HDFS部署测试记录(2019/05)
HDFS部署测试记录
参考资料:
0、HDFS基础知识
1、基本组成结构与文件访问过程
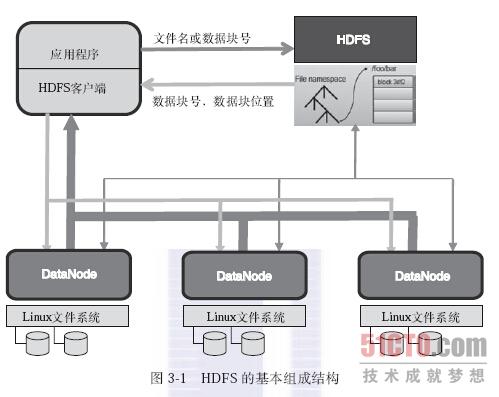
2、NameNode启动时如何维护元数据
1、概念介绍:
Edits文件:NameNode在本地操作hdfs系统的文件都会保存在Edits日志文件中。也就是说当文件系统中的任何元数据产生操作时,都会记录在Edits日志文件中。eg:在HDFS上创建一个文件,NameNode就会在Edits中插入一条记录。同样如果修改或者删除等操作,也会在Edits日志文件中新增一条数据。
FsImage映像文件:包括数据块到文件的映射,文件的属性等等,都存储在一个称为FsImage的文件中,这个文件也是放在NameNode所在的文件系统中。2、流程介绍:
①、加载fsimage映像文件到内存
②、加载edits文件到内存
③、在内存将fsimage映像文件和edits文件进行合并
④、将合并后的文件写入到fsimage中
⑤、清空原先edits中的数据,使用一个空的edits文件进行正常操作3、流程图分析:
4、疑问
因为NameNode只有在启动的阶段才合并fsimage和edits,那么如果运行时间长了,edits文件可能会越来越大,在下一次启动NameNode时会花很长的时间,请问能否让fsimage映像文件和edits日志文件定期合并呢?
答案肯定是可以的,为了解决这个问题我们就要用到Secondary NameNode了,Secondary NameNode主要的作用是什么呢?他是如何将fsimage和edits进行合并的呢?带着疑问再次进行分析。二、Secondary NameNode工作流程:
1、Secondary NameNode和NameNode的区别:
NameNode:
①、存储文件的metadata,运行时所有数据都保存在内存中,这个的HDFS可存储的文件受限于NameNode的内存。
②、NameNode失效则整个HDFS都失效了,所以要保证NameNode的可用性。
Secondary NameNode:
①、定时与NameNode进行同步,定期的将fsimage映像文件和Edits日志文件进行合并,并将合并后的传入给NameNode,替换其镜像,并清空编辑日志。如果NameNode失效,需要手动的将其设置成主机。
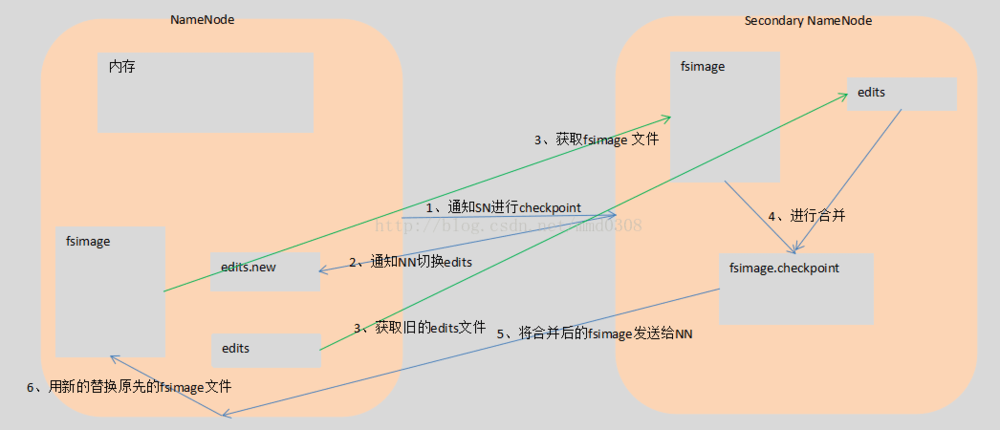
②、Secondary NameNode保存最新检查点的目录和NameNode的目录结构相同。所以NameNode可以在需要的时候应用Secondary NameNode上的检查点镜像。2、什么时候checkpoint
①、连续两次的检查点最大时间间隔,默认是3600秒,可以通过配置“fs.checkpoint.period”进行修改
②、Edits日志文件的最大值,如果超过这个值就会进行合并即使不到1小时也会进行合并。可以通过“fs.checkpoint.size”来配置,默认是64M;3、Secondary NameNode的工作流程
