12种用于Python数据分析的Pandas技巧
转自:微信公众号论智(本文来自Analytics Vidhya,由论智原创编译)。
编者按:依靠完善的编程语言生态系统和更好的科学计算库,如今Python几乎已经成了数据科学家的首选语言。如果你正开始学习Python,而且目标是数据分析,相信NumPy、SciPy、Pandas会是你进阶路上的必备法宝。尤其是对数学专业的人来说,Pandas可以作为一个首选的数据分析切入点。
本文将介绍12种用于数据分析的Pandas技巧,为了更好地描述它们的效果,这里我们用一个数据集辅助进行操作。另外,本文在原文的基础上,使用Python3.6进行操作。
数据集:我们研究的主题是贷款预测,请到datahack.analyticsvidhya.com/contest/practice-problem-loan-prediction下载数据(需注册),并开始学习之旅。
预备!开始!
首先,我们先导入模块,并将数据集加载到Python环境中:
1 import pandas as pd 2 import numpy as np 3 data = pd.read_csv("/root/test1/train.csv", index_col="Loan_ID")
在表格中,如果你想根据另一列的条件筛选当前列的值,你会怎么做?举个例子,假设我们想要一份所有未毕业但已经办理了贷款的女性清单,具体的操作是什么?在这种情况下,Boolean Indexing,也就是布尔索引能提供相应的功能。我们只需这样做:
1 data.loc[(data["Gender"]=="Female") & (data["Education"]=="Not Graduate") & (data["Loan_Status"]=="Y"), ["Gender","Education","Loan_Status"]]
| Gender | Education | Loan_Status | |
|---|---|---|---|
| Loan_ID | |||
| LP001155 | Female | Not Graduate | Y |
| LP001669 | Female | Not Graduate | Y |
| LP001692 | Female | Not Graduate | Y |
| LP001908 | Female | Not Graduate | Y |
| LP002300 | Female | Not Graduate | Y |
| LP002314 | Female | Not Graduate | Y |
| LP002407 | Female | Not Graduate | Y |
| LP002489 | Female | Not Graduate | Y |
| LP002502 | Female | Not Graduate | Y |
| LP002534 | Female | Not Graduate | Y |
| LP002582 | Female | Not Graduate | Y |
| LP002731 | Female | Not Graduate | Y |
| LP002757 | Female | Not Graduate | Y |
| LP002917 | Female | Not Graduate | Y |
2. Apply Function
Apply函数是使用数据和创建新变量的常用函数之一。在对DataFrame的特定行/列应用一些函数后,它会返回相应的值。这些函数既可以是默认的,也可以是用户自定义的。如这里我们就定义了一个查找每行/列中缺失值的函数:
1 #Create a new function: 2 def num_missing(x): 3 return sum(x.isnull()) 4 5 #Applying per column: 6 print ("Missing values per column:") 7 print (data.apply(num_missing, axis=0)) #axis=0 defines that function is to be applied on each column 8 9 #Applying per row: 10 print ("\nMissing values per row:") 11 print (data.apply(num_missing, axis=1).head()) #axis=1 defines that function is to be applied on each row
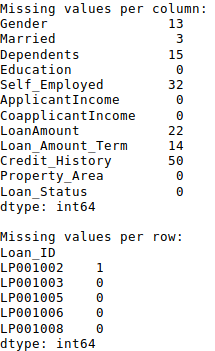
我们得到了预期的结果。需要注意的一点是,这里head() 函数只作用于第二个输出,因为它包含多行数据。
3. 替换缺失值
对于替换缺失值,fillna()可以一步到位。它会用目标列的平均值/众数/中位数更新缺失值,以此达到目的。在这个示例中,让我们用众数分别更新Gender、Married、Self_Employed这几列的缺失值:
1 #First we import a function to determine the mode 2 from scipy.stats import mode 3 mode(data['Gender'].astype(str))

我们得到了众数及其出现的次数。记住很多时候众数会是一个数组,因为可能数据中存在多个高频词,默认情况下,我们会选择第一个:
mode(data['Gender']).mode[0]
现在我们就能更新缺失值,并检测自己对Apply函数的掌握情况:
1 import pandas as pd 2 import numpy as np 3 from scipy.stats import mode 4 data = pd.read_csv("/root/test1/train.csv", index_col="Loan_ID") 5 data.loc[(data["Gender"]=="Female") & (data["Education"]=="Not Graduate") & (data["Loan_Status"]=="Y"), ["Gender","Education","Loan_Status"]] 6 #Impute the values: 7 data['Gender'].fillna(mode(data['Gender'].astype(str)).mode[0], inplace=True) 8 data['Married'].fillna(mode(data['Married'].astype(str)).mode[0], inplace=True) 9 data['Self_Employed'].fillna(mode(data['Self_Employed'].astype(str)).mode[0], inplace=True) 10 #Create a new function: 11 def num_missing(x): 12 return sum(x.isnull()) 13 14 #Now check the #missing values again to confirm: 15 print (data.apply(num_missing, axis=0))
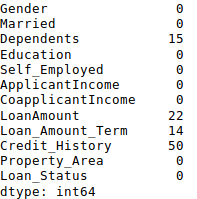
从结果上看,缺失值的确被补上了,但这只是最原始的形式,在现实工作中,我们还要掌握更复杂的方法,如分组使用平均值/众数/中位数、对缺失值进行建模等。
4. Pivot Table
Pandas可以用来创建MS Excel样式数据透视表(Pivot Table)。在本文的例子中,数据的关键列是含有缺失值的“LoanAmount”。为了获得具体的贷款额度数字,我们可以用Gender、Married、Self_Employed这几列的贷款情况进行估算:
1 #Determine pivot table 2 impute_grps = data.pivot_table(values=["LoanAmount"], index=["Gender","Married","Self_Employed"], aggfunc=np.mean) 3 print (impute_grps)

5. Multi-Indexing
如果你仔细观察了“替换缺失值”那一节的输出,你可能会发现一个奇怪的现象,就是每个索引都由3个值组合而成。这被称为多重索引(Multi-Indexing),它有助于操作的快速执行。
让我们接着这个例子,假设现在我们有各列的值,但还没有进行缺失值估算。这时就要用到之前的各种技巧:
1 #iterate only through rows with missing LoanAmount 2 for i,row in data.loc[data['LoanAmount'].isnull(),:].iterrows(): 3 ind = tuple([row['Gender'],row['Married'],row['Self_Employed']]) 4 data.loc[i,'LoanAmount'] = impute_grps.loc[ind].values[0] 5 6 #Now check the #missing values again to confirm: 7 print (data.apply(num_missing, axis=0))
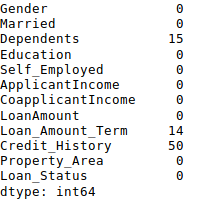
注:
-
多索引需要元组来定义loc语句中的索引组。这是一个在函数中要用到的元组。
-
values [0]的后缀是必需的,因为默认情况下返回的值与DataFrame的值不匹配。在这种情况下,直接分配会出现错误。
6. Crosstab
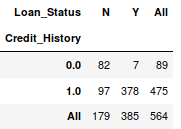
这个函数可以被用来塑造对数据的初始“感觉(概览)”,通俗地讲,就是我们可以验证一些基本假设,如在贷款案例中,“Credit_History”会影响个人贷款成功与否。这可以用交叉表(Crosstab)测试,如下所示:
1 pd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True)
如果说数值还不够直观,我们可以用apply函数把它转换成百分比:
1 def percConvert(ser): 2 return ser/float(ser[-1]) 3 pd.crosstab(data["Credit_History"],data["Loan_Status"],margins=True).apply(percConvert, axis=1)
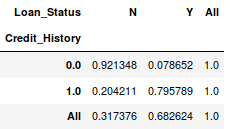
显然,有“CreditHistory”的人获得贷款的机会更大,有80%以上的概率,而没有“CreditHistory”的人获得贷款的概率只有可怜的9%。
但是这就是个简单的预测结果吗?不是的,这里包含着一个有趣的故事。已知有CreditHistory”的人获得贷款的概率更高,那我们大可以设他们的“LoanStatus”为Y,其他人的为N,这样一个模型的预测结果会是什么样的?我们进行了614次测试,而它的正确预测次数是82+378=460,75%的准确率!
