

Python 爬取 北京市政府首都之窗信件列表-[数据处理]
日期:2020.01.24
博客期:132
星期五
【代码说明,如果要使用此页代码,必须在本博客页面评论区给予说明】
//博客总体说明
1、准备工作
2、爬取工作
3、数据处理(本期博客)
4、信息展示
好了今天是除夕,先给大家说句吉利话,“祝大家打代码代代顺利,码码成功”!我因为回家了,今天没做太多东西... ...呼~
登录虚拟机,启动hadoop和hive,准备做数据处理部分!
//建数据库的语句 create table govdata( kind string, asker string, responser string, asktime string, responsetime string, title string, questionSupport int, responseSupport string, responseUnsupport string, questiontext string, responsetext string ) row format delimited fields terminated by '\t';
处理如下:

之后通过文件导入数据(以"\t"为分隔符进行数据导入):
//从路径为"/data/edu3/govdata"的文件导入数据 load data local inpath '/data/edu3/govdata' into table govdata;
处理如下:

之后对应需求部分的处理正在进行
下面是对数据库的测试:

之后使用文件导入方式导入到mysql (因为是以\t为分隔符所以对应以下代码)
LOAD DATA INFILE 'E:\\课件\\3-2\\大数据\\大三寒假作业\\2020-01-23\\datas.txt' INTO TABLE govdata FIELDS TERMINATED BY '\t' LINES TERMINATED BY '\n'
导入以后分别使用sql语句去建立三个需求的表:
CREATE table kinddata As ( select kind as kind, count(1) as num from govdata group by kind order by num desc ); CREATE table yeardata AS ( select SUBSTRING(asktime,1,4) as dt, count(*) as num from govdata group by dt ) ; CREATE table responserdata AS ( select gd.responser as responser, count(*) as num from govdata gd group by responser order by num desc );
得到数据表(可以提供制作网页的数据):

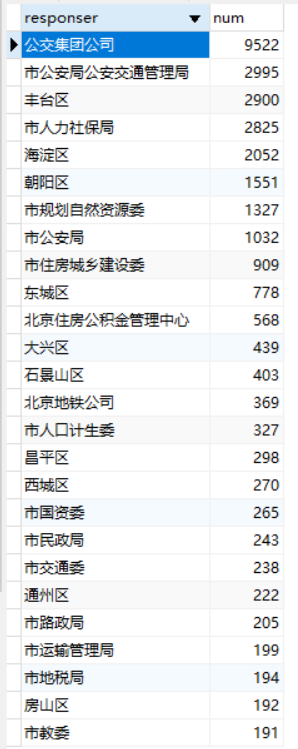

这分别对应的是每年的信件量,回答方对应的信件数,和不同类型的信件数