①、NameNode通知Secondary NameNode进行checkpoint。
②、Secondary NameNode通知NameNode切换edits日志文件,使用一个空的。
③、Secondary NameNode通过Http获取NmaeNode上的fsimage映像文件(只在第一次的时候)和切换前的edits日志文件。
④、Secondary NameNode在内容中合并fsimage和Edits文件。
⑤、Secondary NameNode将合并之后的fsimage文件发送给NameNode。
⑥、NameNode用Secondary NameNode 传来的fsImage文件替换原先的fsImage文件。
4、流程图分析:
作者:0aaadcfeb361
链接:https://www.jianshu.com/p/f01e3626fbf9
来源:简书
简书著作权归作者所有,任何形式的转载都请联系作者获得授权并注明出处。

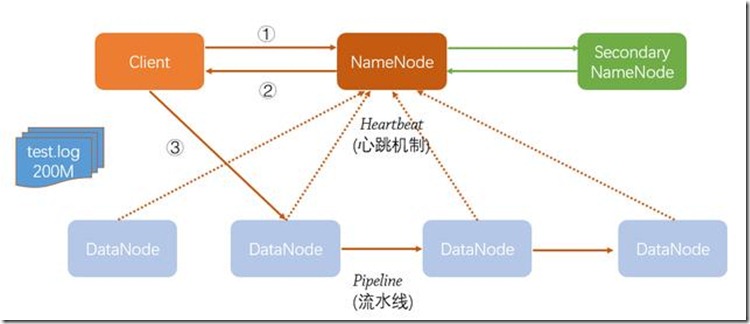
3、HDFS文件上传流程
下图描述了Client向HDFS上传一个200M大小的日志文件的大致过程:
1)首先,Client发起文件上传请求,即通过RPC与NameNode建立通讯。
2)NameNode与各DataNode使用心跳机制来获取DataNode信息。NameNode收到Client请求后,获取DataNode信息,并将可存储文件的节点信息返回给Client。
3)Client收到NameNode返回的信息,与对应的DataNode节点取得联系,并向该节点写文件,写入文件被切分成128m大小的数据块,最后一块可能不够128m,一个数据块里不能同时存储2个以上文件的数据。
4)文件写入到DataNode后,以流水线的方式复制到其他DataNode(以3份冗余为例,数据块副本策略为:第一个块写入最近的机架上的一台服务器,第二个块由第一个块复制到同一个机架上的另一台主机上,最后一个副本被第二个副本主机复制到不同机架的不同主机上),至于复制多少份,与所配置的hdfs-default.xml中的dfs.replication相关。
1、系统环境
硬件准备如下:
两台台式机、两台笔记本
操作系统:CentOS 7 1810版本
1、安装大致记录:
1、安装操作系统,每台机器预留一个盘未使用。安装的时候选择基本服务器,选中安装Java环境。
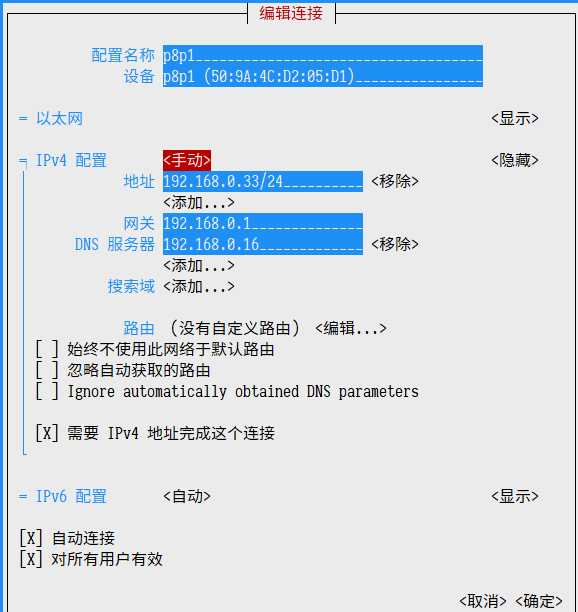
2、设置静态IP
nmtui --> Edit Connect --> p8p1 --> Manual --> 设置静态IP
编辑连接 网卡设备 手动 IP地址
# 设置成功后需要重新启动网络服务
systemctl restart network
ip a #查看是否有效

3、配置Master免密码SSH登录Slave
首先,在Master主机上,使用ssh-keygen命令生成rsa公私钥对文件:
> ssh-keygen -t rsa
Generating public/private rsa key pair.
