【计算机组成原理】 数据的表示和运算
数制与编码
常用的 BCD 码
- 8421码。它是一种有权码。
- 余3码。它是一种无权码。
- 2421码。是一种有权码。特点是 >= 5 的4位二进制数中最高位为1,< 5 的最高位为0。如 5 → 1011 而非 0101。
ASCII 编码使用8位二进制代码,最左边一位是0。
主存字由2B或4B组成,在同一个主存字中,既可以按照先存储低位字节、后存储高位字节的顺序(即从低位字节向高位字节顺序)存放字符串的内容(又称小端模式),又可按照先存储高位字节、后存储低位字节的顺序存放字符串的内容(又称大端模式)。
通常某种编码都由许多码字组成,任意两个合法码字之间最少变化的二进制位数,称为校验码的码距。对于码距不小于 2 的数据校验码,开始具有检错的能力。码距越大,检错、纠错的能力就越强,而且检错能力总是大于等于纠错能力。
奇偶检验码:在原编码上加一个校验位使整个校验码中“1”的个数为奇/偶数。,奇偶检验码只能发现数据中奇数位的出错情况,但不能纠正错误,常用于对存储器数据的检查或传输数据的检查。
海明校验码:设 n 为有效信息的位数,k 为校验位的位数,则信息位 n 和校验位 k 应满足:n + k <= 2k - 1
设信息位为 D4D3D2D1,共4位,校验位为 P3P2P1,对应的海明码为 H7H6H5H4H3H2H1。规定校验位 Pi 在海明号为 2i-1 的位置上,其余各位为信息位,则海明码各位的分布如下:
H7 H6 H5 H4 H3 H2 H1
D4 D3 D2 P3 D1 P2 P1
被校验数据位的海明位号等于校验该数据位的各校验位海明位号之和。校验位 Pi 的值为 由该校验位校验的数据位 所有位求异或。
每个校验组分别利用校验位和参与形成该校验位的信息位进行奇偶校验检查,
S1 = P1 ⊕ D1 ⊕ D2 ⊕ D4,
S2 = P2 ⊕ D1 ⊕ D3 ⊕ D4,
S3 = P3 ⊕ D2 ⊕ D3 ⊕ D4,
若 S3S2S1 的值为“000”,则说明无错;否则说明出错,且这个数就是错误的位号,如 S3S2S1 = 001,说明第一位出错,即 H1 出错,直接将该位取反就达到了纠错的目的。
循环冗余校验(CRC)码
CRC 的基本思想是:在 K 位信息码后再拼接 R 位的校验码,整个编码长度为 N 位,因此这种码又称为(N,K)码。在发送端,将要传送的 K 位二进制信息码左移 R 位,将它与生成多项式 G(x) 做 模2除法(不借位),生成一个 R 位校验码,并附在信息后,构成一个新的二进制码(CRC码),共 K + R 位。若 G(x) = x3 + x2 + 1,则对 1101 进行 模2除。
接收端收到的 CRC 码为 C9C8C7C6C5C4C3C2C1,用生成多项式 G(x) 做 模2除法,若余数为 0,则码字无错。若余数为 010,则说明 C2 出错。
CRC 可以纠正一位或多位错误(由多项式 G(x) 决定),而实际传输中纠正的方法可以按需求进行选择(请求重发,删除数据,自行纠正等)。
定点数的表示与运算
| 编码方式 | 最小值编码 | 最小值 | 最大值编码 | 最大值 | 数值范围 |
| 无符号定点整数 | 0000...000 | 0 | 1111...111 | 2n+1-1 | 0 ≤ x ≤ 2n+1-1 |
| 无符号定点小数 | 0.00...000 | 0 | 0.11...111 | 1-2-n | 0 ≤ x ≤ 1-2-n |
| 原码定点整数 | 1111...111 |
-2n+1 |
0111...111 | 2n-1 | -2n+1 ≤ x ≤ 2n-1 |
| 原码定点小数 | 1.111...111 | -1+2-n | 0.111...111 | 1-2-n | -1+2-n ≤ x ≤ 1-2-n |
| 补码定点整数 | 1000...000 | -2n | 0111...111 | 2n-1 | -2n ≤ x ≤ 2n-1 |
| 补码定点小数 | 1.000...000 | -1 | 0.111...111 | 1-2-n | -1 ≤ x ≤ 1-2-n |
