DL-卷积神经网络的一些总结
来源于课程:http://www.tensorinfinity.com/index.php?r=space/viewmedia&lesson_id=105&id=1162
1 总体层次
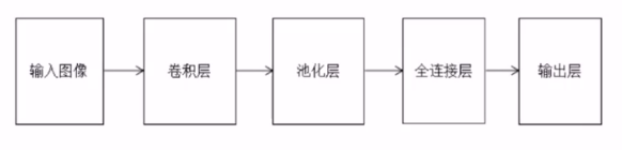
通常就是由输入(一般是矩阵形式的图像数据)、卷积运算层、池化层(下采样技术)、全连接层、输出层,等层次结构组成,其它一些应用网络通常是在此基础上有所层次增减变化。
2 输入层表示
通常卷积神经网络用于图像处理,如果是灰度图像就只有一个值在0-255的矩阵,如果是彩色图像,通常是3个这样的矩阵数据;
而输入大小是需要固定的,比如训练的时候,所用矩阵大小是1000x1000,测试的时候、预测的时候,缩放到这个大小才能进行映射预测,因为每一层操作后都可能变化图像的尺寸,而后面全连接层是固定的比如10个神经元,那么尺寸不同则无法适应后面的全连接层神经元大小。
3 卷积层操作
经过卷积运算图像尺寸变小了,原始是mxn的话,卷积核sxs,卷积后尺寸为:(m-s+1)x(n-s+1)。
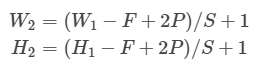
W2是卷积后Feature Map的宽度;W1是卷积前图像的宽度;F是filter的宽度;P是Padding数量,如果P的值是1,那么就补1圈0;S是步幅;H2是卷积后Feature Map的高度;H1是卷积前图像的宽度
一般,还可以padding操作,周围填充0,对图像进行扩展,更好的提取边缘特征。
卷积核尺寸一般行列相等,其为奇数。步长一般为1。
3.1 卷积核映射方式,正向传播:(其中f为激活函数)
卷积核大小sxs,那么卷积计算后的图像第i行第j个元素为:(第l-1层到l层)

计算形式:
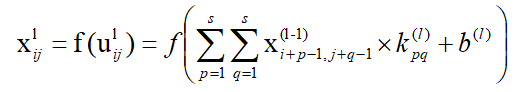
如:


3.2 反向传播
卷积层反向传播需要考虑2个操作:卷积核参数更新,向前一层传递误差。
卷积核要作用于同一个图像的多个不同位置,因此,误差对卷积核参数k求导这样:

第二个乘积项:
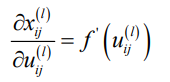
第三个乘积项:
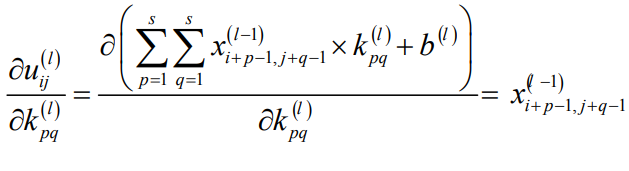
得到卷积核的偏导数计算公式:
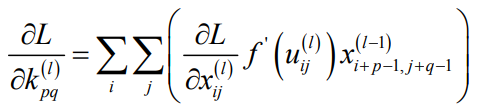
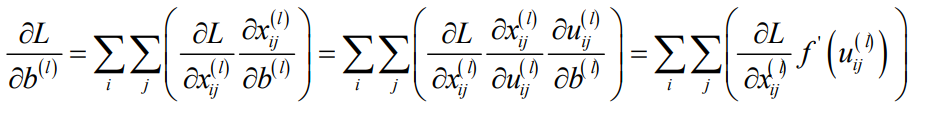
定义误差项:
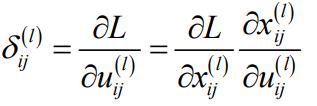
则上面的偏导数:
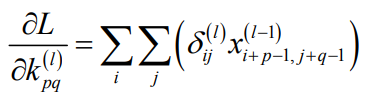
误差项矩阵,尺寸和卷积输出图像相同:
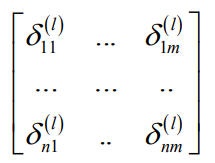
具体例子:
1)卷积核矩阵:

