如何利用快照( snapshot )功能快速定位性能问题
我们常常会遇到这样的困惑,收到用户或者客服的反馈,平台使用有问题,但是测试人员搭建环境后又没办法复现故障,最后导致问题没法解决,眼睁睁地看着用户流失。
这是因为线上生产环境非常复杂、很多时候是偶发性 bug ,但却很难捕捉。特别是随着微服务盛行,系统复杂度增加,线上故障的快速定位和及时分析解决面临着巨大挑战,以前只能靠人来解决。但是人的问题解决能力与速度依赖于经验,有时候甚至需要跨部门的配合,这样的成本非常高,一旦关键人员流失、部门配合不融洽,整个故障的解决速度就会极速下降。
这时候我要给大家带来一款好用的性能分析工具- Application Insight (应用性能管理平台,以下简称 Ai ),至于它能干什么呢?往下看你就知道了~
trace & snapshot 功能介绍
01业务运行中有哪些错误呢?
在代码运行中,常常会遇到这几类型问题:
●JVM
常见的比如 oom 内存溢出、内存泄漏、gc pause 、磁盘运行不足等
● 数据库
常见的比如数据库负载繁忙、数据库服务器超负载、单一 sql 语句执行缓慢、数据库连接池获取时间长、对数据库连接池的访问次数过多等
● 外部服务
常见的比如外部服务网络问题、不同应用之间的调用阻塞、索引设置不合适等
● 其它问题