| 反码定点整数 | 1000...000 | -2n+1 | 0111...111 | 2n-1 | -2n+1 ≤ x ≤ 2n-1 |
| 反码定点小数 | 1.000...000 | -1+2-n | 0.111...111 | 1-2-n | -1+2-n ≤ x ≤ 1-2-n |
| 移码定点整数 | 0000...000 | -2n | 1111...111 | 2n-1 | -2n ≤ x ≤ 2n-1 |
| 移码定点小数 | 小数没有移码定义 | ||||
正数的原码、反码、补码均相同。
原码求补码(负数):除符号位以外,从最低位开始,遇到的第一个 1 以前的各位保持不变,之后各位取反。(或除符号位以外,各位取反,末位 + 1)
已知 [ Y ]补 求 [ -Y ]补,连同符号位求反,末位 + 1。
n + 1 位负数补码的真值 = -2n + 除去符号位的真值。
移码大真值就大,移码小真值就小。
| 码制 | 添补代码 | |
| 正数 | 原码、反码、补码 | 0 |
| 负数 | 原码 | 0 |
| 补码 | 左移添0 | |
| 右移添1 | ||
| 反码 | 1 |
逻辑移位不管是左移还是右移,都添0。
循环移位分为带进位标志位 CF 的循环移位(大循环)和不带进位标志位的循环移位(小循环),过程如图所示:
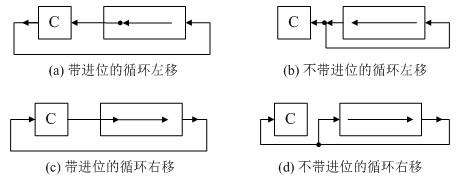
循环移位的主要特点是,移除的数据又被移入数据中,而 是否带进位则要看是否将进位标志位加入循环移位。例如,带进位的循环左移就是将数据位连同进位标志位一起左移,数据的最高位移入进位标志位 CF,而进位标志位则依次移入数据的最低位。
循环移位适合将数据的低字节数据和高字节数据互换。
原码定点数的加减法运算:
加法规则:先判符号位,若相同,则绝对值相加。结果符号位不变;若不同。则做减法,绝对值大的数减去绝对值小的数,结果符号位与绝对值大的数相同。
减法规则:两个原码表示的数相减,首先将减数符号取反,然后将被减数与符号取反后的减数按原码加法进行运算。
运算时注意机器字长,当左边出现溢出时,将溢出位丢掉。
补码定点数的加减法运算:
符号位与数值位按同样的规则一起参与运算,符号位产生的进位要丢掉,结果的符号位由运算得出。
补码运算的结果亦为补码。
符号扩展(可参考移位规则)
在计算机算术运算中,有时必须把采用给定位数表示的数转换成具有不同位数的某种表示形式。例如,某个程序需要将一个 8 位数与另外一个 32 位数相加,要想得到正确的结果,在将 8 位数与 32 位数相加之前,必须将 8 位数转换成 32 位数形式,这称为“符号扩展”。
正数的符号扩展:原有形式的符号位移动到新形式的符号位上,新表示形式的所有附加位都用 0 进行填充。
负数的符号扩展方法则根据机器数的不同而不同。原码表示负数的符号扩展方法与正数相同,只不过此时符号位为 1。补码表示负数的符号扩展方法:原有形式的符号位移动到新形式的符号位上,新表示形式的所有附加位都用 1(对于整数)或 0(对于小数)进行填充。反码表示负数的符号扩展方法:原有形式的符号位移动到新形式的符号位上,新表示形式的所有附加位都用 1 进行填充。
| 乘法类型 | 符号位 | 累加次数 | 移位 | ||||
| 参与运算 | 部分积 | 乘数 | 方向 | 次数 | 每位次数 | ||
| 原码一位乘法 | 否 | 2位 | 0位 | n | 右 | n | 1 |
| 补码一位乘法 | 是 | 2位 | 1位 | n + 1 | 右 | n | 1 |
| 乘法类型 | 符号位参与运算 | 加减次数 | 移位 | 说明 | |
| 方向 | 次数 | ||||
| 原码加减交替法 | 否 | N + 1 或 N + 2 | 左 | N | 若最终余数为负,需恢复余数 |
| 补码加减交替法 | 是 | N + 1 | 左 | N | 商末尾恒置 1 |
在计算机系统中,数值一律用补码来表示和存储。
强制类型转换
当大字长变量向小字长变量强制类型转换时,系统把多余的高位字节部分直接截断,低位直接赋值。
短字长到长字长变量的转换,不仅要使相应的位值相等,高位部分还会扩展为原数字的符号位。
