
Apache Flink - 作业和调度
Scheduling:
- Flink中的执行资源通过任务槽(Task Slots)定义。每个TaskManager都有一个或多个任务槽,每个槽都可以运行一个并行任务管道(pipeline)。管道由多个连续的任务组成,例如第n个MapFunction并行实例和第n个ReduceFunction并行实例。Flink经常并发地执行连续的任务:对于流程序,这在任何情况下都会发生,对于批处理程序,它也经常发生。
- 下图说明了这一点。考虑一个具有数据源、MapFunction和ReduceFunction的程序。数据源和MapFunction的并行度为4,而ReduceFunction的并行度为3。一个管道由Source-Map-Reduce序列组成。在一个具有2个TaskManager(每个TaskManager都有3个插槽)的集群中,程序将按照如下所述执行。
![]()
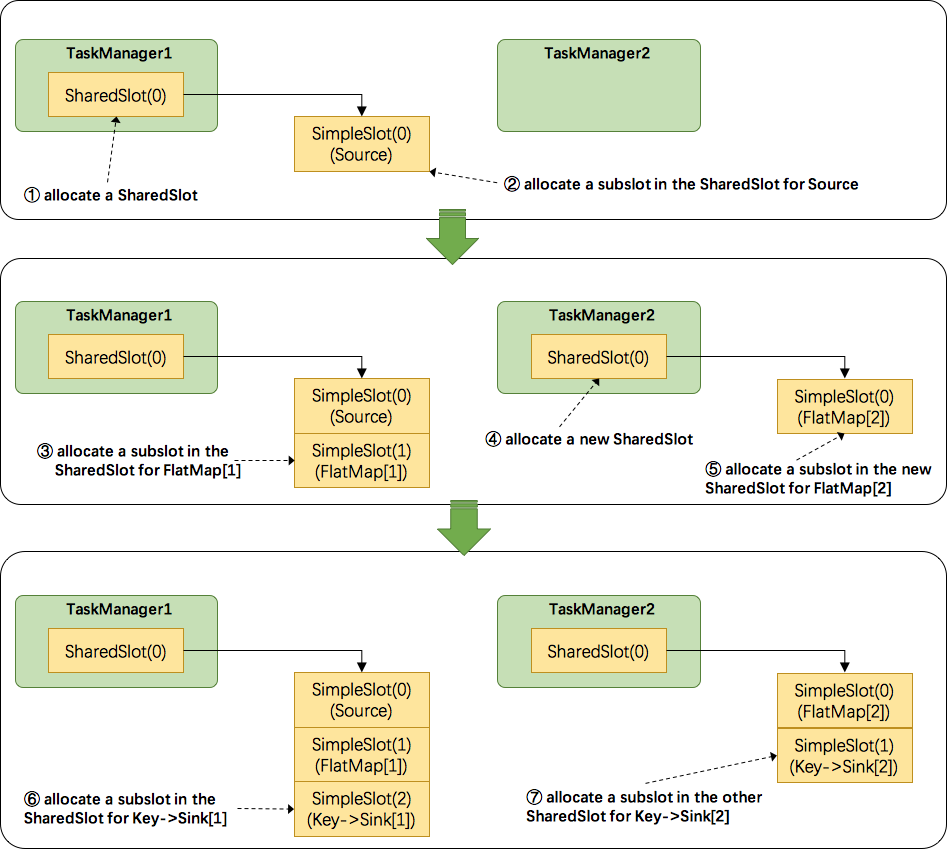
- 关于Flink调度,有两个非常重要的原则:1.同一个operator的各个subtask是不能呆在同一个SharedSlot中的,例如
FlatMap[1]和FlatMap[2]是不能在同一个SharedSlot中的。2.Flink是按照拓扑顺序从Source一个个调度到Sink的。例如WordCount(Source并行度为1,其他并行度为2),那么调度的顺序依次是:Source->FlatMap[1]->FlatMap[2]->KeyAgg->Sink[1]->KeyAgg->Sink[2]。假设现在有2个TaskManager,每个只有1个slot,那么分配slot的过程如图所示:- 为
Source分配slot。首先,我们从TaskManager1中分配出一个SharedSlot。并从SharedSlot中为Source分配出一个SimpleSlot。如上图中的①和②。 - 为
FlatMap[1]分配slot。目前已经有一个SharedSlot,则从该SharedSlot中分配出一个SimpleSlot用来部署FlatMap[1]。如上图中的③。 - 为
FlatMap[2]分配slot。由于TaskManager1的SharedSlot中已经有同operator的FlatMap[1]了,我们只能分配到其他SharedSlot中去。从TaskManager2中分配出一个SharedSlot,并从该SharedSlot中为FlatMap[2]分配出一个SimpleSlot。如上图的④和⑤。 - 为
Key->Sink[1]分配slot。目前两个SharedSlot都符合条件,从TaskManager1的SharedSlot中分配出一个SimpleSlot用来部署Key->Sink[1]。如上图中的⑥。 - 为
Key->Sink[2]分配slot。TaskManager1的SharedSlot中已经有同operator的Key->Sink[1]了,则只能选择另一个SharedSlot中分配出一个SimpleSlot用来部署Key->Sink[2]。如上图中的⑦。
最后
Source、FlatMap[1]、Key->Sink[1]这些subtask都会部署到TaskManager1的唯一个slot中,并启动对应的线程。FlatMap[2]、Key->Sink[2]这些subtask都会被部署到TaskManager2的唯一个slot中,并启动对应的线程。从而实现了slot共享。 - 为
- 最简单的情况下,一个slot只持有一个task,也就是
