UnitOneSummary
UnitOneSummary
目录
- 一、程序结构分析
- 第一次作业
- 第二次作业
- 第三次作业
- 二、Bug分析
- 三、测试
- 四、对象创建模式
- 五、对比和心得体会
一、程序结构分析
第一次作业
思路:
第一次作业较为简单。由于只涉及到幂函数求导,所以我只抽象除了多项式和单项式两个类。输入的处理是直接用正则匹配。求导的时候根据求导规则对幂函数的指数和系数进行运算。单项式们的存储方式是HashMap,以指数为key值,单项式类为value。边分析多项式边求导,求导后存入HashMap时合并key值相同的单项式。
优化:
- 1.去零项:在输出时遇到系数为0的项不输出。
- 2.正项前置:根据系数对各个单项式进行从大到小的排序,在有正项的情况下将正项放在最前面,可节约一个正号。
UML
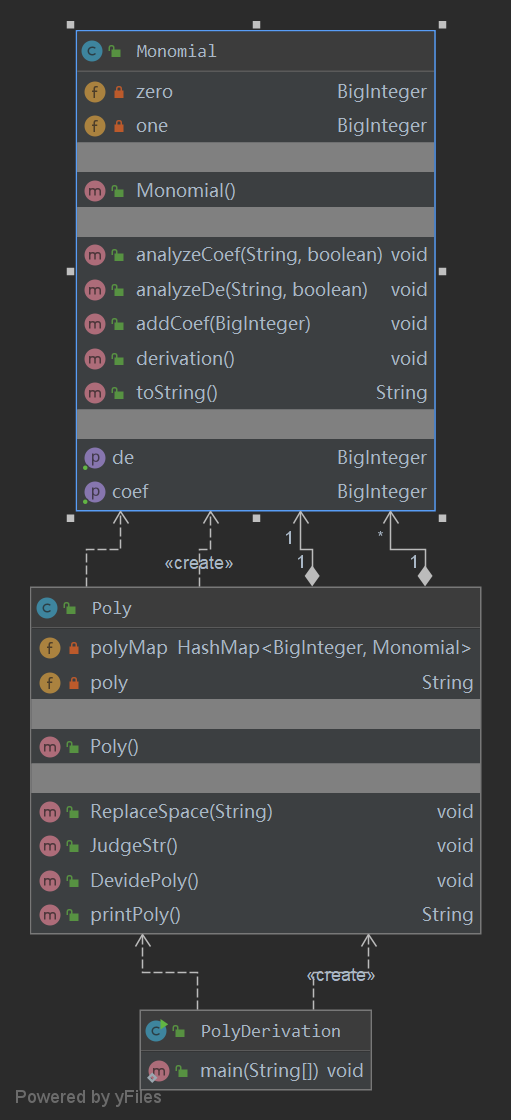
度量分析
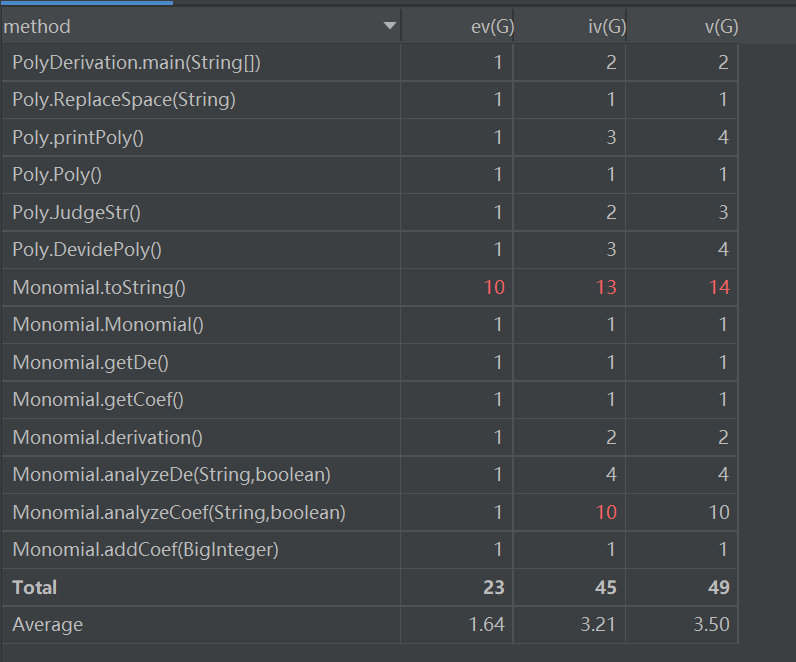

