14 BasicHashTable基本哈希表类(一)——Live555源码阅读(一)基本组件类
这是Live555源码阅读的第一部分,包括了时间类,延时队列类,处理程序描述类,哈希表类这四个大类。
本文由乌合之众 lym瞎编,欢迎转载 http://www.cnblogs.com/oloroso/
本文由乌合之众 lym瞎编,欢迎转载 my.oschina.net/oloroso
BasicHashTable基本哈希表类
这个类搞的很复杂,实质上没什么东西,就是很难看。
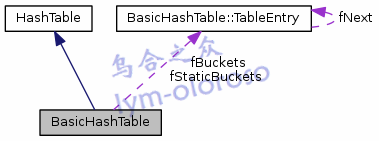
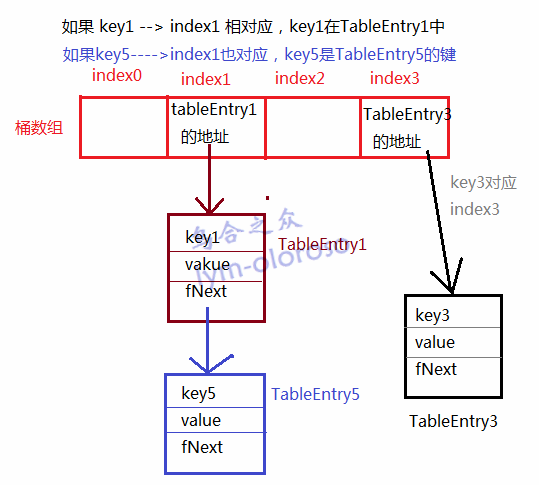
先画一个简图

先说说这个BasicHashTable的设计吧。
这个表的内部嵌套定义了一个TableEntry(表条目)的类,这个类有一个键key,一个值value,以及指向同一个索引下一个条目的指针(此处很有用,为什么要这么设置,后面会说到的)。这里的key是char const*类型,但其并不一定是如此,可以是unsigned类型等,这里只是一个代表。
BasicHashTable的内部定义了一个TableEntry*类型的数组fStaticBuckets,是用来保存表条目的,默认是4个元素。还有一个指向这个数组的指针fBuckets,为什么还要这个数组呢?因为可能哈希表要扩展,4个元素不够用。所以又定义了一个成员fNumBuckets来标识桶(Buckets)的数量,一个桶就是一个数组元素空间。除此之外还需要知道以及保存了多少个条目,于是又有了成员fNumEntries。还有一个就是条目的键的类型,这个在创建哈希表的时候就要确定,所以又增加了成员fKeyType。
还有一个成员fRebuildSize,这个成员是用来确定什么时候该重建的。每次在Add方法调用的时候就会判断当前已有条目数是否达到了fRebuildSize,如果达到了就该重建了。它的值是现有桶数的3倍。前面说了,一个桶可以保存一个TableEntry* 类型的变量,也就是一个条目的地址,而每一个TableEntry对象中,又含有一个fNext变量,指向下一个条目。因为hash是散列算法,那么不同的key可能会散列到同一个index,如何解决这种碰撞问题呢?很好办,用链表。即把同一个散列到index的条目,用链表串联起来。

另外两个成员fDownShift, fMask是用于产生索引index用的。
下面是类BasicHashTable的定义
#define SMALL_HASH_TABLE_SIZE 4
class BasicHashTable : public HashTable {
private:
class TableEntry; // forward
public:
/**
* 1、将fBuckets指向fStaticBuckets,初始化其他几个数据成员
* 2、将FStaticBuckets数值清零(全置为NULL)
*/
BasicHashTable(int keyType);
virtual ~BasicHashTable();
//======== class iteratr =====================================
// Used to iterate through the members of the table:
class Iterator; friend class Iterator; // to make Sun's C++ compiler happy
class Iterator : public HashTable::Iterator {
public:
//绑定到table
Iterator(BasicHashTable& table);
private: // implementation of inherited pure virtual functions
//设置key为下一个节点的key,返回下一个节点的value。如果下一个不存在,返回NULL
void* next(char const*& key); // returns 0 if none
private:
BasicHashTable& fTable; //绑定一个哈希表
unsigned fNextIndex; // index of next bucket to be enumerated after this
TableEntry* fNextEntry; // next entry in the current bucket
};
//===========================================================
private: // implementation of inherited pure virtual functions
//继承的纯虚函数的实现
virtual void* Add(char const* key, void* value);
// Returns the old value if different, otherwise 0
// 如果不同的话返回旧值,否则为0
virtual Boolean Remove(char const* key);
virtual void* Lookup(char const* key) const;
// Returns 0 if not found
//获取当前条目数
virtual unsigned numEntries() const;
private:
//======== class TableEntry =================================
class TableEntry {
public:
