Python 应用工具类 爬取 新型冠状病毒的实时确诊信息【上篇】(2020年寒假小目标10)
日期:2020.02.09
博客期:149
星期日
爬取网址:人民网 (其实我真的不喜欢爬政府相关的网站,这感觉贼难受)、百度的信息报告(推荐)或直接去找 国家卫健委公布的全天疫情数据
1、先来看看网页信息:

可以知道我们数据库里要存储那些数据...
整理成 Bean 类型:
(属性解释) (属性名称) (属性类型)
所在城市-------------------------------------------------- city----------------------------------------------string
所在城市上一级----------------------------------------- province---------------------------------------string
数据更新时间-------------------------------------------- date---------------------------------------------date
确诊人数-------------------------------------------------- confirms----------------------------------------int
治愈人数-------------------------------------------------- cures--------------------------------------------int
死亡人数-------------------------------------------------- deaths------------------------------------------int
但是由于有的地方人数还没有,所以我们需要将数据处理为 int 类型( 如果得到 - ,那就将其归为0)
2、之后我们分析一下网页的 HTML 代码:
2.1 所在城市上一级怎么爬?
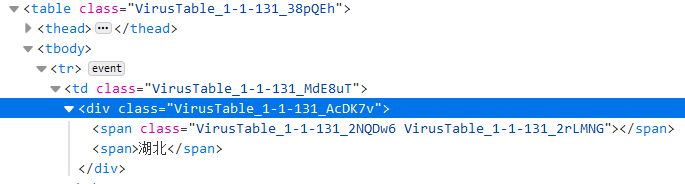
由上图我们知道, “湖北” 应该由 CSS 选择器 提供 .VirusTable_1-1-131_38pQEh ( 选择出 table 来 ),然后对应 .VirusTable_1-1-131_AcDK7v .VirusTable_1-1-131_AcDK7v 来筛选 对应 CSS 的 div 标签,最后选择 span 标签,并去除掉第一项数据。
实际应用中,我们不需要这样爬,因为我们做的数据之间是有关联的。
2.2 数据更新时间怎么爬?
这个应该是最好爬的,直接网页导入,获取HTML后观察
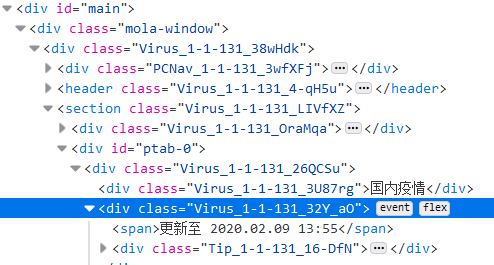
发现要爬墙的数据为 更新至 2020.02.09 13:55,所以应该是 #ptab-0获取 div ,接着 .Virus_1-1-131_32Y_aO 获取子项 div ,然后 查找第一个 span 即可。
2.3 剩余数据如何爬取
我们先要爬到网页中的基础项——由地区、确诊人数、治愈人数、死亡人数构成的四元组。

