

Python 爬取 北京市政府首都之窗信件列表-[Scrapy框架](2020年寒假小目标04)
日期:2020.01.22
博客期:130
星期三
【代码说明,如果要使用此页代码,必须在本博客页面评论区给予说明】
//博客总体说明
1、准备工作(本期博客)
2、爬取工作
3、数据处理
4、信息展示
今天来说一说爬取的工作进展,我们的要求是爬取首都之窗的信件类型,那么我们就开始吧!
首先,先找到网页:http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.flow
然后找到网页的结构,发现是简单的HTML结构,那我们就可以启动Scrapy框架了。
前边说了,之前是一直报403 Forbidden的错,原因我已经找到了!因为广大运营网站不可能希望各个程序员都能够轻易爬走自己的数据,那么怎么办呢?诶~他就对每个请求访问的用户进行检查,发现有一类用户什么都没有,就是想访问,网站一看到这种用户心里可真不是滋味,就会断定“你是来爬我的数据的”,你自然就被网站服务器禁掉了!人家有了“政策”,我们程序员就要想对策是吧!诶,我们可以在爬取的时候,模拟添加一个header,让服务器误认为我们是人,我们应该得到数据!

进行改造:(这是截图没有错,到时候我会给你们代码的)

嗯,现在服务器终于肯乖乖听话了!
先来看我们的基础数据类型:

由此我们可以构造基础的 Bean 类型了(为了方便引入,我就使用Bean当作类名了)
看代码:


1 # [ 保存的数据格式 ] 2 class Bean: 3 4 # 构造方法 5 def __init__(self,asker,responser,askTime,responseTime,title,questionSupport,responseSupport,responseUnsupport,questionText,responseText): 6 self.asker = asker 7 self.responser = responser 8 self.askTime = askTime 9 self.responseTime = responseTime 10 self.title = title 11 self.questionSupport = questionSupport 12 self.responseSupport = responseSupport 13 self.responseUnsupport = responseUnsupport 14 self.questionText = questionText 15 self.responseText = responseText 16 17 # 在控制台输出结果(测试用) 18 def display(self): 19 print("提问方:"+self.asker) 20 print("回答方:"+self.responser) 21 print("提问时间:" + self.askTime) 22 print("回答时间:" + self.responseTime) 23 print("问题标题:" + self.title) 24 print("问题支持量:" + self.questionSupport) 25 print("回答点赞数:" + self.responseSupport) 26 print("回答被踩数:" + self.responseUnsupport) 27 print("提问具体内容:" + self.questionText) 28 print("回答具体内容:" + self.responseText) 29 30 def toString(self): 31 strs = "" 32 strs = strs + self.asker; 33 strs = strs + "\t" 34 strs = strs + self.responser; 35 strs = strs + "\t" 36 strs = strs + self.askTime; 37 strs = strs + "\t" 38 strs = strs + self.responseTime; 39 strs = strs + "\t" 40 strs = strs + self.title; 41 strs = strs + self.questionSupport; 42 strs = strs + "\t" 43 strs = strs + self.responseSupport; 44 strs = strs + "\t" 45 strs = strs + self.responseUnsupport; 46 strs = strs + "\t" 47 strs = strs + self.questionText; 48 strs = strs + "\t" 49 strs = strs + self.responseText; 50 return strs 51 52 # 将信息附加到文件里 53 def addToFile(self,fpath, model): 54 f = codecs.open(fpath, model, 'utf-8') 55 f.write(self.toString()+"\n") 56 f.close() 57 58 # --------------------[基础数据] 59 # 提问方 60 asker = "" 61 # 回答方 62 responser = "" 63 # 提问时间 64 askTime = "" 65 # 回答时间 66 responseTime = "" 67 # 问题标题 68 title = "" 69 # 问题支持量 70 questionSupport = "" 71 # 回答点赞数 72 responseSupport = "" 73 # 回答被踩数 74 responseUnsupport = "" 75 # 问题具体内容 76 questionText = "" 77 # 回答具体内容 78 responseText = ""
//-------[代码解析]
这算是一个中介者,沟通着数据与展示或者数据与文件,这个类相当于是对数据的处理的方法封装
... ...
忘了展示字符串的标签处理封装类了:
1 # [ 对字符串的特殊处理方法-集合 ] 2 class StrSpecialDealer: 3 @staticmethod 4 def getReaction(stri): 5 strs = str(stri).replace(" ","") 6 strs = strs[strs.find('>')+1:strs.rfind('<')] 7 strs = strs.replace("\t","") 8 strs = strs.replace("\r","") 9 strs = strs.replace("\n","") 10 return strs
嗯,之后我们需要想如何根据网页地址来获取html
比如给定了原网站当中的其中一条比如对应网页:
需要我们制作一个对应的网站爬取结点类(它的任务是对于已经给定的网页,进行爬取,并封装成我们上述的Bean类型)
看代码:(省略导包...)
1 # [ 信息爬取结点 ] 2 class DetailConnector: 3 headers = { 4 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'} 5 basicURL = "" 6 7 # ---[定义构造方法] 8 def __init__(self, url): 9 self.basicURL = url 10 11 # 获取 url 的内部 HTML 代码 12 def getHTMLText(self): 13 req = request.Request(url=self.basicURL, headers=self.headers) 14 r = request.urlopen(req).read().decode() 15 return r 16 17 # 获取基本数据 18 def getBean(self): 19 index_html = self.getHTMLText() 20 index_sel = parsel.Selector(index_html) 21 container_div = index_sel.css('div .container')[0] 22 container_strong = index_sel.css('div strong')[0] 23 container_retire = index_sel.css('div div div div')[5] 24 25 #基础数据配置 26 title = " " 27 num_supp = " " 28 question_toBuilder = " " 29 question_time = " " 30 support_quert = " " 31 quText = " " 32 answer_name = " " 33 answer_time = " " 34 answer_text = " " 35 num_supp = " " 36 num_unsupp = " " 37 38 #------------------------------------------------------------------------------------------提问内容 39 # 获取提问标题 40 title = str(container_strong.extract()) 41 title = title.replace("<strong>", "") 42 title = title.replace("</strong>", "") 43 44 # 获取来信人 45 container_builder = container_retire.css("div div") 46 question_toBuilder = str(container_builder.extract()[0]) 47 question_toBuilder = StrSpecialDealer.getReaction(question_toBuilder) 48 if (question_toBuilder.__contains__("来信人:")): 49 question_toBuilder = question_toBuilder.replace("来信人:", "") 50 51 # 获取提问时间 52 question_time = str(container_builder.extract()[1]) 53 question_time = StrSpecialDealer.getReaction(question_time) 54 if (question_time.__contains__("时间:")): 55 question_time = question_time.replace("时间:", "") 56 57 # 获取网友支持量 58 support_quert = str(container_builder.extract()[2]) 59 support_quert = support_quert[support_quert.find('>') + 1:support_quert.rfind('<')] 60 support_quert = StrSpecialDealer.getReaction(support_quert) 61 62 # 获取问题具体内容 63 quText = str(index_sel.css('div div div div').extract()[9]) 64 if(quText.__contains__("input")): 65 quText = str(index_sel.css('div div div div').extract()[10]) 66 quText = quText.replace("<p>", "") 67 quText = quText.replace("</p>", "") 68 quText = StrSpecialDealer.getReaction(quText) 69 70 # ------------------------------------------------------------------------------------------回答内容 71 try: 72 # 回答点赞数 73 num_supp = str(index_sel.css('div a span').extract()[0]) 74 num_supp = StrSpecialDealer.getReaction(num_supp) 75 # 回答不支持数 76 num_unsupp = str(index_sel.css('div a span').extract()[1]) 77 num_unsupp = StrSpecialDealer.getReaction(num_unsupp) 78 # 获取回答方 79 answer_name = str(container_div.css("div div div div div div div").extract()[1]) 80 answer_name = answer_name.replace("<strong>", "") 81 answer_name = answer_name.replace("</strong>", "") 82 answer_name = answer_name.replace("</div>", "") 83 answer_name = answer_name.replace(" ", "") 84 answer_name = answer_name.replace("\t", "") 85 answer_name = answer_name.replace("\r", "") 86 answer_name = answer_name.replace("\n", "") 87 answer_name = answer_name[answer_name.find('>') + 1:answer_name.__len__()] 88 # ---------------------不想带着这个符号就拿开 89 if (answer_name.__contains__("[官方回答]:")): 90 answer_name = answer_name.replace("[官方回答]:", "") 91 # 答复时间 92 answer_time = str(index_sel.css('div div div div div div div div')[2].extract()) 93 answer_time = StrSpecialDealer.getReaction(answer_time) 94 if (answer_time.__contains__("答复时间:")): 95 answer_time = answer_time.replace("答复时间:", "") 96 # 答复具体内容 97 answer_text = str(index_sel.css('div div div div div div div')[4].extract()) 98 answer_text = StrSpecialDealer.getReaction(answer_text) 99 answer_text = answer_text.replace("<p>", "") 100 answer_text = answer_text.replace("</p>", "") 101 except: 102 pass 103 104 bean = Bean(question_toBuilder, answer_name, question_time, answer_time, title, support_quert, num_supp, 105 num_unsupp, quText, answer_text) 106 107 return bean
此代码对应测试代码
dc = DetailConnector("http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId=AH20012200024")
dc.getBean().display()
测试结果:
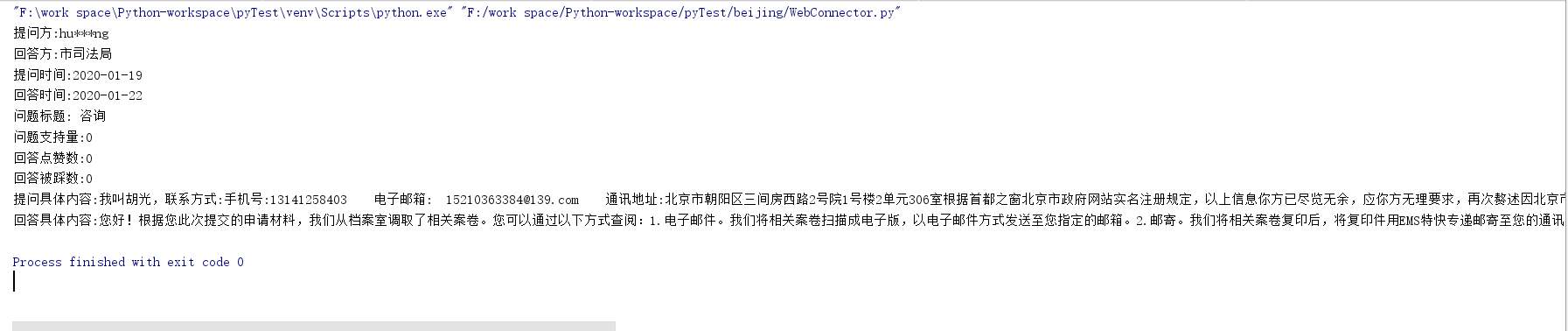
里面用到了CSS选择器的使用
CSS选择器的使用方法(参考网页):https://www.w3school.com.cn/cssref/css_selectors.ASP
但是有了这一部分还是不行,我们需要从原网站找到对应网站的链接地址!
而且从第123期博客,我们可以知道:对应链接的onclick事件的两个参数分别对应的跳转地址关系,所以我们看:
1 # [ 网页爬取的直接对象 ] 2 class WebConnector: 3 4 basicURL = "http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.flow" 5 headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.75 Safari/537.36'} 6 7 # ---[定义构造方法] 8 def __init__(self): 9 pass 10 11 # 获取 url 的内部 HTML 代码 12 def getHTMLText(self): 13 req = request.Request(url=self.basicURL, headers=self.headers) 14 r = request.urlopen(req).read().decode() 15 return r 16 17 # 获取页面内的基本链接 18 def getFirstChanel(self): 19 index_html = self.getHTMLText() 20 index_sel = parsel.Selector(index_html) 21 links = index_sel.css('div #mailul').css("a[onclick]").extract() 22 inNum = links.__len__() 23 for seat in range(0, inNum): 24 # 获取相应的<a>标签 25 pe = links[seat] 26 # 找到第一个 < 字符的位置 27 seat_turol = str(pe).find('>') 28 # 找到第一个 " 字符的位置 29 seat_stnvs = str(pe).find('"') 30 # 去掉空格 31 pe = str(pe)[seat_stnvs:seat_turol].replace(" ","") 32 # 获取资源 33 pe = pe[14:pe.__len__()-2] 34 pe = pe.replace("'","") 35 # 整理成 需要关联数据的样式 36 mor = pe.split(",") 37 # ---[ 构造网址 ] 38 url_get_item = ""; 39 # 对第一个数据的判断 40 if(mor[0]=="咨询"): 41 url_get_item = "http://www.beijing.gov.cn/hudong/hdjl/com.web.consult.consultDetail.flow?originalId=" 42 else: 43 if(mor[0]=="建议"): 44 url_get_item = "http://www.beijing.gov.cn/hudong/hdjl/com.web.suggest.suggesDetail.flow?originalId=" 45 url_get_item = url_get_item + mor[1] 46 47 model = "a+" 48 49 if(seat==0): 50 model = "w+" 51 52 dc = DetailConnector(url_get_item) 53 dc.getBean().addToFile("../testFile/emails.txt",model)
此代码对应测试代码:
wc = WebConnector() wc.getFirstChanel()
测试结果是将默认得到的第一页的内容爬取到文件email.txt里(分隔符为制表符 "\t" )

