博客园备份提取
简述
在博客园记录了一些文章,想把它备份到github上,还好大部分博文都是markdown格式的,博客园也支持备份导出,但是到处的是单个的XML文件。
为了把每一篇博文单独提取出来,所以写了一个小程序来提取。
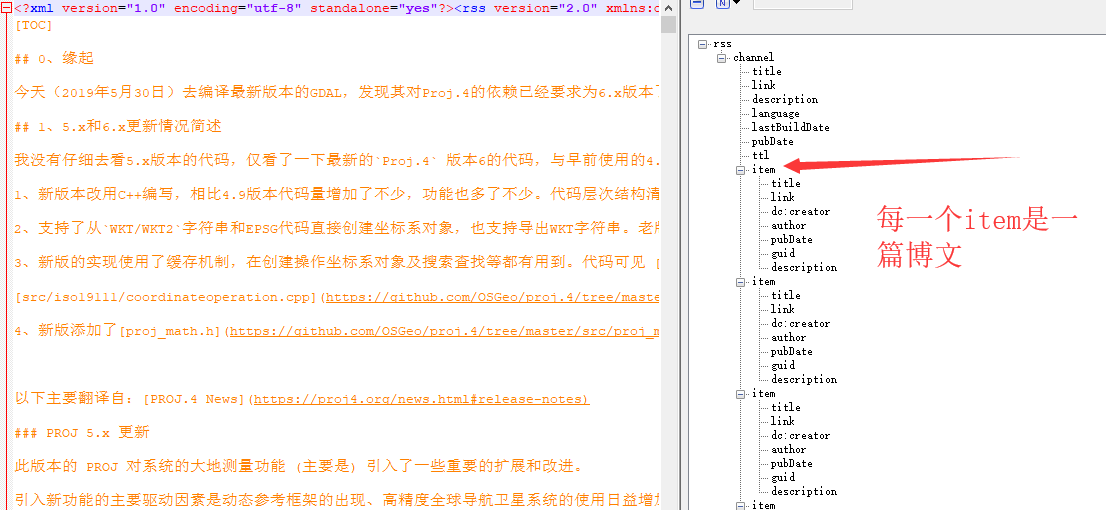
github中需要如下图所示的格式,方能正确的分类
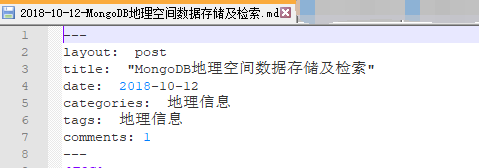
文件名需要日期开头,文件内容中最前面一段是文章的一些描述信息
程序代码
程序是用Golang编写的,代码如下:
// cnblogs2githubpages project main.go
package main
import (
"bytes"
"encoding/xml"
"fmt"
"io/ioutil"
"os"
"strings"
"time"
)
// 结构体中要能够进行XML解析,则字段名必须以大写开头
// 帖子
type Post struct {
XMLName xml.Name `xml:"item"`
Title string `xml:"title"`
Link string `xml:"link"`
Creator string `xml:"dc:creator"`
Author string `xml:"author"`
PubDate string `xml:"pubDate"`
Guid string `xml:"guid"`
Description string `xml:"description,CDATA"`
}
type Blogs struct {
XMLName xml.Name `xml:"channel"`
Title string `xml:"title"`
Link string `xml:"link"`
Description string `xml:"description"`
Language string `xml:"language"`
LastBuildDate string `xml:"lastBuildDate"`
PubDate string `xml:"pubDate"`
Ttl string `xml:"ttl"`
Items []Post `xml:"item"`
}
type RSS struct {
XMLName xml.Name `xml:"rss"`
Blogs Blogs `xml:"channel"`
}
func main() {
if len(os.Args) != 2 {
return
}
backupxml, err := ioutil.ReadFile(os.Args[1])
if err != nil {
fmt.Println(err.Error())
return
}
fmt.Println(len(backupxml))
b := RSS{}
err = xml.Unmarshal(backupxml, &b)
if err != nil {
fmt.Println(err.Error())
return
}
fmt.Println(len(b.Blogs.Items))
// 逐个导出
for i, _ := range b.Blogs.Items {
var item = &(b.Blogs.Items[i])
t, _ := time.Parse(time.RFC1123, item.PubDate)
postdate := t.Format("2006-01-02")
// fmt.Printf("%s\n\t%s\n\t%s\n\t%s\n\t%s\n", date, item.Title, item.Link, item.Author, item.Description[0:64])
postTitle := strings.ReplaceAll(item.Title, " ", "-")
postTitle = strings.ReplaceAll(postTitle, "*", "")
postTitle = strings.ReplaceAll(postTitle, "/", ".")
postTitle = strings.ReplaceAll(postTitle, "\\", "")
postTitle = strings.ReplaceAll(postTitle, "$", "")
postTitle = strings.ReplaceAll(postTitle, "?", "")
postTitle = strings.ReplaceAll(postTitle, ":", "-")
postTitle = strings.ReplaceAll(postTitle, "。", "")
filename := fmt.Sprintf("./%s-%s.md", postdate, postTitle)
fmt.Println(filename)
// 根据博文的标题,做一个简单的分类(只适合当前情况)
var categories string = "其它"
{
title2 := strings.ToLower(item.Title)
if strings.Contains(title2, "live555") {
categories = "live555"
} else if strings.Contains(title2, "linux") || strings.Contains(title2, "ubuntu") {
categories = "linux"
} else if strings.Contains(title2, "gcc") || strings.Contains(title2, "git") ||
strings.Contains(title2, "编程") || strings.Contains(title2, "编译") ||
strings.Contains(title2, "vc") || strings.Contains(title2, "c++") ||
strings.Contains(title2, "visual") || strings.Contains(title2, "程序") {
categories = "编程"
} else if strings.Contains(title2, "gdal") || strings.Contains(title2, "proj") ||
strings.Contains(title2, "gis") || strings.Contains(title2, "地理") {
categories = "地理信息"
}
}
var desc bytes.Buffer
desc.WriteString("---\r\n")
desc.WriteString("layout: post\r\n")
desc.WriteString("title: \"")
desc.WriteString(item.Title)
desc.WriteString("\"\r\ndate: ")
desc.WriteString(postdate)
desc.WriteString("\r\ncategories: ")
desc.WriteString(categories)
desc.WriteString("\r\ntags: ")
desc.WriteString(categories)
desc.WriteString("\r\ncomments: 1\r\n")
desc.WriteString("---\r\n")
tocIndex := strings.Index(item.Description, "[TOC]")
if tocIndex != -1 {
tocIndex += len("[TOC]")
desc.WriteString(item.Description[0:tocIndex])
desc.WriteString("\r\n[博客园原文地址 ")
desc.WriteString(item.Link)
desc.WriteString("](")
desc.WriteString(item.Link)
desc.WriteString(")\r\n\r\n")
desc.WriteString(item.Description[tocIndex:])
} else {
desc.WriteString("\r\n[TOC]\r\n[博客园文章地址 ")
desc.WriteString(item.Link)
desc.WriteString("](")
desc.WriteString(item.Link)
desc.WriteString(")\r\n")
desc.WriteString(item.Description)
}
err := ioutil.WriteFile(filename, desc.Bytes(), os.ModePerm)
if err != nil {
fmt.Println(err.Error())
}
}
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号