也许你会吐槽这么个问题为什么要扯到统计模型。我不否认,但我只想说明一点,就是如果你能把这个模型的准确率再提升哪怕0.001%,这都是个巨大的突破。
注:这里的75%是个大概的值,具体数字在训练集和测试集上有所不同。我希望这能直观地解释为什么在Kaggle这样的比赛中,0.05%的准确率提升能带来500名以上的排名提升。
7. 合并DataFrame
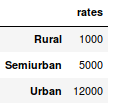
当我们需要将来自不同来源的信息进行整合时,合并DataFrame(或者你们爱说数据框)就变得很重要了。现在房价很热,炒房团也很热,所以我们先用数据集的数据假设一份各地区房屋均价(1平)不同的表:
1 prop_rates = pd.DataFrame([1000,5000,12000],index = ['Rural','Semiurban','Urban'],columns=['rates']) 2 prop_rates
现在我们可以将这些信息与原始DataFrame合并为:
1 data_merged = data.merge(right=prop_rates, how='inner',left_on='Property_Area',right_index=True, sort=False) 2 data_merged.pivot_table(values='Credit_History',index=['Property_Area','rates'], aggfunc=len)
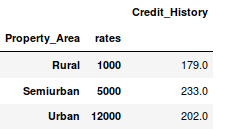
反正买不起,好了,数据合并成功了。请注意,'values'参数在这里是没什么用的,因为我们只是做计数。
8. DataFrame排序
Pandas可以轻松基于多列进行排序,如下所示:
1 data_sorted = data.sort_values(['ApplicantIncome','CoapplicantIncome'], ascending=False) 2 data_sorted[['ApplicantIncome','CoapplicantIncome']].head(10)
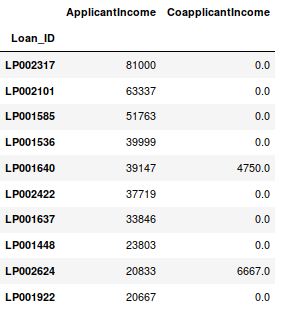
注:Pandas的sort函数已经不能用了,现在排序要调用sort_value。
9. 绘图(Boxplot和直方图)
很多人可能不知道自己能直接在Pandas里绘制盒形图和直方图,无需单独调用matplotlib,一行命令就能搞定。例如,如果我们想比较Loan_Status的ApplicantIncome的分布情况:
1 import matplotlib.pyplot as plt 2 %matplotlib inline 3 data.boxplot(column="ApplicantIncome",by="Loan_Status")

1 data.hist(column="ApplicantIncome",by="Loan_Status",bins=30)
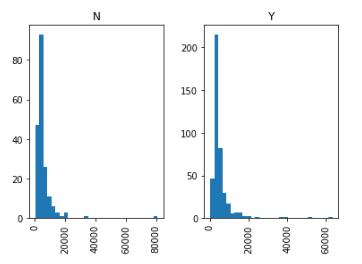
这两幅图表明收入在贷款过程中所占的比重并没有我们想象中那么高,无论是被拒的还是收到贷款的,他们的收入没有非常明显的区别。
10. Cut function for binning
有时候聚类后的数据会更有意义。以今天最近车祸频发的自动驾驶汽车为例,如果我们要用它捕获的数据重现某条路上的交通情况,比起一整天的流畅数据,或是把一天均匀分割为24个小时,“早上”“下午”“晚上”“夜晚”“深夜”这几个关键时段的数据包含的信息量更多,也更有效。如果我们用这些数据建模,它的成果会更直观,而且可以避免过拟合。
这里我们定义一个简单的函数,它可以高效binning:
1 #Binning: 2 def binning(col, cut_points, labels=None): 3 #Define min and max values: 4 minval = col.min() 5 maxval = col.max() 6 7 #create list by adding min and max to cut_points 8 break_points = [minval] + cut_points + [maxval] 9 10 #if no labels provided, use default labels 0 ... (n-1) 11 if not labels: 12 labels = range(len(cut_points)+1) 13 14 #Binning using cut function of pandas 15 colBin = pd.cut(col,bins=break_points,labels=labels,include_lowest=True) 16 return colBin 17 18 #Binning age: 19 cut_points = [90,140,190] 20 labels = ["low","medium","high","very high"] 21 data["LoanAmount_Bin"] = binning(data["LoanAmount"], cut_points, labels) 22 print (pd.value_counts(data["LoanAmount_Bin"], sort=False))