可以明显的看出Monomial的tostring复杂度极高,追本溯源是因为我在里面用了多层且多个if-else语句,仔细想想,其实有些是可以合并的,但当时就脑子想到哪就写到哪,这是十分不应该的。
优点
- 结构较为清晰
- 优化到位
缺点
- 没有单写一个类进行输入字符串处理
- 将求导与单项式写在一起,一点也不面向对象
- 单项式的toString结构过于复杂
第二次作业
思路:
第二次作业主要考察简单幂函数和正余弦函数的求导。我的基本做法是先对输入字符串进行预处理,去掉空格。然后根据正则表达式匹配出项,再把因子从项中分出来。创建了一个Func的接口,有四个类:sin、cos、pow和constant继承这个接口。应用工厂模式创建基本因子对象。
在求导的时候,我偷了懒,由于每个项都可以被总结为ax**b*sin(x)**c*cos(x)**d这种形式,因而我的求导方法有些面向过程,直接根据这种形式求的导。这也导致了在第三次作业中求导部分面临了大量的重构。
优化:
本次作业在优化上,除了沿用第一次作业的去除零项和正项前置外,我还应用了sin(x)**2+cos(x)**2=1这个公式来化简。
UML
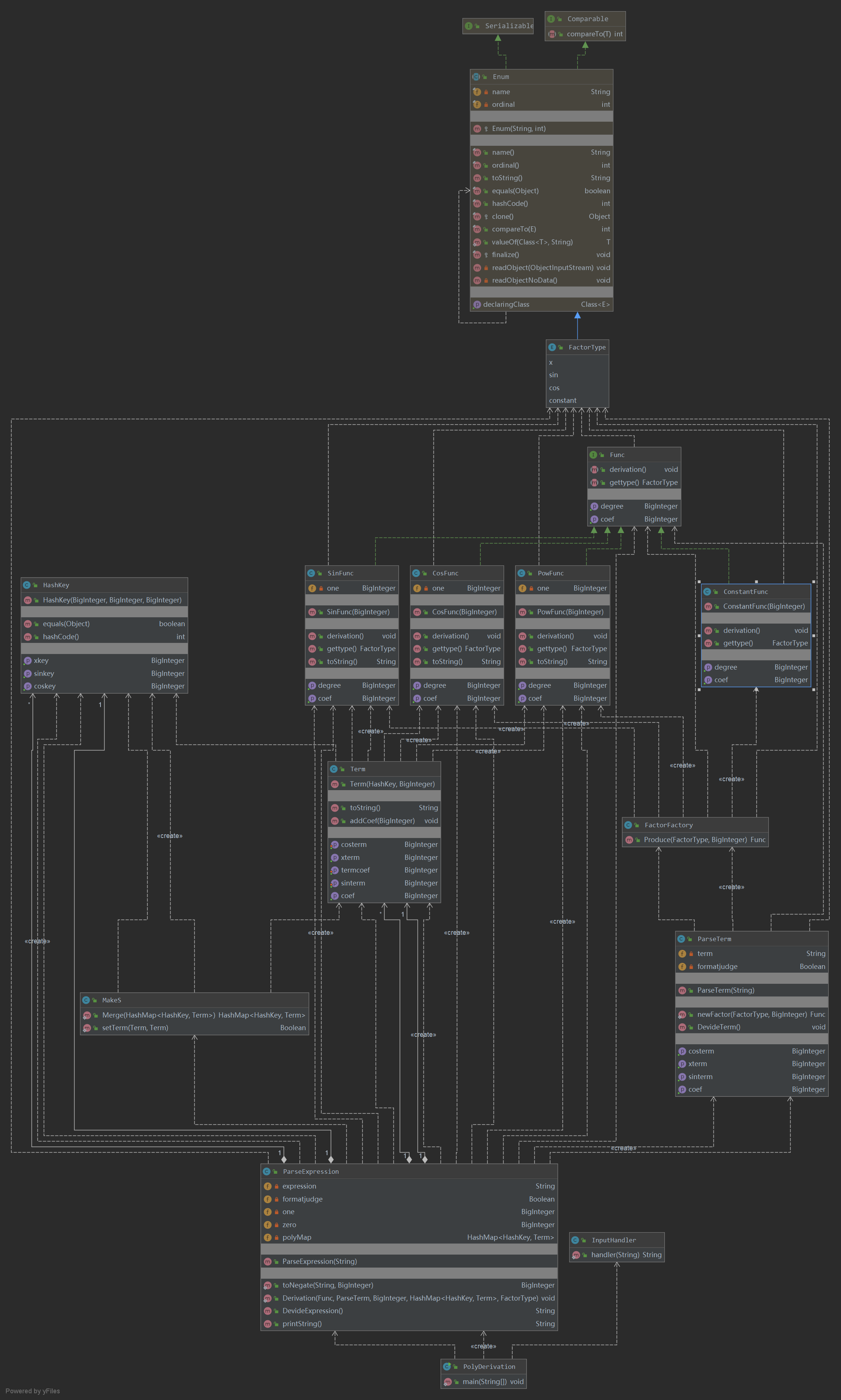
度量分析
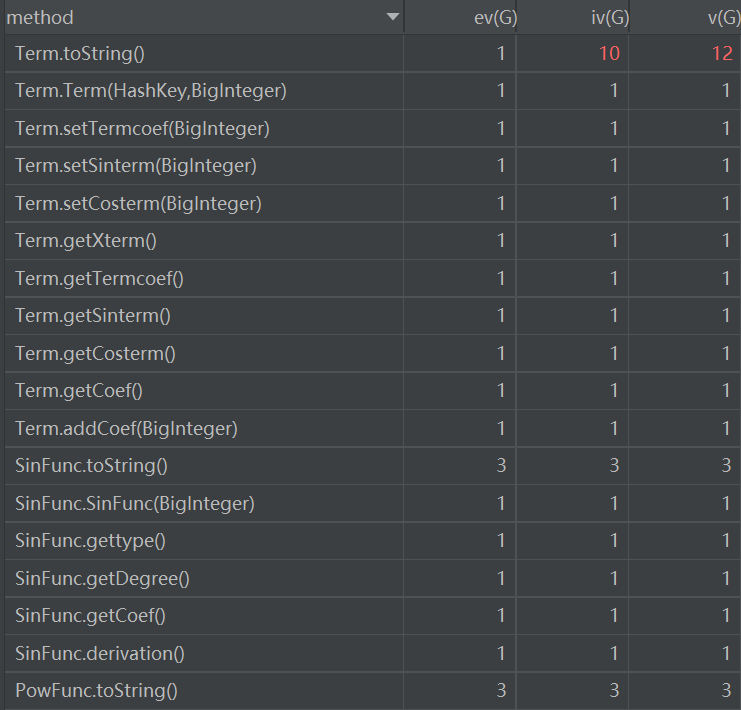

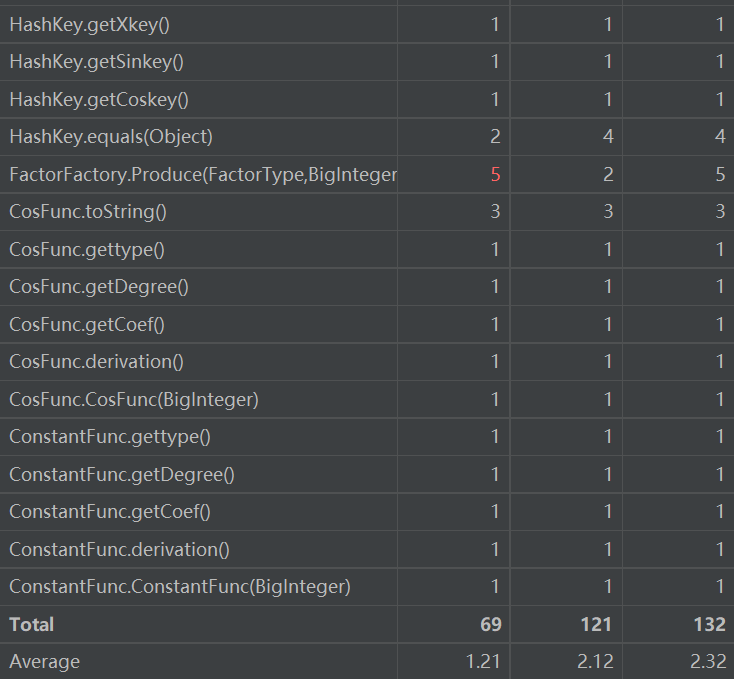
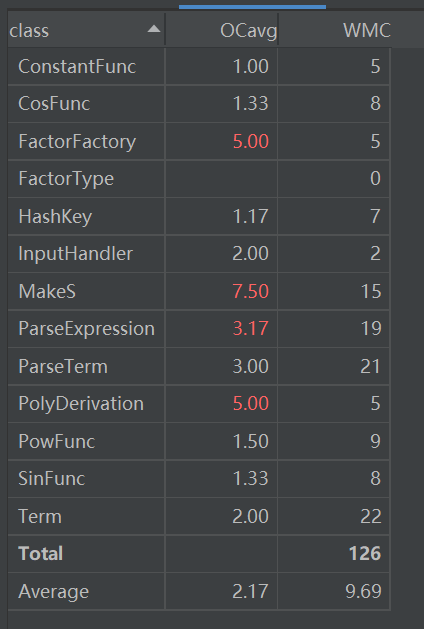
Term类的tostring和上面的toString出现的是同一个问题,在此不再赘述
ParseTerm的DevideTerm则是由于我分割term和判断类型没有分开,其实判断类型应当新开一个方法,因为每种类型的判断步骤其实类似,但我为图省事都聚在一起写了,不停的用if-else导致代码可读性和复杂度双双爆了
MakeS也存在着和上述一样的问题,由于那个化简我最后才写成,比较着急,写的一塌糊涂。不仅类分重了,还分多了,也是一层一层的if-else直接爆表。这都是十分不应该的。
现在看来,分类需谨慎啊,if-else能少用就应该少用啊,复杂度容易高不说,还容易把自己绕进去坑死啊
优点
- 运用了继承的思想
- 逻辑比较顺畅,没有出现bug
缺点
- 优化的时候由于一个循环出现低级错误,导致三角函数的化简那里只能化简一次,白白丧失了很多性能分。
- 求导过于面向过程,面向对象思维运用不到位。
第三次作业
思路:
- 格式判断:本次作业中我先对输入字符串进行了格式判断。
- 空白符判断:在进行空白符判断中,我成功的将非法位置空白符情况总结了出来(即sin、cos、和带符号整数的情况,带符号整数情况需注意sin(- 1)这种因去掉空白符而非法变合法的情况!),避免了边匹配表达式边判断空白符的麻烦,感觉这一点做的非常好。
- 指数大小判断:将表达式中所有的指数用正则单独匹配出来,判断是否大于50。
- 表达式格式判断:在进行空白符判断后,我们就可以大胆的把所有魔鬼空白符都删掉,再进行表达式判断。在表达式判断时,我的思路是,如果遇到嵌套因子/表达式因子,则将其嵌套部分/表达式部分用x替换(e.g.
