【并发编程】(二)锁与并发
并发编程是编程中重要的一环,在特定的场景下,熟悉并发知识并且掌握并发编程显得尤为重要
在本篇开篇前针对几个知识点进行说明,虽然有些组件不是位于juc下并且它本身是无锁实现的,但是它却能解决并发相关的问题
-
ThreadLocal的原理
ThreadLocal应该是java工程师很熟悉的一个组件,它在本地线程、连接池中都有它的身影。它的目的是为了保证多个线程访问变量时的安全访问。通常情况下,我们将变量放入ThreadLocal中,ThreadLocal会为每个变量创建一个“独立的”值,这样避免了多个线程访问相同变量产生的并发问题。所以ThreadLocal变量也称为线程本地变量(私有的)。
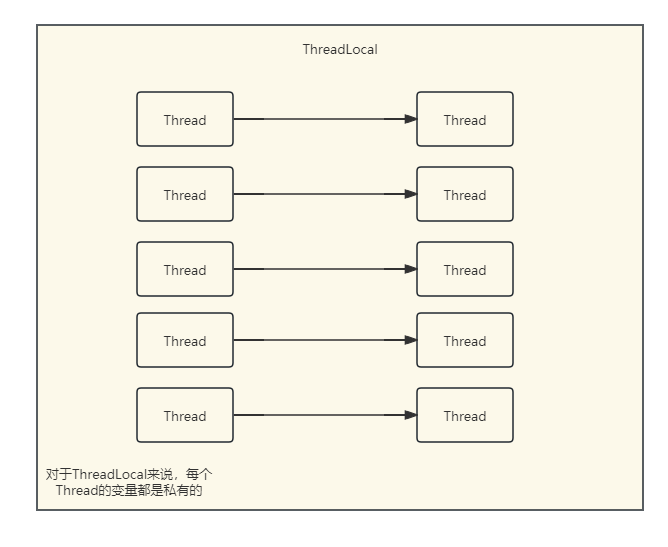
对于ThreadLocal来说,我们看它的模型很难不想到Map的k-v模型,其实在早期的ThreadLocal中,它的设计就是类似Map的设计,通过当前线程进行操作并获取对应线程的值,不多说我们看源码
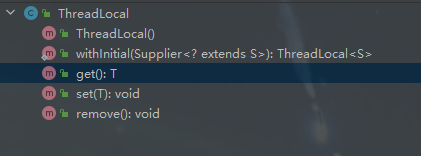
首先我们可以看到,在ThreadLocal中,为我们定义了几个基础的操作,如get、set、remove这些方法的作用不需要多说,它们符合一个容器最基本的操作,增删查,不同的是除此之外还提供了一个无参构造函数和一个方法withInitial,在我们常规的使用中,例如我们通过get获取当前线程中的本地变量,如果ThreadLocal中没有对应的值,则set一个默认值...这种方式相对较为繁琐,如果我希望在没有默认值时调用一个默认值返回使用,可以使用withInitial,例如:
ThreadLocal<Integer> integerThreadLocal = ThreadLocal.withInitial(() -> Integer.MAX_VALUE); 因为在withInitial中参数使用了Supplier,我们可以通过lambda表达式创建一个默认的返回值
在ThreadLocal中的源码中,我们可以发现,它利用的就是上篇中Thread模型中的线程模型,详情看源码:
1 public T get() { 2 Thread t = Thread.currentThread(); //Thread模型 获取当前线程模型 3 ThreadLocalMap map = getMap(t); 4 if (map != null) { 5 ThreadLocalMap.Entry e = map.getEntry(this); 6 if (e != null) { 7 @SuppressWarnings("unchecked") 8 T result = (T)e.value; 9 return result; 10 } 11 } 12 return setInitialValue(); 13 } 14 15 ThreadLocalMap getMap(Thread t) { 16 return t.threadLocals; 17 } 18 ThreadLocal.ThreadLocalMap threadLocals
首先,对于ThreadLocal而言,线程的区分其实就是当前Thread模型获取的 Thread.currentThread() 当前线程,而ThreadLocalMap是ThreadLocal中的一个内部实例,它的作用就是存储这些Thread的k-v数据,如果获取失败或者获取为空就使用 initialValue()获取默认值,默认值就是通过 withInitial中的 Supplier进行设置的。
1 public void set(T value) { 2 Thread t = Thread.currentThread(); 3 ThreadLocalMap map = getMap(t); 4 if (map != null) { 5 map.set(this, value); 6 } else { 7 createMap(t, value); 8 } 9 }
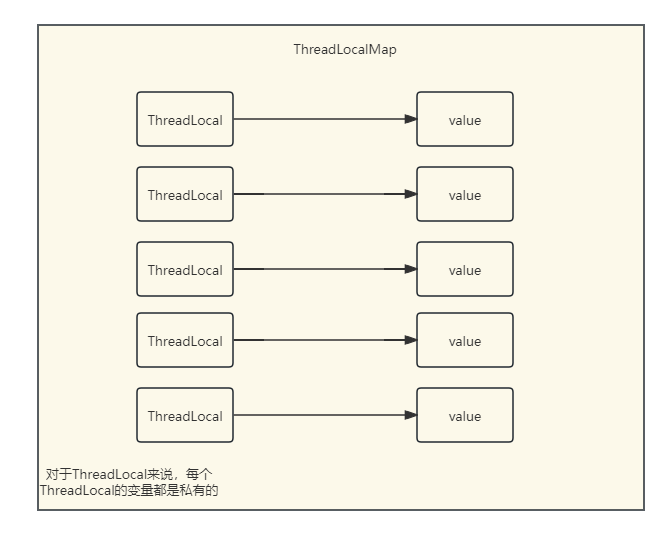
而对于set方法,就更简单明了。获取当先线程,并且去成员变量ThreadLocalMap中查找,如果这时还没有创建Map就先去创建,remove也是一样的,这里不做过多解释,那么我们得出结论就是ThreadLocalMap其实就是ThreadLocal的核心。
1 static class ThreadLocalMap { 2 3 /** 4 * The entries in this hash map extend WeakReference, using 5 * its main ref field as the key (which is always a 6 * ThreadLocal object). Note that null keys (i.e. entry.get() 7 * == null) mean that the key is no longer referenced, so the 8 * entry can be expunged from table. Such entries are referred to 9 * as "stale entries" in the code that follows. 10 */ 11 static class Entry extends WeakReference<ThreadLocal<?>> { 12 /** The value associated with this ThreadLocal. */ 13 Object value; 14 15 Entry(ThreadLocal<?