2)卷积输入图像
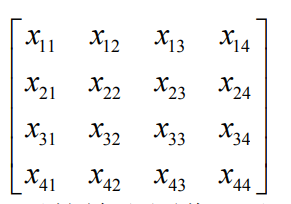
3)卷积之后的输出图像
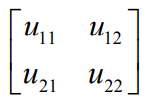
4)输出项分别对应的误差项
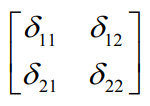
5)对卷积核的偏导数
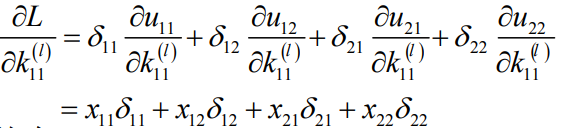

6)可记为卷积形式:
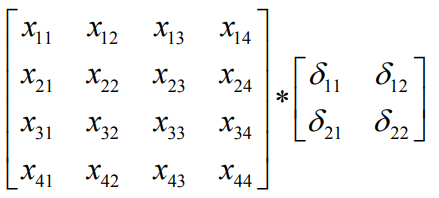
对卷积核参数k的求导即为:
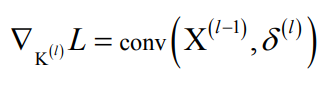
3.3 误差项的递推:

对x11:
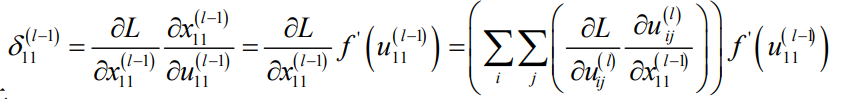

对x12:

太麻烦了,总之这么一个个算,就这么得到了规律:(左边,把后一层的误差四周padding 2层)

误差项的递推公式满足:(右边,卷积核依照正对角线折叠了)
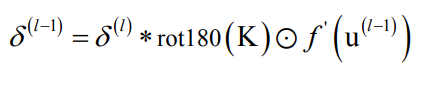
这样,就得到了后一层送过来的误差,再往前一层传递误差的的流程。
3.4 多通道
如彩色图像通常有3个矩阵输入,如下中间用4个3层卷积核操作映射图像,然后每个卷积核的3层合并(对应的3个加一起)成一层,最后输出为1个4通道的抽象图像

4 池化层
卷积操作维度下降还是太慢了,池化层能快速下降图像维度,池化操作(下采样)把图像的某一小部分区域用一个值替代:最大值(max池化,非线性,用的多)、平均值(均值池化)

好处:一小部分微小扰动旋转、平移,对性能影响不大;没有参数。
注意:需要池化核大小,步长等设定
4.1反向传播

1)均值池化
只需要传播误差项,没有参数需要更新。
(就是把后面传来的误差,里面的每个误差元素,扩充成一个sxs的同样误差的矩阵,原来k个不同的误差传来,就把k个误差每个扩展成一个sxs矩阵,成为一个更大的误差矩阵,里面有k个sxs的误差小矩阵)

2)max池化
同样要和均值一样,把后面传来的误差扩充成sxs的矩阵,不过,不是全部一样,而是只把前面最大值位置对应的位置那个误差传递到前面去,其它都是0。

5 全连接层
把最后的矩阵形式的图像数据,拉成一维向量,其它像神经网络那样操作,反向传播也是一样的。
6 完整的正反传播

7 注意
一般参数为随机化,均匀分布,正态分布,然后用神经元数量做归一化。
梯度下降中更新参数的负梯度的缩放因子,不能太大或太小,10-4,一般动态调整,前多少时大一点,后面慢慢减少。
8 一些改进的梯度下降法
8.1动量项
V中记录了以前所有的梯度信息,第1次时为0

8.2 AdaGrad
优化对象的每一个分量都有自己的学习率
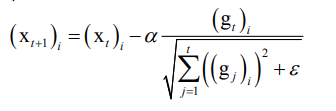
历史导数(gj)绝对值越大分量学习率越小。
缺点:需要人工指定全局学习率,后面分母越来越大,学习率趋于0,无法更新
8.3 RMSProp
是对AdaGrad的改进,对AdaGrad中分母的梯度平方和加入了衰减因子
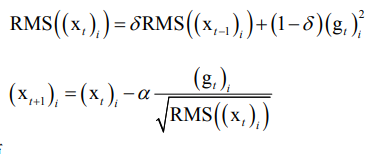
8.4 AdaDelta
也是对AdaGrad的改进,去掉了人工设定全局学习率

