

Apache Flink - 常见数据流类型
DataStream:
DataStream是 Flink 流处理 API 中最核心的数据结构。它代表了一个运行在多个分区上的并行流。一个DataStream可以从StreamExecutionEnvironment通过env.addSource(SourceFunction)获得。- DataStream 上的转换操作都是逐条的,比如
map(),flatMap(),filter()。DataStream 也可以执行rebalance(再平衡,用来减轻数据倾斜)和broadcaseted(广播)等分区转换。 如上图的执行图所示,DataStream 各个算子会并行运行,算子之间是数据流分区。如 Source 的第一个并行实例(S1)和 flatMap() 的第一个并行实例(m1)之间就是一个数据流分区。而在 flatMap() 和 map() 之间由于加了 rebalance(),它们之间的数据流分区就有3个子分区(m1的数据流向3个map()实例)。
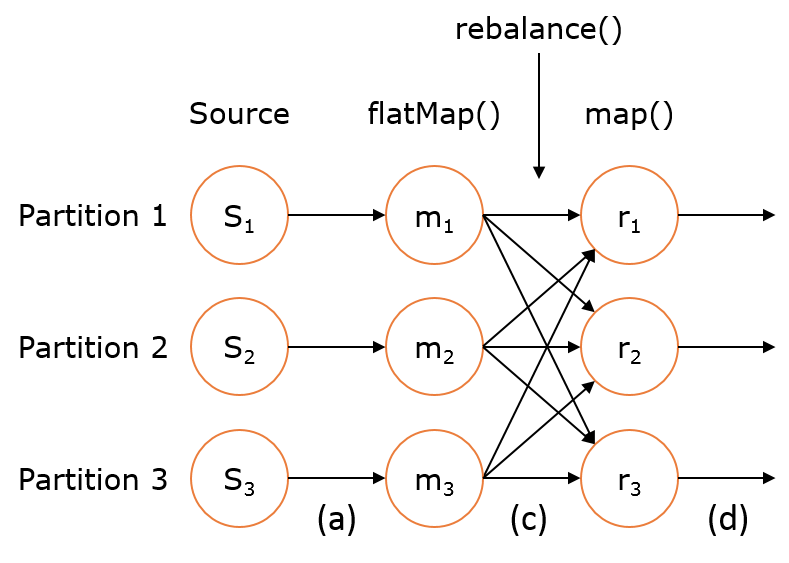 如上图的执行图所示,DataStream 各个算子会并行运行,算子之间是数据流分区。如 Source 的第一个并行实例(S1)和 flatMap() 的第一个并行实例(m1)之间就是一个数据流分区。而在 flatMap() 和 map() 之间由于加了 rebalance(),它们之间的数据流分区就有3个子分区(m1的数据流向3个map()实例)。
如上图的执行图所示,DataStream 各个算子会并行运行,算子之间是数据流分区。如 Source 的第一个并行实例(S1)和 flatMap() 的第一个并行实例(m1)之间就是一个数据流分区。而在 flatMap() 和 map() 之间由于加了 rebalance(),它们之间的数据流分区就有3个子分区(m1的数据流向3个map()实例)。KeyedStream:
KeyedStream用来表示根据指定的key进行分组的数据流。KeyedStream可以通过调用DataStream.keyBy()来获得。而在KeyedStream上进行任何transformation都将转变回DataStream。在实现中,KeyedStream是把key的信息写入到了transformation中。每条记录只能访问所属key的状态,其上的聚合函数可以方便地操作和保存对应key的状态。
WindowedStream & AllWindowedStream:
WindowedStream代表了根据key分组,并且基于WindowAssigner切分窗口的数据流。所以WindowedStream都是从KeyedStream衍生而来的。而在WindowedStream上进行任何transformation也都将转变回DataStream。DataStream[MyType] stream = ... WindowedDataStream[MyType] windowed = stream .keyBy("userId") .window(TumblingEventTimeWindows.of(Time.seconds(5))) // Last 5 seconds of data DataStream[ResultType] result = windowed.reduce(myReducer)
