汇编语言入门四:打通C和汇编语言
回顾
上回我们把汇编里涉及到的寄存器和内存访问相关的内容说了。先来梳理一下:
- 寄存器是一些超级小的临时存储器,在CPU里面,存放CPU马上就要用到的数据或者刚处理完的结果
- 要处理的数据太多,寄存器装不下了,需要更多寄存器,但是这玩意贵啊
- 内存可以解决上述问题,但是内存相比寄存器要慢,优点是相对便宜,容量也大
插曲:C语言与汇编语言的关系
还有一些疑虑,先暂时解释一下。首先,C语言里编程里,我们从来没有关心过寄存器。汇编语言里突然冒出这么一个东西,学起来好难受。接下来的内容,我们先把C语言和汇编语言的知识,来一次大一统,帮助理解。
首先我们来看一个C语言程序:
int x, y, z;
int main() {
x = 2;
y = 3;
z = x + y;
return z;
}考虑到我们的汇编教程才刚开始,我这里尽可能先简化C程序,这样稍后涉及到等价的汇编内容时所需的知识都是前面介绍过的。
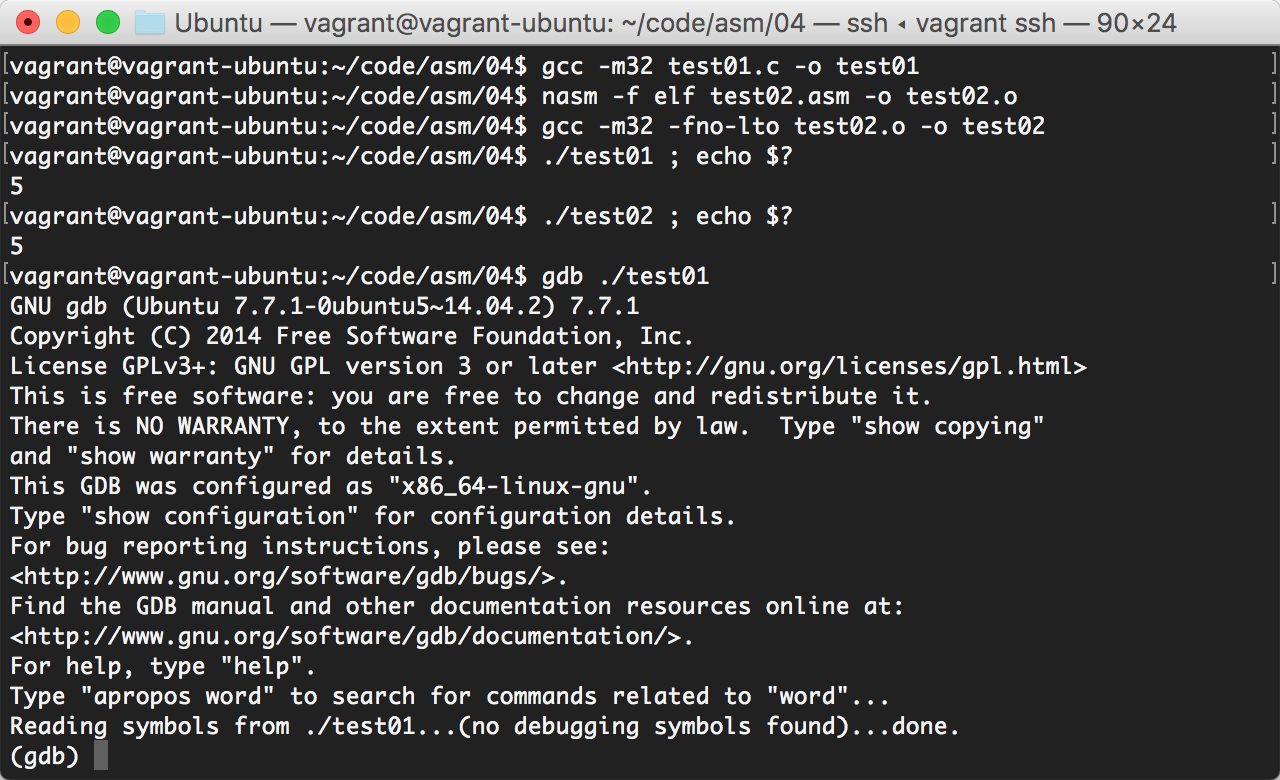
保存为test01.c文件,先编译运行这个程序:
(注意,这里的gcc带了一个参数-m32,因为我们要编译出32位(x86)的可执行文件)
$ gcc -m32 test01.c -o test01
$ ./test01 ; echo $?
5好了,在这里,我们的程序返回了一个值:5。
好的,接下来我们看看如果我们要用汇编实现几乎相同的过程,该怎么做?
