第一次个人编程作业
https://github.com/oldmoney-lana/031902441
一、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 60 |
| · Estimate | · 估计这个任务需要多少时间 | 5 | 5 |
| Development | 开发 | 1200 | 1500 |
| · Analysis | · 需求分析 (包括学习新技术) | 240 | 300 |
| · Design Spec | · 生成设计文档 | 10 | 10 |
| · Design Review | · 设计复审 | 10 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 5 | 5 |
| · Design | · 具体设计 | 20 | 60 |
| · Coding | · 具体编码 | 480 | 600 |
| · Code Review | · 代码复审 | 60 | 240 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 60 | 120 |
| Reporting | 报告 | 60 | 120 |
| · Test Repor | · 测试报告 | 20 | 10 |
| · Size Measurement | · 计算工作量 | 30 | 45 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 10 | 20 |
| · 合计 | 2270 | 3105 |
二、计算模块接口
1.计算模块接口的设计与实现过程
敏感词类 sensitivewords:定义敏感词的编号、内容、长度、类型
结构体 line:定义行号、行内容、长度
结构体 answer:定义答案的编号、内容、行号、输出位置
关系:
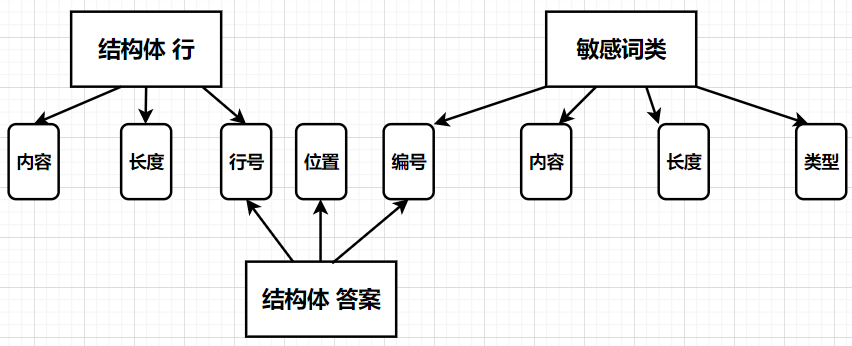
函数 dj:打开敏感词、待测文本文件
函数 print:打开答案文本文件,写入答案
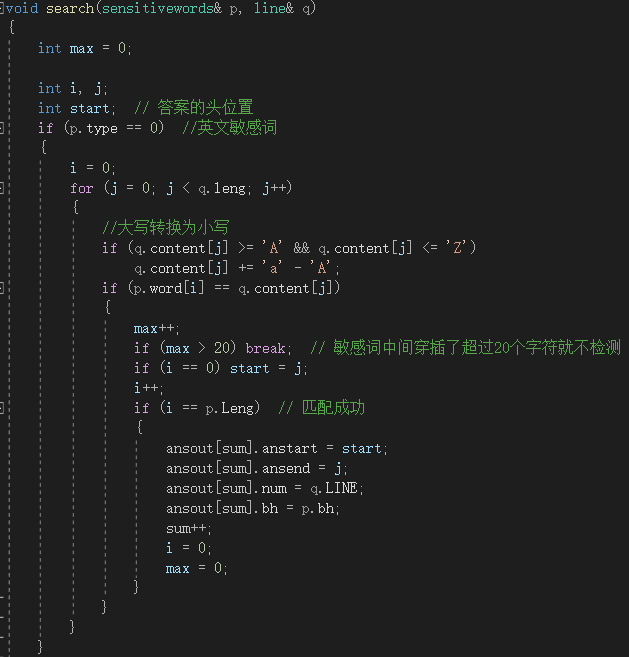
关键函数:search函数(可能独到之处就是非常暴力非常笨拙)
将中文敏感词、英文敏感词分开检测后,把敏感词拆分成一个一个字符,与待测文本的字符匹配。检测到敏感词的第一个字符后,继续匹配直至匹配到敏感词的最后一个字符。然后将编号、行号、第一个字符和最后一个字符在行中的位置存入答案结构体中。
2.计算模块接口部分的性能改进