> k, Object v) { 16 super(k); 17 value = v; 18 } 19 } 20 21 /** 22 * The initial capacity -- MUST be a power of two. 23 */ 24 private static final int INITIAL_CAPACITY = 16; 25 26 /** 27 * The table, resized as necessary. 28 * table.length MUST always be a power of two. 29 */ 30 private Entry[] table; 31 32 /** 33 * The number of entries in the table. 34 */ 35 private int size = 0; 36 37 /** 38 * The next size value at which to resize. 39 */ 40 private int threshold; // Default to 0 41 42 /** 43 * Set the resize threshold to maintain at worst a 2/3 load factor. 44 */ 45 private void setThreshold(int len) { 46 threshold = len * 2 / 3; 47 } 48 49 /** 50 * Increment i modulo len. 51 */ 52 private static int nextIndex(int i, int len) { 53 return ((i + 1 < len) ? i + 1 : 0); 54 } 55 56 /** 57 * Decrement i modulo len. 58 */ 59 private static int prevIndex(int i, int len) { 60 return ((i - 1 >= 0) ? i - 1 : len - 1); 61 } 62 63 /** 64 * Construct a new map initially containing (firstKey, firstValue). 65 * ThreadLocalMaps are constructed lazily, so we only create 66 * one when we have at least one entry to put in it. 67 */ 68 ThreadLocalMap(ThreadLocal<?> firstKey, Object firstValue) { 69 table = new Entry[INITIAL_CAPACITY]; 70 int i = firstKey.threadLocalHashCode & (INITIAL_CAPACITY - 1); 71 table[i] = new Entry(firstKey, firstValue); 72 size = 1; 73 setThreshold(INITIAL_CAPACITY); 74 } 75 }
在ThreadLocalMap源码中,我们通过它的成员变量和它的结构,不难看出它的模型很像我们之前解析HashMap的源码,HashMap源码分析请查看之前的文章《HashMap源码分析》,源码版本为1.8,其他版本源码不做过多介绍。它是将Key对应的Value包装成内部类Entry,与HashMap类似,它们的初始容量都为16,扩容因子0.75,它与HashMap相同都存在扩容,但是与HashMap不同的是,它对于Key的值是以Entry存在,Entry又是Map的k-v模型,我们知道HashMap底层由数组+链表+红黑树,在达到扩容因子后会进行扩容,当链表的长度达到阈值后会进行tree树化,将链表旋转为红黑树结构,这样的好处是控制的树的长度和宽度,使查找更为高效;但是扩容的代价很大,在ThreadLocalMap中扩容同样性能较低,在线程数量多且本地变量少的情况下,就需要进一步改进,在1.8中每一个线程Thread所拥有一个Map实例,这个Map就是ThreadLocalMap,ThreadLocal为key,而本地变量的值为value。这样做的好处是:每个ThreadLocalMap中存储的k-v数量会更少,这样可以避免大量的扩容消耗;当某个Thread获取本地变量后,会将ThreadLocal作为key从ThreadLocalMap中获取对应的value,其他线程无法访问自己的ThreadLocalMap实例、自己也无法访问其他线程的ThreadLocalMap,从而达到线程隔离的目的。所以在1.8的模型应该为:
-
弱引用
在Entry中,我们可以看到Entry被包装了 WeakReference,从字面意思可以看出这是一个弱引用。上面的注释中提到:The entries in this hash map extend WeakReference, using its main ref field as the key (which is always a ThreadLocal object). Note that null keys (i.e. entry.get() == null) mean that the key is no longer referenced, so the entry can be expunged from table. Such entries are referred to as "stale entries" in the code that follows. entries包含了一个继承WeakReference的map,当key为null时意味着它不在被引用,可以从列表中删除(这里的删除指的是GC回收),这段注释猛然看起来很难以理解,那么为什么它们不直接引用ThreadLocal作为key,而是使用WeakReference呢?
