图形处理单元GPU的特点和编程模式
GPU和中央处理单元(CPU)是完全不同的计算架构。前者最初是旨在加速视频数据处理。近年来,GPU已成为专门为并行计算设计的硬件组件。让我们用一个例子来说明这一点。假设我们希望在书中查找一个特定的单词。如果任务交给了CPU,它会从第一页到最后一页完整地阅读这本书,以查找单词,因为CPU是串行处理器,并按顺序进行搜索。然而,如果我们使用GPU,它是一个并行处理器,它将书分成大量部分,并同时读取所有部分。即使每个部分的读取速度都比CPU慢,整本书的读取时间也要短得多。将图形处理器用于非图形目的称为图形处理单元(GPGPU)上的通用计算。
最好的处理器之一Intel Core IV由八个内核组成,其中四个是通过超线程技术模拟的虚拟内核,用于改进计算的并行化。对于物理上存在的每个进程核,操作系统寻址两个虚拟处理器,然后尽可能在它们之间共享工作负载。同时,廉价的图形卡呈现了一种由10倍的核心IV组成的结构。例如,在Nvidia GTX 295中,480个线程或处理器被组合。如此大量的处理器赋予GPU巨大的并行计算能力。GPU在快速傅立叶变换计算(Moreland and Angel,2003)、信号处理(Fung and Mann,2004)、数字图像处理(Jeong等人,2011)、分子计算(蒙特卡洛和分子动力学模拟)(Ivan等人,2008;Alerstam等人,2008)等方面也有广泛的应用。Nvidia的王牌是CUDA,是一种并行计算体系结构,可通过多种编程语言供用户使用。换句话说,CUDA提供了使用GPU进行计算编程的机会。
GeForce:这是Nvidia设计的一系列GPU,用于本研究。GPU架构由芯片上的多个流处理器组成;参见图1(a)。它们被分组在分层组织的多处理器集群中;参见图1(b)。设备和主机分别是GPU和CPU。换句话说,大多数计算和数据都被卸载到设备(GPU)上,每个设备都有自己的随机存取存储器(RAM)。CPU和GPU的RAM分别称为动态RAM和设备存储器。每个多处理器都有一个可从其每个处理器访问的共享内存。此外,每个多处理器都有一个更大的内存空间,称为全局内存;参见图1(c)。全局存储器是主机和设备之间传输读/写或R/W信息的主要工具。通常,本地内存有一个小而快的空间,用于从全局内存调用数据,而线程存储在它们的本地寄存器中。根据图1(c),线程可以访问本地和全局存储器。此外,一些缓存被设置为加速对其存储器的访问。常量由主机初始化,并且对所有线程都可见。
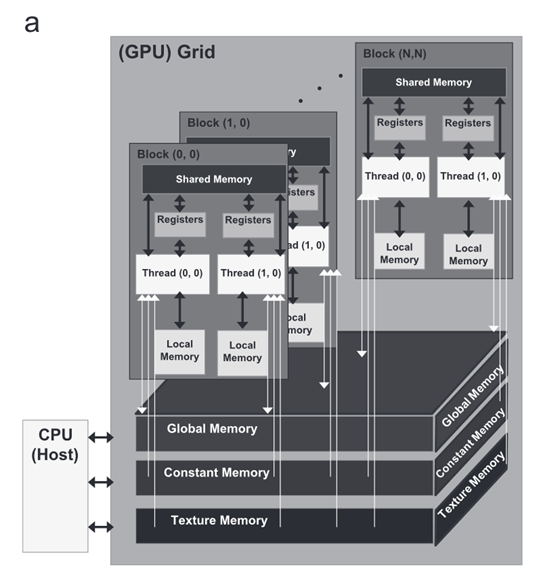
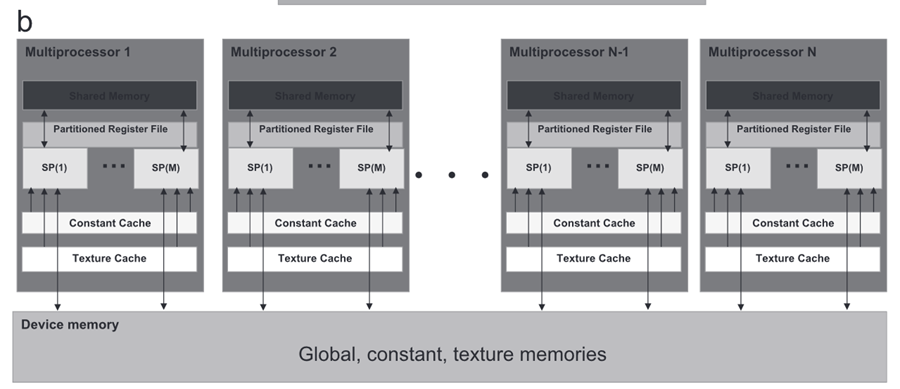