四元组对应上图,“浙江”、“1075”、“185”和“-”
经过代码分析可以得到

3、之后制作第三部分(使用 selenium 方式爬取)
先参考我上一期博客,知道我用的方法,然后上网(或B站)了解 Python 爬取过程。
预备代码
# 内部需求
def inload(stri):
name = str(stri)
name = StrSpecialDealer.deleteRe(name)
name = StrSpecialDealer.simpleDeal(name)
return name
这部分的功能是将字符串一次性处理完成(当然是去除 \n \t 和 所有的标签啦! )
# 输出顺序
link = ["province","city","date","confirms","cures","deaths"]
wsc = WebSelConnector()
wsc.__pageToURL__("https://voice.baidu.com/act/newpneumonia/newpneumonia/?from=osari_pc_3#tab3")
这是变量提前实例化
# 做预处理--------------如果不想做预处理,想做半自动可以使用 time.sleep(60) 暂停线程
div_need_click = wsc.run_tag.find_elements_by_css_selector(".VirusTable_1-1-134_2NQDw6")
num = div_need_click.__len__()
print(num)
# 嗯?你说为什么从 1 开始?因为 0 代表的是 湖北 ,湖北是登进去以后就默认打开的,你再 click 它一下,它不就关上了吗?这样就没湖北省城市数据了呀!
for i in range(1,num):
# 这里用 try 是为了包括“香港”、“澳门”、“台湾”在内的特殊 div 标签无法调用 click 事件的问题的解决
try:
div_need_click[i].click()
except:
pass
嗯,你运行上边的代码 40 % 不会成功,因为要爬取的网页的 CSS 是动态设定的,隔一段时间对应的 CSS 选择器就爬不到所有的数据了,进而爬取失败,大家可以使用 time.sleep(60) 代码来暂停 60 s ,自己将一系列的列表展开,然后等待爬取(这个半自动爬取小技巧,个人自创,随意使用)。目前我还没有找到可以不用 .class 的选择器进行筛选的方法,有的话会补充在下面!
# 确定存储容器
b = Bean()
b.group['province'] = ""
b.group['city'] = ""
b.group['date'] = ""
b.group['confirms'] = ""
b.group['cures'] = ""
b.group['deaths'] = ""
声明一个 Bean 容器,用来存放文件里的一行数据(六元组)
# 开爬!!!
sel = wsc.getNercol()
str_t = sel.css("#ptab-0")[0].css("div div div span")[0].extract()
str_t = inload(str_t)
str_t = str_t.replace("更新至","")
str_t = str_t.replace(".","-").replace(":",".")
str_t = str_t[0:10] + " " + str_t[10:str_t.__len__()]
b.group['date'] = str_t.replace(".",":")
sw = StringWriter("../testFile/xg/"+str(str_t)+".txt")
sw.makeFileNull()
groups = sel.css("#ptab-0")[0].css("div div div table").css("tbody tr")
num = groups.__len__()
moped = ""
for i in range(0,num):
selected = groups[i]
# 第一步 try 过滤 每个省的所有数据对应表
try:
moped = selected.css("table").extract()[0]
continue
except:
selected = selected.css("td")
try:
selected[0].css("span").extract()[1];
# 是 省级 单位
name = inload(selected.extract()[0])
b.group['province'] = name
if name.__eq__("香港") | name.__eq__("澳门") | name.__eq__("台湾"):
b.group['city'] = inload(str(selected[0].extract()))
b.group['confirms'] = inload(str(selected[1].extract()))
b.group['cures'] = inload(str(selected[2].extract()))
b.group['deaths'] = inload(str(selected[3].extract()))
sw.write(b.__toStrSS__(link=link))
except:
try:
# 是 城市级 单位
b.group['city'] = inload(str(selected[0].extract()))
b.group['confirms'] = inload(str(selected[1].extract()))
b.group['cures'] = inload(str(selected[2].extract()))
b.group['deaths'] = inload(str(selected[3].extract()))
sw.write(b.__toStrSS__(link=link))
except:
pass
# print(selected.extract())
# Do Nothing ...
这一部分是具体爬的部分,你们也可以根据不同的结构做不同的 CSS选择器 爬取设计!我特定地把 CSS 选择器设定成 没有 .class #id 的形式,就是为了以 “不变应万变”!
还有就是数据处理,有的地方还没有某种人数,所以它给出的标识是 - !但是我们处理数据就要讲 这三项数据中 - 替换成 0 !这样才合理!(入库前的数据处理)
这三句(六句)后面加上 .replace("-","0")
b.group['confirms'] = inload(str(selected[1].extract())).replace("-","0")
b.group['cures'] = inload(str(selected[2].extract())).replace("-","0")
b.group['deaths'] = inload(str(selected[3].extract())).replace("-","0")
还有我发现会重复一整边的数据?!!标识着 西藏-武汉 !这 ... 不科学!所以在那里(sw.write() 前面【理论上只加在 城市数据那里就行了,不用加两边】)补充上以下代码,用于跳出循环!
if("武汉".__eq__(b.group['city'])&"西藏".__eq__(b.group['province'])):
break
最后别忘了关闭浏览器就行了
wsc.__close__()
需要设置定时爬取的话,可以将上述代码封装成 main 函数,然后 以 time.Sleep() 方法来定时!
def execute():
while 1 + 1 == 2:
# 10 分钟间隔
for i in range(0,600):
time.sleep(1)
print("距离下一次爬取还有"+str(600-i)+"秒!")
print("开始爬取...")
main()
print("爬取结束...")
注意把之前 main 函数里的 print(num) 一句注释掉,否则输出影响美观 ... ...
4、开始爬取并准备好数据
文件命名规则就是爬虫时的网页最后的更新时间!
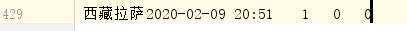
上面是暂时爬到的数据,过一段时间接着爬!
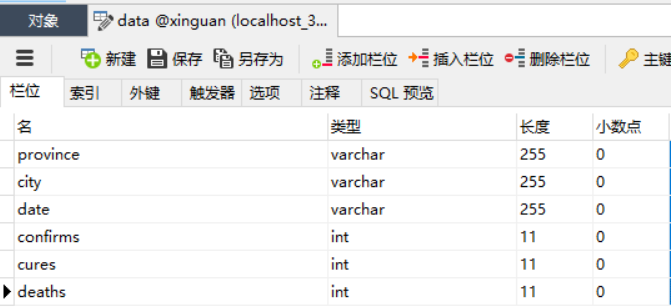
5、导入数据库
如图设计数据库:
右击鼠标 data表 选择 导入向导,以 txt(文本文件)方式导入
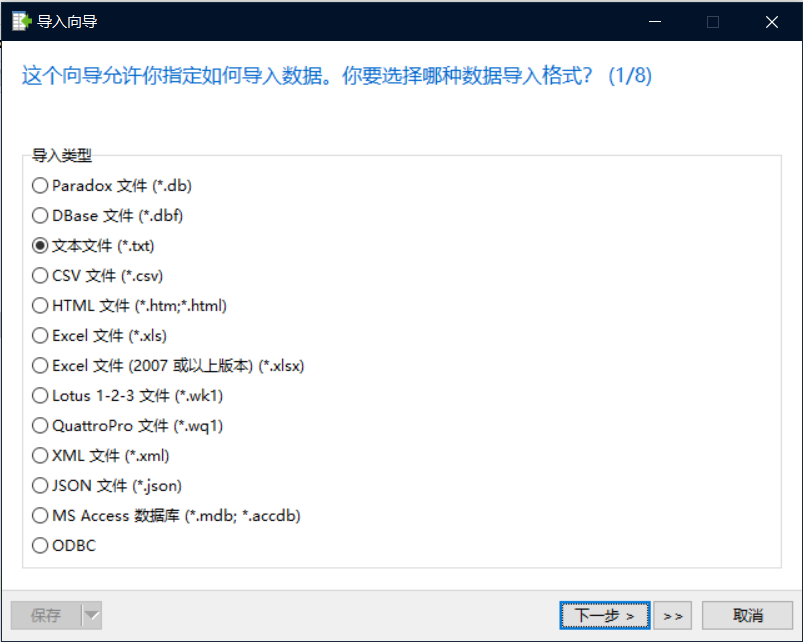
选择目录文件,之后设置 文本限定符 为 无

