
番外2: go语言写的简要数据同步工具
go-etl工具
作为go-etl工具的作者,想要安利一下这个小巧的数据同步工具,它在同步百万级别的数据时表现极为优异,基本能在几分钟完成数据同步。
1.它能干什么的?
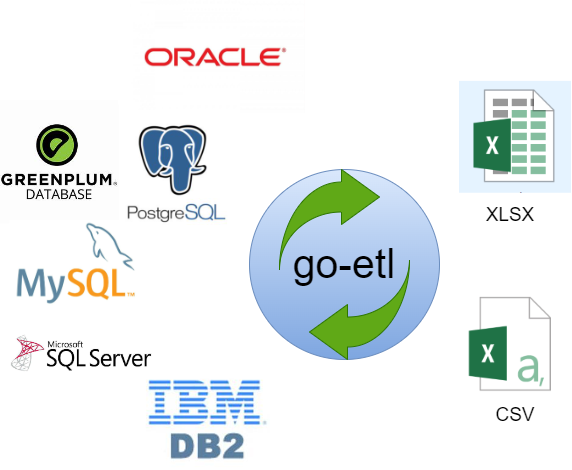
go-etl是一个数据同步工具集,目前支持MySQL,postgres,oracle,SQL SERVER,DB2等主流关系型数据库以及csv,xlsx文件之间的数据同步,在同步百万级别的数据时表现极为优异,基本能在几分钟完成数据同步。
2.怎么获取它?
可以在最新发布版本下载到windows或者linux操作系统的64位版本二进制程序
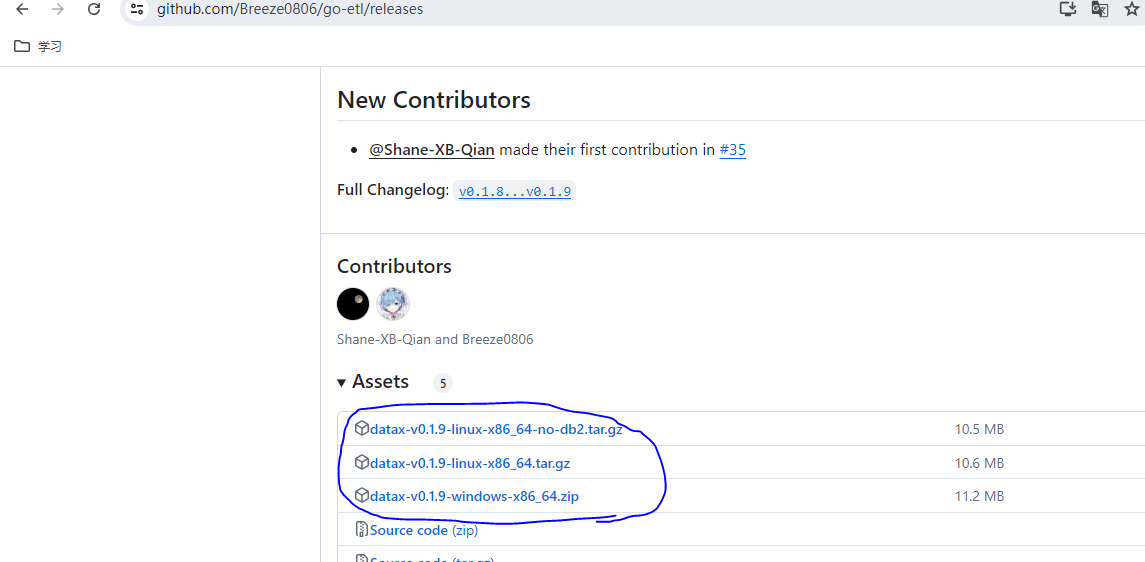
如图所示第1个是不包含db2功能的linux二进制程序,第2个是linux版本的,第3个是windows版本的
3.怎么使用它?
