


hadoop的起源——Lucene
用java书写代码,实现与Google类似的全文搜索功能,它提供了全文检索引擎的架构,包括完整的查询引擎和索引引擎
Doug Cutting 写的一个开源软件,借鉴了Google的 GFS和MapReduce思想,Map-Reduce 和 Nutch Distributed File System (NDFS) 分别被纳入称为 Hadoop 的项目中。
实现大数据、云存储、云计算,首选hadoop。
PB级以上
TB是一个计算机存储容量的单位,它等于2的40次方,或者接近一万亿个字节(即,一千千兆字节)
TechTarget自己的百科网站Whatis有关于PB大小的定义:“PB是数据存储容量的单位,它等于2的50次方个字节,或者在数值上大约等于1000个TB
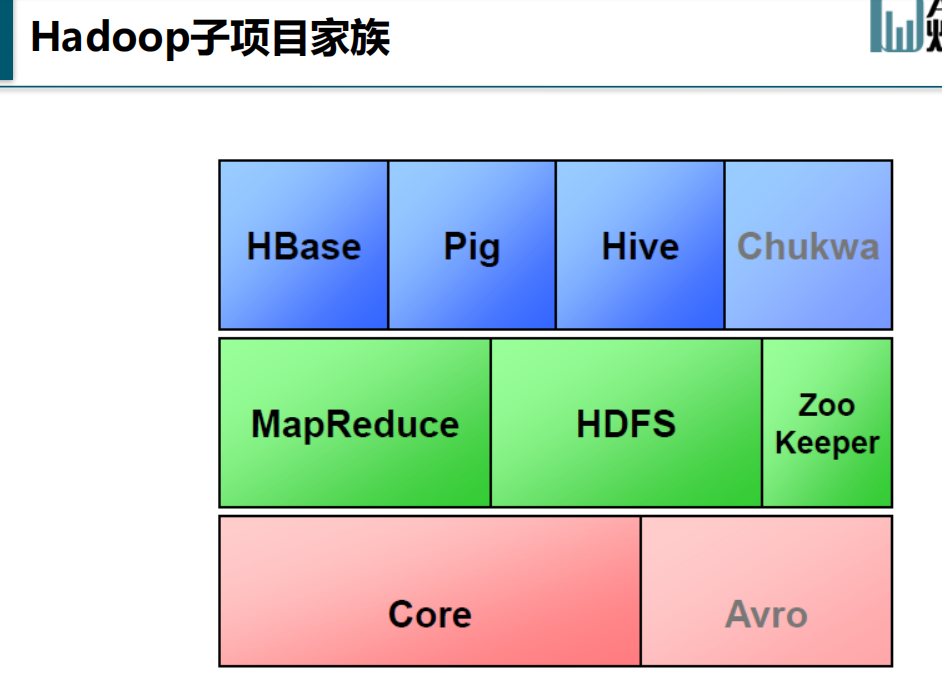
chukwa--数据集成工具,抓取信息。
pig--可以用shell轻量级语言进行数据处理或
数据分析,将shell命令-->mapreduce 再返回结果。
Hive--相当于sql语言到reduce的映射器将
sql-->mapreduce,再返回结果。复杂的sql语句不支持。
HBase--Nosql数据库,链式数据库,链式存储。
面向数据分析,提高响应速度,减少Io。本身也可以做成分布式集群。
MapReduce和HDFS(分布式文件系统)两大支柱
ZooKeeper--服务器节点以及进程之间的通讯。
core--hadoop的核心代码
Hadoop架构
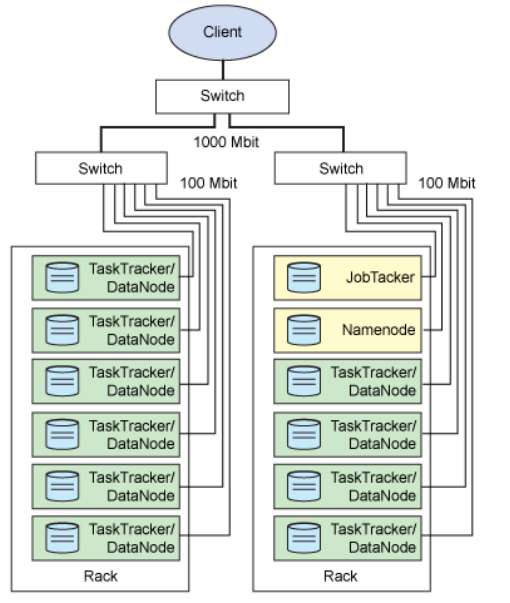
客户端
switch--交换机
黑线--网线
矩形--物理服务器
hadoop的后台进程 :jobTacker、NameNode、TaskTracker。。。
NameNode: Master
HDFS的守护程序,总控的作用。
纪录文件是如何分割成数据块的,以及这些数据块被存储到哪些节点上
对内存和I/O进行集中管理
缺点:是个单点,发生故障将使集群崩溃
Secondary Namenod:辅助名称节点 Master
NameNode的后备
当NameNode故障NameNode使用
缺:只能手动切,没办法自动
DataNode:slaver
每台从服务器都运行一个
负责把HDFS数据块读写到本地文件系统
这三个组成了HDFS
rack--机架
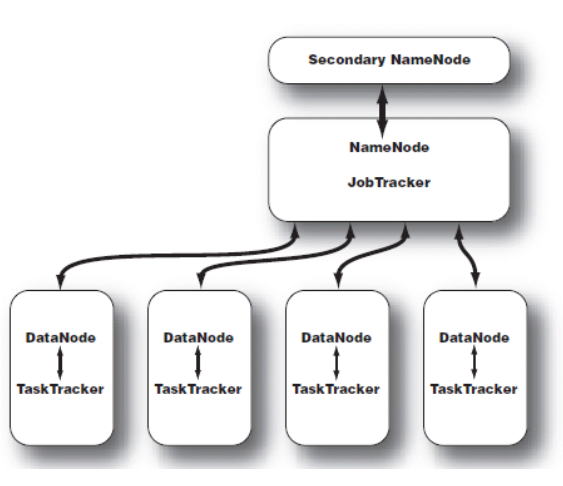
JobTracker:Master 作业跟踪器
用于处理作业(用户提交代码)的后台程序
决定有哪些文件参与处理,然后切割task并分配节点

监控task,重启失败的task(于不同的节点)
每个集群只有唯一 一个JobTracker,位于Master节点
TaskTracker:slaver 任务跟踪器
位于slave节点上,与datanode结合(代码与数据一起的原则)
管理各自节点上的task(由jobtracker分配)
每个节点只有一个tasktracker,但一个tasktracker可以启动多个JVM,用于并行执行map或reduce任务
与jobtracker交互
Master不是唯一的
这俩组成了MapReduce