Flink 的窗口实现中会将到达的数据缓存在对应的窗口buffer中(一个数据可能会对应多个窗口)。当到达窗口发送的条件时(由Trigger控制),Flink 会对整个窗口中的数据进行处理。Flink 在聚合类窗口有一定的优化,即不会保存窗口中的所有值,而是每到一个元素执行一次聚合函数,最终只保存一份数据即可。
- 在key分组的流上进行窗口切分是比较常用的场景,也能够很好地并行化(不同的key上的窗口聚合可以分配到不同的task去处理)。不过当我们需要在普通流上进行窗口操作时,就要用到
AllWindowedStream。AllWindowedStream是直接在DataStream上进行windowAll(...)操作。AllWindowedStream 的实现是基于 WindowedStream 的。Flink 不推荐使用AllWindowedStream,因为在普通流上进行窗口操作,就势必需要将所有分区的流都汇集到单个的Task中,而这个单个的Task很显然就会成为整个Job的瓶颈。
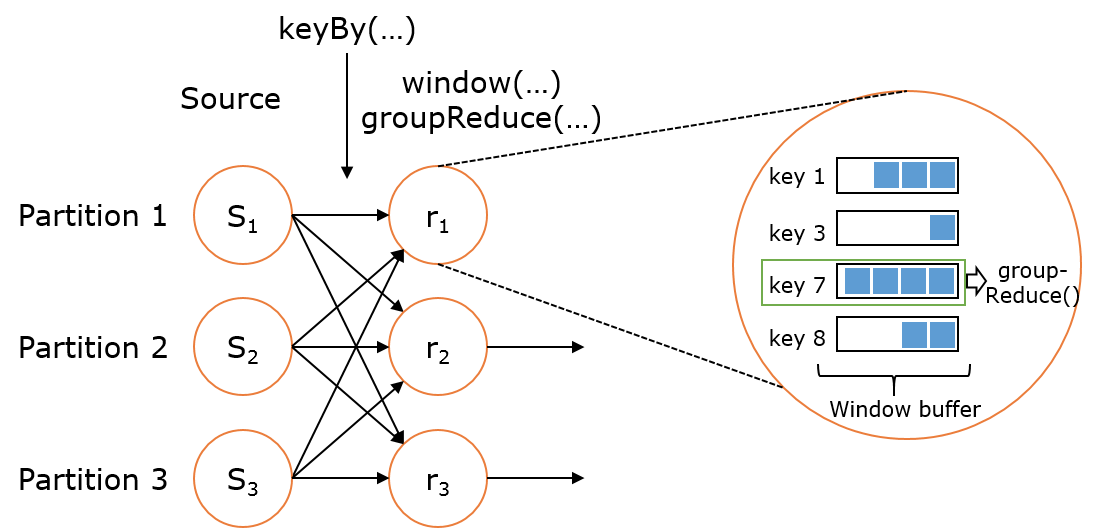 Flink 的窗口实现中会将到达的数据缓存在对应的窗口buffer中(一个数据可能会对应多个窗口)。当到达窗口发送的条件时(由Trigger控制),Flink 会对整个窗口中的数据进行处理。Flink 在聚合类窗口有一定的优化,即不会保存窗口中的所有值,而是每到一个元素执行一次聚合函数,最终只保存一份数据即可。
Flink 的窗口实现中会将到达的数据缓存在对应的窗口buffer中(一个数据可能会对应多个窗口)。当到达窗口发送的条件时(由Trigger控制),Flink 会对整个窗口中的数据进行处理。Flink 在聚合类窗口有一定的优化,即不会保存窗口中的所有值,而是每到一个元素执行一次聚合函数,最终只保存一份数据即可。JoinedStreams & CoGroupedStreams:
- co-group 侧重的是group,是对同一个key上的两组集合进行操作,而 join 侧重的是pair,是对同一个key上的每对元素进行操作, join 只是 co-group 的一个特例。
- JoinedStreams 和 CoGroupedStreams 是基于 Window 上实现的,所以 CoGroupedStreams 最终又调用了 WindowedStream 来实现。
DataStream[MyType] firstInput = ... DataStream[AnotherType] secondInput = ... DataStream[(MyType, AnotherType)] result = firstInput.join(secondInput) .where("userId").equalTo("id") .window(TumblingEventTimeWindows.of(Time.seconds(3))) .apply (new JoinFunction () {...})
