关于爬取babycenter.com A-Z为顺序的所有英文名及其详细属性
这一次爬取的内容已经在标题里提到了,下面是详细要求及其图示:
1、首先以A-Z的顺序获取所有英文名,最后爬取该英文名的详细信息。
2、CSV的header以3中的单词为准,请别拼错。如果没有对应的数据,该列留空。
3、最终CSV中的字段名以此为准:EnName,CnName,Gender,Meaning,Description,Source,Character,Celebrity,WishTag
4、请遵守爬虫协议,先保存html至本地,学习并掌握bs4解析规则,切勿频繁请求主机。

网站的url是:“https://www.babycenter.com/babyNamerSearch.htm?startIndex=0&gender=MALE&batchSize=40&startsWith=A”
首先开始构思整体的爬取思想:
我把整个项目功能模块切分成为4个:爬虫控制器、url管理器、网页请求器、网页分析器和数据输出器
爬虫程序的运行流程说明如下:
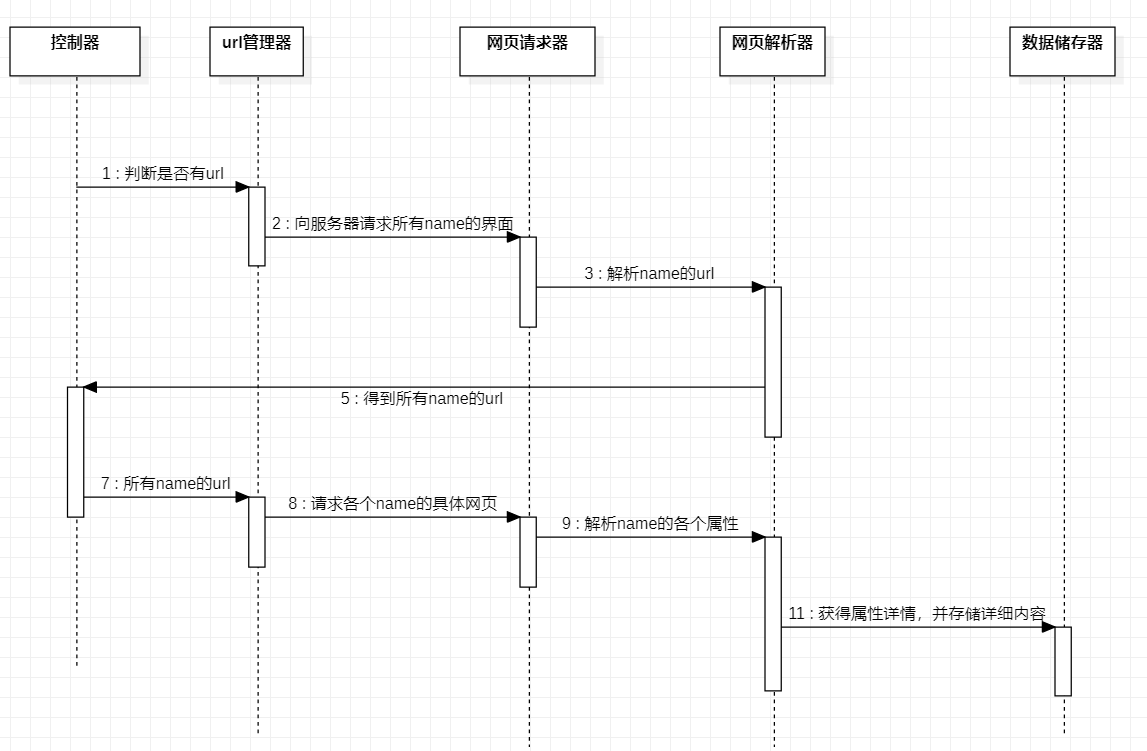
(1)控制器通过for循环获得以A-Z开头为名字的所有页面。
(2)url管理器获得控制器传来的url以后将所有的连接传给网页请求器,网页请求器通过requests向服务器进行请求,并将请求结果传给网页解析器
(3)网页解析器针对网页请求器传来的一系列url进行解析,获得每个页面中英文名相对应的href,将href打包放入网页请求器
(4)网页请求器获取到href开始请求,请求的结果再次传到网页解析器之中。
(5)网页解析器开始分析相关网页,并选取需要的内容进行打包处理,处理完以后的数据将被以list的形式传送到数据存储器。
(6)存储器接收到来自网页解析器传来的数据据以后,开始以csv的形式存入文档之中。程序运行完毕
我用流程图和时序图来解释一下各功能模块之间的合作流程:

时序图:
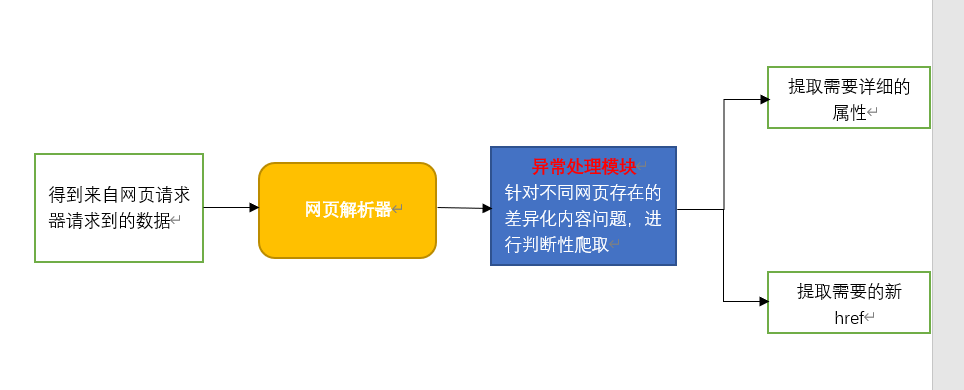
重点讲解一下这里的网页解析器:
网页解析器是从网页中提取有价值数据的工具。
Python常用的解析器有四种,一是正则表达式,二是html.parser,三是beautifulSoup,四是lxml。
