爬虫学习:xpath爬取评书网
在家闲着,想找点评书听,但找了很久都没找到方便打包下载的地方。于是就拿起自学的python爬虫,自己动手丰衣足食。
运行环境:Windows7,python3.7
操作步骤:
1.打开选好的评书主页面(https://www.5tps.com/html/23602.html),并调出chrome控制台,找到目录列表对应的元素。

2.点开具体回目,筛选具体的音频链接。
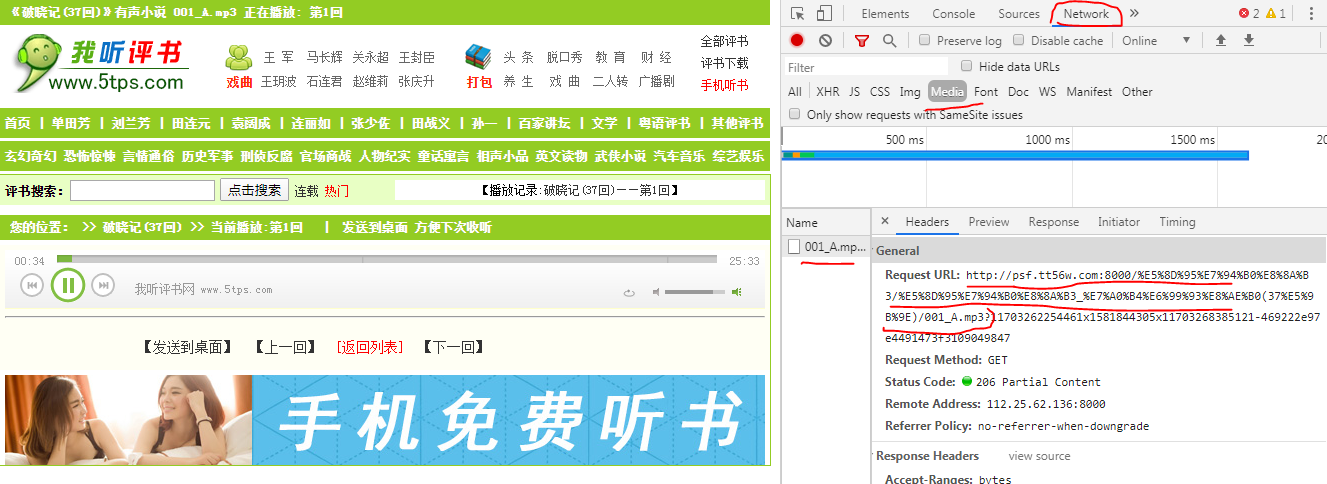
可以看到链接:http://psf.tt56w.com:8000/%E5%8D%95%E7%94%B0%E8%8A%B3/%E5%8D%95%E7%94%B0%E8%8A%B3_%E7%A0%B4%E6%99%93%E8%AE%B0(37%E5%9B%9E)/001_A.mp3
是乱码,具体情况是连接中中文转码造成的,可以百度在线的网址进行转码,结果为:
http://psf.tt56w.com:8000/单田芳/单田芳_破晓记(37回)/001_A.mp3
利用相同的原理,再点几个页面,我们可以找到一个规律,这个评书的音频链接命名规则是【http://psf.tt56w.com:8000/单田芳/单田芳_破晓记(37回)/】+【章节的对应元素代码】。
因此只需要爬取主页面目录的元素即可。
代码如下:
from lxml import etree import requests headers = {"User-Agent" : "Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1 Trident/5.0;"} url='https://www.5tps.com/html/23602.html' html=etree.HTML(requests.get(url,headers=headers).content) results=html.xpath('//ul/li/a/@title') #音频链接 resultst=html.xpath('//ul/li/a/text()') #章节名字 for i in range(len(results)): results[i]='http://psf.tt56w.com:8000/单田芳/单田芳_破晓记(37回)/'+results[i] resultst[i]=resultst[i].replace('\xa0','') with open('G:\dota\pingshu2\{}.mp3'.format(resultst[i][1:-1]),'wb') as f: f.write(requests.get(results[i]).content) #下载并保存,具体保存路径根据需要修改 print(resultst[i][1:-1]) print('爬取完成!')
参考链接:
https://www.cnblogs.com/RyanLea/p/11072070.html

