
Zookeeper 概念、运行原理、配置、启动
Zookeeper:为了保证分布式数据的一致性,ZK提供通用的分布式锁服务,泳衣协调分布式应用
ZK(Zookeeper)使用的是Paxos算法
ZK分别在Hadoop和HBase中的作用:
在Hadoop中,使用Zk的事件处理确保整个集群只有一个NN(NameNode),存储配置信息等
在HBase中,使用ZK的时间处理确保整个集群只有一个HMaster,察觉HRegionServer联机和宕机,存储访问控制列表等
ZK工作原理:
1、每个server在内存总存储了一份数据(元数据),这些数据会定期的被存在磁盘中
2、ZK在启动时,将从所有server中选一个做leader(遵循Paxos算法协议)
3、leader负责处理数据更新等操作
4、一个更新操作成功,当且仅当大数server在内存中成功修改数据
Paxos算法:ZK service中有固定的server,每个都可以发起一个提议,所有的server进行投票,但同意票数过半时,提议生效,反之失效,每个server只能投一次,不可重复。
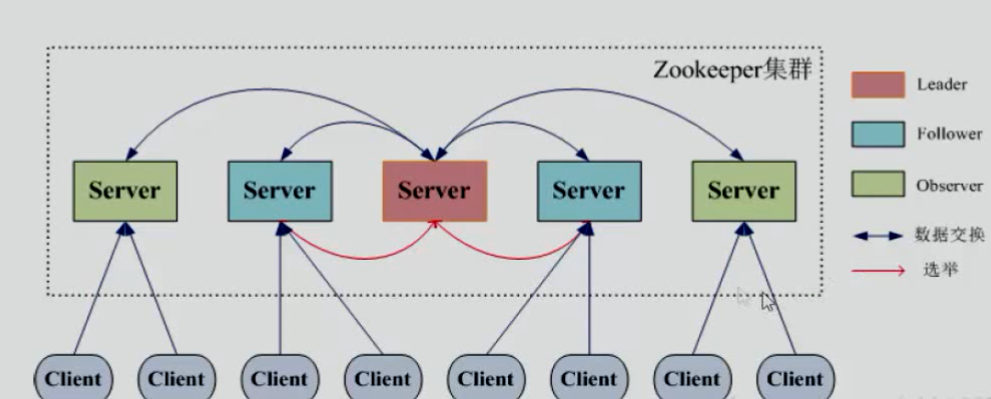
ZK Service:服务器集群
Server Leader:发起提议
Server(Follower):投票
Observer:接收客户端的请求,将写请求转发给Leader,Observe不参与投票,只同步leader状态,目的是为了提高读取速度
Client:请求
情况一:当Client需要知道某条提议的结果,向其中一个Server发起询问,server会在本地(local storage)查找该提议结果回复Client
情况二:当某个Client需要修改数据,请求发到某个server,server会将提议交给server leader,由server leader发起提议,请所有server一起投票(投票机制:该提议的数据大于或等于自己的编号(mZxid),server才投赞成,编号格式:由64位数据组成,高32位是leader,低32位是指数据被修改了几次),赞成超过半数则生效,leader会通知其他server更新数据,被请求要求修改数据的server会将结果返回至Client
情况三:当多个server都无法连接到server leader时,server间将推选新的leader,当leader挂掉了,谁发现了谁就会发起自己做leader的提议(严格准守投票机制),当确定leader后,其他server会向leader同步数据,选leader期间将拒绝所有的client请求
图:
ZK优点:

Zk配置:


将Server变成Observe:只需将zoo.cfg中 把server.A=B:C:D改成server.A=B:C:D:observer
启动:
ZK集群启动:在bin目录下执行命令:./zkServer.sh start
检测集群是否启动:bin目录下运行命令:./zkServer.sh status

 浙公网安备 33010602011771号
浙公网安备 33010602011771号