

一、模块
什么是模块?
模块就是一系列功能的结合体
模块的三种来源:
1.内置的(python解释器自带的)
2.第三方的(别人写的)
3.自定义的(你自己写的)
模块的四种表现形式:
1.使用python编写的py文件(也就是意味着py文件也是可以称之为模块
2.已被编译为共享库或DLL的或C++扩展(了解)
3.把一系列模块组织到一起的文件夹(文件夹下有一个__init__.py文件,该文件夹称之为包)
4.使用C编写并连接到Python解释器的内置模块
模块选择
1.用别人写好的模块(内置的,第三方的):典型的拿来主义,好处:极大的提高开发效率
2.使用自己写的模块(自定义的):当程序比较庞大的时候,你的项目不可能只在一个py文件中
**其他的文件以模块的形式导过去直接调用即可
如何使用模块?
一定要区分哪个是执行文件,哪个是被导入文件
Import 方法(导入模块方式1)
1.首先运行执行文件,会创建一个执行文件aa.py的名称空间
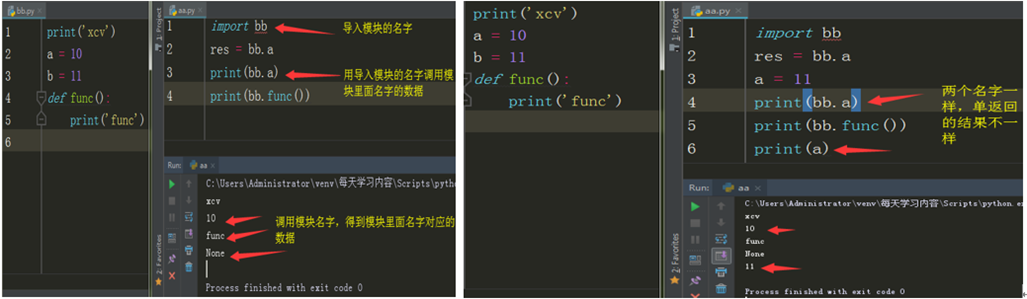
2.在执行文件里面 import bb.py文件(导入 bb.py文件模块)
3.python解释器运行 bb.py文件,同时在内存也会创建一个xx.py的名称空间,并存放bb.py文件中产生的名字和值
4.执行文件时,会在创建的名称空间里会产生一个指向执行bb.py创建的模块名称空间的名字,这个名字即模块名字

**这里需要注意的就是:
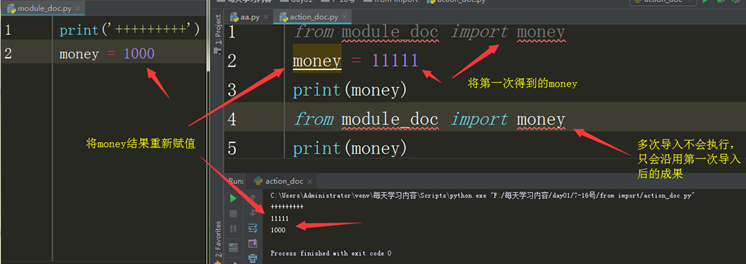