上面都是我们常见的场景,但是还有一些问题是深深的潜藏在程序中,需要我们深入地分析代码才能找到原因。
线程死锁、循环操作、事务异常、jvm crash 等
02什么是 trace ?
trace 收集程序运行时的信息来查询程序运行情况,定位代码中需要修改和优化的部分,提高代码运行速度,提升用户体验。
业内常用的方法有如下三种:
● 事件方法
在 Java 语言中,使用 jvmti( jvm tools interface )api 方法来捕捉诸如方法调用、类载入、类卸载、进入离开线程等事件,然后再基于这些事件进行代码行为的分析。
● 统计抽样
每隔一段事件中断调用系统,收集当前的调用栈信息,记录调用栈中出现的函数及这些函数的调用结构,基于这些信息得到函数的调用关系图及每个函数的 cpu 使用信息。
● 插码
在目标程序中插入指令代码,这些指令代码会记录程序运行的开始时间、结束时间等,再经过统计得出函数调用情况、函数 cpu 使用情况。
03 AI 的 trace
Ai 采用插码与快照(统计抽样)的方式来实现 trace ,trace 包括慢 trace 、错误 trace 、sql trace 、snapshot 四类:
● 慢 trace
在用户的事务响应时间超过阈值的时候去进行采集。系统默认是2秒,但用户可以根据自己实际情况在 Ai 的“设置-慢事务”处进行设置。

![]()
![]()
● 错误 trace