首先我们明确一个概念,在前文中说到jvm的守护线程gc线程,会通过gc的回收将已经失去引用的资源回收掉。在线程池篇幅中我们说不推荐使用Executors的工厂方法创建线程池,有很大的原因是因为在BlockQueue队列中是不限制大小的,如果我们添加大量的任务,会导致这些任务无法被完成且这些任务保持着强引用,gc没有办法回收,在超过了jvm的伊甸区并且存活时间够长之后会进入老年代,old。如果gc无法回收,导致堆栈内存占用过大直到无法为新对象开辟新的内存时,会导致OOM。那么什么叫内存泄漏呢?它是指不再使用的内存但是没有归还给jvm,它们都是因为引用导致无法被回收。而在jvm中,目前的垃圾回收器都是以根可达算法,它会认为强引用的对象是不需要被回收的
那么老规矩,我们用一个图来描述一下WeakReference:
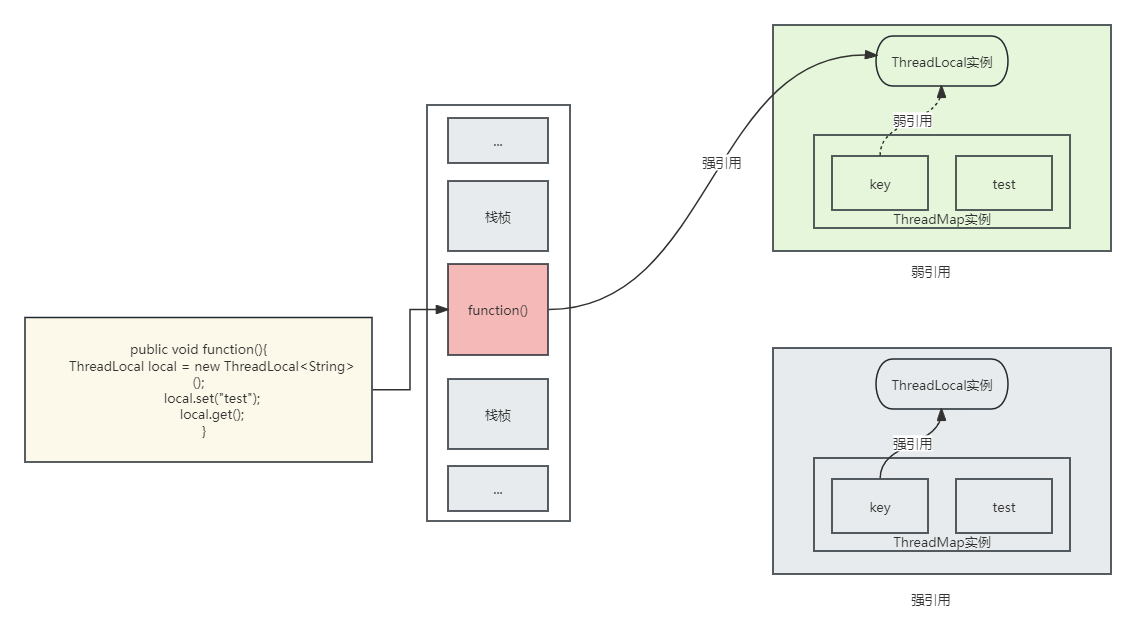
例如我们有一个代码块function(),一个线程执行了function方法,它首先会在执行前后进行出入栈,对应在jvm中就是栈桢的操作。我们直到对于一个方法的成员变量,在方法体出栈后会将内部的成员变量释放,等待下一次gc去处理它,这里不过多介绍jvm的原理,不然篇幅过长,可以参考我之前的文章:《jvm内存模型》,那么我们在function中创建了一个ThreadLocal对象,先进行赋值,再获取值。在创建ThreadLocal时用local指向ThreadLocal的对象地址,它们是强引用;再调用set方法后,当前线程的ThreadLocalMap会创建一个k-v实例,并且key使用WeakReference来包装弱引用;当function执行完成后,出栈,栈帧被销毁,这时强引用的local也将不存在,但是ThreadLocalMap中对应的key还指向ThreadLocal实例,如果这时key是强引用,那么key引用的ThreadLocal和value都无法被gc,例如下面灰色区域,key强引用ThreadLocal实例,那这个ThreadLocal将无法被回收。
我们更建议使用static final 来修饰ThreadLocal,针对一个线程内所有的操作都是共享的。推荐使用static来修饰,是因为静态变量在加载初始化时会创建一次,只会分配一次空间,这样所有的类实例都会使用相同的存储空间;为了确保ThreadLocal的唯一性,使用final修饰符进行修饰,当然如果是私有的ThreadLocal,搭配private进行修饰保证调用的范围。但是如果我们使用static final修饰ThreadLocal,它会带来的问题是静态资源中的key在生命周期中永远是非null,导致entry一直存在,所以在使用static final时推荐搭配remove进行手动释放。
其实我们观察ThreadLocal,不难发现,它其实就是一种空间换时间的思路。每个线程保持自己的一份本地变量,从而避免多个线程在操作同一资源时产生并发问题。这种方式也是另一种无锁编程,当然无锁不仅仅这么简单,下面要针对jvm 进行锁的分析,包括jvm的锁、aqs的无锁思想、偏向锁和锁升级。
-
锁
后面的篇幅,着重梳理jvm内置锁,为什么提前要介绍ThreadLocal呢,因为它本身就是一种无锁的思想。jvm中的锁可以算得上重头戏,在jdk不断升级完善的过程中,从轻量锁,锁升级,重入,到新版本追随go的脚步,实现携程虚拟线程...jvm的内卷也一步步增加了
在java中,锁是互斥的。意味着最多只有一个线程可以获取到锁,当有多个线程且只有一个线程获取到相同的锁后,其他线程必须等待或者阻塞,直到获取锁的线程释放了锁。
-
线程安全
线程安全是指:当多个线程访问相同的共享变量时,达到的结果符合我们预期的、正确的行为。相反:如果多个线程操作出现了错误的、达不到预期的结果,我们也称它们是线程不安全的。
-
自增操作是线程不安全的
一个老生常谈的问题。i++ 是不是线程安全的?为什么?