Enter file in which to save the key (/home/hdfs/.ssh/id_rsa):
Created directory '/home/hdfs/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/hdfs/.ssh/id_rsa.
Your public key has been saved in /home/hdfs/.ssh/id_rsa.pub.
The key fingerprint is:
SHA256:DhiGxXsKCgLB8neD6O8kITIB51rBnnE/N7vgkwelxLQ hdfs@hdfs.0
The key's randomart image is:
+---[RSA 2048]----+
|+oo.. |
|++o+o . |
|+o+=o* . |
|o+*.+oE + |
|Bo.o.=.*So |
|oo... +o. |
| .... +.. |
| o. + o |
| .. o |
+----[SHA256]-----+
然后将使用ssh-copy-id命令将公钥ID发送到三台Slave主机上:
> ssh-copy-id 192.168.0.31
/usr/bin/ssh-copy-id: INFO: Source of key(s) to be installed: "/home/hdfs/.ssh/id_rsa.pub"
The authenticity of host '192.168.0.31 (192.168.0.31)' can't be established.
ECDSA key fingerprint is SHA256:aALaCB/ir5BTIA2EUWyN1jRmLSRcnDs2ffr3Jo5+niw.
ECDSA key fingerprint is MD5:3d:b6:ba:a8:e2:56:0f:93:31:9b:66:61:98:c9:fb:e2.
Are you sure you want to continue connecting (yes/no)? yes
/usr/bin/ssh-copy-id: INFO: attempting to log in with the new key(s), to filter out any that are already installed
/usr/bin/ssh-copy-id: INFO: 1 key(s) remain to be installed -- if you are prompted now it is to install the new keys
hdfs@192.168.0.31's password:
Number of key(s) added: 1
Now try logging into the machine, with: "ssh '192.168.0.31'"
and check to make sure that only the key(s) you wanted were added.
/home/hdfs [hdfs@hdfs] [14:25]
> ssh-copy-id 192.168.0.32
/home/hdfs [hdfs@hdfs] [14:25]
> ssh-copy-id 192.168.0.33
完成上述操作之后,在Master主机上就可以无需密码登录三台Slave主机了。
2、磁盘分区
安装好系统后,对未使用的磁盘进行分区,可以使用parted命令进行:
sudo parted
GNU Parted 3.1
使用 /dev/sda
Welcome to GNU Parted! Type 'help' to view a list of commands.
# 输入help查看命令列表
(parted) help
align-check TYPE N check partition N for TYPE(min|opt) alignment
help [COMMAND] print general help, or help on COMMAND
mklabel,mktable LABEL-TYPE create a new disklabel (partition table)
mkpart PART-TYPE [FS-TYPE] START END make a partition
name NUMBER NAME name partition NUMBER as NAME
print [devices|free|list,all|NUMBER] display the partition table, available devices, free space, all found partitions, or a particular partition
quit exit program
rescue START END rescue a lost partition near START and END
resizepart NUMBER END resize partition NUMBER
rm NUMBER delete partition NUMBER
select DEVICE choose the device to edit
disk_set FLAG STATE change the FLAG on selected device
disk_toggle [FLAG] toggle the state of FLAG on selected device
set NUMBER FLAG STATE change the FLAG on partition NUMBER