当程序运行异常或直接报错时,我们会直接采集错误 trace,还原现场。

![]()
● Sql trace
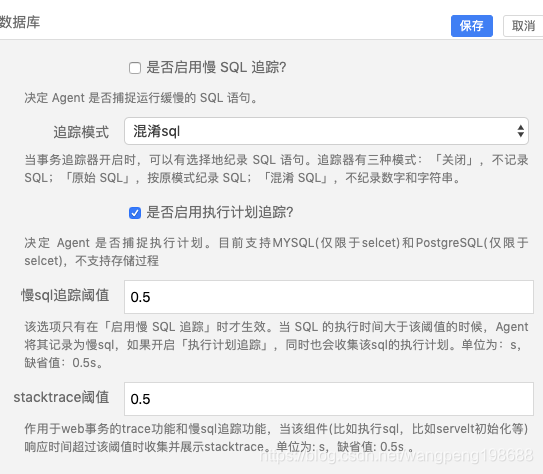
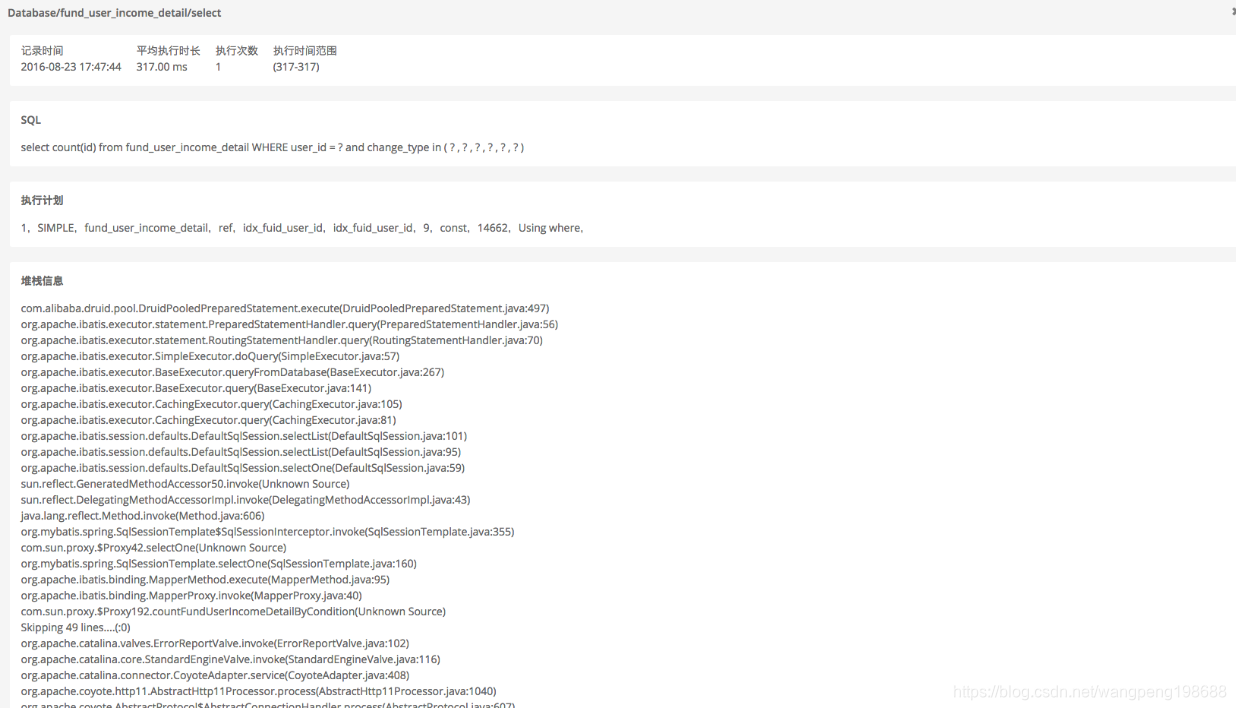
在平台开启慢 sql 追踪,并设置慢 sql 追踪阈值,当 sql 的性能大于该阈值的时候,agent 记录慢 sql 的堆栈信息。默认为0.5s,用户可以根据自己实际情况在 Ai 的“设置-数据库”进行设置。
同时用户可以开启 sql 执行计划,对于执行缓慢的 sql 进行抓取。
![]()
![]()
● snapshot
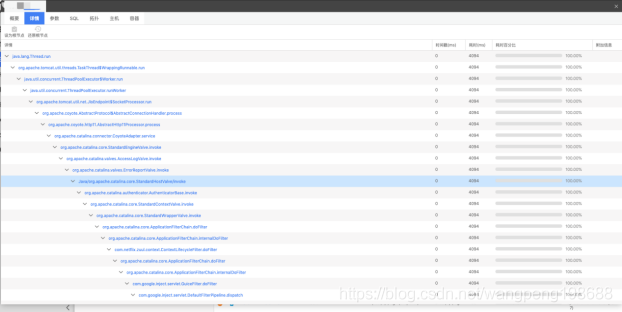
snapshot 实现原理为在客户业务运行缓慢时对调用进行多次代码快照,并且进行方法、耗时分析,得出快照 trace 。
采集规则为 web 事务连续两分钟的平均响应时间超过4*apdex_T(默认两秒),且每分钟的快照数不超过1个。
用户无需做任何配置,即可使用此功能,还可以根据业务动态调整阈值。
![]()
用户案例分析
01问题类型:连接服务被拒绝
1)问题现象:用户反馈无法退出登录
2)问题调查和分析
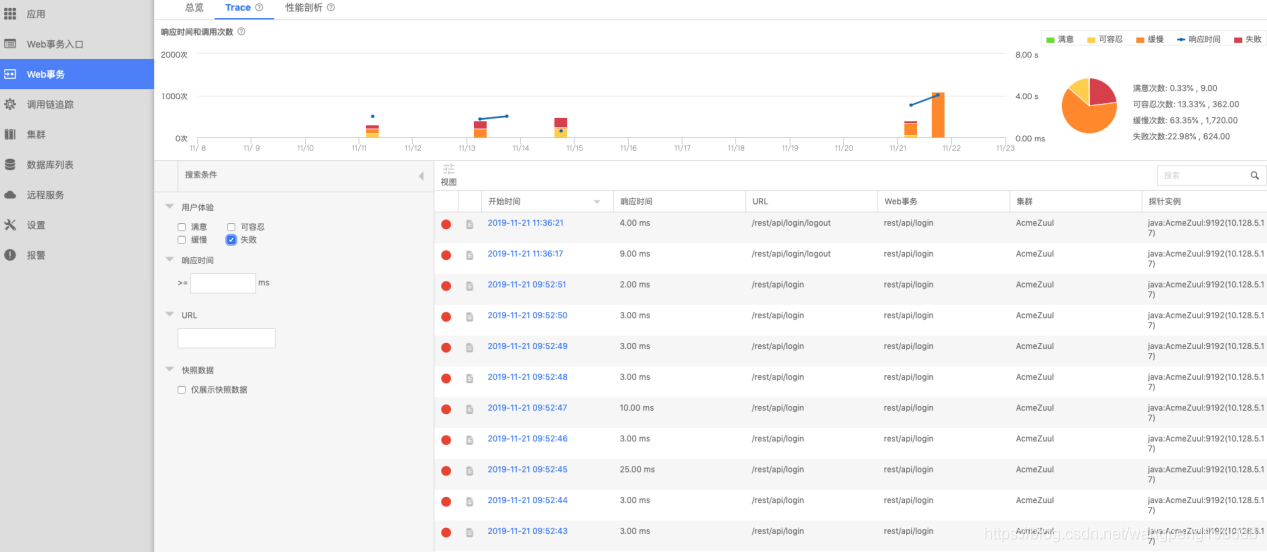