SimpleSlot的实现。复杂点的情况,一个slot能共享给多个task使用,也就是SharedSlot的实现。SharedSlot能包含其他的SharedSlot,也能包含SimpleSlot。所以一个SharedSlot能定义出一棵slots树。

JobManager 数据结构:
- 在job执行期间,JobManager跟踪分布式任务,决定何时调度下一个任务(或一组任务),并对完成的任务或执行失败作出反应。
- JobManager接收JobGraph,这是由运算符(JobVertex)和中间结果(IntermediateDataSet)组成的数据流的表示。每个运算符都有属性,比如并行性和它执行的代码。此外,JobGraph有一组附加的库,这些库是执行操作符代码所必需的。
- JobManager 将 JobGraph 转换为 ExecutionGraph。ExecutionGraph 是 JobGraph 的并行版本:对于每个 JobVertex,它包含每个并行子任务的 ExecutionVertex。并行度为100的运算符将有一个 JobVertex 和100个 ExecutionVertex。ExecutionVertex 跟踪特定子任务的执行状态。一个 JobVertex 中的所有 ExecutionVertex 都保存在 ExecutionJobVertex 中,它会跟踪操作符的整体状态。除顶点外,执行图还包含 IntermediateResult 和 IntermediateResultPartition。
![]() 每个ExecutionGraph都有一个与之相关联的job状态。这个job状态指示当前工作的执行状态。
每个ExecutionGraph都有一个与之相关联的job状态。这个job状态指示当前工作的执行状态。 - Flink job首先处于创建(created)状态,然后切换到运行(running)状态,完成所有工作后切换到已完成(finished)状态。在出现故障的情况下,job首先切换到故障(failing)状态,取消所有正在运行的任务。如果所有job顶点都已达到最终状态,且job不可重新启动,则job转换为失败。如果job可以重新启动,那么它将进入重新启动状态。一旦任务完全重新启动,它将到达创建状态。如果用户取消job,它将进入取消(cancelling)状态。这还需要取消所有当前正在运行的任务。一旦所有运行的任务都达到了最终状态,任务转换到该状态就会被取消。
- 与表示全局终端状态并触发清理作业的已完成、已取消和已失败状态不同,暂停(suspended)状态仅是本地终端。本地终端意味着job的执行已经在相应的JobManager上终止,但是Flink集群的另一个JobManager可以从持久的HA存储中检索这个job并重新启动它。因此,达到暂停状态的作业不会被完全清理。
![]()
- 在执行ExecutionGraph过程中,每个并行任务都经历多个阶段,从创建到完成或失败。下面的图表说明了它们之间的状态和可能的转换。一个任务可以多次执行(例如在故障恢复过程中)。由于这个原因,ExecutionVertex的执行被跟踪。每个ExecutionVertex都有当前的执行,以及先前的执行。
![]()
 每个ExecutionGraph都有一个与之相关联的job状态。这个job状态指示当前工作的执行状态。
每个ExecutionGraph都有一个与之相关联的job状态。这个job状态指示当前工作的执行状态。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号