toggle [NUMBER [FLAG]] toggle the state of FLAG on partition NUMBER
unit UNIT set the default unit to UNIT
version display the version number and copyright information of GNU Parted
# 打印输出当前磁盘分区状况。可使用select命令选择当前磁盘
(parted) print list
Model: ATA ST1000DM003-1ER1 (scsi)
Disk /dev/sda: 1000GB
Sector size (logical/physical): 512B/4096B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system 标志
1 1049kB 107GB 107GB primary xfs 启动
2 107GB 116GB 8590MB primary linux-swap(v1)
# 使用mkpart命令创建分区,创建分区后需要进行格式化
(parted) mkpart
分区类型? primary/主分区/extended/扩展分区? primary
文件系统类型? [ext2]? ext4
起始点? 116G
结束点? 1000G
# 再次查看
(parted) print list
Model: ATA ST1000DM003-1ER1 (scsi)
Disk /dev/sda: 1000GB
Sector size (logical/physical): 512B/4096B
Partition Table: msdos
Disk Flags:
Number Start End Size Type File system 标志
1 1049kB 107GB 107GB primary xfs 启动
2 107GB 116GB 8590MB primary linux-swap(v1)
3 116GB 1000GB 884GB primary
创建分区之后进行格式化
sudo mkfs --type=ext4 /dev/sda3
mke2fs 1.42.9 (28-Dec-2013)
文件系统标签=
OS type: Linux
块大小=4096 (log=2)
分块大小=4096 (log=2)
Stride=0 blocks, Stripe width=0 blocks
53977088 inodes, 215878656 blocks
10793932 blocks (5.00%) reserved for the super user
第一个数据块=0
Maximum filesystem blocks=2363490304
6589 block groups
32768 blocks per group, 32768 fragments per group
8192 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208,
4096000, 7962624, 11239424, 20480000, 23887872, 71663616, 78675968,
102400000, 214990848
Allocating group tables: 完成
正在写入inode表: 完成
Creating journal (32768 blocks): 完成
Writing superblocks and filesystem accounting information: 完成
使用lsblk命令查看分区的UUID
> lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sda
├─sda1 xfs root 96b41d6f-ec6b-4f99-bafc-928f7e1a6ff3 /
├─sda2 swap 305435df-f273-42e0-84c0-75ee168dd73d [SWAP]
└─sda3 ext4 fad60377-af57-4bb0-b192-71c14996c051
sr0
添加挂载信息到/etc/fstab文件中,然后执行mount -a挂载。
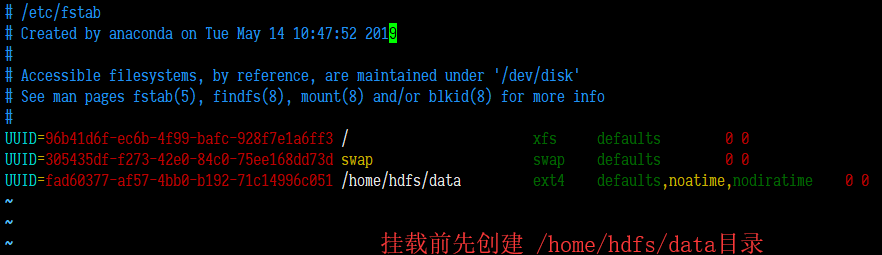
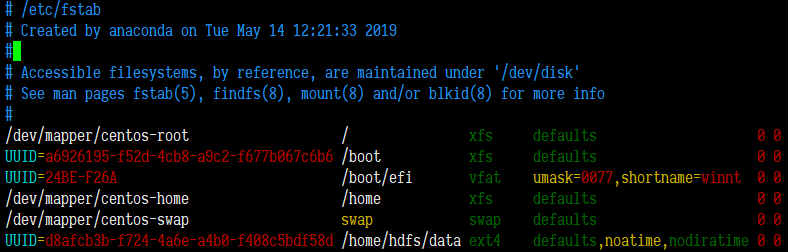
3、配置好的机器情况
| IP | 主机 | 磁盘状况 | |
|---|---|---|---|
| 192.168.0.30 | hdfs0(Namenode/Master) | 128G-SSD系统,500G-HDD数据 | |
| 192.168.0.31 | hdfs1(DataNode/Slave1) | 1T-HDD(100G系统,900G 数据) | |
| 192.168.0.32 | hdfs2(DataNode/Slave2) | 120G-SSD系统,1T-HDD数据 | |
| 192.168.0.33 | hdfs3(DataNode/Slave3) | 128G-SSD系统,1T-HDD数据 |
2、安装HDFS
对四台机器都做下面的步骤
先安装java(Hadoop 3.1.2必须是安装1.8.0版本JDK)基础运行环境:
sudo yum install java-1.8.0-openjdk java-1.8.0-openjdk-devel java-1.8.0-openjdk-headless java-1.8.0-openjdk-javadoc java-1.8.0-openjdk-accessibility
然后添加JAVA_HOME环境变量,这里修改/etc/profile文件来添加:
vim /etc/profile
# 在最后面添加
JAVA_HOME=/usr
export JAVA_HOME
export PATH=$PATH:/home/hdfs/hadoop-3.1.2/bin:/home/hdfs/hadoop-3.1.2/sbin
下载Hadoop包,这里直接下载编译好的二进制文件:
wget http://mirror.bit.edu.cn/apache/hadoop/common/hadoop-3.1.2/hadoop-3.1.2.tar.gz
下载完成之后直接解压:
tar -xzvf hadoop-3.1.2.tar.gz
解压之后可以进入hadoop-3.1.2/bin和hadoop-3.1.2/sbin(需要把这两个路径导入环境变量PATH中,也是在/etc/profile文件中添加export语句)运行一下里面的程序,如果能正常运行的话就没有问题了。
> export PATH=$PATH:/home/hdfs/hadoop-3.1.2/bin:/home/hdfs/hadoop-3.1.2/sbin
> hdfs
Usage: hdfs [OPTIONS] SUBCOMMAND [SUBCOMMAND OPTIONS]
OPTIONS is none or any of:
--buildpaths attempt to add class files from build tree
--config dir Hadoop config directory
--daemon (start|status|stop) operate on a daemon
--debug turn on shell script debug mode
--help usage information
--hostnames list[,of,host,names] hosts to use in worker mode
--hosts filename list of hosts to use in worker mode
--loglevel level set the log4j level for this command
--workers turn on worker mode
SUBCOMMAND is one of:
Admin Commands:
........
3、配置HDFS
当前HDFS的设计支持在集群中存在多个NameNode,且支持水平扩展。
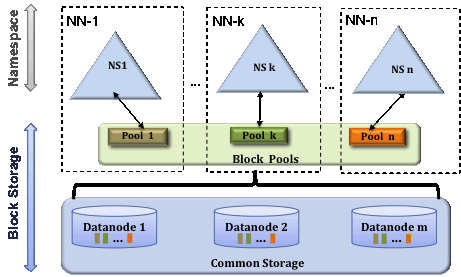
修改NameNode机器上的/home/hdfs/hadoop-3.1.2/etc/hadoop/目录下的core-site.xml文件,修改后大致如下:
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.0.30:9000</value>
<description>NameNode主机的 HDFS的URI,hdfs://namenode_ip:port</description>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hdfs/tmp</value>
<description>namenode 上传到 hadoop 的临时文件夹</description>
</property>
<property>
<name>fs.trash.interval</name>
<value>4320</value>
</property>
</configuration>
修改NameNode机器上的/home/hdfs/hadoop-3.1.2/etc/hadoop/目录下的hdfs-site.xml文件,修改后大致如下:
<configuration>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/hdfs/name</value>
<description>DataNode上存储 hdfs 名字空间元数据的目录</description>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/hdfs/data</value>
<description>DataNode上数据块的存储位置</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
<description>副本个数,默认配置是 3,应小于datanode机器数量</description>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.permissions.superusergroup</name>
<value>staff</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
</configuration>
修改完成之后,拷贝这两个文件覆盖DataNode主机下面的同名文件。
在NameNode机器上的/home/hdfs/hadoop-3.1.2/etc/hadoop/目录下添加slaves文件,逐行写入DataNode主机的IP。
vim slaves
192.168.0.31
192.168.0.32
192.168.0.33
在NameNode节点上执行下面命令进行HDFS格式化操作,执行操作后会在配置文件指定的相关目录下生成相关的文件。
hdfs namenode -format
然后执行start-dfs.sh启动HDFS服务。
遇到的错误及处理
错误:Error: JAVA_HOME is not set and could not be found.