TableEntry* fNext; //下一个指针
char const* key; //键
void* value; //值
};
//===========================================================
//使用key来确定index和要查找的条目
TableEntry* lookupKey(char const* key, unsigned& index) const;
// returns entry matching "key", or NULL if none
//返回“key”匹配的条目,如果没有找到返回null
//比较两个key是否一样
Boolean keyMatches(char const* key1, char const* key2) const;
// used to implement "lookupKey()"
// 用于实现 "lookupKey()"
//创建一个条目,将其放入到桶数组的index位置
TableEntry* insertNewEntry(unsigned index, char const* key);
// creates a new entry, and inserts it in the table
// 创建一个新条目,并插入到这个哈希表
//给一个条目entry的key成员赋值(绑定一个key)
void assignKey(TableEntry* entry, char const* key);
// used to implement "insertNewEntry()"
// 用于实现“insertNewEntry”
//从哈希表中找到entry,移除后销毁
void deleteEntry(unsigned index, TableEntry* entry);
//将条目entry的key删除
void deleteKey(TableEntry* entry);
// used to implement "deleteEntry()"
// 用于实现 "deleteEntry()"
//重建哈希表,重建的尺寸是以前的四倍
void rebuild(); // rebuilds the table as its size increases
//重建表作为它的尺寸的增加而增加
//从key散列索引,通过key来获取一个索引值
unsigned hashIndexFromKey(char const* key) const;
// used to implement many of the routines above
// 用于实现许多以上的程序
//随机索引,其实并非随机。产生一个与i有关的随机值,这是单向不可逆的
unsigned randomIndex(uintptr_t i) const {
//1103515245这个数很有意思,rand函数线性同余算法中用来溢出的
//这个函数的作用就是返回一个随机值,因为默认fMask(0x3),也就是只保留两位
//为什么只要保留2位,也就是0 1 2 3 这四种结果咯,因为桶默认只有四个
return (unsigned)(((i * 1103515245) >> fDownShift) & fMask);
}
private:
TableEntry** fBuckets; // pointer to bucket array 指向 桶数组,桶中保存TableEntry对象地址
TableEntry* fStaticBuckets[SMALL_HASH_TABLE_SIZE];// used for small tables 用于小表
unsigned fNumBuckets/*桶数*/, fNumEntries/*节点数*/, fRebuildSize/*重建尺寸大小*/,
fDownShift/*降档变速*/, fMask/*掩码*/;
int fKeyType;
};
迭代器BasicHashTable::Iterator
这里把迭代器先分析了,这个迭代器是继承自HashTable::Iterator的。
通过看代码可知,其被class BasciHashTable声明为了友元类。
成员fTable是一个BasicHashTable对象的引用,所以其构造的时候必须绑定一个BasicHashTable对象。成员fNextEntry和fNextIndex是用来查找TableEntry条目用的,这个在next方法中会详细介绍。
class Iterator; friend class Iterator; // to make Sun's C++ compiler happy
class Iterator : public HashTable::Iterator {
public:
//绑定到table
Iterator(BasicHashTable& table);
private: // implementation of inherited pure virtual functions
//设置key为下一个节点的key,返回下一个节点的value。如果下一个不存在,返回NULL
void* next(char const*& key); // returns 0 if none
private:
BasicHashTable& fTable; //绑定一个哈希表
unsigned fNextIndex; // index of next bucket to be enumerated after this
TableEntry* fNextEntry; // next entry in the current bucket
};
BasicHashTable::Iterator的构造和析构
