julia的cpu和gpu实现版本
- Julia集是一种在复平面上非发散点形成的分形点的集合。具有非常美观的几何特征。
例如,对于复变函数的一个通项公式
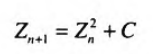
下面的代码包括cpu和gpu版本的Julia集算法
其中用到了一维索引和二维索引的转换关系
#include "cuda_runtime.h" #include "device_launch_parameters.h" #include <stdio.h> #include "common/book.h" #include "common/cpu_bitmap.h" const int DIM_WIDTH = 800; const int DIM_HEIGHT = 800; struct cuComplex{ float r, i; cuComplex(float a, float b):r(a), i(b) {} float magnitude2(void) { return r * r + i * i; } cuComplex operator*(const cuComplex & a) { return cuComplex(r * a.r - i * a.i, i * a.r + r * a.i); } cuComplex operator+(const cuComplex & a) { return cuComplex(r + a.r, i + a.i); } }; __device__ struct cuComplexGPU { float r, i; __device__ cuComplexGPU(float a, float b) :r(a), i(b) {} __device__ float magnitude2(void) { return r * r + i * i; } __device__ cuComplexGPU operator*(const cuComplexGPU& a) { return cuComplexGPU(r * a.r - i * a.i, i * a.r + r * a.i); } __device__ cuComplexGPU operator+(const cuComplexGPU& a) { return cuComplexGPU(r + a.r, i + a.i); } }; int juliaCPU(int x, int y) { const float scale = 1.5; float jx = scale*(float)(DIM_WIDTH / 2 - x) / (DIM_WIDTH / 2); float jy = scale*(float)(DIM_HEIGHT / 2 - y) / (DIM_HEIGHT / 2); cuComplex c(-0.8, 0.156); cuComplex a(jx, jy); int i = 0; for (i = 0; i < 200; i++) { a = a * a + c; if (a.magnitude2() > 1000) return 0; } return 1; } __device__ int juliaGPU(int x, int y) { const float scale = 1.5; float jx = scale * (float)(DIM_WIDTH / 2 - x) / (DIM_WIDTH / 2); float jy = scale * (float)(DIM_HEIGHT / 2 - y) / (DIM_HEIGHT / 2); cuComplexGPU c(-0.8, 0.156); cuComplexGPU a(jx, jy); int i = 0; for (i = 0; i < 200; i++) { a = a * a + c; if (a.magnitude2() > 1000) return 0; } return 1; } void julia(unsigned char *ptr) { for (int y = 0; y < DIM_HEIGHT; y++) { for (int x = 0; x < DIM_WIDTH; x++) { int offset = x + y * DIM_HEIGHT; int juliaValue = juliaCPU(x, y); ptr[offset * 4 + 0] = 255 * juliaValue; ptr[offset * 4 + 1] = 0; ptr[offset * 4 + 2] = 0; ptr[offset * 4 + 3] = 255; //printf("%d ", juliaValue); } } } __global__ void juliaKernel(unsigned char* ptr) { //map threadIdx/BlockIdx to cell pos int x = blockIdx.x; int y = blockIdx.y; int offset = x + y * gridDim.x; //calcualte the value on the cell pos int juliaValue = juliaGPU(x, y); ptr[offset * 4 + 0] = 255 * juliaValue; ptr[offset * 4 + 1] = 0; ptr[offset * 4 + 2] = 0; ptr[offset * 4 + 3] = 255; //printf("%d ", juliaValue); } void testJuliaSet() { CPUBitmap bitmap(DIM_WIDTH, DIM_HEIGHT); unsigned char* ptr = bitmap.get_ptr(); julia(ptr); bitmap.display_and_exit(); } void testGPUJuliaSet() { CPUBitmap bitmap(DIM_WIDTH, DIM_HEIGHT); unsigned char* dev_bitmap; HANDLE_ERROR(cudaMalloc((void**)&dev_bitmap, bitmap.image_size())); dim3 grid(DIM_WIDTH, DIM_HEIGHT); //configure the block grid juliaKernel<<<grid, 1>>>(dev_bitmap); HANDLE_ERROR(cudaMemcpy(bitmap.get_ptr(), dev_bitmap, bitmap.image_size(), cudaMemcpyDeviceToHost)); bitmap.display_and_exit(); HANDLE_ERROR(cudaFree(dev_bitmap)); } int main() { //testJuliaSet(); testGPUJuliaSet(); return 0; }


 浙公网安备 33010602011771号
浙公网安备 33010602011771号