件路径
db_path = 'stock_data.db'
# 如果数据库文件已存在,删除它
if os.path.exists(db_path):
os.remove(db_path)
# 创建或连接到数据库
conn = sqlite3.connect(db_path)
cursor = conn.cursor()
# 创建表格
cursor.execute(......)
# 提交事务,关闭数据库连接
conn.commit()
return conn
2.3.2 插入数据到数据库
- 定义了insert_data函数,该函数接受数据库连接对象conn和股票数据data作为参数,将股票数据插入到stocks表中。
# 插入数据到数据库
def insert_data(conn, data):
cursor = conn.cursor()
cursor.execute('''
INSERT INTO stocks (股票代码, 股票名称, 最新价, 涨跌幅, 涨跌额, 成交量, 成交额, 振幅, 换手率, 市盈率, 市净率, 最高, 最低, 今开, 昨收)
VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?, ?)
''', (
data['f12'], data['f14'], data['f2'], data['f3'], data['f4'], data['f5'], data['f6'],
data['f7'], data['f8'], data['f9'], data['f23'], data['f15'], data['f16'], data['f17'], data['f18']
))
conn.commit()
2.3.3 爬取页面
-
定义了fetch_data函数,该函数接受一个页码page作为参数,构建URL请求东方财富网站的股票数据。
-
使用requests模块发送HTTP请求获取网页内容。
-
由于网页内容是一个JSONP格式的响应(即在JSON数据前后包裹了函数调用),使用正则表达式提取出JSON数据,并使用json.loads解析JSON数据。
-
对比网页,查看参数信息
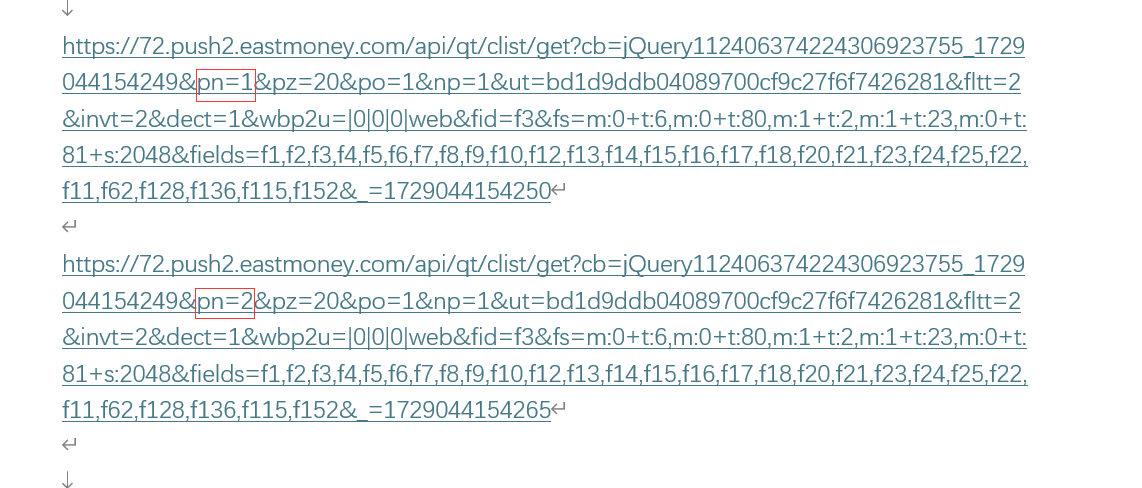
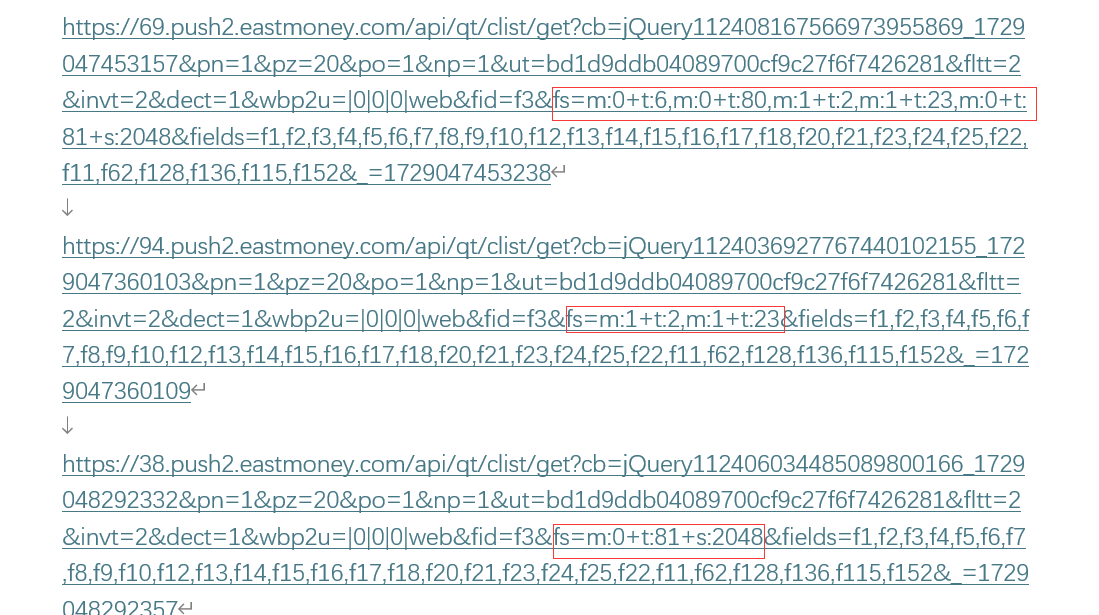
