
数据采集第一次作业
代码链接:第一次数据采集实践作业码云链接
1、作业1
1.1、作业要求
-
用requests和BeautifulSoup库方法定向爬取给定网址(http://www.shanghairanking.cn/rankings/bcur/2020) 的数据,屏幕打印爬取的大学排名信息。
-
输出信息:
| 排名 | 学校名称 | 省市 | 学校类型 | 总分 |
|---|---|---|---|---|
| 1 | 清华大学 | 北京 | 综合 | 852.5 |
| 2...... |
1.2、代码思路和关键代码展示
1.2.1、发送HTTP请求并考虑请求异常情况:
-
使用requests.get方法向目标网址发送GET请求。
-
response.raise_for_status():如果请求失败(如404或500错误),将抛出异常。
-
使用try-except结构捕获请求过程中可能出现的异常,并打印错误信息。
# 使用requests获取网页内容
try:
response = requests.get(url)
response.raise_for_status() # 如果请求失败,将抛出异常
# 使用“utf-8”编码,避免乱码
html_content = response.content.decode('utf-8')
except requests.RequestException as e:
print(f"请求错误: {e}")
1.2.2、解析网页内容并处理数据:
-
使用BeautifulSoup解析获取到的HTML内容。
-
使用find方法找到包含排名信息的表格。
-
遍历表格的每一行(跳过标题行),提取每行的数据,包括排名、学校名称、省市、学校类型和总分。
-
由于学校名称可能包含其他信息,代码中使用get_text方法和split函数来提取学校名称的第一部分。
for row in table.find_all("tr")[1:]: # 跳过标题行
# 提取每行的数据
cols = row.find_all("td")
rank = cols[0].text.strip()
# 学校名称只要前面的XX大学,学校名称
school_name = cols[1].get_text(separator=" ", strip=True).split(" ")
school_name = school_name[0]
province = cols[2].text.strip() #省份
school_type = cols[3].text.strip() #学校类型
total_score = cols[4].text.strip() #总分
1.2.3、数据持久化存储:将数据写入CSV文件并打印在控制台:
- 打开一个CSV文件,并使用csv.writer写入标题行和数据行。
- 每提取一行数据,就将其写入CSV文件。
- 在控制台打印提取的信息,使用格式化字符串进行对齐。
with open('university_rankings.csv', 'w', newline='', encoding='utf-8-sig') as file:
writer = csv.writer(file)
# 写入标题行
writer.writerow(['排名', '学校名称', '省市', '学校类型', '总分'])
# 写入数据行
writer.writerow([rank, school_name, province, school_type, total_score])
# 打印提取的信息,使用格式化字符串进行对齐
print(f"{rank:<5} {school_name:<15} {province:<5} {school_type:<10} {total_score:<10}")
1.3、结果展示
- 控制台输出
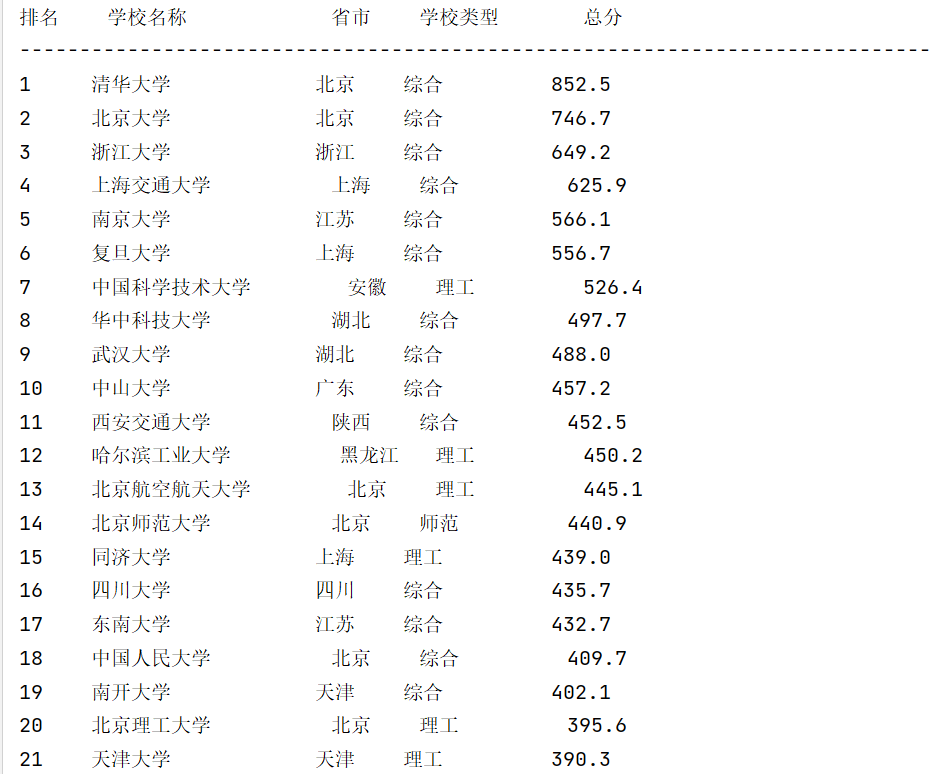
- 持久化存储
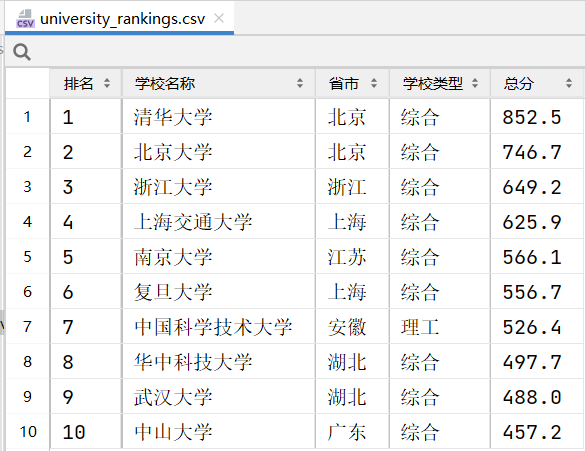
1.4、总结体会
-
从网页上抓取的数据可能包含额外的空格、换行符或其他不需要的字符,这就需要进行数据清洗以确保数据的整洁性。通过使用函数text.strip()来删除不必要的空格。