打开/home/hdfs/hadoop-3.1.2/etc/hadoop/hadoop-env.sh文件,添加export JAVA_HOME=/usr(根据实际情况修改路径)。
错误:ERROR: Cannot set priority of datanode process
权限原因,这里是因为指定的data目录拥有者不是当前运行hdfs的用户,所以直接执行sudo chown hdfs:hdfs /home/hdfs/data修改即可。
(这里是因为默认挂载磁盘的是root用户)
错误:Unresolved datanode registration: hostname cannot be resolved (ip=192.168.0.33, hostname=192.168.0.33)
这个需要在NameNode主机上修改/etc/hosts文件,添加几个DataNode主机名。(这个错误是在NameNode主机执行hdfs namenode,DataNode主机执行hdfs datanode出现的,因为直接执行start-dfs.sh不出现错误提示,也没有成功启动,这个问题还有待研究)
192.168.0.31 hdfs1
192.168.0.32 hdfs2
192.168.0.33 hdfs3
错误:无法在NameNode之外的主机访问http://namenodeip:50070地址。
这个是因为在服务绑定的是本地环回地址,而不是对外网络地址。这里修改NameNode主机上的hdfs-site.xml文件,在里面添加如下设置即可:
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
完成配置后,对HDFS系统概览
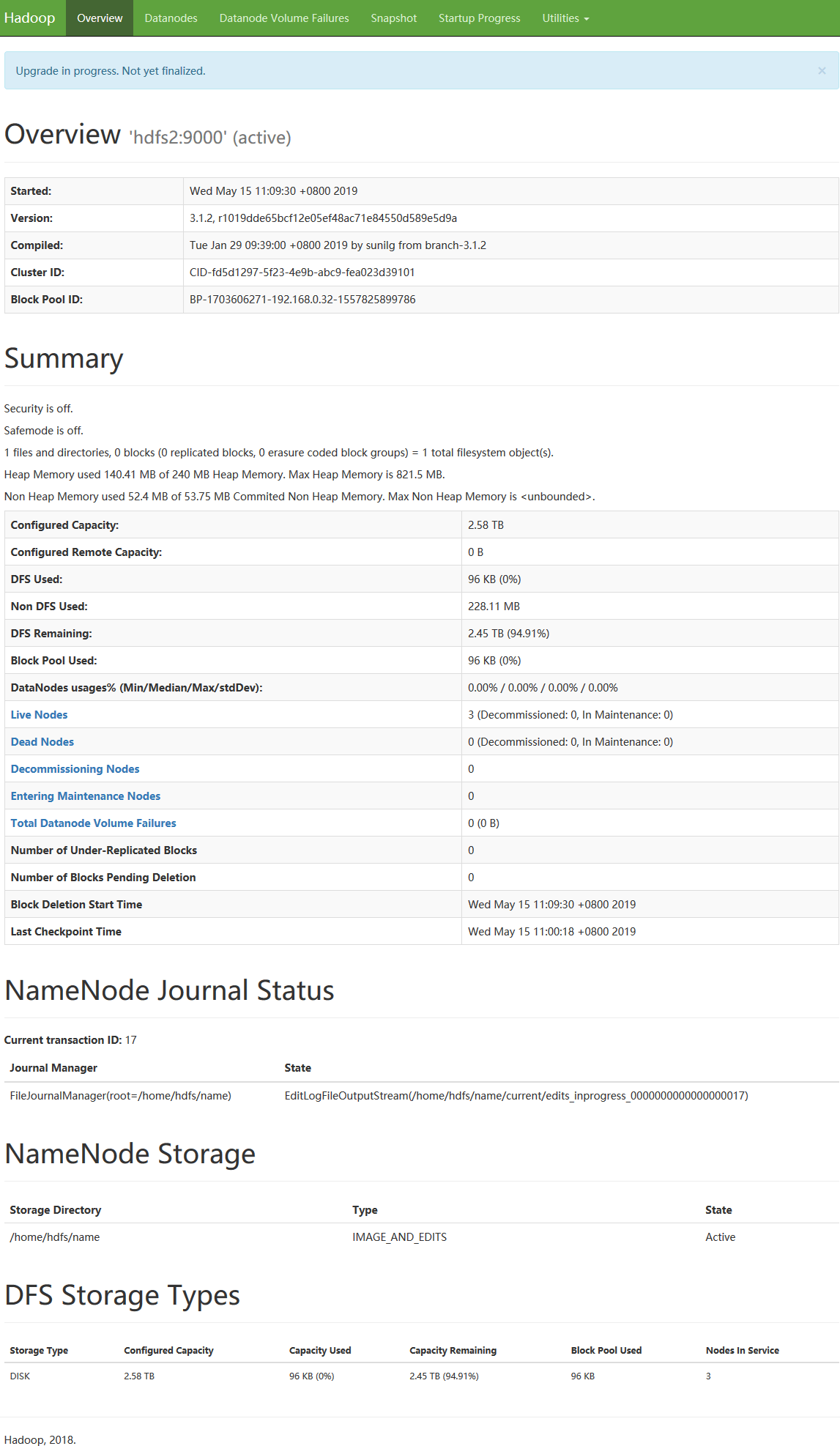
