
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。但是有些时候一昧的追求范式减少冗余,反而会降低数据读写的效率,这个时候就要反范式,利用空间来换时间。
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般说来,数据库只需满足第三范式(3NF)就行了。
三范式
第一范式(1NF)
即表的列的具有原子性,不可再分解,即列的信息,不能分解, 只要数据库是关系型数据库(mysql/oracle/db2/informix/sysbase/sql server),就自动的满足1NF。
关系型数据库: mysql/oracle/db2/informix/sysbase/sql server
非关系型数据库: (特点: 面向对象或者集合)
NoSql数据库: MongoDB/redis(特点是面向文档)
第二范式(2NF)
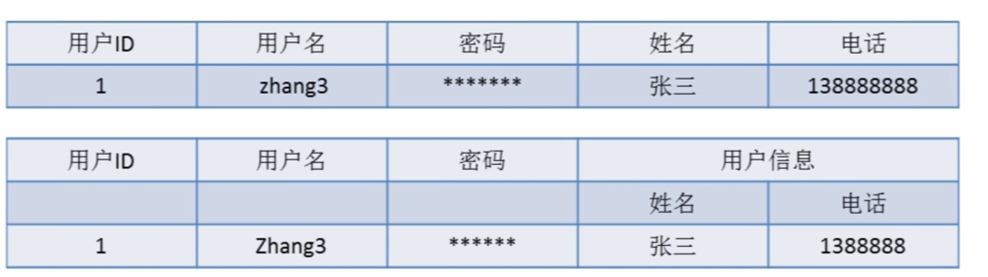
第二范式(2NF)是在第一范式(1NF)的基础上建立起来的,即满足第二范式(2NF)必须先满足第一范式(1NF)。第二范式(2NF)要求数据库表中的每个实例或行必须可以被惟一地区分。为实现区分通常需要我们设计一个主键来实现(这里的主键不包含业务逻辑)
第三范式(3NF)
满足第三范式(3NF)必须先满足第二范式(2NF)。简而言之,第三范式(3NF)要求一个数据库表中不包含已在其它表中已包含的非主键字段。就是说,表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放(能尽量外键join就用外键join)。很多时候,我们为了满足第三范式往往会把一张表分成多张表
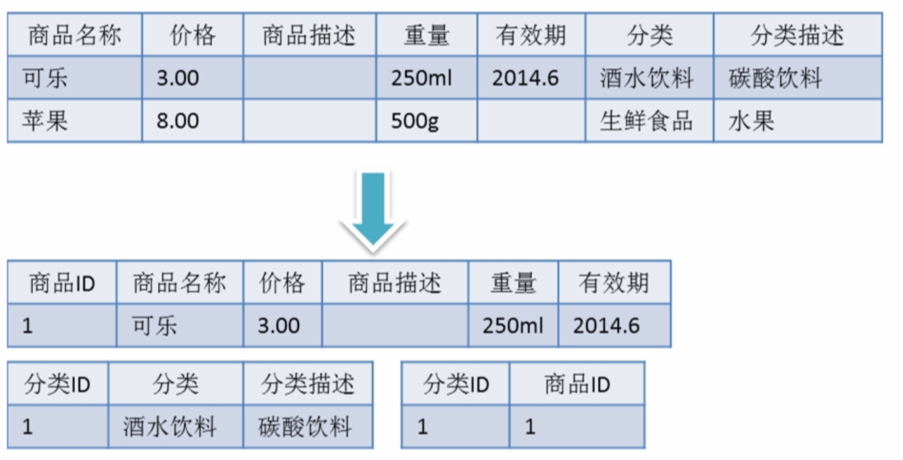
反三范式
没有冗余的数据库未必是最好的数据库,有时为了提高运行效率,就必须降低范式标准,适当保留冗余数据。具体做法是: 在概念数据模型设计时遵守第三范式,降低范式标准的工作放到物理数据模型设计时考虑。降低范式就是增加字段,减少了查询时的关联,提高查询效率,因为在数据库的操作中查询的比例要远远大于DML的比例。但是反范式化一定要适度,并且在原本已满足三范式的基础上再做调整的。
知乎上对范式和反范式的理解
摘自 https://www.zhihu.com/question/19900437
著作权归作者所有。
商业转载请联系作者获得授权,非商业转载请注明出处。
作者:孙文亮
链接:https://www.zhihu.com/question/19900437/answer/14089402
来源:知乎
数据库设计应该也是分为三个境界的:
第一个境界,刚入门数据库设计,范式的重要性还未深刻理解。这时候出现的反范式设计,一般会出问题。
第二个境界,随着遇到问题解决问题,渐渐了解到范式的真正好处,从而能快速设计出低冗余、高效率的数据库。
第三个境界,再经过N年的锻炼,是一定会发觉范式的局限性的。此时再去打破范式,设计更合理的反范式部分。
范式就像武侠里面的招数,初学者妄想不按招数来,只能死的很难堪。毕竟招数都是高手总结归纳的精华。而随着武功提高,招数熟练之后,必然是发现招数的局限性,要么忘掉招数,要么自创招数。只要努力,加上多熬几年,总能达到第二个境界,总会觉得范式是经典。此时能不过分依赖范式,快速突破范式局限性的人,自然是高手。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号