8.5 Adam

8.6 改进总结

9 其它网络
9.1LeNet网络
用了标准的卷积层,池化层,全连接层结构,此后各种卷积网络的设计都借鉴了它的思想。激活函数统一采用tanh;损失函数采用欧氏距离损失函数;求解算法采用梯度下降法;训练样本的类别标签采 用向量编码形式。


layer name kernel size output size
输入层 \ 32x32
卷积层1 5x5 6x28x28
MaxPool1 2x2, stride=2 6x14x14
卷积层2 5x5 16x10x10
MaxPool2 2x2, stride=2 16x5x5
全连接层1 16x5x5 120
全连接层2 120 84
输出层 84 10
9.1.1 Pytorch实现LeNet网络
使用的数据集是MNIST,其中包括6万张28x28的训练样本,1万张测试样本。
1)训练模型并且保存
import torch
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn as nn
import torch.optim as optim
from torch.autograd import Variable
# 定义网络结构
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Sequential( # input_size=(1*28*28)
nn.Conv2d(1, 6, 5, 1, 2), # padding=2保证输入输出尺寸相同
nn.ReLU(), # input_size=(6*28*28)
nn.MaxPool2d(kernel_size=2, stride=2), # output_size=(6*14*14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5),
nn.ReLU(), # input_size=(16*10*10)
nn.MaxPool2d(2, 2) # output_size=(16*5*5)
)
self.fc1 = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.ReLU()
)
self.fc3 = nn.Linear(84, 10)
# 定义前向传播过程,输入为x
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# nn.Linear()的输入输出都是维度为一的值,所以要把多维度的tensor展平成一维
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
# 超参数设置
EPOCH = 3 # 遍历数据集次数
BATCH_SIZE = 32 # 批处理尺寸(batch_size)
LR = 0.001 # 学习率
# 定义数据预处理方式
train_dataset = datasets.MNIST(
root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(
root='./data', train=False, transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# 定义损失函数loss function 和优化方式(采用SGD)
net = LeNet()
criterion = nn.CrossEntropyLoss() # 交叉熵损失函数,通常用于多分类问题上
optimizer = optim.SGD(net.parameters(), lr=LR, momentum=0.9)
# 训练
if __name__ == "__main__":
for epoch in range(EPOCH):
sum_loss = 0.0
# 数据读取
for i, data in enumerate(train_loader, 1):
# 每一次BATCH_SIZE个数据
inputs, labels = data
inputs = Variable(inputs)
labels = Variable(labels)
# 梯度清零
optimizer.zero_grad()
# forward + backward
outputs = net(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 每训练100个batch打印一次平均loss
sum_loss += loss.data[0] * labels.size(0)
if i % 100 == 0:
print('[{}/{}] loss {},curr loss {}: {:.6f}'.format(epoch + 1, EPOCH, i, loss.data[0],
sum_loss / (BATCH_SIZE * i)))
# 每跑完一次epoch测试一下准确率
net.eval()
correct = 0
for data in test_loader:
images, labels = data
images = Variable(images)
labels = Variable(labels)
outputs = net(images)
# 取得分最高的那个类,1:按照列对比,返回两个参数:最大值、最大值索引
# 也可以predicted = torch.max(outputs, 1)[1]
_, predicted = torch.max(outputs, 1)