双流上的数据在同一个key的会被分别分配到同一个window窗口的左右两个篮子里,当window结束的时候,会对左右篮子进行笛卡尔积从而得到每一对pair,对每一对pair应用 JoinFunction。
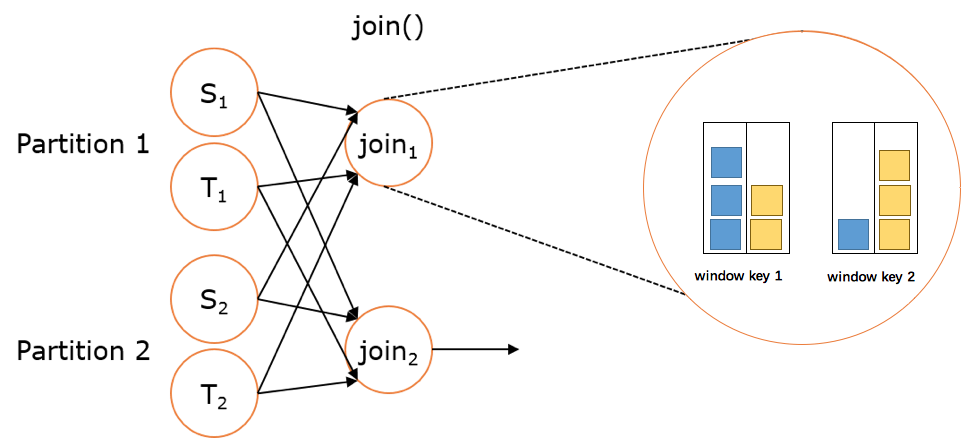 双流上的数据在同一个key的会被分别分配到同一个window窗口的左右两个篮子里,当window结束的时候,会对左右篮子进行笛卡尔积从而得到每一对pair,对每一对pair应用 JoinFunction。
双流上的数据在同一个key的会被分别分配到同一个window窗口的左右两个篮子里,当window结束的时候,会对左右篮子进行笛卡尔积从而得到每一对pair,对每一对pair应用 JoinFunction。ConnectedStreams:
- 在 DataStream 上有一个 union 的转换
dataStream.union(otherStream1, otherStream2, ...),用来合并多个流,新的流会包含所有流中的数据。union 有一个限制,就是所有合并的流的类型必须是一致的。 - union 有一个限制,就是所有合并的流的类型必须是一致的。
ConnectedStreams提供了和 union 类似的功能,用来连接两个流,但是与 union 转换有以下几个区别:- ConnectedStreams 只能连接两个流,而 union 可以连接多个流。
- ConnectedStreams 连接的两个流类型可以不一致,而 union 连接的流的类型必须一致。
- ConnectedStreams 会对两个流的数据应用不同的处理方法,并且双流之间可以共享状态。这在第一个流的输入会影响第二个流时, 会非常有用。
- 如下 ConnectedStreams 的样例,连接
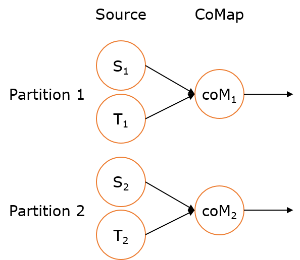
input和other流,并在input流上应用map1方法,在other上应用map2方法,双流可以共享状态(比如计数)。DataStream[MyType] input = ... DataStream[AnotherType] other = ... ConnectedStreams[MyType, AnotherType] connected = input.connect(other) DataStream[ResultType] result = connected.map(new CoMapFunction[MyType, AnotherType, ResultType]() { override def map1(value: MyType): ResultType = { ... } override def map2(value: AnotherType): ResultType = { ... } })
当并行度为2时:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号