sin(x**2)->sin(x),(1+x**2)->(x))。这样表达式就可以沿用第二次作业的正则判断。而嵌套部分则调用判断因子的方法来判断,表达式因子的内部表达式再次递归调用判断表达式的方法。
- 表达式处理:在表达式处理部分,我先对表达式处理,将除了
*和**后面的符号,其余的+都处理成只有一个,然后-都变成+-,**换为^,然后采用递归下降分解表达式,然后再用递归求导。- 分解表达式:用
+将表达式分解为项,再用*将项分解为因子,其中遇到括号时,括号内的符号不作为拆分符号。得到因子后,用正则表达式匹配因子,用工厂模式根据匹配创建新的因子类对象。我本次作业中创建了Factor接口,接口中有derivation和getIt两个抽象方法,sin、cos、pow、exp、composite和constant六个类继承自此接口。其中值得一提的是composite和exp这两个第三次作业种才出现的新因子。composite的处理我是分为了outtype和inner两部分,inner无论多么简单,都看作表达式,调用表达式的求导方法对其求导,虽然浪费了时间,但在一定程度上简化了思维难度。exp则直接调用表达式求导方法对其括号内内容进行求导。 - 求导的时候我应用了
(a*b*c*d*e)'=a'*(b*c*d*e)+a*(b*c*d*e)'这种求导思想,递归求导。
- 分解表达式:用
优化:
- 本次作业我在优化方面做的有所欠缺。因为发现自己的优化规律是"不优化不一定出错,但一优化准保出错。"因此最后的版本只去了零项,稍微在因子求导阶段化简了结果(如x**1只输出x),求了把稳。最后事实也证明我的想法是对的,虽然优化的不多,但贵在没有bug,在强测中也取得了不错的分数。
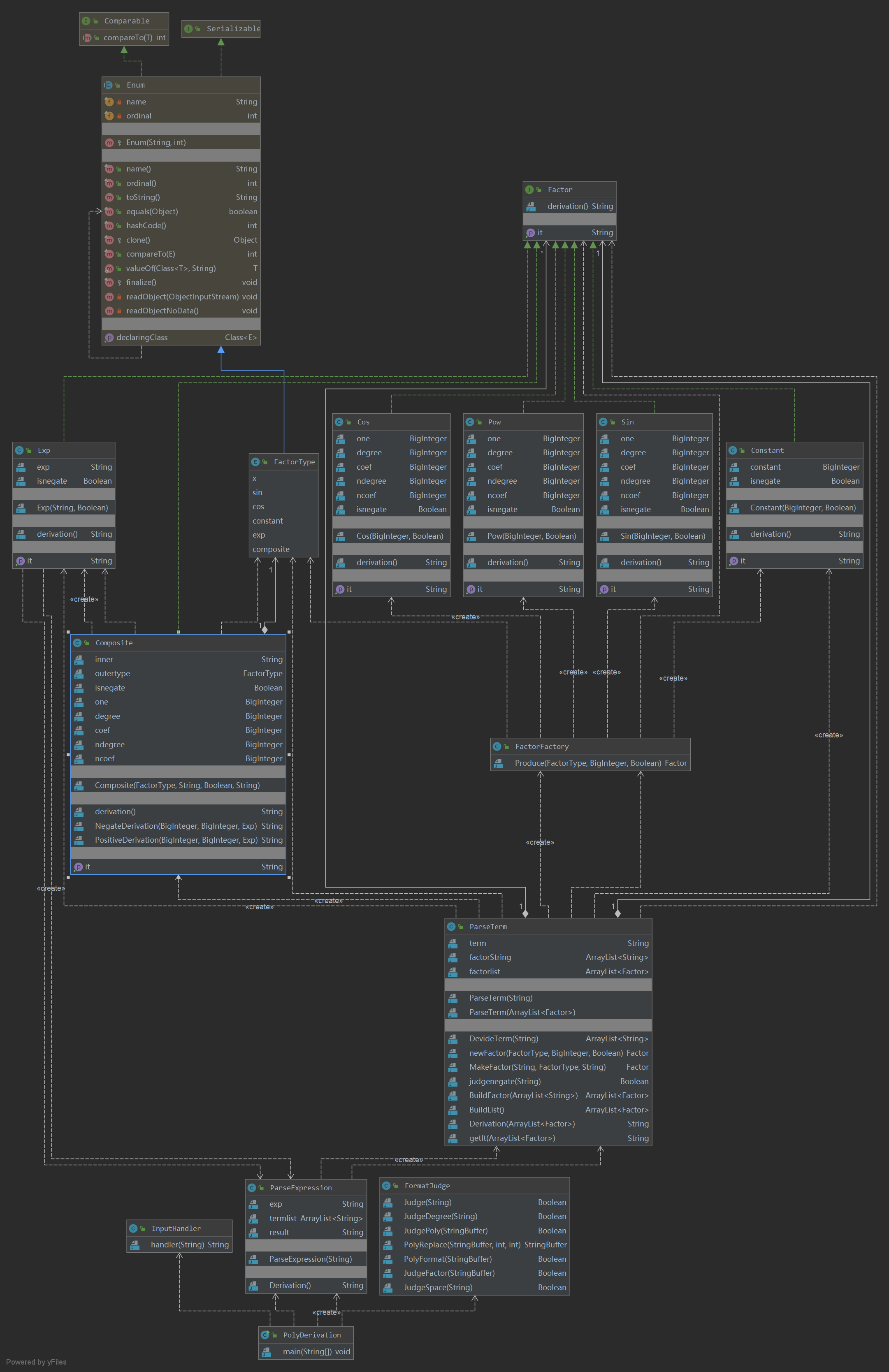
UML:
度量分析:
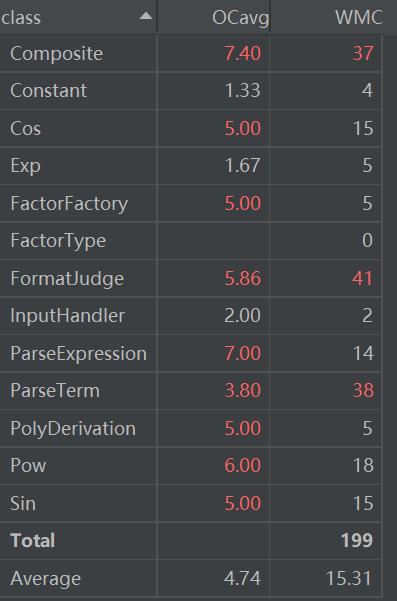