当一个模块被导入第一次以后,在此导入时,就不会在执行模块文件,会沿用第一次导入的成果
**使用import 导入模块时,访问模块名称空间里面的名字,统一格式:模块名.名字
1.指名道姓的访问模块中的名字,永远不会与执行文件中的名字冲突
2.你如果想访问模块中的名字,必须用模块名.名字的方式
注意:
1.只要你能拿到函数名,无论在哪里都可以用函数名+括号来调用这个函数(会回到函数定义阶段 依次执行函数体内代码)
2.函数在定义阶段,函数名的查找方式就已经固定死了,不会因调用位置的变化而发生改变
只要当几个模块有相同部分或者属于同一个模块,可以写在一行,但当几个模块没有联系的情况下,应该多次导入
**通常导入模块的句式 写在文件的开头
第一种方法导入:import os,time,aa #结构不清晰
第二种方法:
import os
import time
import aa
当模块的名字比较复杂的时候,可以给该模块名取别名
Import abcdefghigklmn as res 取模块里面的数据时,可以通过这个别名.名字来操作
From…import… 导入模块方式2
注意事项:
多次导入不会执行,只会沿用第一次导入后的成果
运行执行文件发生的过程:
1.先创建执行文件的名称空间,
2.首次导入模块文件名,
3.运行模块文件
4.运行模块时,将产生的名字存放到模块名称空间中
5.直接拿到指向模块名称空间中某个值得名字
特点:
From …import …名字
1.访问模块中的名字不需要加模块名前缀
2.在访问模块中的名字时,可能会与执行文件里面的名字重复,这时就需要注意。(缺点)
补充:
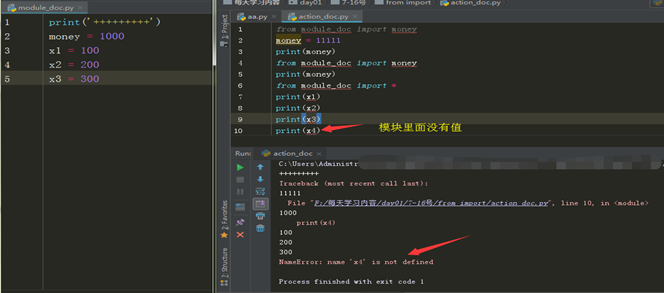
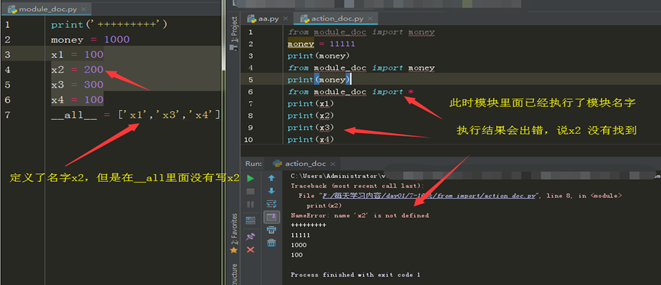
一次性取模块中的名字 :from xx import *
为什么 * 可以取到模块里面的所有名字,那是*自动找模块中的__all__ (里面可以带参数即名字),当__all__里面没有参数是,模式取出的是模块中的所有名字,
不然的话就是__all__ 设定的名字
二、循环导入问题及解决思路
循环导入可以理解为 当运行一个执行文件a时,在执行文件里导入了一个模块b,然后就运行这个模块文件b,在这个运行的模块文件b里面有导入了一个模块文件c,运行这个模块文件c时,这个模块文件里面又插入了一个模块文件b,然后就一直彼此调模块,循环。
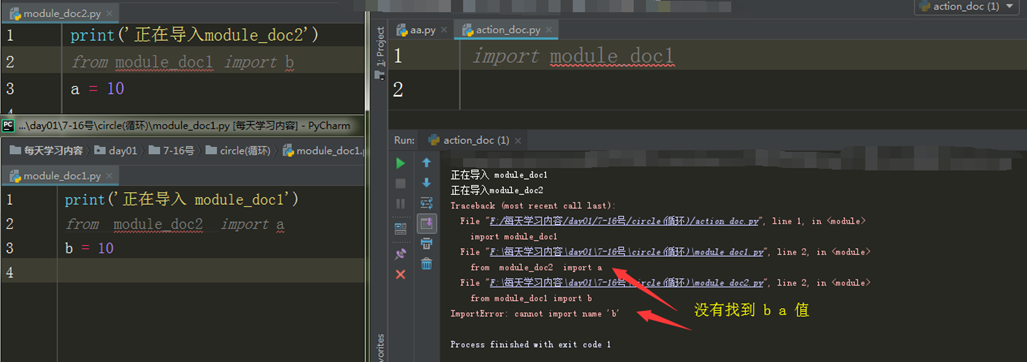
如果出现循环导入问题 那么一定是你的程序设计的不合理 循环导入问题应该在程序设计阶段就应该避免
解决循环导入问题的方式
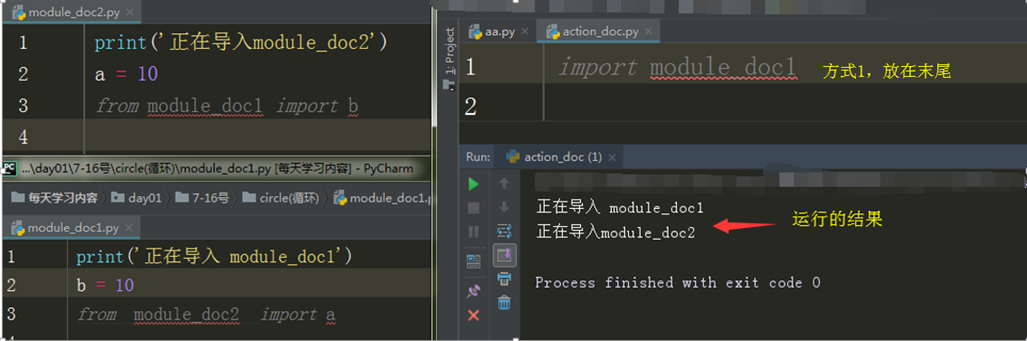
1.方式1
将循环导入的句式写在文件最下方()
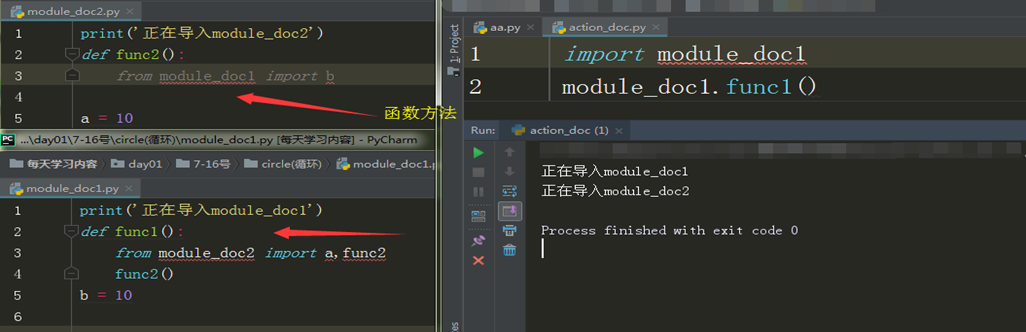
2.方式2
函数内导入模块
"""
循环导入
三、区分py文件的两种类型
内置方法:__name__
1. 当文件是执行文件时,print(__name__)时,返回的结果是__main__
2. 当文件被当作模块文件导入的时候,print(__name__)打印的结果 是模块名字,没有后缀名