#爬取页面
def fetch_data(page):
url = f"https://6.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112403007640661422415_1728979782517&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728979782518"
# 使用requests获取网页内容
try:
response = requests.get(url)
response.raise_for_status() # 如果请求失败,将抛出异常
except requests.RequestException as e:
print(f"请求错误: {e}")
else:
# 使用正则表达式提取JSON数据
pattern = r'\((.*?)\)' # 匹配括号中的内容
match = re.search(pattern, response.text)
if match:
data = match.group(1) # 提取括号内的数据
json_data = json.loads(data) # 解析JSON数据
return json_data
2.4 结果展示
- 控制台输出:
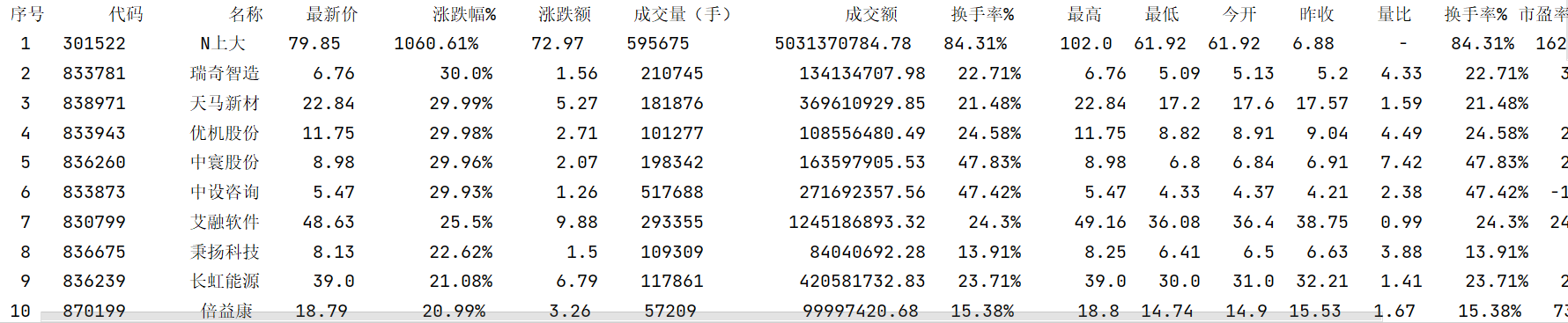
- 持久化存储:
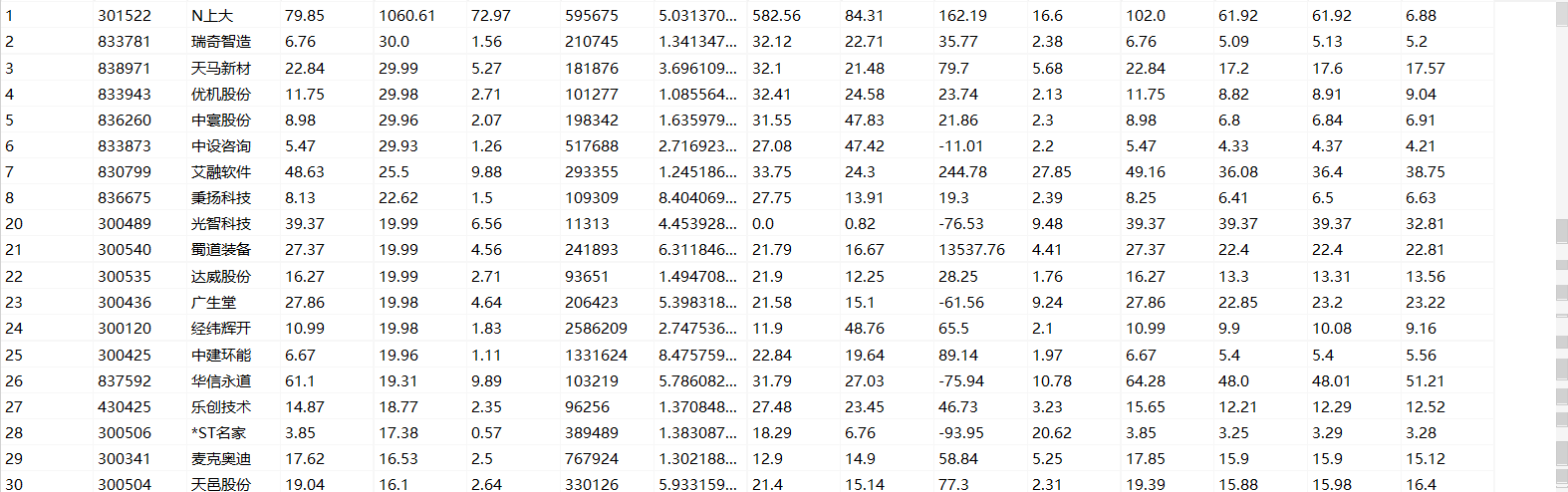
2.5 总结体会
-
数据解析:通过正则表达式从JSONP响应中提取JSON数据,并使用json.loads进行解析。
-
数据格式化输出:在display_data函数中,数据被格式化输出,使得打印结果更加清晰易读。
-代码的可配置性:通过main函数的参数pages,用户可以指定要爬取的页数,这提高了代码的灵活性。
-错误处理:在fetch_data函数中,如果请求失败或没有数据,程序会打印错误信息并继续执行。
3 作业3
3.1、作业要求
-
爬取中国大学2021主榜(https://www.shanghairanking.cn/rankings/bcur/2021) 所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