第三次复杂度整体看来都不太行,主要原因在于我把很多的事情都放在了一个方法(类)中进行。现在再去看指导书中的方法,相比原来的不理解,现在我有了新的思路。化整为零,不仅是为每一种函数建立类,而且为每一种组合方式建立类,将函数与其运算相对分离看,各行其职,相比我这版的大混杂,这无疑是一种更加思路清晰的做法,因而我最近也在思考着向这个方向重构部分代码。
优点:
- 结构清晰,没有被测出bug
- 应用了接口和继承,不同功能的类也大多可以分出来,有了面向对象的思想。
缺点:
- 格式判断的时候
()这种错误格式会出错。(虽然没被查出来qaq) - 没有使用表达式树,且很多数据直接使用字符串保存,不易化简。
- 耦合度和复杂度都过高了,疯狂爆红。
二、Bug分析
- 第一次作业:无
- 第二次作业:无
- 第三次作业:出现
()这种非法形式判断会出现问题,原因在于我读到(和)就直接把里面的内容扔给判断表达式/因子格式的函数,而忽略了括号内内容为空的情况。这不仅是由于我对非法格式的判断出现了纰漏,更是暴露出了我的其他问题。在进行每一步时,我都应将进行这一步的所有情况思考全,比如我要将括号里的东西传给其他方法,那就应该考虑到空和非空两种情况,而非空又会有非法和合法两种情况。再比如,用栈存储左括号来进行括号匹配的时候,我也应在遇到)将栈内内容推出一个的时候,考虑栈空和栈不空两种情况,而不是直接推出。在一些细节,尤其是空与非空这种容易使我忘记的地方,在今后的作业中我觉得我应该尤为注意。
三、发现别人Bug所采用的策略
- 自动评测机:我在第一次作业时就搭建了基于python脚本和shell脚本的自动评测机。
- 编写python脚本用xeger根据正则表达式随机生成数据。
- 编写python脚本用sympy来计算标准答案和互测屋中所有人的答案
- 编写python脚本用rand来在[-10,10]中线性随机选取100个数据带入正确答案和他人答案,根据指导书上正确性判断的公式,得出是否正确。
- 编写shell脚本将各个流程串起来,使用wsl运行。(其中在得到他人程序后应先将其程序打包成jar包)
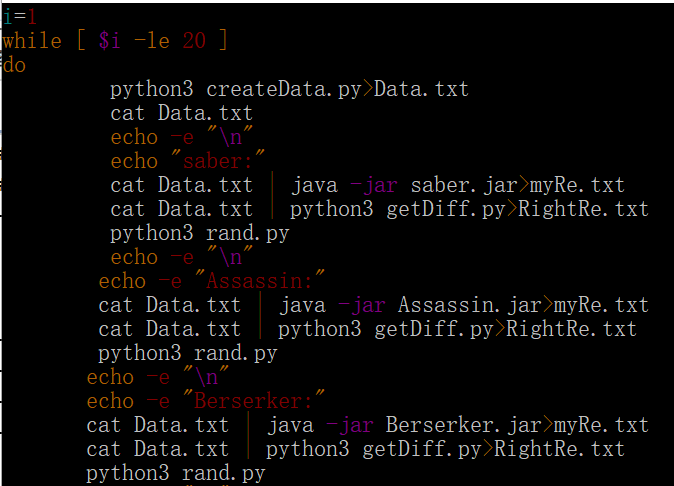