go-etl datax二进制程序是一款即插即用的程序,它的唯一难点是配置导入配置文件,配置它的配置文件我们需要理解它的工作原理
3.1 工作原理
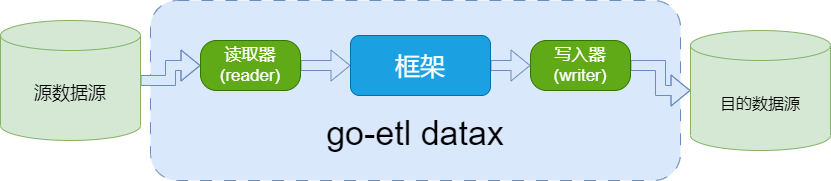
如上图所示go-etl datax将数据从源数据源同步到目的数据源,
-
读取器:
reader为数据采集模块,负责采集数据源的数据,将数据发送给框架。 -
写入器:
writer为数据写入模块,负责不断向框架取数据,并将数据写入到目的端。 -
框架:框架用于连接
reader和writer,作为两者的数据传输通道,并处理缓冲,流控,并发,数据转换等核心技术问题
3.2 配置数据同步文件
通过工作原理,需要配置reader和writer才能使go-etl datax准确地开始工作,本次以csv和mysql之间的数据同步为例, 以下是完整的配置文件,但仅需要关注job.content即可
{
"core" : {
"container": {
"job":{
"id": 1,
"sleepInterval":100
}
}
},
"job":{
"content":[
{
"reader":{
"name": "csvreader",
"parameter": {
"path":["split.csv"],
"encoding":"utf-8"
}
},
"writer":{
"name": "mysqlwriter",
"parameter": {
"username": "root",
"password": "123456",
"writeMode": "insert",
"column": ["*"],
"connection": {
"url": "tcp(192.168.15.130:3306)/mysql",
"table": {
"db":"source",
"name":"split"
}
},
"batchTimeout": "1s",
"batchSize":1000
}
},
"transformer":[]
}
],
"setting":{
"speed":{
"byte":0,
"record":1024,
"channel":4
}
}
}
}
这里先看reader,首先留意到的时reader的名字是csvreader,表明其源数据源的类型,再例如如mysql的读取器为mysqlreader,接着留意到的时reader的参数,path代表csv文件的存储位置,encoding为csv文件的字符集。
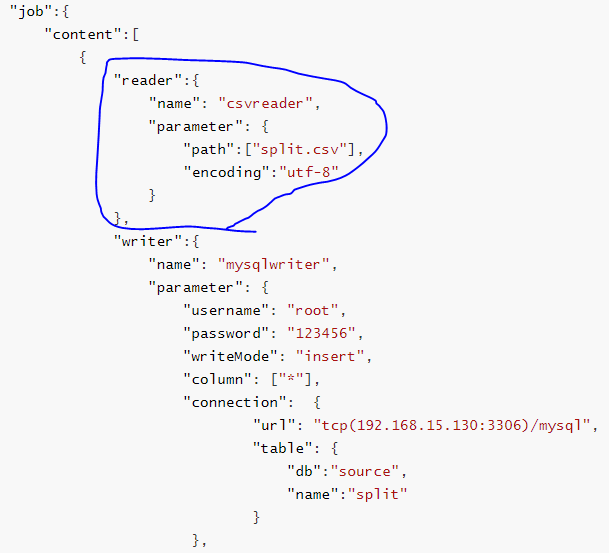
这里再看writer,首先留意到的时reader的名字是mysqlreader,表明其目的数据源的类型,再例如csv的读取器为mysqlreader,接着留意到的时writer的参数,需要配置的是username,password,connection的url和table,用户名密码无需多言,这里要重点讲讲url,基本配置格式:tcp(ip:port)/db,ip:port代表mysql数据库的IP地址和端口,db表示要默认连接的数据库,table是需要写入的表信息。

3.3 运行程序导入数据
将上述配置命名为config.json,将其和datax以及待导入的数据文件split.csv放到同一目录下,在windows中使用命令行或者linux中使用终端执行以下命令
datax
3.4 批量写入数据
3.4.1 源目的配置向导文件
源目的配置向导文件是csv文件,每行配置可以配置如下:
path[table],path[table]
每一列可以是路径或者是表名,注意所有的表要配置库名或者模式名,需要在数据源配置文件配置。
3.4.2 批量生成数据配置集和执行脚本
在windows中使用命令行或者linux中使用终端执行以下命令
datax -c tools/testData/xlsx.json -w tools/testData/wizard.csv
-c 指定数据源配置文件 -w 指定源目的配置向导文件。
执行结果会在数据源配置文件目录文件生成源目的配置向导文件行数的配置集,分别以指定数据源配置文件1.json,指定数据源配置文件2.json,...,指定数据源配置文件[n].json的配置集。
另外,在当前目录会生成执行脚本run.bat或者run.sh。
3.4.3 运行脚本
windows中使用命令行即可
run.bat
linux中使用终端执行即可
run.sh

 浙公网安备 33010602011771号
浙公网安备 33010602011771号