-
技巧:分析该网站的发包情况,分析获取数据的api
-
输出信息:Gitee文件夹链接
| 排名 | 学校 | 省市 | 类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 969.2 |
3.2 作业3 Gitee文件夹链接
3.3 浏览器F12调试分析的过程
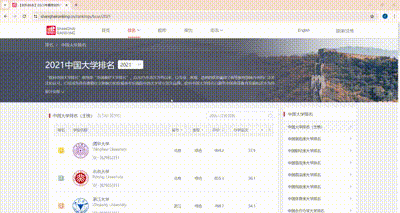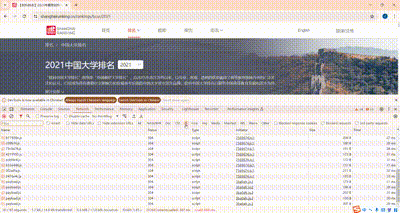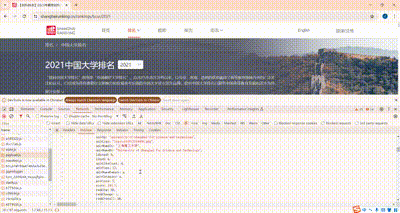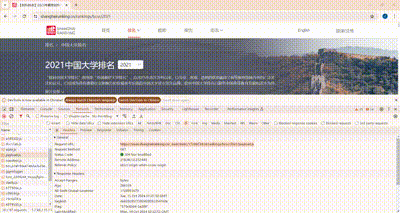
3.4 代码思路和关键代码展示
3.4.1 爬取数据
-
fetch_data函数负责发送HTTP请求到指定的URL,获取网页内容。
-
使用正则表达式从网页内容中提取排名、学校名称、省份、类型和分数等信息。
def fetch_data(url):
response = requests.get(url=url)
text = response.text
#爬取数据
rank = re.findall(',ranking:(.*?),',text) #排名
name = re.findall(',univNameCn:"(.*?)",', text) #学校名称
province = re.findall(',province:(.*?),', text) # 省市
category = re.findall(',univCategory:(.*?),', text) #学校类型
score = re.findall(',score:(.*?),', text) # 总分
3.4.2 数据处理
-
由于数据中可能包含编码,代码中还包含了一个映射字典code_tmp,用于将编码转换为可读的文本。
-
对于每个提取的数据项,如果分数(score)字段是编码的,则使用映射字典将其转换为浮点数。
# 变量字典映射
#将网页中的映射复制下来,方便映射
a = (......) #太长,博客上就不显示了
# b类字符带有多余空格,直接使用pycharm自带的整体替换,将“ ,”替换为”,“
b = '......' #太长,博客上就不显示了
c = b.split(',')