首先,三个全局变量:
int x, y, z;
总得有吧。(这里之所以会用全局变量,是考虑到局部变量相关的汇编知识还未介绍,先将就一下,后续再说局部变量的内容)
首先,在C语言里,你可以认为每个变量都会占用一定的内存空间,也就是说,这里的x、y、z分别都占用了一个“整型”也就是4字节的存储空间。
上次我们介绍过在汇编里面访问内存的知识,当然,我们也知道了怎么在数据区划出一定的空间,这次我们就照搬前面提及的方法:
global main
main:
mov eax, 0
ret
section .data
x dw 0
y dw 0
z dw 0这个程序就等价于下面的C代码:
int x, y, z;
int main() {
return 0;
}也就是现在有了三个全局变量,只是现在汇编程序什么都没做,仅仅返回了0而已。
这里的C代码和上述汇编代码从某种程度上来说,就是完全等价的。甚至,我们的C语言编译器就可以直接把C代码,翻译成上述的汇编代码,余下的工作交给nasm再编译一次,把汇编转化为可执行文件,就能够得到最后的程序了。当然,理论上可以这么做,实际上有的编译器也就是这么做的,只是人家生成的汇编格式不是nasm,而是其它的类型,但是道理都差不多。
也就是说,一个足够精简的C编译器,只需要能够把C代码翻译成汇编代码,剩下的交给汇编器完成,也就能实现完整的C语言编译器了,也就能得到最后的可执行文件了。实际上C编译器是完全可以这么做的,甚至有的就是这么做的。
好了,先不扯这些,我们先把前面的程序补充完整,达到和最前面的C代码等价为止。接下来,我们要关注这个:
x = 2;
y = 3;也就是要把数字2和3,分别放到x和y对应的内存区域中去。很简单,我们可以这么做:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax也就是先把2扔到寄存器eax中去,然后把eax中的内容放回到x对应的内存中。同理,y也这样处理。
好了,接下来的加法语句:
z = x + y;也可以做了:
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax好了,这段代码应该可以看懂吧,简单说一下思路:
- 把x和y对应的内存中的内容分别放到eax和ebx中去
- 进行形如eax = eax + ebx的加法,最终的和存放在eax中
- 再将eax中的内容存放到z对应的内存中去
最后,我们还有一个事情需要处理,也就是返回语句:
return z;这个也很好办,按照约定,eax中的值,就是函数的返回值:
mov eax, [z]
ret整个程序就算完了,我们已经完整地将C代码的汇编语言等价形式写出来了,最终的代码是这样的:
global main
main:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0来先保存成文件test02.asm,编译运行看看效果:
$ nasm -f elf test02.asm -o test02.o
$ gcc -m32 test02.o -o test02
$ ./test02 ; echo $?
5搞定。结果完全和前面的C代码一致。
揭开C程序的庐山真面目
你以为自己YY出等价的汇编代码就完事儿了?图样,接下来我们继续用工具一探究竟,玩真的。
先说一下准备工作,首先有下面两个文件:
test01.c test02.asm其中一个为上面提到的完整C代码,一个为上述完整的汇编代码。然后按照前面的指示,都编译成可执行文件,编译完成后是这样的:
$ gcc -m32 test01.c -o test01
$ nasm -f elf test02.asm -o test02.o
$ gcc -m32 -fno-lto test02.o -o test02
$ ls
test01 test01.c test02 test02.asm test02.o(注意,要按照这里的编译命令来做)
其中的test01是C代码编译出来的,test02是汇编代码编译出来的。
祭出gdb
好,接下来有请我们的大将军gdb登场。
先来看看我们的C编译后的程序,反汇编之后是什么鬼样子:
gdb ./test01然后输入命令查看反汇编代码:
(gdb) set disassembly-flavor intel
(gdb) disas main
Dump of assembler code for function main:
0x080483ed <+0>: push ebp
0x080483ee <+1>: mov ebp,esp
0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2
0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3
0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024
0x0804840a <+29>: mov eax,ds:0x804a028
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov ds:0x804a020,eax
0x08048416 <+41>: mov eax,ds:0x804a020
0x0804841b <+46>: pop ebp
0x0804841c <+47>: ret
End of assembler dump.
(gdb) quit
$好,别急,先退出,我们再看看我们汇编程序的反汇编代码:
gdb ./test02
(gdb) set disassembly-flavor intel
(gdb) disas main
0x080483f0 <+0>: mov eax,0x2
0x080483f5 <+5>: mov ds:0x804a01c,eax
0x080483fa <+10>: mov eax,0x3
0x080483ff <+15>: mov ds:0x804a01e,eax
0x08048404 <+20>: mov eax,ds:0x804a01c
0x08048409 <+25>: mov ebx,DWORD PTR ds:0x804a01e
0x0804840f <+31>: add eax,ebx
0x08048411 <+33>: mov ds:0x804a020,eax
0x08048416 <+38>: mov eax,ds:0x804a020
0x0804841b <+43>: ret
0x0804841c <+44>: xchg ax,ax
0x0804841e <+46>: xchg ax,ax
End of assembler dump.