快捷写法:main直接tab键即可
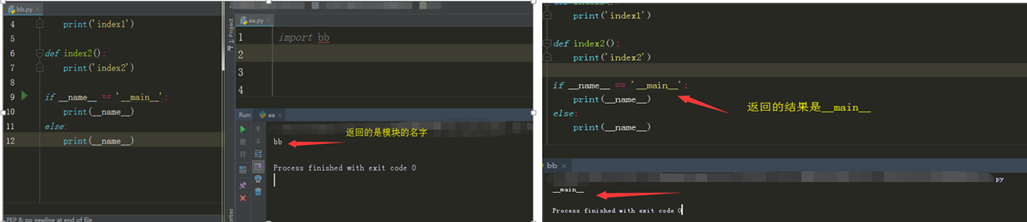
__name__的用处:当开发一个程序时,当我们要执行编写的函数时,会在文件底部调用函数,看下函数执行情况,但是当程序上线时,用户调用这些函数时,为了不让测试时的函数不会被调用,就用__name__来做判断。
四、模块的查找顺序
- 先从内存中找
- 在内置中找
- Sys.path中找(环境变量)
一定要分清楚谁是执行文件谁是被导入文件(******)
Sys.path 是一个大列表,里面放了一个文件路径,第一个路径永远是执行文件所在的文件夹
Sys.path是以当前被执行文件路径为参照物
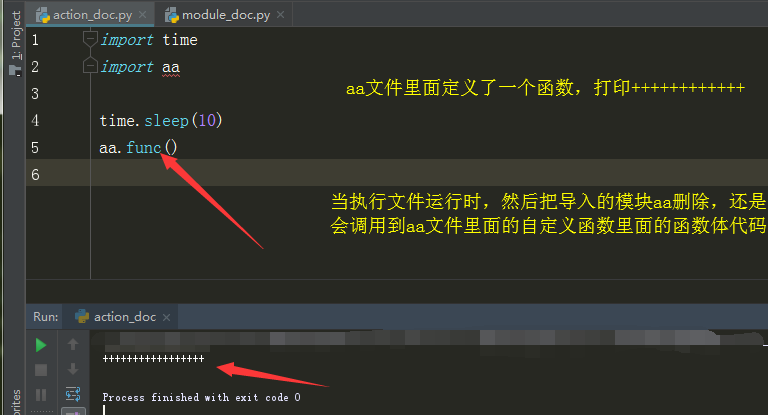
- 从内存中找:在执行文件导入time模块,及导入的模块,然后time.sleep(10),在这过程中把导入的模块删除,看会不会执行后面的结果
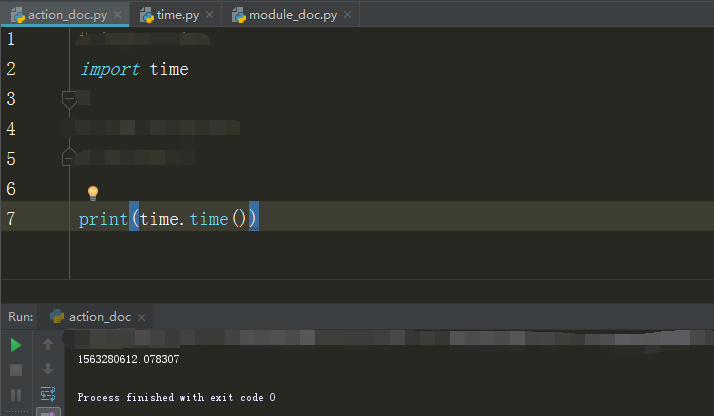
2.在内置中找 用time这个列子
注意py文件名不应该与模块名(内置的,第三方)冲突
- sys.path中找(环境变量)
在当前执行文件所在的文件夹里面找导入模块,不然会出错
方法:
From 同级文件夹 import 导入模块
- 当导入模块在多层文件夹下面,可以使用符号点‘.’ 连接文件夹与文件夹之间的关系
- 不用点‘.’时,改环境变量
用到sys模块
Sys.path.append(‘模块文件的绝对地址’),然后可以导入模块