-
在爬取学校名称的时候,遇到了冗余信息如:学校英文名和985211等信息,发现所需要爬取的信息都位于空格前的首位,通过split进行获取第一个信息。
-
最后将结果保存到.csv文件中,实现持久化存储。
2、作业2
2.1、作业要求
-
用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
-
输出信息:
| 序号 | 价格 | 商品名 |
|---|---|---|
| 1 | 65.00 | xxx |
| 2...... |
2.2、代码思路和关键代码展示
2.2.1、定义crawl_page函数
-
这个函数用于爬取单个页面的商品信息。
-
使用time.sleep添加随机等待时间,以模拟正常用户行为。
-
构造完整的URL,并发送GET请求,如果请求失败或发生异常,则打印错误信息。。
-
如果请求成功(状态码200),则使用正则表达式提取商品名称和价格。
-
使用csv.writer将提取的信息写入CSV文件,并使用锁lock确保线程安全。
# 锁对象,用于在写入CSV文件时避免冲突
lock = threading.Lock()
def crawl_page(page, start_url, headers, csv_file):
"""
爬取单个页面的商品信息并保存到CSV文件中
"""
time.sleep(random.randint(2, 4)) # 随机等待时间,模拟正常用户行为
url = f"{start_url}{page}"
try:
response = requests.get(url=url, headers=headers)
if response.status_code == 200:
text = response.text
# 正则表达式模式
pattern1 = r"alt='([^']*)'" #商品名称
pattern2 = r"¥(\d+\.\d{2})" #商品价格
# 使用正则表达式搜索
matches1 = re.findall(pattern1, text)
matches2 = re.findall(pattern2, text)
2.2.2、定义main函数
-
这个函数是主程序,用于使用多线程爬取多个页面。
-
定义请求头headers,包括用户代理和Cookie。
-
检查CSV文件是否存在,如果不存在则创建文件并写入标题行。
-
循环创建线程,每个线程负责爬取一个页面的商品信息。
-
使用thread.start()启动线程,并将线程对象添加到线程列表中。
-
使用thread.join()等待所有线程完成
def main(start_url, start_page, end_page, csv_file):
"""
主程序,使用多线程爬取多个页面
"""
headers = {}
# 确保CSV文件存在
if not os.path.exists(csv_file):
with open(csv_file, 'w', newline='', encoding='utf-8-sig') as file:
writer = csv.writer(file)
writer.writerow(['序号', '商品名称', '价格'])
threads = []
for page in range(start_page, end_page + 1):
thread = threading.Thread(target=crawl_page, args=(page, start_url, headers, csv_file))
thread.start()
threads.append(thread)
for thread in threads:
thread.join()
2.3、结果展示
-
控制台输出:

-
持久化存储:

2.4、总结体会
-
模拟正常用户行为:通过在请求间添加随机等待时间,可以模拟正常用户的浏览行为,减少被服务器识别为爬虫的风险。
-
用户代理和Cookie:在请求头中设置用户代理和Cookie可以模拟特定浏览器的请求,对于访问某些需要具有反爬机制的页面是必要的。
-
多线程提高效率:通过使用threading库,程序能够同时发送多个HTTP请求,显著提高了爬取数据的效率。这对于需要爬取大量页面的情况特别有用。