我们来做个实验:


1 private static int count = 0; 2 3 public static void main(String[] args) { 4 Runnable runnable = new Runnable() { 5 @Override 6 public void run() { 7 for (int i = 0; i < 10000; i++) { 8 count++; 9 } 10 } 11 }; 12 13 Thread thread1 = new Thread(runnable); 14 Thread thread2 = new Thread(runnable); 15 16 thread1.start(); 17 thread2.start(); 18 19 try { 20 thread1.join(); 21 thread2.join(); 22 } catch (InterruptedException e) { 23 e.printStackTrace(); 24 } 25 26 System.out.println("Count: " + count); 27 }
我们让两个线程各执行1000次++操作,会发现得到的结果达不到我们的预期,每次执行都会有新的结果,我们可以得到结论:自增运算不是线程安全的。实际上自增运算并不是一个原子操作,而是被划分成了几个操作的复合操作,这个例子在《神奇的volatile》一文中也有明确的说明,这里不做过多介绍。
-
临界区
临界区,通常表示一个公共资源,它可能被多个线程访问,但是我们希望它每次只能被一个线程访问,在同一时间其他线程想要访问它们必须阻塞等待。在简单的开发中,我们常常会希望代码是以串行的方式执行的,但是如果有多个线程并发执行就会出现意料之外的后果。
-
synchronized关键字
在java中,我们最熟悉的莫过于synchronized关键字,在java中每个对象都对象头,对象头中都有一个内置的锁,当我们使用synchronized后相当于调用synchronized获取锁,所以synchronized可以对代码进行加锁,保证只有一个线程可以获取到锁。
-
synchronized方法
当使用synchronized修饰一个方法时,该方法为同步方法,在当前方法返回之前,任何时间只会有同一个线程进入同步方法,如果此时有其他线程都需要执行这个同步方法,那么其他线程会去等待。
public synchronized void increment() { for (int i = 0; i < 10000; i++) { count++; } System.out.println("Count: " + count); }
-
synchronized代码块
对于小的临界区,如果我们直接在方法上声明synchronized,可以避免线程竞争;但是对于较大的临界区,为了执行效率,最好将大的临界区拆分成小的临界区:
1 public class SynchronizedExample { 2 private int count = 0; 3 private Object lock = new Object(); 4 5 public static void main(String[] args) { 6 SynchronizedExample example = new SynchronizedExample(); 7 example.increment(); 8 } 9 10 public void increment() { 11 for (int i = 0; i < 10000; i++) { 12 synchronized (lock) { 13 count++; 14 } 15 } 16 System.out.println("Count: " + count); 17 } 18 }
在synchronized后括号中的对象,代表进入临界区需要获取的对象锁。我们直到在jvm中,每个对象都有一个监视器(Monitor),因此任何对象都可以作为synchronized的同步锁,在上面的例子中放弃了在方法上使用synchronized,而是通过synchronized来拆分了临界区。在这种方式下,多个线程同样可以并发执行increment方法,但是同时只有一个线程可以进入临界区。那么synchronized方法和synchronized代码块有什么区别呢?简单地说synchronized方法时一种比较粗的控制,它的作用范围与整个方法上;而synchronized代码块相对较为精细,在synchronized代码块之外的代码还是可以并发执行的,并不一定所有的代码都需要强制单线程执行。而在synchronized方法其实就是一个synchronized代码块,只不过它的代码块包含了这个方法中所有的代码,所以他们本质来说没有什么区别,就像我们这样写:
1 private int count = 0; 2 public void increment() { 3 synchronized(this) { 4 count++; 5 } 6 } 7 public synchronized void increment() { 8 count++; 9 }
-
静态同步
在java中,一切皆为对象。java对象在编译时会加载成class对象。在class对象中,包含了这个对象的类、名称、属性、方法等等...我们无法通过构造创建一个class对象,它只有在类加载到jvm通过defineClass创建。所有的类都是在第一次使用被动态加载到jvm中,jvm为动态加载机制配套了一个判定动态加载的行为,类加载器首先检查这个class是否被加载,如果没有被加载,则根据类全路径查找class并加载到jvm方法区内存。
普通的synchronized,同步锁是锁当前对象的this的monitor,如果修饰synchronized同时是static修饰的,因为static修饰的方法属于class实例而不是object、静态资源在创建就会被分配,静态方法中是无法使用this指针的,所以synchronized搭配static后无法获取object的this对象监听器。实际上,使用synchronized搭配static时,synchronized锁的并不是object对象,而是class对象中的监视器。一个类对象的实例可能有很多,但是它们只会有一个class对象,所以在使用synchronized搭配static时,会导致jvm内所有线程互斥。这也导致一个jvm内所有线程竞争都是一把锁,颗粒度非常粗。