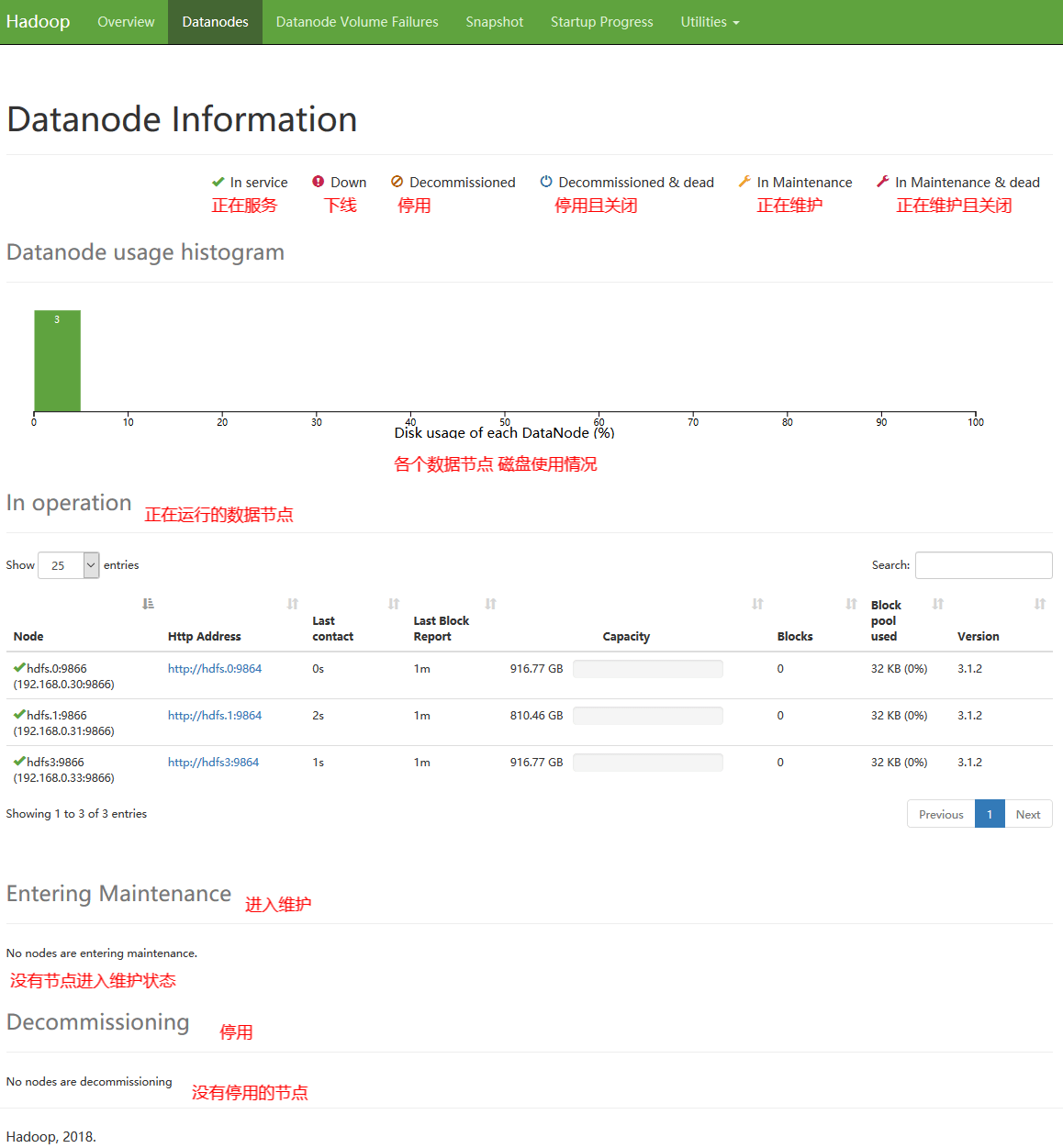
4、读写文件测试
挂载window共享目录
sudo mount -t cifs -o username=Administrator -o password=xxxxxxxxx //192.168.0.46/d /mnt/46
在要操作HDFS的机器上,必须要能够通过主机名访问对应的DataNode节点,所以需要将DataNode节点的名称和IP映射写入Hosts文件(或者可以使用一个本地的域名服务器,并在上添加相应的记录)。
上传一个目录到HDFS上:
> time hadoop fs -put /mnt/46/src_data/xx512/* /rsimage/xx-512
hadoop fs -put /mnt/46/src_data/xx512/* /rsimage/xx-512 456.41s user 467.21s system 31% cpu 49:12.57 total
上传的目录上有271GB大小的文件,这里的速度差不多是94MB每秒。
监控下网络流量情况
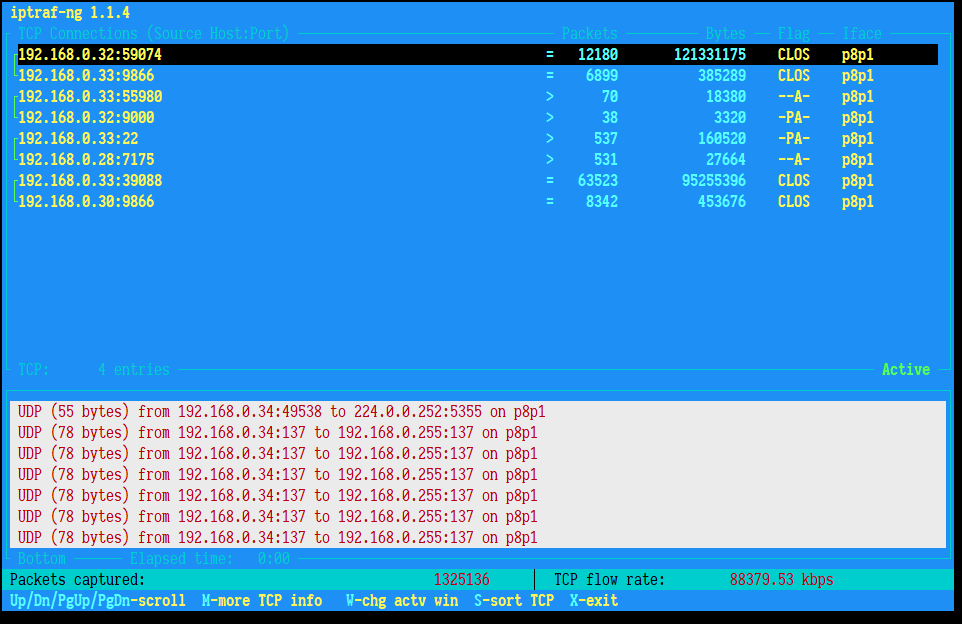
dd命令测试读取速度(在非DataNode节点测试)
dd bs=64k if=/mnt/hdfs/rsimage/xx-512/xxxx.img of=/dev/null
记录了24421+1 的读入
记录了24421+1 的写出
1600485903字节(1.6 GB)已复制,14.9559 秒,107 MB/秒
#-----------------省略多余的分割线----------------
dd bs=64k if=/mnt/46/src_data/xx/xxxx.img of=/dev/null
记录了23952+1 的读入
记录了23952+1 的写出