-
线程安全:在多线程环境中写入文件时,使用锁(threading.Lock)来确保线程安全,避免数据写入时的冲突。
3、作业3
3.1、作业要求
-
爬取一个给定网页( https://news.fzu.edu.cn/yxfd.htm)或者自选网页的所有JPEG和JPG格式文件
-
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
3.2、代码思路和关键代码展示
3.2.1、解析网页内容:
-
使用BeautifulSoup解析获取到的HTML内容。
-
使用re.compile定义一个正则表达式,用于匹配JPEG和JPG图片的URL
if response.status_code == 200:
# 解析网页内容
soup = BeautifulSoup(response.text, 'html.parser')
# 创建一个目录来保存图片
image_folder = 'fzu_images'
if not os.path.exists(image_folder):
os.makedirs(image_folder)
# 正则表达式,匹配JPEG和JPG图片
image_pattern = re.compile(r'.*\.(jpg|jpeg)$')
3.2.2、遍历并下载图片:
-
使用soup.find_all('img')找到网页中所有的
标签。
-
对于每个
标签,获取其src属性,即图片的URL。
-
使用正则表达式检查URL是否以.jpg或.jpeg结尾,以确保只下载JPEG和JPG格式的图片。
-
根据图片URL的前缀(如//、/),构建完整的图片URL。
-
发送GET请求下载图片,并使用os.path.basename提取图片文件名。
-
将图片内容写入文件,保存到之前创建的目录中。
# 遍历网页中所有的<img>标签
for img_tag in soup.find_all('img'):
img_url = img_tag.get('src')
# 使用正则表达式检查图片格式
if img_url and image_pattern.search(img_url):
# 尝试构建完整的图片URL
if img_url.startswith('//'):
full_img_url = 'https:' + img_url
elif img_url.startswith('/'):
full_img_url = 'https://news.fzu.edu.cn' + img_url
else:
full_img_url = img_url # 已经是完整的URL
# 获取图片内容
try:
img_response = requests.get(url=full_img_url,headers=headers)
img_response.raise_for_status() # 确保请求成功
# 提取图片文件名
img_filename = os.path.join(image_folder, os.path.basename(img_url))
# 保存图片
with open(img_filename, 'wb') as f:
f.write(img_response.content)
print(f'图片已保存:{img_filename}')
except requests.exceptions.RequestException as e:
print(f"无法下载图片:{full_img_url},错误:{e}")
3.3、结果展示
- 控制台输出
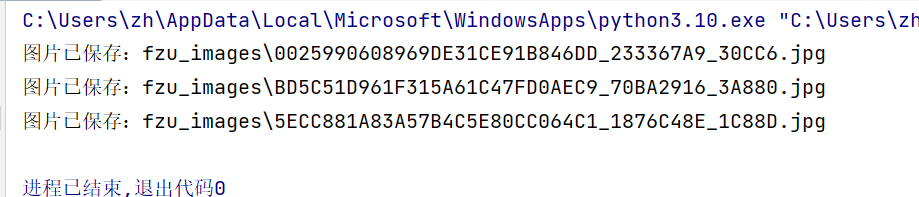
- 持久化存储

3.4、总结体会
-
此次爬取的图片只有3张,于是特意看了一下页面原数据,发现其他大部分图片后缀为.png,不过作业要求为爬取jpg和jpeg的图片,所以就没有对代码做进一步修改。
-
通过正则表达式匹配,可以筛选出特定格式的图片链接,实现对网页中图片的选择性下载。
-
os库提供了丰富的方法来操作文件系统,如创建目录、获取文件路径等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号