a:登录平台查看登出的接口情况
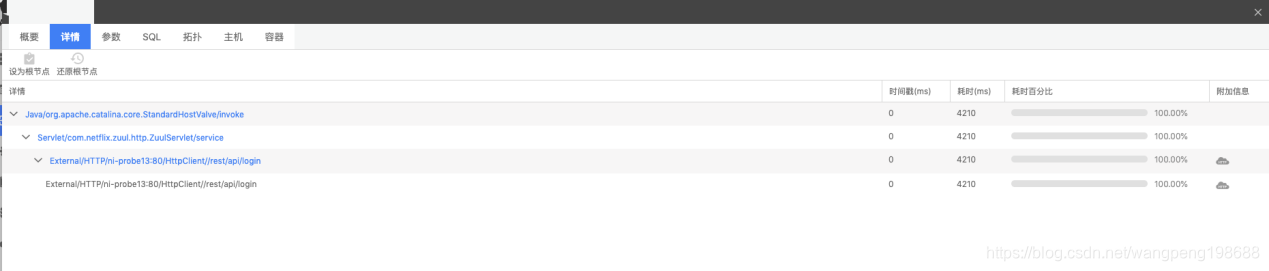
登录接口为 rest / api / login ,选择该 web 事务后进入查看详情,使用“筛选”进行条件过滤,获取失败的 trace 。
![]()
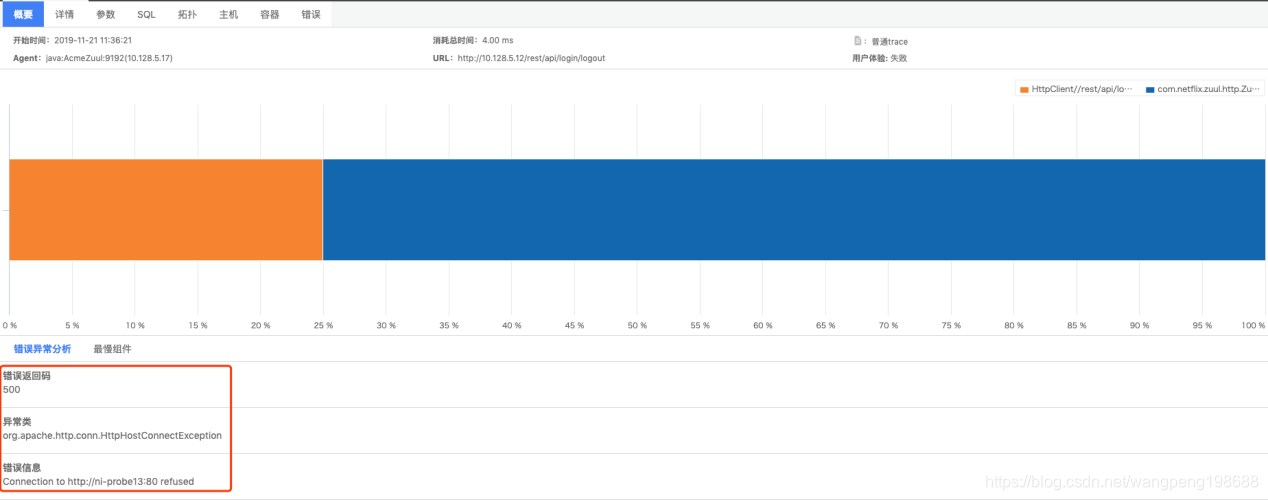
b:查看错误 trace
在总览页面,通过异常分析,看到 http 响应码和异常类、异常信息,这时候我们已经清楚问题原因了。
![]()
点击“详情”查看程序的执行情况,可以看到程序循环了三次,均出现错误

![]()
在错误详情,查看详情的调用栈,我们排查到“caused by java.net.ConnectException:拒绝连接(connection refused)
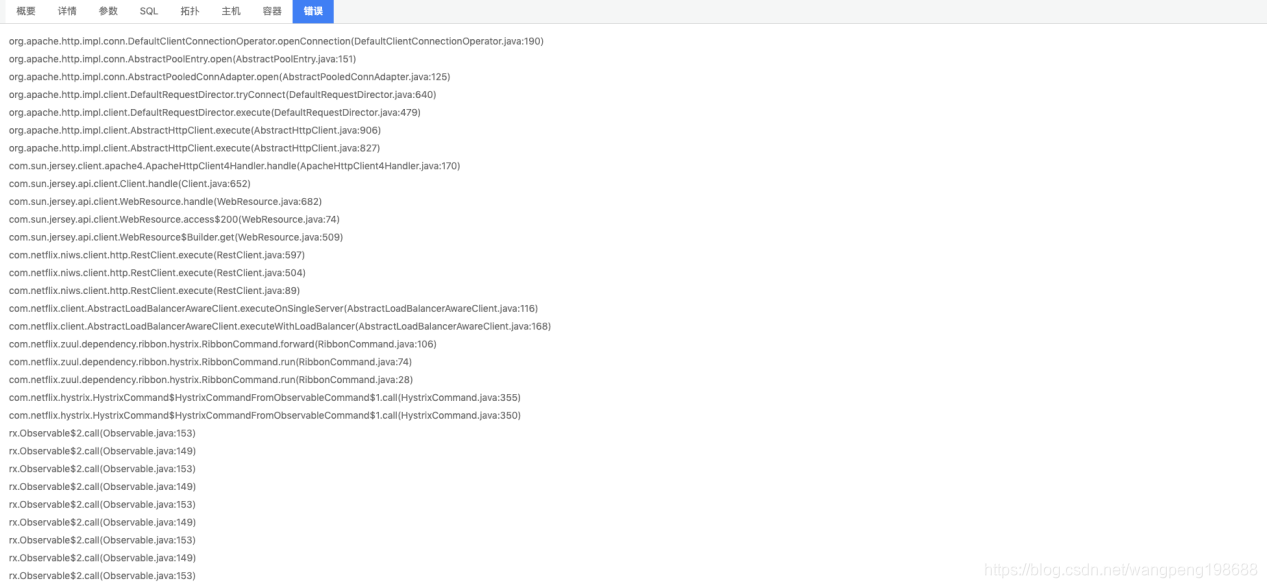
![]()

![]()

![]()
3)解决方案
与运维人员配合重启负责注册模块的服务器后,业务恢复正常。
4)建议方案
在报警处针对重要业务服务进行配置,当响应时间超过阈值或者出现频率超过阈值时,提前报警,挽回损失。
4.1 新功能体验
登录平台后可以查看报警状态

![]()
进入事务详情,鼠标悬停查看该时间段内发生的最近最严重的报警详情

![]()
