GPU和CUDA概述
图形处理单元(GPU)是连接到图形卡的流处理器集群sm,用于极快处理大容量数据集。最初,GPU的可编程性涉及面向图形的细节,这使得应用程序非常有限。NVIDIA提供了一个用户友好的开发环境,名为计算统一设备架构(CUDA),它允许程序员像传统的CPU编程那样从内存和操作的角度进行思考。CUDA为我们生成在GPU上执行的并行代码提供了一种更简单的方法。
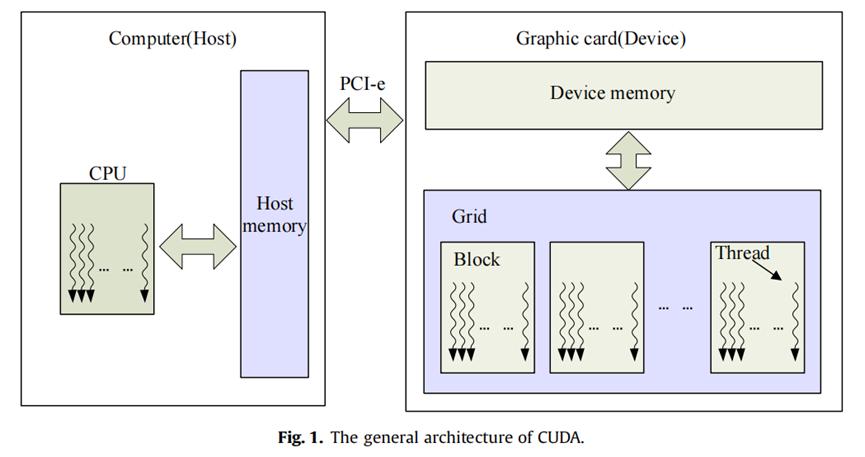
在大多数情况下,支持CUDA的GPU是安装在主机中的独立设备,通过名为PCI-e(外围组件互连快速)总线的接口进行通信,该总线用于在设备之间传输数据和命令。每个GPU是一个独立的设备,与主处理器异步运行,这意味着主处理器和所有GPU可以同时执行计算。除了少数与主机共享显示内存的设备外,GPU有自己的物理内存。尽管GPU内存的大小有限,但它可以提供比传统主机内存更高的内存带宽.
CUDA内核是可从主机调用的函数,在CUDA设备上异步执行,这意味着主机将内核排队,仅在GPU上执行,不等待内核完成,而是继续执行其他工作。尽管由于异步机制,CUDA内核无法返回值,但CUDA还提供了一些同步接口,以便主机可以确定内核或管道何时完成。
CUDA线程是GPU上的基本执行单元,就像每个线程都有自己的处理器,具有不同的寄存器和线程标识,在共享内存环境中运行。内核应该利用多个线程来执行这项工作。能够并发运行的线程数由GPU计算能力决定。板载GPU硬件线程调度程序负责线程切换和调度,这对CUDA开发人员是透明的。内核源代码中的执行配置定义了将运行内核的线程数量及其在1D、2D或3D计算网格中的排列。CUDA的总体架构如图1所示,Nvidia提供的文件(2011a,2011b)和其他相关文献(Farber,2011;Sanders和Kandrot,2010)中提供了CUDA编程和优化的更详细介绍。
来源

 浙公网安备 33010602011771号
浙公网安备 33010602011771号