在synchronized的同步锁,会在代码或方法正常完成退出后释放,当然在异常情况也会自动释放。所以synchronized不需要担心特殊情况导致无法释放的问题。
-
java对象结构与内置锁
摘自《java并发线程》中,提供了基于java对象的描述:
不同的jvm对象结构不一致,下文中以hotspot jvm为例:Hotspot对象并没有将java实例的对象一比一映射到本地native的C++对象中,而是设计了一个oop-klass对象:
我们参考hotsopt的源码可知:1 class oopDesc { 2 friend class VMStructs; 3 friend class JVMCIVMStructs; 4 private: 5 volatile markOop _mark; 6 union _metadata { 7 Klass* _klass; 8 narrowKlass _compressed_klass; 9 } _metadata;1 class instanceOopDesc : public oopDesc { 2 public: 3 // aligned header size. 4 static int header_size() { return sizeof(instanceOopDesc)/HeapWordSize; } 5 6 // If compressed, the offset of the fields of the instance may not be aligned. 7 static int base_offset_in_bytes() { 8 // offset computation code breaks if UseCompressedClassPointers 9 // only is true 10 return (UseCompressedOops && UseCompressedClassPointers) ? 11 klass_gap_offset_in_bytes() : 12 sizeof(instanceOopDesc); 13 } 14 15 static bool contains_field_offset(int offset, int nonstatic_field_size) { 16 int base_in_bytes = base_offset_in_bytes(); 17 return (offset >= base_in_bytes && 18 (offset-base_in_bytes) < nonstatic_field_size * heapOopSize); 19 } 20 };1 class arrayOopDesc : public oopDesc { 2 friend class VMStructs; 3 friend class arrayOopDescTest; 4 5 // Interpreter/Compiler offsets 6 7 // Header size computation. 8 // The header is considered the oop part of this type plus the length. 9 // Returns the aligned header_size_in_bytes. This is not equivalent to 10 // sizeof(arrayOopDesc) which should not appear in the code. 11 static int header_size_in_bytes() { 12 size_t hs = align_up(length_offset_in_bytes() + sizeof(int), 13 HeapWordSize); 14 #ifdef ASSERT 15 // make sure it isn't called before UseCompressedOops is initialized. 16 static size_t arrayoopdesc_hs = 0; 17 if (arrayoopdesc_hs == 0) arrayoopdesc_hs = hs; 18 assert(arrayoopdesc_hs == hs, "header size can't change"); 19 #endif // ASSERT 20 return (int)hs; 21 } 22 }上面版本是基于jdk11 hotspot中定义的c++源码,位于hotspot.share.oops.oop.hpp及其子类。
opp:普通对象指针,表示对象的实例信息,从名字来看是一个指针,实际并不仅仅是一个内存地址,而是内存地址的一个描述或者对内存中数据结构的描述。所以jvm对象类被定义为oppDesc:每当在java代码中创建一个对象时,jvm会创建一个instanceOopDesc实例来表示这个对象,此对象会放在堆区。类似的,当java代码创建一个数组时,jvm会创建一个arrayOopDesc实例来表示,所以我们认为一个普通的java对象底层是一个instanceOopDesc实例。