例:short x = -4321; int y = x; unsigned short u = (unsigned short) x; unsigned int v = u;
结果:x = -4321, y = -4321, u = 61215, v = 61215
x、y、u、v 的十六进制表示分别是 0xef1f、0xffffef1f、0xef1f、0x0000ef1f
| 类型 | 16位机器 | 32位机器 | 64位机器 |
| char | 8 | 8 | 8 |
| short | 16 | 16 | 16 |
| int | 16 | 32 | 32 |
| long | 32 | 32 | 64 |
| long long | 64 | 64 | 64 |
| float | 16 | 32 | 32 |
| double | 64 | 64 | 64 |
数据按边界对齐指变量的起始地址必须能够被自身的数据类型的大小整除。
对真值 0 表示形式唯一的机器数是补码和移码。
使用补码表示时,若符号位相同,则数值位越大,码值越大。
不带进位位的循环左移将最高位进入最低位和标志寄存器 C 位。
8421码是十进制数的编码。
存储模4补码(变形补码,双符号位)仅需一个符号位,因为正确的数值两个符号位相同,只在 ALU 中采用双符号位。
在计算机中,通常用无符号数来表示主存地址。
浮点数的表示与运算
左规:当浮点数运算的结果为非规格化时要进行规格化处理,将尾数算术左移一位,阶码减1(基数为2时)的方法称为左规,左规可能要进行多次。
右规:当浮点数运算的结果尾数出现溢出(双符号位为 01 或 10)时,将尾数算术右移一位,阶码加 1(基数为2时)的方法称为右规。需要右规时,只需进行一次。
(1)原码规格化后。
正数为 0.1xx...x的形式,其最大值表示为 0.11...1,最小值表示为 0.10...0。
尾数的表示范围为 1/2 ≤ M ≤ (1-2-n)
负数为 1.1xx...x的形式,其最大值表示为 1.10...0,最小值表示为 1.11...1。
尾数的表示范围为 -(1-2-n) ≤ M ≤ -1/2。
(2)补码规格化后
正数为 0.1xx...x的形式,其最大值表示为 0.11...1,最小值表示为 0.10...0。
尾数的表示范围为 1/2 ≤ M ≤ (1-2-n)
负数为 1.0xx...x的形式,其最大值表示为 1.01...1,最小值表示为 1.0...0。
尾数的表示范围为 -1 ≤ M ≤ -(1-2-n)。
补码规格化数的尾数最高为一定与尾数符号位相反。
运算结果大于最大正数时称为正上溢,小于绝对值最大负数时称为负上溢,正上溢和负上溢统称为上溢。数据一旦产生上溢,计算机必须中断运算操作,进行溢出处理,当运算结果在 0 至最小正数之间时称为正下溢,在 0 至绝对值最小负数之间时称为负下溢,正下溢和负下溢统称为下溢。数据下溢时,浮点数值趋于零,计算机仅将其当作机器零处理。
IEEE 754 标准
| 类型 | 数符 | 阶码 | 尾数数值 | 总位数 | 偏置值 | |
| 十六进制 | 十进制 | |||||
| 短浮点数(FLOAT) | 1 | 8 | 23 | 32 | 7FH | 127 |
| 长浮点数(DOUBLE) | 1 | 11 | 52 | 64 | 3FFH | 1023 |
| 临时浮点数 | 1 | 15 | 64 | 80 | 3FFFH | 16383 |
| 数符 | 阶码 | 尾数 |
计算所得阶码需加上偏置值,以移码形式表示。对于规格化的二进制浮点数,数值的最高位总是“1”,为了能使尾数多表示一位有效位,将这个“1”隐含,因此尾数数值实际上是24位。
阶码以移码形式表示,尾数以原码形式表示。
阶码全 1 表示无穷大,全 0 表示非规格化数。
浮点数的加减运算:(1)对阶。小阶向大阶看齐。(2)尾数求和(3)规格化(4)舍入。“0”舍“1”入法;恒置“1”法。(5)溢出判断(6)强制类型转换
采用规格化的浮点数主要是为了增加数据的表示精度。
对阶操作不存在阶码减小(小阶向大阶看齐)。
舍入是浮点数的概念,定点数没有舍入的概念。浮点数舍入的情况有两种:对阶、右规格化。
