利用numpy select 和numpy where 做pandas数据处理
还是最近的那个项目,最后收尾阶段遇到这样一个问题:
根据表格每一行某几列的数据进行条件筛选后并生成新的一列数据。
像下面这个示例一样👇:
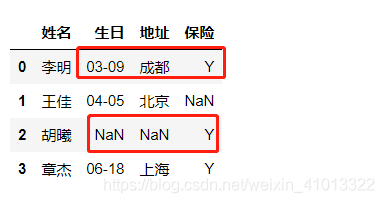
需要根据每一行的“ 生日”,“地址”,“保险”是否有值来生成新的一列字段,比如叫“完整度”字段。
就拿王佳来说,因为他的 “保险”字段是空值,但是“地址”和“生日”有对应的值。那么最后新字段 “完整度”这里就要填入 “比较完整” 四个字。同理,李明的“完整度” 就应该是“很完整”;胡曦就是“不完整”;最后章杰就是“很完整”。
看起来是个比较简单的多列条件筛选问题,熟悉pandas的朋友肯定会说 “直接写一个IF-ELSE的 筛选函数后再在该DataFrame里面用apply应用即可解决。” 貌似是这么回事,掌柜一开始也是这么想的,但是写了后实际运行出现了如下报错:
回看上面的数据发现有两行存在 NaN值的情况,所以出现了如上报错。。。
于是再次借助强大的搜索引擎谷歌后发现了 用np.select方法解决更高效:
于是修改代码如下:
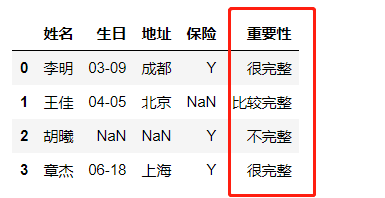
运行后就得到新的一列“完整度”的值:
是不是很方便就解决了多列条件筛选后生成新一列值的问题。
PS: 延伸一下,如果你只想对一列数据进行条件筛选,照样生成新的一列值该怎么处理呢?

还是上面那组数据,比如掌柜这里只根据“保险”这一列是否有“Y”来判断新的一列值,叫“重要性”。有“Y”值就填入“重要”;否则就是“不重要”。
直接上代码:
这里只需要把 np.select()换成 np.where()即可解决!!!还是很方便。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号