

l 架构准备
|
Node1 |
192.168.15.3 |
|
Node2 |
192.168.15.4 |
|
VIP |
192.168.15.254 |
l 软件
MySQL 5.6 Keepalive
yum install gcc python-devel
easy_install mysql-python
l MySQL配置
node1:
|
server-id = 033306 log-bin = mysql-bin binlog-format = row log-slave-updates = true gtid-mode = on enforce-gtid-consistency = true auto-increment-increment = 2 auto-increment-offset = 1 relay-log = /var/lib/mysql/relay-log-3306 |
node2:
|
server-id = 043306 log-bin = mysql-bin binlog-format = row log-slave-updates = true gtid-mode = on enforce-gtid-consistency = true auto-increment-increment = 2 auto-increment-offset = 2 relay-log = /var/lib/mysql/relay-log-3306 |
查看两个UUID
|
Node1 |
e05b8b73-fa94-11e4-aa31-000c29b0dac1 |
show global variables like '%uuid%'; |
|
Node2 |
2e619521-9eb4-11e5-9868-000c295b6358 |
赋权(node1和node2)
mysql> grant replication slave,replication client on *.* to repluser@'192.168.15.%' identified by 'replpass';
mysql> flush privileges;
备份:
|
mysqldump -uroot --opt --default-character-set=utf8 --triggers -R --master-data=2 --hex-blob --single-transaction --no-autocommit --all-databases > all.sql |
注(会有一个警告):
|
Warning: A partial dump from a server that has GTIDs will by default include the GTIDs of all transactions, even those that changed suppressed parts of the database. If you don't want to restore GTIDs, pass --set-gtid-purged=OFF. To make a complete dump, pass --all-databases --triggers --routines --events. |
将导出的数据放到node2中(用免秘钥传输过去):
|
[root@node1 ~]# yum -y install openssh-clients [root@node2 mysql]# yum -y install openssh-clients 在node1上 [root@node1 ~]# ssh-keygen [root@node1 ~]# ssh-copy-id 192.168.15.4 传送文件 [root@node1 ~]# scp -rv all.sql 192.168.15.4:/tmp ================================================= 在node2上 [root@node2 mysql]# mysql </tmp/all.sql |
在node2上配置连接
|
mysql> change master to master_host='192.168.15.3',master_port=3306,master_user='repluser',master_password='replpass',master_auto_position=1; mysql> start slave; mysql> show slave status\G; Slave_IO_Running: Yes Slave_SQL_Running: Yes Retrieved_Gtid_Set: Executed_Gtid_Set: e05b8b73-fa94-11e4-aa31-000c29b0dac1:1-2
|
完成后备份node2的数据同步到node1中
|
[root@node2 mysql]# ssh-keygen [root@node2 mysql]# ssh-copy-id 192.168.15.3 [root@node2 mysql]# mysqldump -uroot --opt --default-character-set=utf8 --triggers -R --master-data=2 --hex-blob --single-transaction --no-autocommit --all-databases > all.sql [root@node2 mysql]# scp -r all.sql 192.168.15.3:/tmp
|
在node1上导入
|
[root@node1 ~]# mysql < /tmp/all.sql |
会有一个报错,但可以不理会
RROR 1840 (HY000) at line 24: @@GLOBAL.GTID_PURGED can only be set when @@GLOBAL.GTID_EXECUTED is empty.
|
mysql> change master to master_host='192.168.15.4',master_port=3306,master_user='repluser',master_password='replpass',master_auto_position=1; mysql> start slave; mysql> show slave status\G; |
l 同步复制
node1:
mysql> create database ck1;
node2:
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| ck1 |
| mysql |
| performance_schema |
| test1 |
+--------------------+
5 rows in set (0.00 sec)
查看从库状态
|
Retrieved_Gtid_Set: e05b8b73-fa94-11e4-aa31-000c29b0dac1:3 Executed_Gtid_Set: 2e619521-9eb4-11e5-9868-000c295b6358:1-2, e05b8b73-fa94-11e4-aa31-000c29b0dac1:1-3 |
之前的
|
Retrieved_Gtid_Set: Executed_Gtid_Set: e05b8b73-fa94-11e4-aa31-000c29b0dac1:1-2 |
在node2中创建表
mysql> use ck1;
mysql> create table test(id int unsigned not null primary key auto_increment,test varchar(100));
在node1中查看表的情况
mysql> use ck1;
Database changed
mysql> show tables;
之前的状态
|
Retrieved_Gtid_Set: 2e619521-9eb4-11e5-9868-000c295b6358:1-2 Executed_Gtid_Set: 2e619521-9eb4-11e5-9868-000c295b6358:1-2, |
现在的状态
|
Retrieved_Gtid_Set: 2e619521-9eb4-11e5-9868-000c295b6358:1-3 Executed_Gtid_Set: 2e619521-9eb4-11e5-9868-000c295b6358:1-3, e05b8b73-fa94-11e4-aa31-000c29b0dac1:1-3 |
l 配置keepalived
|
rpm -ivh http://mirrors.ustc.edu.cn/fedora/epel/6/x86_64/epel-release-6-8.noarch.rpm |
在node1中
|