num_correct = (predicted == labels).sum()
correct += num_correct.data[0]
print('第%d个epoch的识别准确率为:%f' % (epoch + 1, (correct / (len(test_dataset)))))
torch.save(net.state_dict(), './LeNet.pth')
2)加载模型并且可视化预测对比
import torch
import torchvision
from torchvision import transforms
from torchvision import datasets
from torch.utils.data import DataLoader
import torch.nn as nn
from torch.autograd import Variable
import matplotlib.pyplot as plt
# 定义网络结构
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.conv1 = nn.Sequential( # input_size=(1*28*28)
nn.Conv2d(1, 6, 5, 1, 2), # padding=2保证输入输出尺寸相同
nn.ReLU(), # input_size=(6*28*28)
nn.MaxPool2d(kernel_size=2, stride=2), # output_size=(6*14*14)
)
self.conv2 = nn.Sequential(
nn.Conv2d(6, 16, 5),
nn.ReLU(), # input_size=(16*10*10)
nn.MaxPool2d(2, 2) # output_size=(16*5*5)
)
self.fc1 = nn.Sequential(
nn.Linear(16 * 5 * 5, 120),
nn.ReLU()
)
self.fc2 = nn.Sequential(
nn.Linear(120, 84),
nn.ReLU()
)
self.fc3 = nn.Linear(84, 10)
# 定义前向传播过程,输入为x
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
# nn.Linear()的输入输出都是维度为一的值,所以要把多维度的tensor展平成一维,用于全连接
x = x.view(x.size()[0], -1)
x = self.fc1(x)
x = self.fc2(x)
x = self.fc3(x)
return x
# 超参数设置
EPOCH = 3 # 遍历数据集次数
BATCH_SIZE = 32 # 批处理尺寸(batch_size)
LR = 0.001 # 学习率
# 定义数据预处理方式
train_dataset = datasets.MNIST(
root='./data', train=True, transform=transforms.ToTensor(), download=True)
test_dataset = datasets.MNIST(
root='./data', train=False, transform=transforms.ToTensor())
train_loader = DataLoader(train_dataset, batch_size=BATCH_SIZE, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=BATCH_SIZE, shuffle=False)
# ====加载训练模型========
net = LeNet()
net.load_state_dict(torch.load('LeNet.pth'))
# ========加载一个批次32张数据========
dataiter = iter(test_loader)
imgs, labels = next(dataiter)
# ====可视化32个imgs数据集=======
import numpy as np
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
imshow(torchvision.utils.make_grid(imgs))
# ===转成tensor张量
imgs = Variable(imgs)
labels = Variable(labels)
# img:32x1x28x28
# imgs[0:1]是1x1x28x28
# torch.nn包只接受那种小批量样本的数据,而非单个样本[batch,channel,height,width]。
# 因此这里测试一个样本的时候,只能是1x1x28x28,既只能用imgs[0:1]。用imgs[0][0]错误
# 也可以正常思维的选中28x28部分,然后input.unsqueeze(0)这样扩充维度
X, y = imgs[0:1], labels[0]
predict = net(X)
print(torch.max(predict, 1)[1], y)
输出:
Variable containing:
7
[torch.LongTensor of size 1x1]
Variable containing:
7
[torch.LongTensor of size 1]