11. 为nominal数据编码
有时候我们需要对称名数据(nominal数据)重新分类,这可能是由于各种原因造成的:
-
一些算法(如Logistic回归)要求所有输入都是数字,所以我们要把称名变量重新编码为0,1 ...(n-1)。
-
有时一个类别可能包含多种表达,如“温度”可以被记录为“High”“Medium”“Low”“H”“low”,其中“High”和“H”是一码事,“Low”和“low”也是一码事,但Python会认为它们是不同的。
-
有些类别的频数非常低,所以我们应该把它们合并起来。
为了解决这个问题,这里我们定义了一个简单的函数,它把输入作为“字典”,然后调用Pandas的replace函数重新编码:
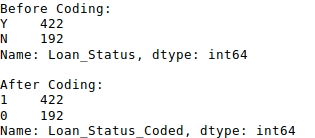
1 #Define a generic function using Pandas replace function 2 def coding(col, codeDict): 3 colCoded = pd.Series(col, copy=True) 4 for key, value in codeDict.items(): 5 colCoded.replace(key, value, inplace=True) 6 return colCoded 7 8 #Coding LoanStatus as Y=1, N=0: 9 print ('Before Coding:') 10 print (pd.value_counts(data["Loan_Status"])) 11 data["Loan_Status_Coded"] = coding(data["Loan_Status"], {'N':0,'Y':1}) 12 print ('\nAfter Coding:') 13 print (pd.value_counts(data["Loan_Status_Coded"]))
12. 迭代dataframe的行
这不是一个常用的技巧,但如果遇到这种问题,相信没人想到时候再绞尽脑汁想办法,或者直接自暴自弃用for循环遍历所有行。这里我们举两个要用到这种方法的场景:
-
当带有数字的nominal variable被当成数字。
-
当某一行带有字符(因为数据错误)的Numeric variable被当成分类。
这时我们就要手动定义列的类别。虽然很麻烦,但这之后如果我们再检查数据类别:
1 #Check current type: 2 data.dtypes
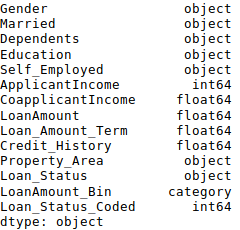
这里我们看到Credit_History是一个称名变量,但是它却显示为float。解决这些问题的一个好方法是创建一个包含列名和类型的csv文件,有了它,我们就可以创建一个函数来读取文件并分配列数据类型。
1 #Load the file: 2 colTypes = pd.read_csv('/root/test1/datatypes.csv') 3 print (colTypes)

加载这个文件后,我们可以遍历每一行,并使用'type'列将数据类型赋值给'feature'列中定义的变量名称。
1 #Iterate through each row and assign variable type. 2 #Note: astype is used to assign types 3 4 for i, row in colTypes.iterrows(): #i: dataframe index; row: each row in series format 5 if row['type']=="categorical": 6 data[row['feature']]=data[row['feature']].astype(np.object) 7 elif row['type']=="continuous": 8 data[row['feature']]=data[row['feature']].astype(np.float) 9 print (data.dtypes)

希望本文对你有用!
原文地址:www.analyticsvidhya.com/blog/2016/01/12-pandas-techniques-python-data-manipulation/