BasicHashTable::Iterator在构造的时候,将fNextIndex置为了0,而fNextEntry置为NULL。仅仅是绑定了一个table。就是迭代器构建的时候,并没有指向一个条目。
那么它的析构呢?答案是没有。BasicHashTable::Iterator并没有定义析构函数,其使用默认的析构。为什么呢?因为BasicHashTable::Iterator迭代器对象只会指向已经存在的条目,而不会自己创造条目。不存在内存的手动申请释放问题。
BasicHashTable::Iterator::Iterator(BasicHashTable& table)
: fTable(table), fNextIndex(0), fNextEntry(NULL) {
}
BasicHashTable:: Iterator::next(char const*& key)方法
这个方法就重要了,这是在迭代器里面最重要方法了。它指示了迭代器的工作原理。
前面已经说过了,fNextEntry指针在构造的时候初始化为NULL了,而fNextIndex初始化为0了。所以这里必须要先找到一个可以用于索引的条目。于是先从桶数组fBuckets的第一个桶开始找,遍历桶,直到找到一个有指向条目的桶,如果找遍了都没有找到,那就直接返回NULL咯。
这里要注意的是fNextIndex的重要性,它保证了不会使得迭代器只用于一个桶所指向的链表,而是在走到链表尾部之后,会走向下一个可用桶去。
如果迭代器不是刚刚构造的,或还没有走到链表的尾部。已经使用过了,那么fNextEntry不为NULL,就可以直接做后续的步骤了。
如果迭代器指向了一个可用的TableEntry,那么就设置参数key(注意参数类型,是一个指针的引用)指向这个条目的key,同时返回这个条目的value。同时必须将fNextEntry指向下一个条目。
void* BasicHashTable::Iterator::next(char const*& key) {
while (fNextEntry == NULL) {
//如果下一个索引值大于哈希表的桶数,返回NULL
if (fNextIndex >= fTable.fNumBuckets) return NULL;
//fNextEntry指向对应的桶位置,fNextEntry后移
fNextEntry = fTable.fBuckets[fNextIndex++];
}
BasicHashTable::TableEntry* entry = fNextEntry;
fNextEntry = entry->fNext;
key = entry->key; //设置key
return entry->value; //返回值
}
BasicHashTable的构造
BasicHashTable的构造过程很简单,但是要注意的是其参数keyType,这说明了这个BasicHashTable中保存条目的key的类型是一致的。在HashTable.hh文件中定义了两个const量,如果不是这两个定义的,那么key会当作unsigned int*类型,keyType的值代表key指向的内存空间元素个数。
int const STRING_HASH_KEYS = 0; //字符串型key
int const ONE_WORD_HASH_KEYS = 1; //这个直接当作char*变量,实质是作为整数在用
还有SMALL_HASH_TABLE_SIZE这个值,这是一个宏定义,其是 4 。另一个是REBUILD_MULTIPLIER(重建乘数)其是 3 。这两个值确定了初始的时候桶bucket的个数,即桶数组fBuckets的大小。一个确定重新建桶数组的临界条件。在每次条目数到了桶数的3倍的时候就会重建桶,重建的桶数(fNumBuckets)是之前的4倍。
fDownShift和fMask这两个值是用于将key散列到index时候用的。fDownShift在每次重建桶的时候会减2,所以14次重建桶其就为0了。但是基本不会有这么多次重建,7次重建之后,桶的数目就达到了4^8=65536个。
初始化的时候,每个桶都被初始化为了NULL,这时候哈希表中还没有条目。
BasicHashTable::BasicHashTable(int keyType)
: fBuckets(fStaticBuckets), fNumBuckets(SMALL_HASH_TABLE_SIZE),
fNumEntries(0), fRebuildSize(SMALL_HASH_TABLE_SIZE*REBUILD_MULTIPLIER),
fDownShift(28), fMask(0x3), fKeyType(keyType) {
for (unsigned i = 0; i < SMALL_HASH_TABLE_SIZE; ++i) {
fStaticBuckets[i] = NULL;
}
}
BasicHashTable的析构
BasicHashTable的析构中用到了deleteEntry方法,后面会详细的说这个方法,这里简要的说一下其作用。这个方法将第二个参数entry指向的条目从哈希表中移除,并将其delete。
BasicHashTable的析构会释放整个哈希表。逐个桶释放逐个条目链表。
BasicHashTable::~BasicHashTable() {
// Free all the entries in the table:
for (unsigned i = 0; i < fNumBuckets; ++i) {
TableEntry* entry;
while ((entry = fBuckets[i]) != NULL) {
deleteEntry(i, entry);
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号