code_tmp = dict(zip(c,a))
for i in range(len(name)):
rank[i] = code_tmp[rank[i]]
province[i] = code_tmp[province[i]]
category[i] = code_tmp[category[i]]
#有部分score数据带有编码,有些没有
try:
score[i]=float(score[i])
except:
score[i]=float(code_tmp[score[i]])
3.4.3 打印并永久化存储
#打印数据并进行保存
with sqlite3.connect('universities_rank.db') as conn:
cursor = conn.cursor()
cursor.execute('INSERT INTO universities_rank (rank, name, province, category,score) VALUES (?, ?, ?, ?,?)',
(rank[i],name[i], province[i], category[i], score[i]))
conn.commit()
print(rank[i],name[i], province[i], category[i], score[i])
3.5 结果展示
- 控制台输出
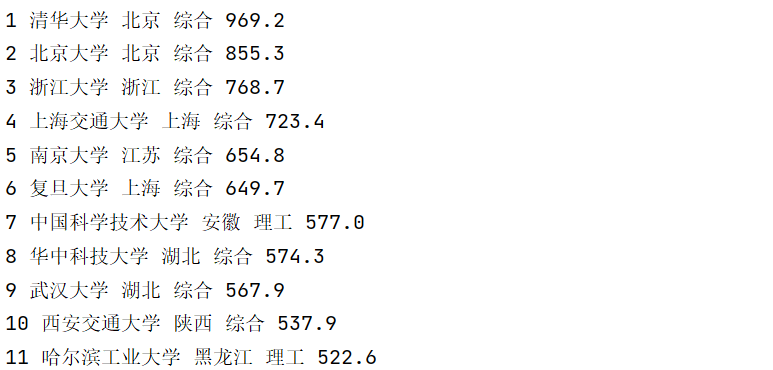
- 持久化存储
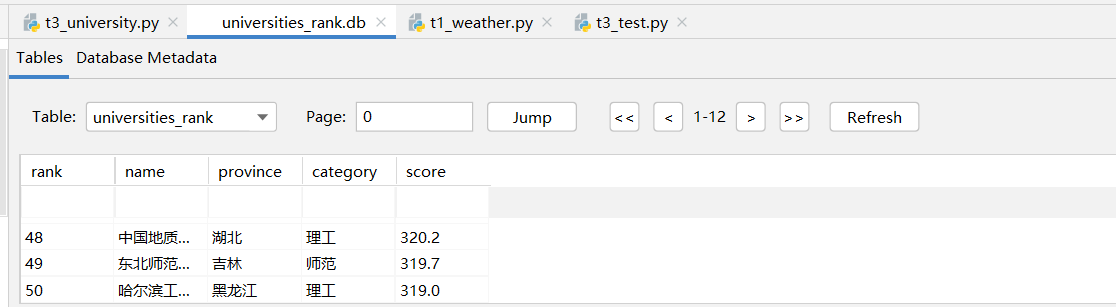
3.6 总结体会
-
API的基本概念:API(Application Programming Interface)是软件间相互通信的一套规则或协议。它允许不同的软件系统通过定义好的接口进行数据交换和功能调用。
-
理解API数据传输格式:常见的数据传输格式包括JSON和XML。JSON格式轻量级且易于解析,而XML则具有良好的扩展性和可读性。
-
数据清洗和转换:在提取数据后,代码对数据进行了清洗和转换,例如将编码转换为可读的文本,以及将分数转换为浮点数。
-
这显示了数据处理的重要性,因为从网页上爬取的数据往往需要进一步处理才能使用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号