(gdb) quit好了,我们都看到反汇编代码了。先来检查一下这里test02的反汇编代码,和我们写的汇编代码是不是一致的:
0x080483f0 <+0>: mov eax,0x2
0x080483f5 <+5>: mov ds:0x804a01c,eax
0x080483fa <+10>: mov eax,0x3
0x080483ff <+15>: mov ds:0x804a01e,eax
0x08048404 <+20>: mov eax,ds:0x804a01c
0x08048409 <+25>: mov ebx,DWORD PTR ds:0x804a01e
0x0804840f <+31>: add eax,ebx
0x08048411 <+33>: mov ds:0x804a020,eax
0x08048416 <+38>: mov eax,ds:0x804a020
0x0804841b <+43>: ret直接和前面写的汇编进行比对便是,由于格式问题,里面的部分地址和标签已经面目全非,但是我们只要能够辨识出来就行了,不需要全部都搞得明明白白。这是前面的汇编代码:
mov eax, 2
mov [x], eax
mov eax, 3
mov [y], eax
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret数一下行数就知道,是相同的。再仔细看看每一条指令,基本也是差不多的。当然x、y、z这些东西不见了,变成了一些奇奇怪怪的符号,在此暂不深究。
我们再看看C程序的汇编代码:
0x080483ed <+0>: push ebp
0x080483ee <+1>: mov ebp,esp
0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2
0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3
0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024
0x0804840a <+29>: mov eax,ds:0x804a028
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov ds:0x804a020,eax
0x08048416 <+41>: mov eax,ds:0x804a020
0x0804841b <+46>: pop ebp
0x0804841c <+47>: ret 这里,先撇开下面几个指令(这几个指令本身是有用的,但是在这个例子里,可以暂时先去掉,具体它们是干啥的,后面说),去掉它们:
push ebp
mov ebp, esp
....
pop ebp于是C程序反汇编变成了这样子:
0x080483f0 <+3>: mov DWORD PTR ds:0x804a024,0x2
0x080483fa <+13>: mov DWORD PTR ds:0x804a028,0x3
0x08048404 <+23>: mov edx,DWORD PTR ds:0x804a024
0x0804840a <+29>: mov eax,ds:0x804a028
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov ds:0x804a020,eax
0x08048416 <+41>: mov eax,ds:0x804a020
0x0804841c <+47>: ret还是看起来不太明朗,怎么办?我们追踪里面的数字2、3和add指令,把那些稀奇古怪的符号换成我们认识的标签x、y、z再看看:
0x080483f0 <+3>: mov [x],0x2
0x080483fa <+13>: mov [y],0x3
0x08048404 <+23>: mov edx,[x]
0x0804840a <+29>: mov eax,[y]
0x0804840f <+34>: add eax,edx
0x08048411 <+36>: mov [z],eax
0x08048416 <+41>: mov eax,[z]
0x0804841c <+47>: ret对比前面我们自己写的汇编代码看看呢?是不是基本是八九不离十了?仅仅有两个地方不一样:1. 使用的寄存器顺序不太一样,但是这个无妨;2. 有两条汇编指令,在C编译后的反汇编代码中对应的是一条指令。
这里我们发现了,原来
mov eax, 2
mov [x], eax可以被精简为一条语句:
mov [x], 2好的,按照C编译器给我们提供的信息,我们的汇编程序还可以简化成这样:
global main
main:
mov [x], 0x2
mov [y], 0x3
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0然而,当我们把汇编写成这样自己编译的时候,却出错了,这里并不能完全这么写,得做一些小修改,把前两条指令改成:
mov dword [x], 0x2
mov dword [y], 0x3这样再编译,就没有问题了。通过研究,我们用汇编写出了和前面的C程序编译后代码等价的汇编程序:
global main
main:
mov dword [x], 0x2
mov dword [y], 0x3
mov eax, [x]
mov ebx, [y]
add eax, ebx
mov [z], eax
mov eax, [z]
ret
section .data
x dw 0
y dw 0
z dw 0总结
好了,到这里,我们通过nasm、gcc和gdb,将一个简单的C程序,用汇编语言等价地实现出来了。
说一下这一段内容的重点:
- C程序在编译阶段,在逻辑上,会被转化成等价的汇编程序
- 汇编程序经过编译器内置(或外置)的汇编器,编译成机器指令(到可执行文件的过程中还有一个链接阶段,后面再提)
- 我们可以通过gdb反汇编得知一个C程序的汇编形式
其实,学习汇编语言的目的,并非主要是为了今后用汇编语言编程,而是借助于对汇编语言的理解,进一步地去理解高级语言在底层的一些细节,一个C语言的赋值语句,一个C语言的加法表达式,在编译后运行的时候,到底在做些什么。也就是通过汇编认识到计算机中,程序执行的时候到底在做些什么,CPU到底在干什么,借助于此,理解计算机程序在CPU眼里的本质。
后续通过这个,结合各种资料学习汇编语言,将是一个非常不错的选择。在对汇编进行实践和理解的过程中,也能更清楚地知道C语言里的各种写法,到底代表什么含义,加深对C语言的认识。
废话
本节内容涉及的代码和操作就多一些了,当然能够耐心做完是最好的,一天两天不够就三天五天,也是值得的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号