C\C++ 知识点汇总
C\C++反汇编中几个比较重要的知识点
1.C++的虚函数表
2. 两个虚函数类实例对象是否共用一份虚函数表
3. 构造函数是否可以加虚,析构函数是否可以加虚
4. C++中的引用
5. C中针对switch的优化
1. 64位函数的调用约定
从右往左顺序入栈,前四个存放于寄存器(从左往右),RCX、RDX、R8、R9;
其之后依次会存入 rsp+8h, rsp+10h ··· 中。
当数量超出4个,其将剩余的直接存入栈中。
1. 如果使子类对象调用父类的函数
childptr->parent::func();
child.parent::func();
无论是否加虚,其都会正确调用父类的函数。
1. C++的虚函数表
#include <Windows.h> #include <iostream> #include <stdio.h> using namespace std; class animal{ virtual void speak()=0; virtual void name()=0; }; class cat: public animal { public: void speak() { cout << "miaomiaomaio~" << endl; } void name() { cout << "I am a cat" << endl; } }; int main() { cat c; c.speak(); }
如上代码,其对于cat类,存在两个虚函数。
虚函数存储在虚函数表中,因此该成员的第一位是一个表的地址,里面存储了其对应的虚函数地址。

我们在IDA中查看其虚函数表所在位置

2. 派生类中没有更改的虚函数,其表中地址是否与父类的一致
是一致的,这个算是常识,很好理解。
即使没有改动父类的虚函数,其依然生成一张新表(指地址改变);
但是其表中的函数地址,如果子类没重写,则与父类的一致。
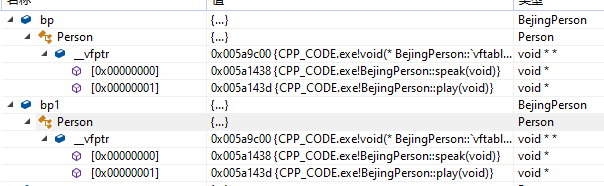
3. 两个虚函数类实例对象是否共用一份虚函数表
是共用一份虚函数表,其反汇编代码如下
3. 构造函数是否可以加虚,析构函数是否可以加虚
构造函数不可加虚,因为虚函数是依照虚函数表来实现的,虚函数表地址存储在变量中,此时变量还没生成,当然不可以生成;析构函数可以加虚,因为其虚函数表已经建立。
4. 多态的意义
其只有在运行时才可以实现,可以被基类来转换,如下;若A类不的speak()不加虚,此输出会是 "AAA",而不是"ABC"。

5. 虚函数表菱形继承问题
其继承如下,之前我们在 问题[2] 中分析过,一个类的多个实例化共用一个虚函数表,但这个是一个类多个虚函数表。
其实,理解虚函数本质就很好理解 A->B , A->C 时,其根据B与C类来更改A的虚函数表,因此虚函数表当然会改变,不会是相同一份。

3. C++中的引用
#include <Windows.h> #include <iostream> #include <stdio.h> using namespace std; void func(int& x) { cout << x << endl; } int main() { int x = 2; func(x); }
引用的本质是指针,但是又对指针做了限制,无法对指针本身指向内容进行修改。
查看下面的反汇编代码就很好理解。
我们查看其反汇编代码:
func(x);
005E20B9 lea eax,[ebp-0Ch] // 传入变量x的地址
005E20BC push eax
005E20BD call 005E145B
cout << x << endl;
005E1941 mov eax,dword ptr [ebp+8]
005E1944 mov ecx,dword ptr [eax]
005E1946 push ecx // 从指针中取出值来进行操作
3. C中针对switch的优化
1)常规形式
switch被翻译成 if..else..结构
2)大表索引
#include <stdio.h> int main(int argc, char* argv[]) { int s = 5; switch (s) { case 101: printf("101\n"); break; case 102: printf("102\n"); break; case 103: printf("103\n"); break; case 104: printf("104\n"); break; default: printf("error\n"); break; } return 0; }
我们查看其反汇编代码:
switch (s) {
00AF183F mov eax,dword ptr [ebp-8]
00AF1842 mov dword ptr [ebp+FFFFFF30h],eax
00AF1848 mov ecx,dword ptr [ebp+FFFFFF30h]
00AF184E sub ecx,65h
00AF1851 mov dword ptr [ebp+FFFFFF30h],ecx
00AF1857 cmp dword ptr [ebp+FFFFFF30h],3
00AF185E ja 00AF18A9
00AF1860 mov edx,dword ptr [ebp+FFFFFF30h]
00AF1866 jmp dword ptr [edx*4+00AF18CCh]
其将变量S-101h,获取索引(0,1,2,3),然后判断如果大于3,直接跳到default域中,否则根据索引去 00AF18CCh 这张表中获取跳转地址。
我们查看这张表中的内容:
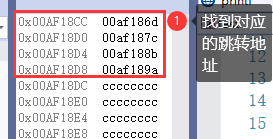
因此这样可以极大的加快查找效率
3)大表+小表索引
上面大表索引有一个缺点,就是当出现断层时,中间很大一块要使用default的地址填补,比如 1,2,3,4,101,102,103,104;
此时就是采用大表+小表的索引形式,构建两张大表。
我们按例子中的思路再来构建 1,2,3,4,101,102,103,104 这种情况
switch (s) {
0088504F mov eax,dword ptr [ebp-8]
00885052 mov dword ptr [ebp+FFFFFF30h],eax
00885058 mov ecx,dword ptr [ebp+FFFFFF30h]
0088505E sub ecx,1
00885061 mov dword ptr [ebp+FFFFFF30h],ecx
00885067 cmp dword ptr [ebp+FFFFFF30h],67h
0088506E ja 008850FE
00885074 mov edx,dword ptr [ebp+FFFFFF30h]
0088507A movzx eax,byte ptr [edx+00885138h]
00885081 jmp dword ptr [eax*4+00885114h]
可以看到索引值从00885138h这张表中获取,一个字节,拿到该索引值后又从00885114h这张表中获取。


这样本来需要四个字节存储的空白只需要一个字节就够了。
4)放弃大表+小表,重新回归大表。
上面那种仍然有很多空白,我们继续设想,如果更加极端的情况呢?
现在我们假设 1,2,3,4,101,102,103,104,10001,10002,10003,10004
在这种情况下,我们继续观察,发现其放弃采用两张表的形式,又回归到一张表中了。
其根据大小按索引重新排序,回归到一张表中。
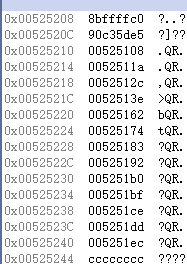
反汇编代码

 浙公网安备 33010602011771号
浙公网安备 33010602011771号