这里我选用的是beautifulSoup作为我的网页解析器,相对于正则表达式来说,使用beautifulSoup来解析网页更为简单。
beautifulSoup将网页转化为DOM树来解析,每一个节点是网页的每个标签,通过它提供的方法,你可以很容易的通过每个节点获取你想要的信息。
本功能模块除拥有正常爬取功能外,添加了异常处理功能,这是因为在爬取BabyCenter.com网站中,各name的详情网页中What does Aiden mean?栏目中存在不同的html设计,针对该差异化问题,若不加以处理,爬取过程有几率报错。故添加由try方法组成的异常处理模块,保证爬取过程的顺利。
图解功能块:
还有这里说明一下为什么需要调用两次网页解析器
第一次调用网页解析器的原因是需要在首页找到所有英文名所对应的href:
之所以要通过解析器来find英文名的的地址
是因为这个网站的每个英文名的href不是按照惯例类型:‘www.!@#¥%&*NAME={某英文名}.com’
而是‘www.!@#¥%&*NAME={某英文名+一串没有无规律的数字}.com’
由于找不到规律,无法通过for循环name=‘xxx’挨个进入网站,故需要进入首页调取英文名对应的href
实现代码可参见下图:

剩余的步骤,如果按照惯例的话,只需要for循环将url传到下一函数中进行find属性内容就可以了
但是!!
每当我爬取description和character的内容时候,系统都会报错:
第一类报错是无法获取character的内容
第二类是根本无法获取description和character,找不到属性
在反复比对完网页以后,我发现BabyCenter.com这个网站的排版很奇特
你可以看到三种设计:
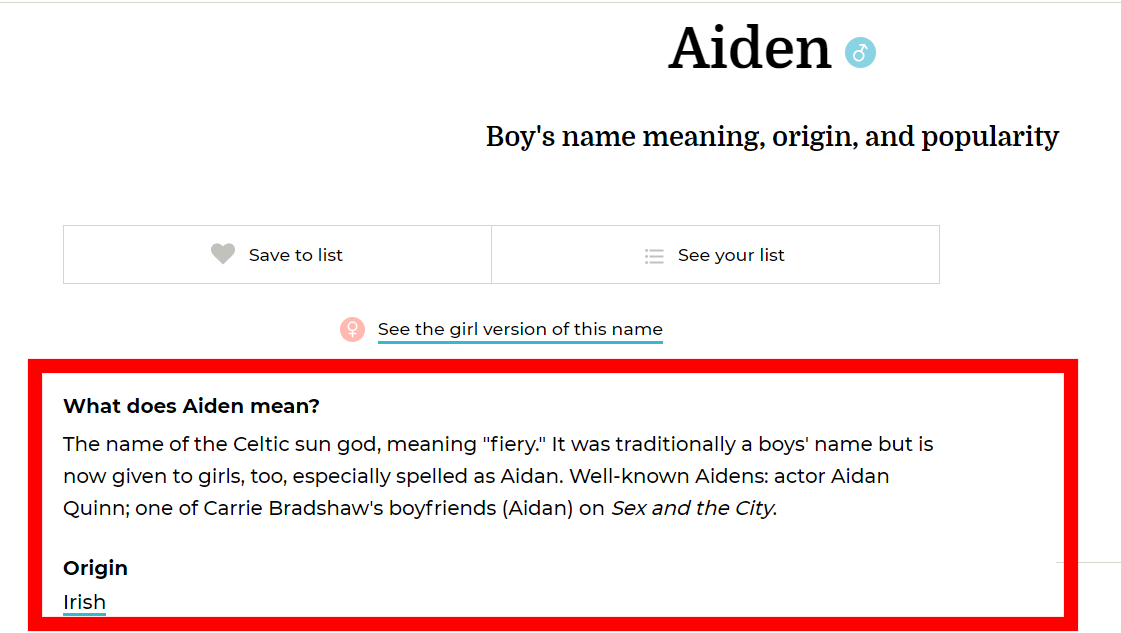
第一种版型
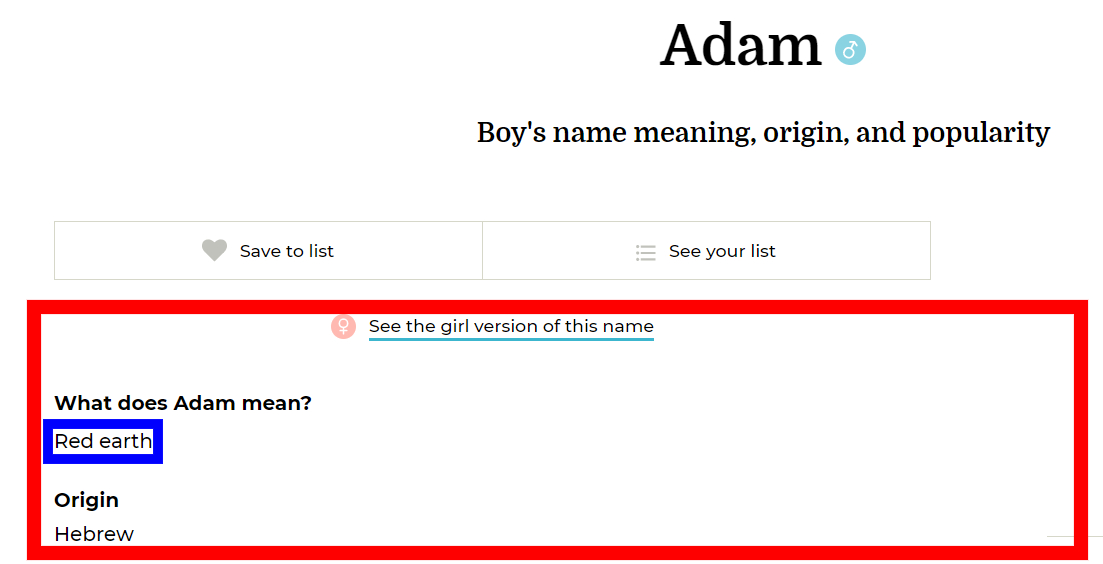
第二种版型
第三种版型
解决方案:运用try,except方法进行爬取,
当爬取报错的时候跳转到另外的一个try方法之中进行爬取,
三种版型运用两个try方法。详细代码见图:
def getDESandCHAR(EveryName,EveryHref):#获取description和character descriptions=[] characters=[] Content=[] for i in range(len(EveryName)): url = EveryHref[i] kv = {'User-Agent':'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36'} Res = requests.get(url,headers=kv).text demo=BeautifulSoup(Res,'html.parser') try:#此处开始第一次尝试,是否存在bodytext,如果不存在,则description和characters全部返还none ss = (' Well-known ','Aiden','s: ') k = ''.join(ss).replace('\n','') x = demo.find('div',{'class':'spacer'}).find('p',{'class':'bodyText'}).text.split(k,1) print(x[0].replace(',',',').replace("'",'').replace('/',' ').replace('\n','')) descriptions.append(x[0]) try:#此处开始尝试查询是否存在characters,如果不存在则返还none print(x[1].replace(',',',').replace("'",'').replace('/',' ').replace('\n','')) characters.append(x[1]) except:#尝试失败,返还characters返还none print('none') characters.append('none') except:#尝试失败,descriptions和characters全部返还none descriptions.append('none') characters.append('none') Content=[descriptions,characters]#两属性放入一个表格之中,return一个参数 return Content
还有source部分也和上述部分差不多
代码下一次有时间再上吧

 浙公网安备 33010602011771号
浙公网安备 33010602011771号