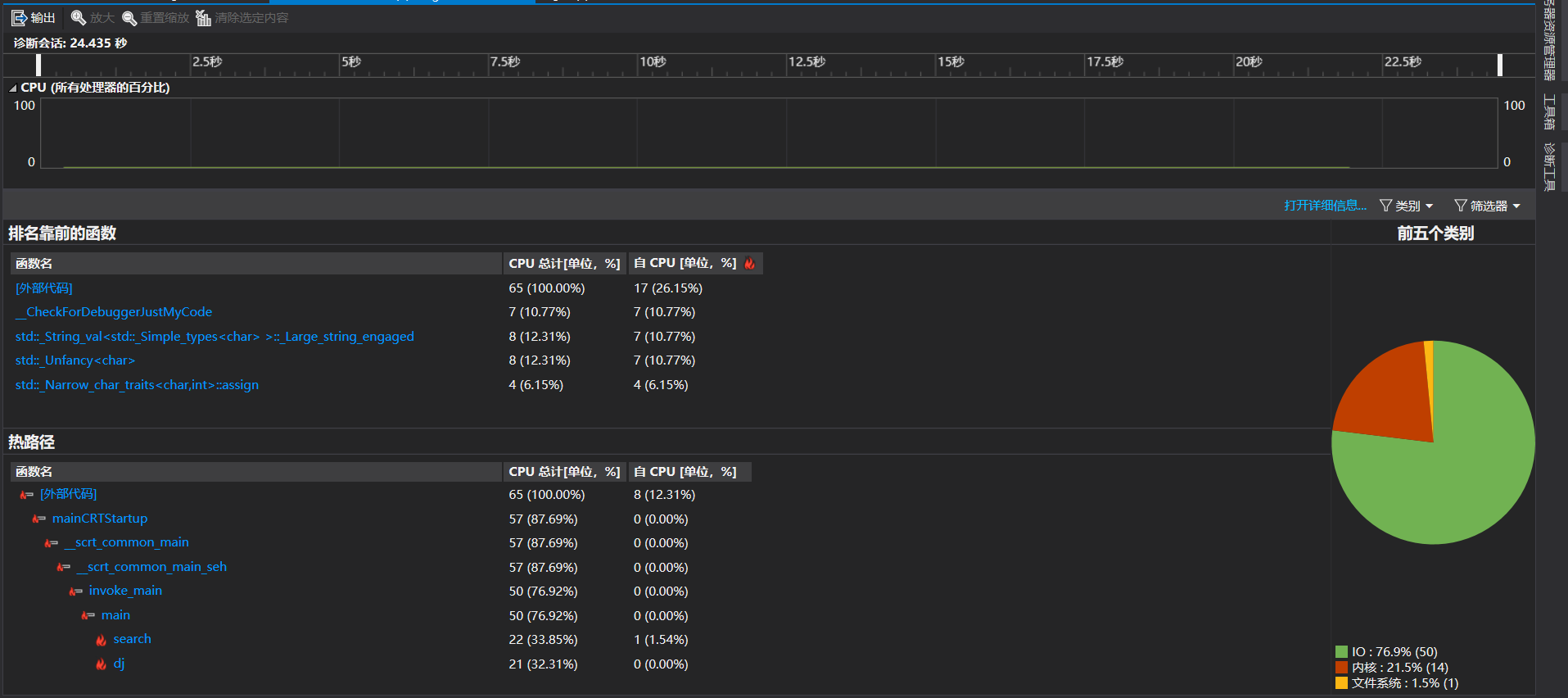
由图可见IO时间占比非常大,但是我也想不到有什么办法可以改进,只会使用文件流输入输出。然后就是内核时间,其实我觉得将敏感词拆分成树结构应该会节省不少时间,但是我基础不太好,算法这块没学明白,为了完成作业得出结果我还是选择了用敏感词类直接存放,希望以后加深学习能够更好地使用高效的算法。
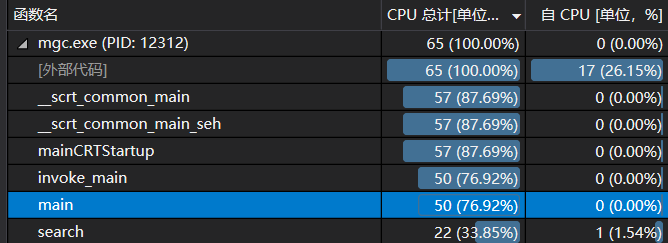
占比最大的是search函数
主要代码:
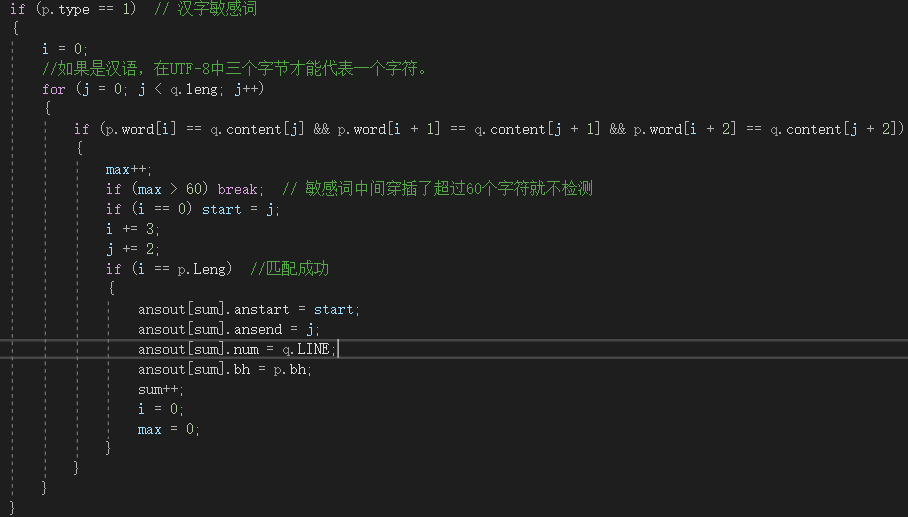
3.计算模块部分单元测试展示
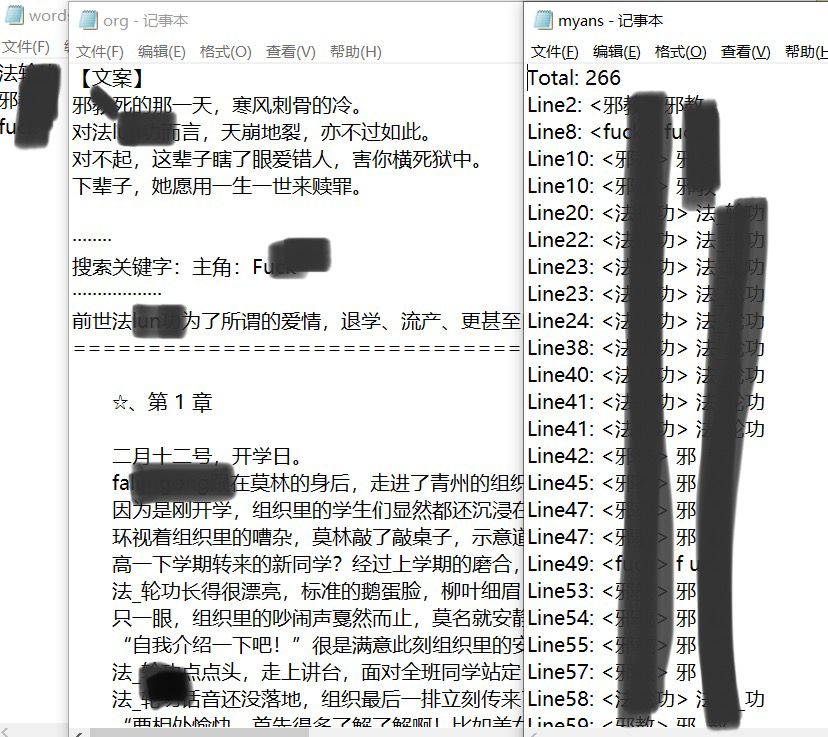
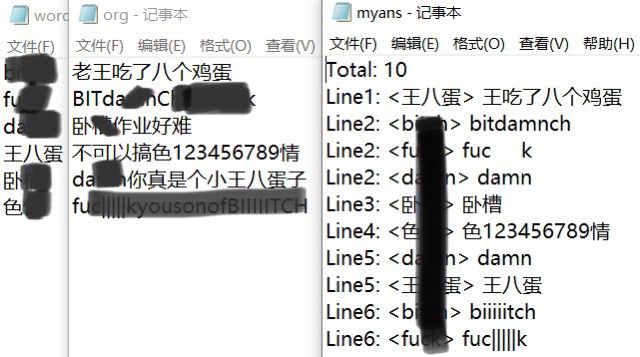
4.计算模块部分异常处理说明
输入文件路径

输入错误

输入正确

三、心得
我并不满意这一次自己做的作业。从结果就可以看出,我的水平只能检测出两百多个敏感词。
一开始我还走了不少的歪路:听别的同学说用python很好写,我便心想,那我去看个几天的python网课也许我就能把作业写出来了。但是对我来说,短时间学习一门新语言,并不能马上使用它写好一个有难度的作业。希望以后能好好学习一下python用它来解决更多的问题吧。