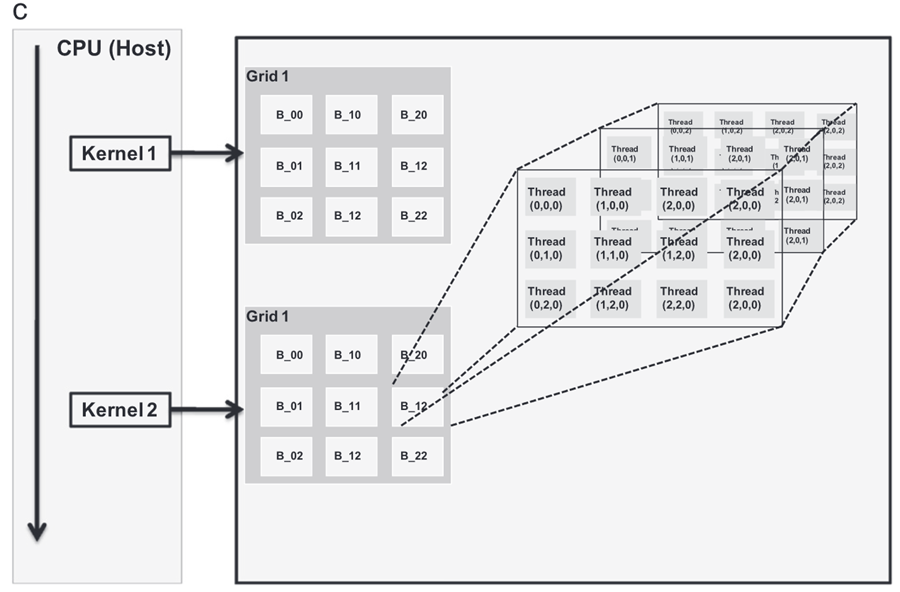
图1.CUDA编程模型。(a) 调用执行模型,显示全局GPU结构,通过该结构,它能够并行化命令(SP对于流处理器是即时的);(b) 具有全局、常量和纹理内存不同部分的CUDA设备内存分配的详细图像,以及(c)线程和块分配的示意图,该示意图将内核描述为不同块和网格中的线程集合(具有修改,采用自Nvidia,2008)。
名为kernel的操作用于以并行模式执行应用程序的各个部分,可以在不同的数据集上独立执行多次。因此,它相当于从主机调用并在设备上运行的函数。线程块是通过本地内存共享数据并同步执行工作的线程的集合。但是,不同块中的线程不能一起工作。一组块表示网格,如图1(c)所示。在任何时候,内核上的几个线程都会被执行;它们被称为线程块的网格。线程和块具有它们自己的标识,例如块ID,一维或二维,以及线程ID,其为1D、2D或3D,这简化了高速处理的存储器寻址。
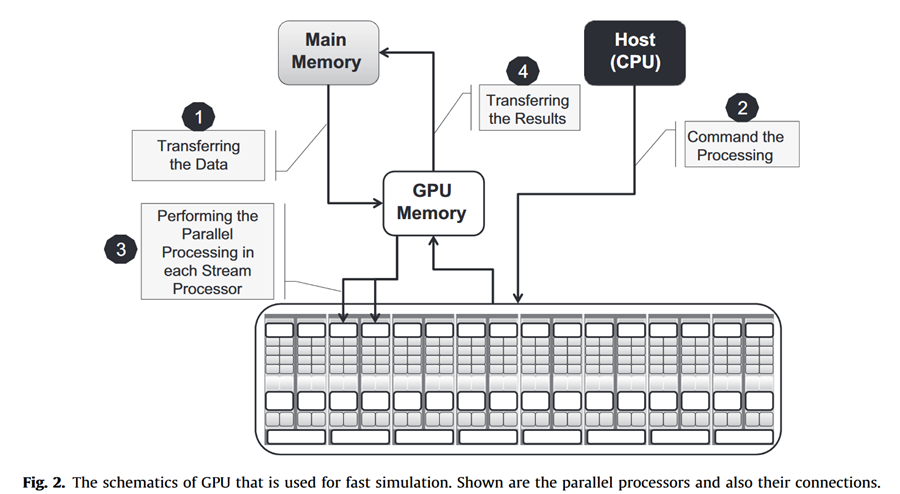
应该指出的是,CUDA和CPU的线程之间存在一些差异。例如,CUDA线程非常轻量级,这是由于很少的创建开销和即时切换。CUDA并行使用数千个线程,而可用的CPU只能使用少数线程。该架构如图2所示。CUDA的主要步骤总结如下(见图2)。首先,在主机和设备上分别分配内存。然后,通过使用CUDA应用程序编程接口(API),将来自主机的数据复制到设备中,然后定义线程和块的数量。接下来,在每个线程上,内核函数与其他内核上的函数并行执行。最后,使用CUDA API将设备中的数据复制到主机上。
尽管GPU具有所有优点,但它也有一些局限性。例如,由于在当前可用的GPU中,一个块中的所有线程同时工作,因此让每个线程执行不同的操作是低效的。一旦其中一个完成了工作,我们就向它提供新数据。换句话说,在由多个网格点组成的第一组中,GPU执行并行计算。由于馈入GPU的组没有任何冲突,因此模拟很容易完成。然后,下一组网格点被传输到GPU。使用网格点组的一个优点是避免CPU和GPU之间的数据传输,因为两者之间的数据带宽传输相对较低,这使得在两者之间传输最小数据量至关重要。
来源
[1] Tahmasebi P, Sahimi M, Mariethoz G, 等. Accelerating geostatistical simulations using graphics processing units (GPU)[J]. Computers & Geoscience, Elsevier, 2012.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号