还有就是,注意表的配置:

最后,对应好表中数据项,选择添加:
设置对应项:f1 f2 f3 f4 f5 f6
![]()
![]()
6、做好数据库备份(以免第二天爬取的数据有问题)
鼠标右击数据库,选择转存SQL文件(数据和结构),之后导出成文件包。
记着每一个文件都将数据导入一次且仅一次,如果记不住就给表设计上 主键 ------- 城市 + 时间
//----------------【2020-02-12 补充】
我找到了那个类动态变化是怎样变化的,就是隔一段时间它就会自动加一,那么我们需要做的就是测试并找到那个数字,怎样可以找到呢?
# 做预处理--------------如果不想做预处理,想做半自动可以使用 time.sleep(60) 暂停线程
tmp = 141
div_need_click = wsc.run_tag.find_elements_by_css_selector(".VirusTable_1-1-"+str(tmp)+"_2NQDw6")
num = div_need_click.__len__()
while num == 0:
tmp = tmp + 1
div_need_click = wsc.run_tag.find_elements_by_css_selector(".VirusTable_1-1-" + str(tmp) + "_2NQDw6")
num = div_need_click.__len__()
print(num)
将原来 div_need_click 和 num 的赋值部分,替换成以上代码!
我就是要找到那个数值,哦,对了,那个 print(num) 本来应该是 print(tmp) 的,只不过要不要都可以啦!
【END】