点击红点跳转报警记录查看该事务在该时间段内的所有详情
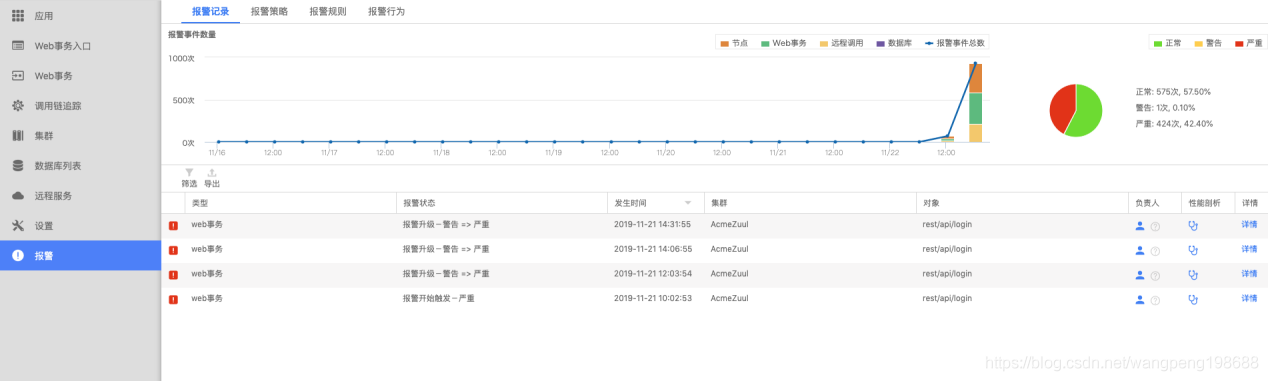
![]()
4.2 如何配置报警
a:从 Ai 页面点击报警
进入报警页面,再选择报警规则,创建报警规则名称、选择类型、自定义规则的可用与不可用时间(比如节假日不可用等)
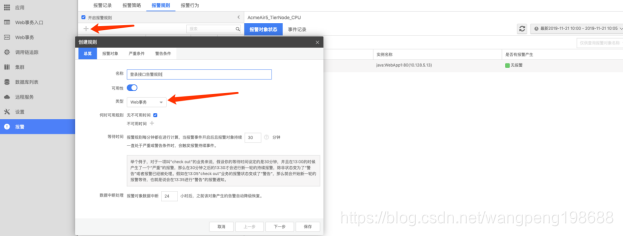
![]()
b:选择报警对象
目前系统支持按照具体 web 事务、按照不同集群、按照高频 web 事务入口( cpm >10)来进行选择,我们选择按照具体的 web 事务为报警对象。
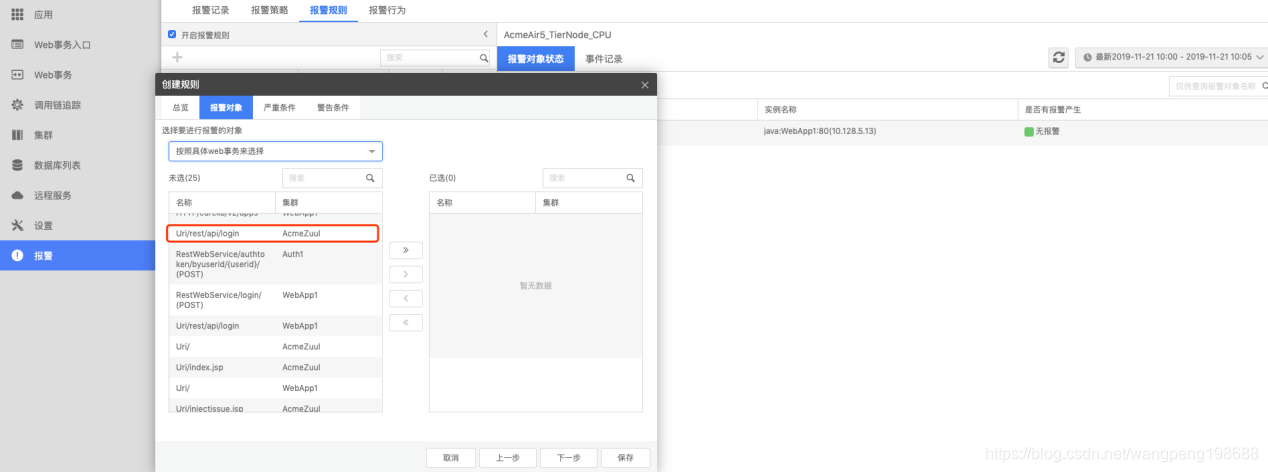
![]()
c:选择严重条件
根据我们的业务述求,只要过去10分钟内该事务的平均响应时间大于2秒,而且至少有5分钟的平均响应时间大于2s, 则触发严重报警。

![]()
d:选择警告条件
根据我们的业务述求,只要过去10分钟内该事务的平均响应时间大于1秒,而且至少有5分钟的平均响应时间大于1s, 则触发严重报警。
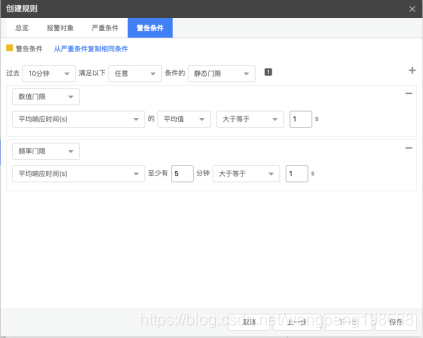
![]()
此时我们报警规则已配置好,当事务触发报警时,便可在 Ai 平台直接查看是否有报警、是否严重。如果您想及时感知报警,可进行进一步的配置。