[root@node1 ~]# cd /etc/keepalived/ [root@node1 keepalived]# cat keepalived.conf vrrp_script vs_mysql_82 { script "/etc/keepalived/checkMySQL.py -h 127.0.0.1 -P 3306" interval 15 } vrrp_instance VI_82 { state BACKUP nopreempt interface eth0 virtual_router_id 82 #同一集群中该数值要相同 priority 100 advert_int 5 authentication { auth_type PASS #Auth 用密码,但密码不要超过8 位 auth_pass 82565387 } track_script { vs_mysql_82 } virtual_ipaddress { 192.168.15.254 } }
checkMySQL.PY内容 #!/usr/bin/python #coding: utf-8 # grant usage on *.* to 'pxc-monitor'@'%' identified by 'showpxc';
import sys import os import getopt import MySQLdb import logging
dbhost='127.0.0.1' dbport=3306 dbuser='repluser' dbpassword='replpass'
def checkMySQL(): global dbhost global dbport global dbuser global dbpassword
shortargs='h:P:' opts, args=getopt.getopt(sys.argv[1:],shortargs) for opt, value in opts: if opt=='-h': dbhost=value elif opt=='-P': dbport=value #print "host : %s, port: %d, user: %s, password: %s" % (dbhost, int(dbport), dbuser, dbpassword) db = instanceMySQL(dbhost, dbport, dbuser, dbpassword) st = db.ishaveMySQL() #if ( db.connect() != 0 ): # return 1 #db.disconnect() return st
class instanceMySQL: conn = None def __init__(self, host=None,port=None, user=None, passwd=None): self.dbhost= host self.dbport = int(port) self.dbuser = user self.dbpassword = passwd
def ishaveMySQL(self): cmd=" ps -ef|grep mysqld|grep -v \"grep\"|grep -v \"mysqld_safe\"|wc -l " mysqldNum = os.popen(cmd).read() cmd ="netstat -tunlp | grep \":::%s\" | wc -l" % self.dbport mysqlPortNum= os.popen(cmd).read() #print mysqldNum, mysqlPortNum if ( int(mysqldNum) <= 0): print "error" return 1 if ( int(mysqldNum) > 0 and mysqlPortNum <= 0): return 1 return 0
def connect(self): # print "in db conn" # print "host : %s, port: %d, user: %s, password: %s" % (self.dbhost, self.dbport, self.dbuser, self.dbpassword) try: self.conn=MySQLdb.connect(host="%s"%self.dbhost, port=self.dbport,user="%s"%dbuser, passwd="%s"%self.dbpassword) except Exception, e: # print " Error" print e return 1 return 0 def disconnect(self): if (self.conn): self.conn.close() self.conn = None
if __name__== "__main__": st=checkMySQL() sys.exit(st)
|
测试连接
[root@node1 keepalived]# /etc/keepalived/checkMySQL.py -h 127.0.0.1 -P 3306
启动keepalived
|
原有的 [root@node1 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:59:d4:9f brd ff:ff:ff:ff:ff:ff inet 192.168.15.3/24 brd 192.168.15.255 scope global eth0 inet6 fe80::20c:29ff:fe59:d49f/64 scope link valid_lft forever preferred_lft forever [root@node1 keepalived]# /etc/init.d/keepalived start 查看messages的日志可以看到 Dec 10 08:17:17 node1 Keepalived_healthcheckers[2383]: Netlink reflector reports IP 192.168.15.254 added
此时的 [root@node1 ~]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:59:d4:9f brd ff:ff:ff:ff:ff:ff inet 192.168.15.3/24 brd 192.168.15.255 scope global eth0 inet 192.168.15.254/32 scope global eth0 inet6 fe80::20c:29ff:fe59:d49f/64 scope link valid_lft forever preferred_lft forever
|
启动完毕后,在node1中建一个测试账号
mysql> grant all privileges on *.* to 'zhangli.xiong'@'%' identified by 'zhangli.xiong';
mysql> flush privileges;
在本地客户机上连接
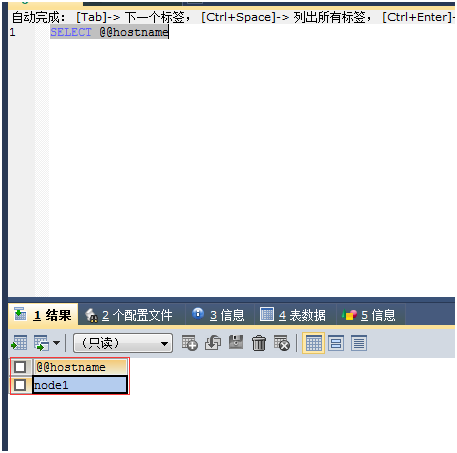
测试说明成功
此时添加node2的keepalived的配置文件(跟node1一样)
启动keepalived
|
[root@node2 keepalived]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:5b:63:58 brd ff:ff:ff:ff:ff:ff inet 192.168.15.4/24 brd 192.168.15.255 scope global eth0 inet6 fe80::20c:29ff:fe5b:6358/64 scope link valid_lft forever preferred_lft forever [root@node2 keepalived]# /etc/init.d/keepalived start
|
关闭node1的DB服务器
Dec 10 08:30:12 node1 Keepalived_healthcheckers[2383]: Netlink reflector reports IP 192.168.15.254 removed
此时node2中的messages显示
|
Dec 10 08:30:18 node2 Keepalived_healthcheckers[3950]: Netlink reflector reports IP 192.168.15.254 added [root@node2 keepalived]# ip addr 1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00 inet 127.0.0.1/8 scope host lo inet6 ::1/128 scope host valid_lft forever preferred_lft forever 2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000 link/ether 00:0c:29:5b:63:58 brd ff:ff:ff:ff:ff:ff inet 192.168.15.4/24 brd 192.168.15.255 scope global eth0 inet 192.168.15.254/32 scope global eth0 inet6 fe80::20c:29ff:fe5b:6358/64 scope link valid_lft forever preferred_lft forever
|
连接测试发现已经切换到node2


 浙公网安备 33010602011771号
浙公网安备 33010602011771号