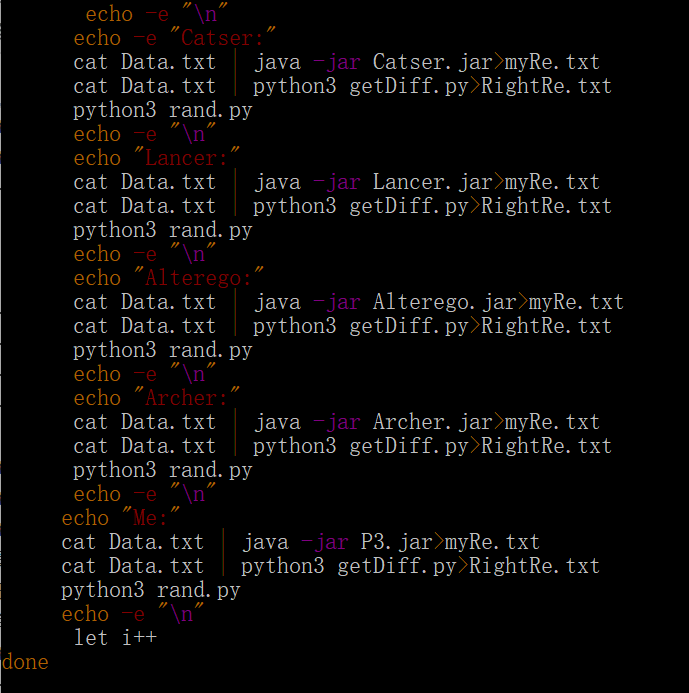
shell脚本整体框架如下
效果如下
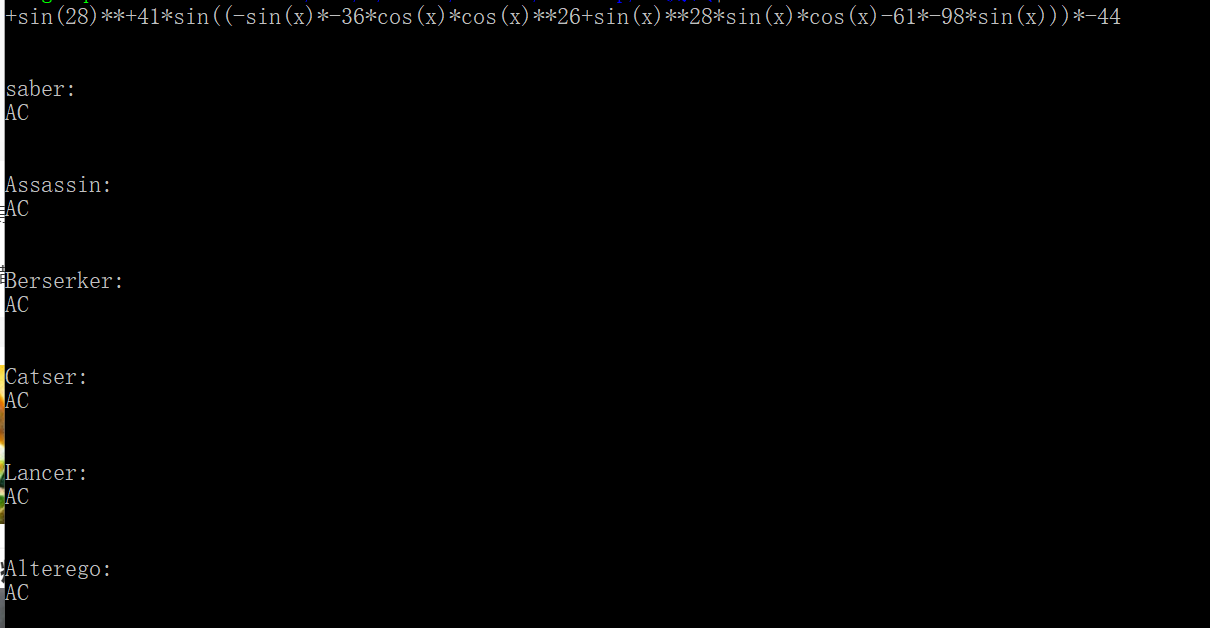
虽然自动评测机看起来很省事,其随机性也总是会给我带来惊喜,但正是由于其随机性,一些针对的易错的数据,还是需要我自己来手搓一下。
- 手搓数据: 自己动手出边缘数据,如
(((((((((((X)))))))))))这种爆栈爆递归数据,或者++123这种虽简单,但容易忽略处理不当的数据。 - 发现的bug:在三次作业中,我的主要hack来源都是自动评测机查出来的,说明其在查找bug上起到了很大的作用。除了第三次dl优化爆炸产生了错,其他的错大多数都是易忽视的小细节问题,说明这一块大家还是要再注意些。下面列举几个典型错误。
- 1.((((((((((((((((((((x))))))))))))))))))))) 这个错误抓到的是tle的问题,是典型的架构出错的问题。说明该同学在构思的时候没有估计自己所需要的递归层数,导致其过多而出错。
- 2.-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x-x... 这是我在第一次作业中看到别人hack的一个样例,感觉很有意思。该同学出现了stackoverflow的错误。查找后发现是正则爆栈,这说明在应用正则表达式上出现了问题。遇到需要正则匹配的地方,不应用超大正则直接莽,在应用正则之前的预处理,以及分步的思想很重要。
- 3.cos(x) 这纯粹是细节的问题。该同学将其的导数写成了sin(x)。这说明写代码的时候不仅应当看顾全局,更应小心细节,一个细节可能就会使你的整篇代码白码。这更是警醒我们,在测试的时候不应只看大数据、复杂数据。有些细的点可能才是出错的大概率来源。
- 4.求导后出现
(x)**2。这是典型的没有仔细阅读指导书所出的错。在写代码前仔细读懂读全指导书的每一句话至关重要。
- 附上hack次数:
- 第一次作业:成功hack了6次。被hack:0。