1569778398字节(1.6 GB)已复制,13.4775 秒,116 MB/秒
#-----------------省略多余的分割线----------------
dd bs=64k if=/mnt/46/src_data/xx/xxxx.img of=/dev/null
记录了23952+1 的读入
记录了23952+1 的写出
1569778398字节(1.6 GB)已复制,13.343 秒,118 MB/秒
#-----------------省略多余的分割线----------------
dd bs=64k if=/mnt/hdfs/rsimage/xx-512/xxxx.img of=/dev/null
记录了24421+1 的读入
记录了24421+1 的写出
1600485903字节(1.6 GB)已复制,13.7455 秒,116 MB/秒
在某个DataNode节点测试
/home/hdfs/test/caddy [hdfs@hdfs] [14:01]
> dd bs=64k if=/mnt/46/src_data/xx/xxxx.img of=/dev/null
记录了23952+1 的读入
记录了23952+1 的写出
1569778398字节(1.6 GB)已复制,13.45 秒,117 MB/秒
/home/hdfs/test/caddy [hdfs@hdfs] [14:02]
> dd bs=64k if=/mnt/hdfs/rsimage/xx-512/xxxx.img of=/dev/null
记录了24421+1 的读入
记录了24421+1 的写出
1600485903字节(1.6 GB)已复制,9.56565 秒,167 MB/秒

 浙公网安备 33010602011771号
浙公网安备 33010602011771号