可见,和真是结果一致。
9.2 AlexNet网络
2012年,Hinton等人设计出一个称为AlexNet的深层卷积神经网络,在图像分类任务上取得了成功。


AlexNet网络的特点 层数更深,参数更多,规模更大 训练样本更多,采用了GPU加速 新的激活函数 ReLU
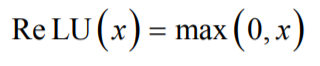
dropout机制:在训练时随机的选择一部分神经元进行正向传播和反向传播,另外一些神经元的参数值保持不变,以减轻过拟合。

扩充数据思想:平翻转图像,从原始图像中随机裁剪、平移变换,颜色、光照变换,一个图片可以阔绰多个来学习。

1)随机裁剪,对256×256的图片进行随机裁剪到224×224,然后进行水平翻转,相当于将样本数量增加了((256-224)^2)×2=2048倍;
(2)测试的时候,对左上、右上、左下、右下、中间分别做了5次裁剪,然后翻转,共10个裁剪,之后对结果求平均。作者说,如果不做随机裁剪,大网络基本上都过拟合;
(3)对RGB空间做PCA(主成分分析),然后对主成分做一个(0, 0.1)的高斯扰动,也就是对颜色、光照作变换,结果使错误率又下降了1%。
https://my.oschina.net/u/876354/blog/1633143
重叠池化 (Overlapping Pooling):一般的池化(Pooling)是不重叠的,池化区域的窗口大小与步长相同。在AlexNet中使用的池化(Pooling)却是可重叠的,也就是说,在池化的时候,每次移动的步长小于池化的窗口长度。AlexNet池化的大小为3×3的正方形,每次池化移动步长为2,这样就会出现重叠。重叠池化可以避免过拟合,这个策略贡献了0.3%的Top-5错误率。
局部归一化(Local Response Normalization,简称LRN):当使用ReLU时这种“侧抑制”很管用,因为ReLU的响应结果是无界的(可以非常大),所以需要归一化。使用局部归一化的方案有助于增加泛化能力。
9.2.1 PyTorch 实现
import torch.nn as nn
from torchvision import models
import numpy as np
from torch.autograd import Variable
import torch
class BuildAlexNet(nn.Module):
def __init__(self, model_type, n_output):
super(BuildAlexNet, self).__init__()
self.model_type = model_type
if model_type == 'pre':
# 直接加载torch提供的alexnet模型
model = models.alexnet(pretrained=True)
self.features = model.features
fc1 = nn.Linear(9216, 4096)
fc1.bias = model.classifier[1].bias
fc1.weight = model.classifier[1].weight
fc2 = nn.Linear(4096, 4096)
fc2.bias = model.classifier[4].bias
fc2.weight = model.classifier[4].weight
self.classifier = nn.Sequential(
nn.Dropout(),
fc1,
nn.ReLU(inplace=True),
nn.Dropout(),
fc2,
nn.ReLU(inplace=True),
nn.Linear(4096, n_output))
# 或者直接修改为
# model.classifier[6]==nn.Linear(4096,n_output)
# self.classifier = model.classifier
if model_type == 'new':
# 在2015年 Very Deep Convolutional Networks for Large-Scale Image Recognition.提到LRN基本没什么用。
self.features = nn.Sequential(
nn.Conv2d(3, 64, 11, 4, 2),
nn.ReLU(inplace=True),
# 池化大小3,步长2,填充0
nn.MaxPool2d(3, 2, 0),
nn.Conv2d(64, 192, 5, 1, 2),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 0),
nn.Conv2d(192, 384, 3, 1, 1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2, 0))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(9216, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, n_output))
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), -1)
out = self.classifier(x)
return out
if __name__ == '__main__':
model_type = 'pre'
n_output = 10
alexnet = BuildAlexNet(model_type, n_output)
print(alexnet)
#各种训练
#保存模型
x = np.random.rand(1, 300, 224, 224)
x = x.astype(np.float32)
x_ts = torch.from_numpy(x)
x_in = Variable(x_ts)
y = alexnet(x_in)
print(y)
9.3 VGG网络
由牛津大学视觉组提出,被广泛应用于视觉领域的各类任务 K. Simonyan and A. Zisserman. Very Deep Convolutional Networks for Large-Scale Image Recognition. international conference on learning representations. 2015
主要创新是:采用了小尺寸卷积核
所有卷积层都使用3x3的卷积核,且卷积步长为1
为了保证卷积后的图像大小不变,对图像进行了填充,四周各填充1个像素
所有池化层都采用2x2的核,步长为2
除了最后一个全连接层之外,所有层都采用了ReLU激活函数
用2个相连的 3x3卷积核可以实现5x5的卷积核
用3个相连的3x3卷积核可以实现7x7的卷积核
小卷积核有更少的参数,能够加速网络的训练和计算,同时可以减轻过拟合问题
两个3x3的卷积核有18个参数(不考虑偏置项),而一个5x5卷积核有25个参数
除了参数减少,用多层小卷积核实现一个大卷积核的另外一个好处是多了几次激活函数,增加了非线性