对阶操作不会引起阶码上溢或下溢。右规和尾数舍入都可能引起阶码上溢。左规时可能引起阶码下溢。尾数溢出时结果不一定溢出。
设阶码和尾数均用补码表示,阶码部分共 K + 1 位(含 1 位阶符),尾数部分共 n + 1 位(含 1 位数符),则
| 浮点数 | 浮点表示 | 真值 | |
| 阶码 | 尾数 | ||
| 最大正数 | 01...1 | 0.11...11 | (1 - 2-n) * 2^(2k - 1) |
| 绝对值最大负数 | 01...1 | 1.00...00 | -1 * 2^(2k - 1) |
| 最小正数 | 10...0 | 0.00...01 | 2-n * 2^(-2k) |
| 规格化的最小正数 | 10...0 | 0.10...00 | 2-1 * 2^(-2k) |
| 绝对值最小负数 | 10...0 | 1.11...11 | -2-n * 2^(-2k) |
| 规格化的绝对值最小负数 | 10...0 | 1.01...11 | -(2-1 + 2-n) * 2 ^(-2k) |
算术逻辑单元(ALU)
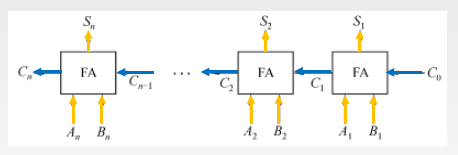
1. 一位全加器
全加器(FA)是最基本的加法单元,有加数 Ai、加数 Bi 与低位传来的进位 Ci-1 共三个输入有 本位和 Si 与向高位的进位 Ci 共两个输出。
和表达式:Si = Ai ⊕ Bi ⊕ Ci-1 (Ai、Bi、Ci-1 中有奇数个 1 时,Si = 1;否则 Si = 0)
进位表达式:Ci = AiBi + (Ai ⊕ Bi)Ci-1
2.串行加法器
在串行加法器中,只有一个全加器,数据逐位串行送入加法器中进行运算。若操作数长 n 位,则加法器就要分 n 次进行,每次产生一位和,并且串行逐位送回寄存器。进位触发器用来寄存进位信号,以便参与下一次运算。
串行加法器具有器件少、成本低的优点,但运算速度慢,多用于某些低速的专用运算器。
3.并行加法器
并行加法器由多个全加器组成,其位数与机器的字长相同,各位数据同时运算。并行加法器中的每个全加器都有一个从低位送来的进位输出和一个传送给高位的进位输出,通常将传递进位信号的逻辑线路连接起来构成的几位内网络称为进位链。
并行加法器的进位通常分为串行进位与并行进位。
- 串行进位。把 n 个全加器串接起来,就可以进行两个 n 位数的相加,这种加法器称为串行进位的并行加法器。串行进位又称行波进位,每级进位直接依赖于前一级的进位,即进位信号是逐级形成的。如图:
- 并行进位。并行进位又称先行进位、同时进位,其特点是各级进位信号同时形成。
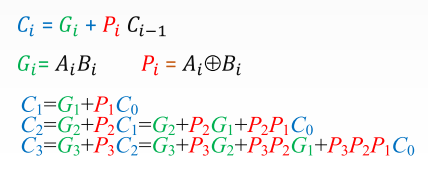
- 上述各式所有的进位输出仅由 Gi、Pi及最低进位输入 C0 决定,而不依赖于其低位的进位输入 Ci-1 ,因此各级进位输出可以同时产生。这种进位方式是快速的,与字长无关。
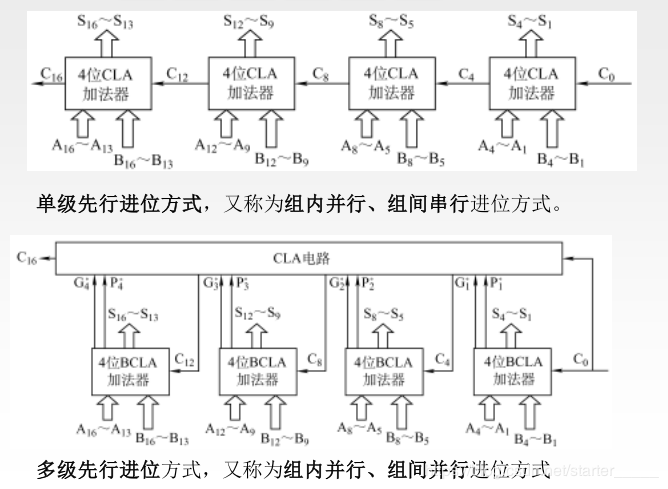
分组并行进位方式,把 n 位全加器分为若干小组,小组内的各位之间实行并行快速进位,小组与小组之间可以采用串行进位方式,也可以采用并行快速进位方式,因此有以下两种情况:
ALU 是一种功能较强的组合逻辑电路。
74181 为 4 位并行加法器,其 4 位进位是同时产生的,用 4 片 74181 芯片可组成 16 位 ALU。其片内进位是快速的,但片间进位是逐片传递的,即组内并行(74181 片内)、组间串行(74181 片间)。
若把 16 位 ALU 中的每 4 位作为一组,即将 74181 与 74182 芯片(先行进位芯片)配合,用类似位间快速进位的方法来实现 16 位 ALU(4 片 ALU 组成),则能得到 16 位的两级先行进位 ALU,即组内并行(74181 片内)、组间并行(74181 片间)。

在串行进位的并行加法器中,影响加法器运算速度的关键因素是进位传递延迟。
地址寄存器不属于运算器,而属于存储器。状态寄存器、数据总线、ALU 均是组成运算器的部件。
以上内容均来自王道书籍及相关课程等

 浙公网安备 33010602011771号
浙公网安备 33010602011771号