4.3 如何接收报警
a:创建接收人

![]()
b:选择接收方式
目前 Ai 默认邮件与 webhook 报警方式,但通过与 Cloud Alert (智能告警平台,简称 CA 平台)的打通,支持短信、微信、钉钉等通知方式,更详细的报警分发与报警压缩可查看(通过免费版,中小运维团队够够的)https://www.aiops.com/CAintroduce.html
c:将接收人和报警规则关联
选择报警规则和触发行为即可
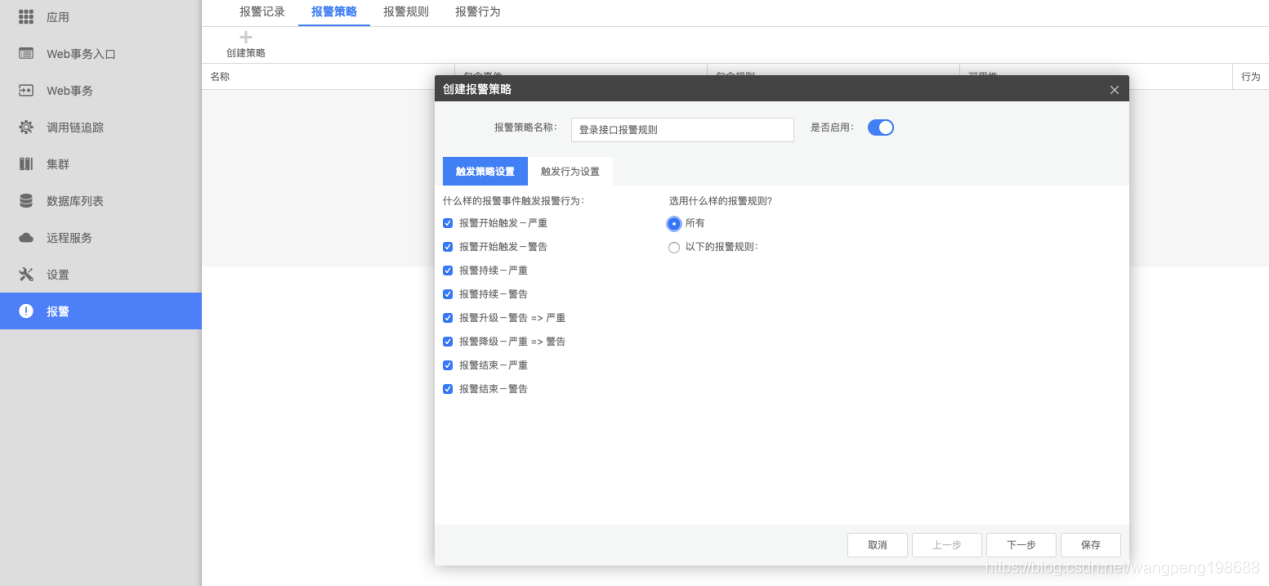
![]()
常常使用我们 Ai 平台看报警的小伙伴一定有点奇怪,为什么我没有在 Ai 平台中看到报警状态的相关信息呢?
没错,Ai 与报警深度关联功能是我们新开发的功能,我也提前体验了一把,感觉棒棒哒!该功能于12月中旬上线,小伙伴们敬请期待吧~
若您还不是 OneAPM 用户,请点击 https://user.oneapm.com/pages/v2/signup 立即注册免费试用,即刻感受性能优化吧!
在使用的过程中,如您有任何疑问和建议,欢迎随时联系我们,我们将竭诚为您服务:
qq:321095806
社区:http://club.oneapm.com

 浙公网安备 33010602011771号
浙公网安备 33010602011771号