9.3.1 PyTorch实现
import torch.nn as nn
import torchvision
from torch.autograd import Variable
import torch
import math
import matplotlib.pyplot as plt
import numpy as np
class VGG(nn.Module):
def __init__(self, features, num_classes=10, init_weights=True):
super(VGG, self).__init__()
self.features = features
self.classifier = nn.Sequential(
nn.Linear(512 * 7 * 7, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(True),
nn.Dropout(),
nn.Linear(4096, num_classes),
)
if init_weights:
self._initialize_weights()
def forward(self, x):
x = self.features(x)
x = x.view(x.size()[0], -1)
x = self.classifier(x)
return x
def _initialize_weights(self):
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
if m.bias is not None:
m.bias.data.zero_()
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0, 0.01)
m.bias.data.zero_()
def make_layers(cfg, batch_norm=False):
layers = []
in_channels = 3
for v in cfg:
if v == 'M':
layers += [nn.MaxPool2d(kernel_size=2, stride=2)]
else:
conv2d = nn.Conv2d(in_channels, v, kernel_size=3, padding=1)
if batch_norm:
layers += [conv2d, nn.BatchNorm2d(v), nn.ReLU(inplace=True)]
else:
layers += [conv2d, nn.ReLU(inplace=True)]
in_channels = v
return nn.Sequential(*layers)
cfg = {
'A': [64, 'M', 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'B': [64, 64, 'M', 128, 128, 'M', 256, 256, 'M', 512, 512, 'M', 512, 512, 'M'],
'D': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 'M', 512, 512, 512, 'M', 512, 512, 512, 'M'],
'E': [64, 64, 'M', 128, 128, 'M', 256, 256, 256, 256, 'M', 512, 512, 512, 512, 'M', 512, 512, 512, 512, 'M'],
}
def vgg11(**kwargs):
model = VGG(make_layers(cfg['A']), **kwargs)
return model
def vgg11_bn(**kwargs):
model = VGG(make_layers(cfg['A'], batch_norm=True), **kwargs)
return model
def vgg13(**kwargs):
model = VGG(make_layers(cfg['B']), **kwargs)
return model
def vgg13_bn(**kwargs):
model = VGG(make_layers(cfg['B'], batch_norm=True), **kwargs)
return model
def vgg16(**kwargs):
model = VGG(make_layers(cfg['D']), **kwargs)
return model
def vgg16_bn(**kwargs):
model = VGG(make_layers(cfg['D'], batch_norm=True), **kwargs)
return model
def vgg19(**kwargs):
model = VGG(make_layers(cfg['E']), **kwargs)
return model
def vgg19_bn(**kwargs):
model = VGG(make_layers(cfg['E'], batch_norm=True), **kwargs)
return model
import torchvision.transforms as transforms
import torchvision as tv
from torch.utils.data import DataLoader
def getData(): # 定义数据预处理
transform = transforms.Compose([
transforms.RandomSizedCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
# transforms.Normalize(mean=[0.485, 0.456, 0.406],
# std=[0.229, 0.224, 0.225])
])
trainset = tv.datasets.CIFAR10(root='./data', train=True, transform=transform, download=True)
testset = tv.datasets.CIFAR10(root='./data', train=False, transform=transform, download=True)
train_loader = DataLoader(trainset, batch_size=32, shuffle=True)
test_loader = DataLoader(testset, batch_size=32, shuffle=False)
classes = ('plane', 'car', 'bird', 'cat', 'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
return train_loader, test_loader, classes
def imshow(img):
img = img / 2 + 0.5 # unnormalize
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
if __name__ == '__main__':
net11 = vgg11()
#
# ==加载训练、测试器========
trainset_loader, testset_loader, classes = getData()
# ========各种训练========
# .....................
# ========各种训练========
# 加载测试集迭代器,每次取batch_size=32个
dataiter = iter(testset_loader)
imgs, labels = next(dataiter)
# ===可视化=====
imshow(torchvision.utils.make_grid(imgs))
# ===转成tensor张量======
imgs = Variable(imgs)
labels = Variable(labels)
# 或自己创建随机数据
# [torch.FloatTensor of size 1x3x224x224]
# X2 = np.random.random_sample(size=(1, 3, 224, 224))
# X2 = Variable(torch.from_numpy(X2).float())
# ====取数据进行显示及预测=====
X, y = imgs[0:1], labels[0]
# 最后输出神经元10个,代表10个类别的概率
pred = net11(X)
# 按列计算概率最大的那个
pdy = torch.max(pred, 1)[1]
# pdy是variable变量,需要->tensor->numpy()后得到数字
pdy = pdy.data.numpy()
# 打印预测的类型,真实的类型
print(classes[pdy[0][0]], classes[y.data[0]])

9.4 GoogLeNet网络
GoogLeNet由Google提出,主要创新是Inception机制,它对图像进行多尺度处理。
Christian Szegedy, Wei Liu, Yangqing Jia, Pierre Sermanet, Scott Reed, Dragomir Anguelov, Dumitru Erhan, Vincent Vanhoucke, Andrew Rabinovich, Going Deeper with Convolutions, Arxiv Link: http://arxiv.org/abs/1409.4842
大幅度减少了模型的参数数量,其做法是将多个不同尺度的卷积核、池化进行 整合,形成一个Inception模块,去掉了全连接层,节省空间,减少计算量。
Inception模块的目标是:用一系列小的卷积核来替代大的卷积核,而保证二者有近似的性能


用1x1卷积进行降维 不会改变图像的高度和宽度,只会改变通道数
10 反卷积运算
好处:卷积网络可视化、全卷积网络中的上采样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号