1 class InstanceKlass: public Klass { 2 friend class VMStructs; 3 friend class JVMCIVMStructs; 4 friend class ClassFileParser; 5 friend class CompileReplay; 6 7 public: 8 static const KlassID ID = InstanceKlassID; 9 10 protected: 11 InstanceKlass(const ClassFileParser& parser, unsigned kind, KlassID id = ID); 12 13 public: 14 InstanceKlass() { assert(DumpSharedSpaces || UseSharedSpaces, "only for CDS"); } 15 16 // See "The Java Virtual Machine Specification" section 2.16.2-5 for a detailed description 17 // of the class loading & initialization procedure, and the use of the states. 18 enum ClassState { 19 allocated, // allocated (but not yet linked) 20 loaded, // loaded and inserted in class hierarchy (but not linked yet) 21 linked, // successfully linked/verified (but not initialized yet) 22 being_initialized, // currently running class initializer 23 fully_initialized, // initialized (successfull final state) 24 initialization_error // error happened during initialization 25 };对于hotspot的代码片段,我们可以理解问,对于jvm来说,它会给加载的类创建一个InstanceKlass对象,用在jvm表示元数据对象。但是这个InstanceKlass对象就是给jvm内部使用的,并不暴露给java层,而在java层使用的类元数据对象是java.lang.Class对象,也就是Class类的实例对象。总体而言,java对象Object结构包括三部分:对象头、对象体和对象字节
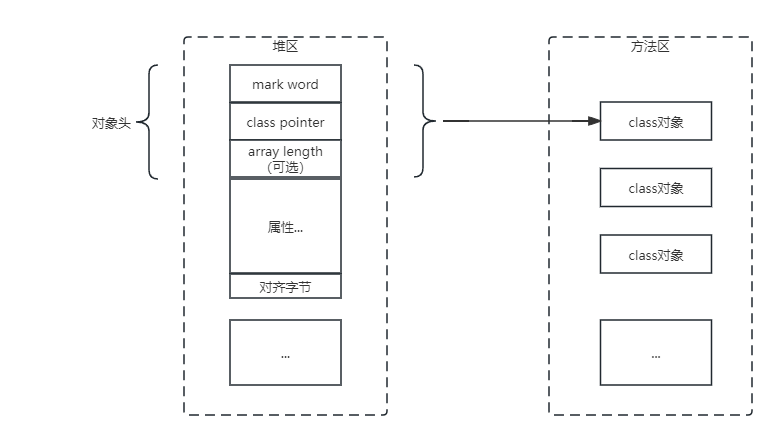
对象头:对象头包括mark word、class pointer、array length:
mark word:用于存储自身运行时数据例如GC标记位、哈希码、锁状态等...
class pointer:指针,用于存放此对象的元数据InstanceKlass地址,虚拟机它通过此指针可以确定是哪个类的实例
array length:数组长度,如果是一个数组,那么包含此字段,用于记录数组的长度
对象体:包含对象的实例变量,用于成员属性,包括弗雷成员属性值。这部分按4字节对齐
对齐字节:对齐字节也叫填充对齐,保证java对象所占的内存字节数为8的倍数。HotSpot VM内存管理要求对象起始位置必须是8的字节整数倍。对象头本身是8的倍数,当对象实例变量数据不是8的倍数时,需要填充数据来保证8字节对齐
在对象结构中,mark word、class pointer、array length都与jvm的位数有关,32位的jvm mark word、class pointer均为一个word长度:32位;在64位jvm下mark word、class pointer均为一个word长度:64位。但是在64位jvm下,如果jvm的对象数量过多,64位将会比32位多浪费出将近50%内存。为了节约内存可以设置UseCompressedOops来开启指针压缩。开启后以下对象将会被压缩指针到32位:
- Class对象指针(静态变量)
- Object对象指针(成员变量)
- 普通对象数组元素指针
在堆内存小于32G时,64位虚拟机会默认开启UseCompressedOops:
java -XX:+UseCompressedOops mainClass
-
Mark word结构
java的内置锁,就存储在对象结构中,并且存储在对象头 mark word中。mark word的长度由jvm的位数决定,不会受到压缩指针的影响。
java内置锁状态有四种,分别为:无锁、偏向锁、轻量级锁和重量级锁。在jdk1.6之前,内置锁是一个重量级锁,效率低下。在jdk1.6之后,jvm为了提高锁的获取与释放效率,堆synchronized实现进行了优化,引入了偏向锁、轻量级锁的实现。并且这四种所会随着竞争情况升级,而且不可降级。
在《jvm锁降级》中有这样一篇文章介绍了锁的降级,内置锁是否支持锁降级,这里不做过多讨论,有兴趣同学可以通过其他文档来查找
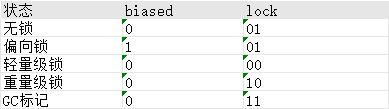
我们忽略32位,主要以64位来说明:

lock:锁标记位,占两个二进制位,希望用尽可能少的二进制表示尽可能多的信息,所以设置了lock标记
biased:用于表示是否是偏向锁,用一个二进制位表示
使用lock和biased两个组合来表示Object实例处于一个什么锁状态,它们的状态可以这样区分:
-
锁升级
我们上面介绍了,基于对象头存储了内置锁的信息,并且在1.6之后内置锁做了优化升级,主要针对锁获取和释放做了优化。首先我们要直到这几种状态对应的锁的表现:
- 无锁:java对象创建完成后还没有线程竞争,这时它是无锁状态
- 偏向锁:指相同的同步代码被同一个线程访问,那么线程会默认获取锁,降低竞争获取锁的代价。当这个线程执行同步代码块时,不需要做任何检查和切换,偏向锁在竞争不激烈时效率很高,通过线程ID记录偏向的线程
- 轻量级锁:当有两个线程竞争同一把锁时,两个线程公平竞争,其中一个线程获取到锁后,会将mark word中记录当前线程帧栈;当锁处于偏向锁又被另一个线程尝试占用时,会撤销偏向锁,锁会升级为轻量级锁。尝试获取锁的线程以自旋的方式获取锁,不会阻塞当前线程,以便提高性能。自旋其实非常简单,如果持有锁的线程在短时间内释放资源,那么等待锁的线程不需要做内核态和用户态的切换进入阻塞挂机,而是等一等...等待释放后尝试获取锁;但是一直自旋是消耗cpu的,如果一直获取不到锁,那么线程不能一直自旋等待,需要让线程自旋一段时间后阻塞休眠,这时就需要直到要自旋多久放弃,在jdk1.6之后引入了自适应性自旋锁,它其实就是由上一次当前锁的自选时间和锁的状态决定的。如果线程上一次自旋成功了,下一次就会更多的自旋...如果自旋失败了,那么就要尽可能少的自旋...