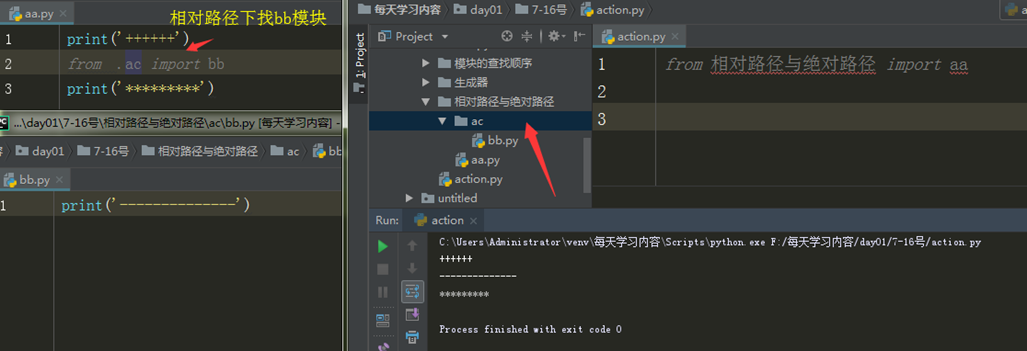
五、模块的绝对导入与相对导入
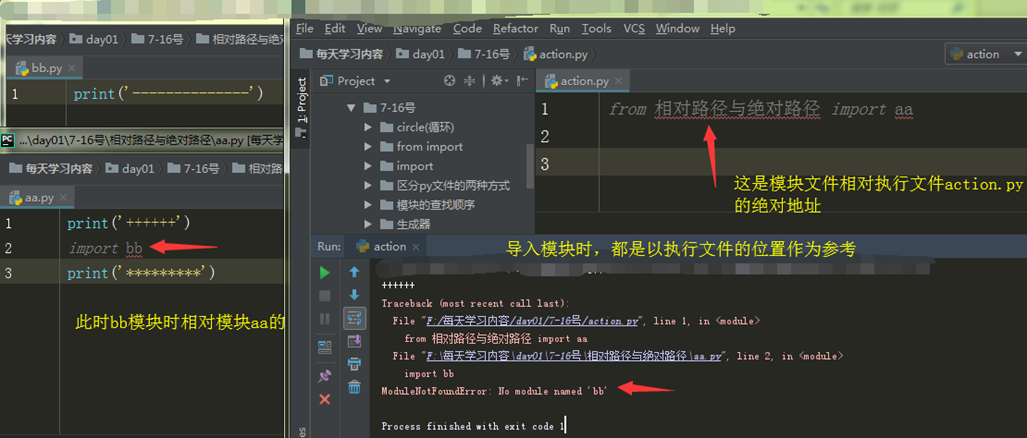
**绝对导入必须依据执行文件所在的文件夹路径为准
1.绝对导入无论在执行文件中还是被导入文件都适用
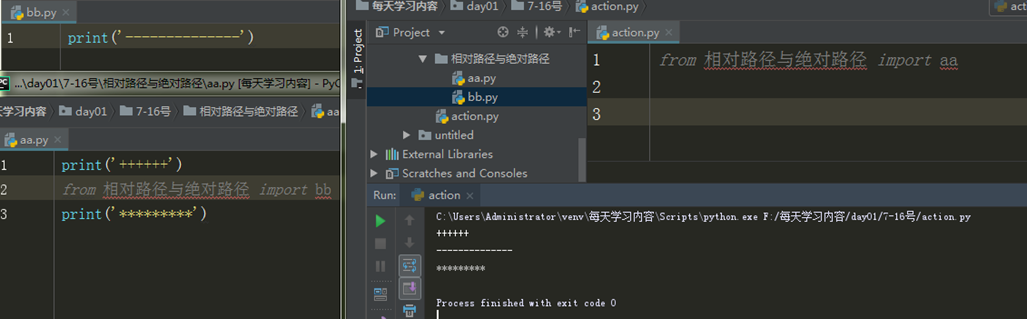
相对导入
.代表的当前路径
..代表的上一级路径
...代表的是上上一级路径
注意:相对导入不能再执行文件中使用
相对导入只能在被导入的模块中使用,使用相对导入 就不需要考虑
执行文件到底是谁 只需要知道模块与模块之间路径关系
六、软件开发的目录规范
Bin文件夹
Start.py项目启动文件 start.py在根目录下,启动程序需要更改
Conf文件夹
Settings.py项目配置文件
Core文件夹
Src.py 核心逻辑文件
Db文件夹
数据相关
Lib文件夹
Common.py项目所用到的公共功能
Log文件夹
Log.log项目的日志文件
Readme文件夹
项目介绍信息
当启动start.py时,要找到cone下的src.py模块,两种方法:
- 将core文件路径添加到sys.path 中,但有可能需要其他模块,虽然可以添加到sys.path中去,但是麻烦
- 将程序根文件夹位置添加到sys.path中去
Python会自动将你新建的最顶层的目录自动添加到环境变量中,这样做不是针对开发者,而是针对下载你这个软件的用户
不要手动拼接路径:方法:os.path.join(‘BASE_DIR’,’文件夹名’)


