
MapReduce提交作业
步骤:
1、开发作业
2、编译项目并打成jar包,上传至HDFS
3、使用命令(脚本)启动作业
Java代码:
/**
* 检索关键词出现的次数
*/
public class MapReduceUtils {
/**
* diver
*
* @param a [0]要解析的文件全路径
* [1]输出存放的路径
*/
public static void main(String[] a) throws Exception {
Configuration entries = new Configuration();
Job job = Job.getInstance(entries, "我是作业名");
//设置job的处理类
job.setJarByClass(MapReduceUtils.class);
//设置作业处理的输入路径
FileInputFormat.setInputPaths(job, new Path(a[0]));
//设置map的相关参数
job.setMapperClass(MyMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(LongWritable.class);
//设置reduce参数
job.setReducerClass(MyReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(LongWritable.class);
//设置作业的输出路径
FileOutputFormat.setOutputPath(job, new Path(a[1]));
//提交作业
boolean b = job.waitForCompletion(true);
//完成,退出
System.exit(b ? 0 : 1);
}
/**
* 自定义Mapper
* 读取输入的文件
* <p>
* LongWritable map读取的偏移量
* Text map读取的字符
* <p>
* Text reduce读取的关键字
* LongWritable reduce读取的关键字的次数
*/
public static class MyMapper extends Mapper<LongWritable, Text, Text, LongWritable> {
private final LongWritable one = new LongWritable(1);
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
//接收每行数据,定义分割规则
String[] split = value.toString().split(" ");
for (String sp : split) {
context.write(new Text(sp), one);
}
}
}
/**
* 自定义Reduce
* 递归操作
* <p>
* Text reduce读取的关键字
* LongWritable reduce读取的关键字的次数
* <p>
* Text 输入的key
* LongWritable 输出关键字次数
*/
public static class MyReduce extends Reducer<Text, LongWritable, Text, LongWritable> {
@Override
protected void reduce(Text key, Iterable<LongWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (LongWritable writable : values) {
sum += writable.get();
}
context.write(key, new LongWritable(sum));
}
}
}
maven命令编译项目:mvn clean package -xxx(项目名)
成功后,上传至HDFS,命令:scp xxx/xxx.jar(jar全路径) xxx(用户名)@xxx(ip地址):xxx(目的地的全路径)
Copy成功后,使用命令 :hadoop jar xxxx(刚上传的文件全路径) com.hdfs.api.test.mapreduce.MapReduceUtils(要执行的主函数类全路径) xxx(要解析的文件全路径,要加主机全地址) xxx(结果输出的全路径,要加主机全地址)
后面的参数视当时业务逻辑而定
执行命令,例如:hadoop jar D:\\a.jar com.hdfs.api.test.mapreduce.MapReduceUtils hdfs://192.xxx:9000/app/input/hello.txt hdfs://192.xxx:9000/app/out/result.txt
其中有个问题,输出文件是不能先存在的,否则会抛出异常:
ERROR security.UserGroupInformation: PriviledgedActionException as:allencause:org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://xxx/xxx already exists
Exception in thread "main" org.apache.hadoop.mapred.FileAlreadyExistsException: Output directory hdfs://xxx/xxx already exists
解决办法:
1、将删除命令和执行命令写入脚本(不推荐)
脚本内容:
hadoop fs -rm -f /out/result.txt
hadoop jar D:\\a.jar com.hdfs.api.test.mapreduce.MapReduceUtils hdfs://192.xxx:9000/app/input/hello.txt hdfs://192.xxx:9000/app/out/result.txt
2、在main方法中的提交作业之前加入一下代码(推荐)
//检测输出文件是否已存在。存在则删除
FileSystem fileSystem = FileSystem.newInstance(entries);
Path outFilePath = new Path(a[1]);
if (fileSystem.exists(outFilePath)) {
//存在,删除
fileSystem.delete(outFilePath, true);
}
优化:
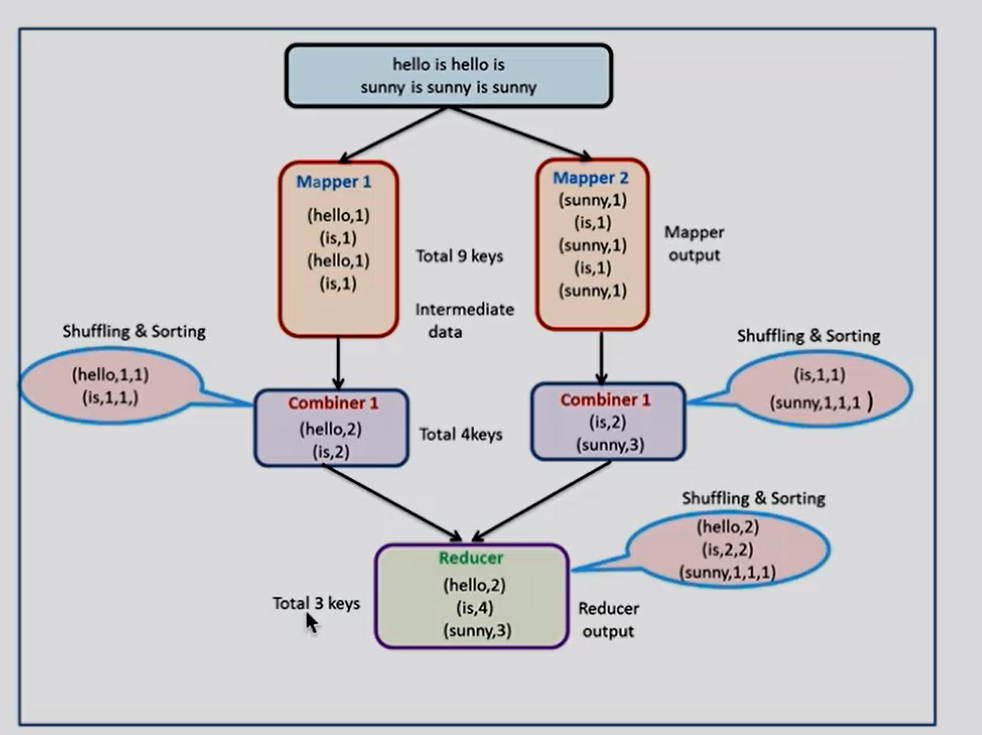
不加入Combiner组件是9个数据传给Reduce,加入后,是只有4个数据传给Reduce,Combiner处理类的逻辑和Reduce是一样的,所以直接传自定义的Reduce即可
只用在设置Reduce参数是加入一行代码即可
Combiner使用场景:
求和、次数 相加型的
//设置Combiner job.setCombinerClass(MyReduce.class);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号