- 第二次作业:成功hack了18次(其中应该有同质,但由于有的代码有些难看懂,没去读,所以找到的都交了)。被hack:0。
- 第三次作业:成功hack了8次。被hack:0。
四、应用对象创建模式
- 工厂模式: 对于本次作业可以使用工厂模式来创建因子,只需要定义一个创建对象的接口,让实现了该接口的子类自己决定实例化哪一个工厂类。根据条件来创建不同对象时感觉非常好用。
- 抽象工厂模式:抽象工厂模式是围绕一个超级工厂创建其他工厂。该超级工厂又称为其他工厂的工厂,它提供了一种创建对象的最佳方式。在抽象工厂模式中,接口是负责创建一个相关对象的工厂,不需要显式指定它们的类。每个生成的工厂都能按照工厂模式提供对象。在重构中,我可以把第三次作业代码中的工厂模式进行更改。将因子与计算方法分来。分别创建接口,再为二者创建抽象类(AbstractFactory)来获取工厂(FactorFactory和CaculateFactory)。创建扩展了 AbstractFactory 的工厂类,基于给定的信息生成实体类的对象。创建一个工厂创造器/生成器类,通过传递因子或计算类型信息来获取工厂。然后获取实体类的对象。
五、对比和心得体会
在看了别人的优秀代码后察觉到了自己的不足。
- 首先,方法耦合度高,有些可以拆开的方法还是合在一起写了。虽然相比pre有了很大很大的提升,但是面向对象的思想还是不够。
- 其次,存储数据结构单一。这几次作业中我基本都是用HashMap存的数据,虽然第三次作业想用表达式树,但由于思考半天还是没有一个完美的思路而不得不放弃,看到了大佬的表达式树构建后感觉收获了很多。
- 最后,虽然这三周过的倍感煎熬,但看到成绩总会觉得是值得的,感觉自己的水平也在不断的提升,面向对象的思想也在一点点渗透。听说以前OO的考核制度比现在更凶残。我们现在的公测、互测等已经是在一届届老师助教的努力下得到了很大的完善。为了不辜负助教老师们为我们铺设的学习环境,也为了不辜负自己,我一定会继续努力,投入百分百的精力进去,提高自己的编程能力!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号