但是这还是没有结束,因为这只有默认的6条数据,如何继续爬取剩下的5624-1页的数据呢?
我目前找到了它传输数据的JSON包(附链接:http://www.beijing.gov.cn/hudong/hdjl/com.web.search.mailList.mailList.biz.ext)
截图如下:
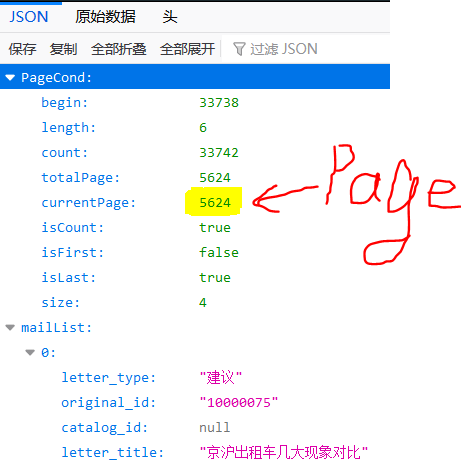
PS:前面那期博客内容应该是不全的,因为爬到第27页才出来一个特殊的页面:(居然还有投诉类型的?!!)

投诉类型对应页面前缀为http://www.beijing.gov.cn/hudong/hdjl/com.web.complain.complainDetail.flow?originalId=