- 如果其他线程自旋且失败了,超过了最大的自旋时间,那么线程会放弃自旋,将锁升级为重量级锁。重量级锁会让尝试获取锁的线程进行阻塞,性能降低。重量级锁也叫同步锁,这时mark word会指向一个monitor监视器,这个监视器对象用来记录排队的线程。
-
偏向锁
在实际开发场景中,如果一个同步代码块,只有一个线程多次重入获取锁,就不需要阻塞线程,唤醒cpu从用户态转为内核态,这就是偏向锁最根本的概念。
偏向锁的原理是,如果一个不存在线程竞争的线程获取锁,那么锁就进入偏向状态,此时lock会改为01,biased会改为1,然后将线程ID使用CAS记录在mark word中。后续线程进入同步代码块时可以通过线程ID和标志位,不需要做任何同步操作。因为在jvm中,大多数情况可能线程并不存在竞争,而是总是由同一个线程获取到锁,从而提升锁的性能;同理如果多个线程竞争频繁,那么偏向锁就是多余的,撤销偏向也会带来一定的性能开销。在jvm中,启用偏向锁会延迟4秒开启,意味着刚创建的对象是不会开启偏向锁的,4秒后创建的对象才会开启偏向锁:因为jvm在启动时有一系列复杂的动作,比如装载配置、初始化。这个过程会有大量的synchronized进行加锁,且大多数锁都会存在竞争,为了减少初始化时间,jvm默认延迟加载偏向。当然我们也可以通过设置jvm的参数来禁止延迟:-XX:+UseBiasedLocking -XX:BiasedLockingStartupDelay=0
-
偏向锁升级和撤销
偏向锁的升级其实很简单,当多个线程竞争后发现当前锁已经偏向(存储了线程ID)并且线程ID不是自己,那么就说明出现了线程竞争,就会尝试撤销偏向锁然后将锁升级为轻量级锁。
在《java并发编程》中描述到:撤销偏向锁的条件为:1.多个线程产生竞争;2.调用偏向锁对象obj的obj.hashCode()或者System.identityHashCode()计算对象哈希码之后。为什么获取hashCode时会撤销偏向锁呢?因为偏向锁中没有存储mark word的哈希码,由上面对象头的设计中我们不难看出,轻量级锁会在栈帧值得lock record记录哈希码,而重量级锁会在monitor中记录哈希码,这样对哈希码起到备份作用。但是在偏向锁中存储的是偏向线程的ID,并没有存储哈希码,所以在调用哈希码的方法时会撤销偏向锁,当锁可偏向后,mark word将变成未锁定状态,并且只能升级成轻量级锁;当对象处于偏向锁时,调用哈希码方法会将偏向锁撤销后强制升级成重量级锁。
偏向锁的撤销代价还是很大的:
- jvm需要获取一个安全点:softPoint(在以前的文章中可以参考关于jvm gc的文章中介绍了安全点)《关于jvm内存模型及GC调优》,当jvm到达安全点后,所有的用户线程将被停止(stw),当然偏向的用户线程也不例外
- 遍历线程栈帧,检查是否存在锁记录。如果存在,就需要清空锁记录,变为无锁的状态,并修复mark word指向,清除存储的偏向线程ID
- 将当前锁升级为轻量级锁,或者重量级锁
- 唤醒当前线程
偏向锁的升级:如果当前锁已经是偏向锁,那么一定会存储偏向线程的ID。此时如果有其他线程尝试抢占锁,因为偏向锁不会主动释放,所以第二个线程一定可以看到内置锁的偏向状态,那么就表明这个锁其实已经存在竞争条件了。jvm去检查原来持有锁的线程是否存活,如果挂了那么就将对象变为无锁状态,并且重新偏向;如果线程依然存活,就表明原来的线程还在使用偏向锁,那么就需要将锁升级为轻量级锁。
在很多情况下,其实进入同一个代码块的线程会是相同的线程,这也就是jvm优化偏向锁的目的。
-
轻量级锁
轻量级锁的目的主要是在多线程竞争不激烈的情况下,通过CAS机制减少下性能损耗。
重量级锁使用了操作系统的互斥(Mutex Lock),会在用户态和内核态间来回切换,从而带来较大的性能损耗。而轻量级锁就是为了避免这种情况。很多锁对象状态可能很快就会被释放,在短时间内阻塞并唤醒线程显然不值得,为此引入了轻量锁的概念。轻量锁是一种自旋锁,它只需要在jvm层面进行自旋解决线程同步问题。
轻量锁执行过程:
- 线程进入临界区之前,如果内置锁没有锁定,jvm在lock record中记录一个锁记录,用于存储对象目前mark word的拷贝
- 然后进行CAS自旋,抢锁线程通过CAS自旋,尝试将内置锁对象头的ptr_to_lock_record更新为当前抢占锁线程栈帧中的记录地址,如果这个操作成功了就表示这个线程已经获取到当前的锁,然后将lock标记修改为00轻量锁
- CAS更新成功后,会返回旧值。这时线程会将旧的mark word备份,在释放之后会将旧值恢复到锁的对象头(内置锁对象mark word会发生改变,会出现指向锁的指针,而无锁状态下会存储对象的hash信息)
轻量锁中包含了两种轻量锁,就是上文中说到的默认轻量锁和自适应轻量锁:
默认轻量锁:轻量锁执行CAS是需要消耗CPU的,所以不能让轻量锁无休止的自旋,这也说明轻量锁更适合哪些临界区耗时很短的场景。默认情况下自旋次数为10次,可以通过-XX:PreBlockSpin来修改
自适应轻量锁:自旋次数不固定,而是依靠上一次自旋的结果和自旋的次数决定,可以理解为:如果上一次自旋成功,那么我认为这一次应该也能成功;如果上一次失败,那么这次可能也没办法成功。
-
轻量锁的升级
我们希望轻量级锁都用于耗时很快的同步块中,但是有时候总是事与愿违。那么如果一个线程执行同步块很慢,那么会导致什么问题?过大的自旋导致CPU性能消耗大,所以当竞争激烈的情况下,轻量锁会升级为重量级锁(Mutex Lock)
-
重量级锁
在jvm中,包含了一个监视器monitor,它包含了对象头和对象信息,它相当于一个令牌。本质上,监视器是一种同步工具,也是一种同步机制:获取到令牌的人先...只有一个令牌可以被获取...获取到令牌后需要返还...
那么我们可以将这个思想具体拆分:
- 同步,互斥执行,因为只有一个令牌
- 通信,一个线程拿着令牌执行完成,其他线程全部阻塞休眠。那么怎么让它们直到这个令牌已经空闲了
在ObjectMonitor.hpp hotSpot源码中是这么写的
1 class ObjectMonitor { 2 public: 3 enum { 4 OM_OK, // no error 5 OM_SYSTEM_ERROR, // operating system error 6 OM_ILLEGAL_MONITOR_STATE, // IllegalMonitorStateException 7 OM_INTERRUPTED, // Thread.interrupt() 8 OM_TIMED_OUT // Object.wait() timed out 9 }; 10 11 private: 12 friend class ObjectSynchronizer; 13 friend class ObjectWaiter; 14 friend class VMStructs; 15 16 volatile markOop _header; // displaced object header word - mark 17 void* volatile _object; // backward object pointer - strong root 18 public: 19 ObjectMonitor* FreeNext; // Free list linkage 20 private: 21 DEFINE_PAD_MINUS_SIZE(0, DEFAULT_CACHE_LINE_SIZE, 22 sizeof(volatile markOop) + sizeof(void * volatile) + 23 sizeof(ObjectMonitor *)); 24 protected: // protected for JvmtiRawMonitor 25 void * volatile _owner; // pointer to owning thread OR BasicLock 26 volatile jlong _previous_owner_tid; // thread id of the previous owner of the monitor 27 volatile intptr_t _recursions; // recursion count, 0 for first entry 28 ObjectWaiter * volatile _EntryList; // Threads blocked on entry or reentry. 29 // The list is actually composed of WaitNodes, 30 // acting as proxies for Threads. 31 private: 32 ObjectWaiter * volatile _cxq; // LL of recently-arrived threads blocked on entry. 33 Thread * volatile _succ; // Heir presumptive thread - used for futile wakeup throttling 34 Thread * volatile _Responsible; 35 36 volatile int _Spinner; // for exit->spinner handoff optimization 37 volatile int _SpinDuration; 38 39 volatile jint _count; // reference count to prevent reclamation/deflation 40 // at stop-the-world time. See deflate_idle_monitors(). 41 // _count is approximately |_WaitSet| + |_EntryList| 42 protected: 43 ObjectWaiter * volatile _WaitSet; // LL of threads wait()ing on the monitor 44 volatile jint _waiters; // number of waiting threads 45 private: 46 volatile int _WaitSetLock; // protects Wait Queue - simple spinlock
摘取部分代码:
_waitSet:用ObjectWaiter实现的链表
_cxq:用ObjectWaiter实现的竞争队列
_EntryList:候选线程队列
简单来看呢,其实也很清晰,回想起aqs的阻塞队列,将新来的所有线程都放入cxq,然后进过候选的线程放入enrtyList,再通过合适的时机将队列中的线程唤醒.... jvm的源码超出了认知... 不做过多解析,感兴趣的朋友自行下载openjdk hotspot源码进行查看
-
线程通信
线程通信相关不在本章做详细介绍,关于wait、notify等等.. 请参考《关于LockSupport》这里有对于基本线程间通信的内容。
本文来自博客园,作者:青柠_fisher,转载请注明原文链接:https://www.cnblogs.com/oldEleven/p/17865903.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号