

机器学习入门 06 数理统计中的描述统计
目录
数理统计
1.描述统计
2.
1.描述统计
1.什么是描述统计?
描述统计描述统计 从数据中提取 变量的主要信息
2.从数据中提取 变量的主要信息 => 【指标】 统计量
统计量
1.频率与频数
2.集中趋势分析:
均值、中位数、众数、分位数
3.离散程度分析:
极差、方差、标准差
4.分布形状:
偏度、峰度
3.提取 变量:
1.数值变量【就是一个table 中的 column 是数值类型】
2.类别变量【就是一个table 中的 column 是非数值类型 String】
统计量
1.频率与频数
1.适用场景 =》 类别变量
2.频数:就是 每个不同的取值出现的次数
3.频率:每个不同的取值出现的次数 与 总次数的比值 用%表示
意义:
类别变量中,每个取值出现的次数
eg:
A班级 及格 30人 , B班级及格 35人 能说明(4)
1.A班级 成绩更好
2.B班级 成绩更好
3.成绩差不多
4.无法确定哪个班级成绩好
分析:
1.类别变量 =》 及格
2.频数 =》 及格人数
3.缺少总数
import pandas as pd
if __name__ == '__main__':
df = pd.read_csv(r"D:\chinasoft international\python-sk\0413study\emp.csv",index_col="eid")
print(df.head())
# 1.频数
job_cnt = df['job'].value_counts()
print(job_cnt)
# 2.频率 = 频数 / 总次数
job_percent = job_cnt * 100 / len(df)
print(job_percent)
# 3.数据可视化
import matplotlib.pyplot as plt
import seaborn as sns
sns.countplot(data=df,x="job")
plt.show()
2.集中趋势分析
均值、中位数、众数、分位数
均值:一组数据的总和 除以 数据的个数
均值 = 和 / 个数
中位数:一组数据的 按照 升序进行排列 最中间的位置 就是 中位数
众数:一组数据 出现的次数最多的值
注意:
1.数值变量:
均值、中位数 表示一组数据的集中程度
2.类别变量:
众数 集中程度
3.分布:
正态分布:
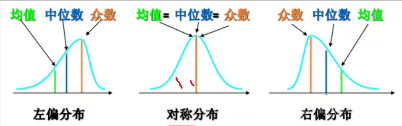
偏态分布:
左偏分布:均值在最左边 均值 中位数 众数
右偏分布:均值在最右边 众数 中位数 均值
4.影响:
1.均值 =》 受 极端值 影响
2.中位数 众数 不受极端值影响【稳定】
3.众数 一组数据 中 可能不是唯一的【单拿出来 是不行的】
import warnings
import pandas as pd
if __name__ == '__main__':
df = pd.read_csv(r"D:\chinasoft international\python-sk\0413study\emp.csv",index_col="eid")
print(df.head())
# sal 均值 中位数 众数
sal_mean = df['sal'].mean()
print('sal_mean:',sal_mean)
sal_meedian = df['sal'].median()
print('sal_meedian:',sal_meedian)
# 众数1
sal_mode = df['sal'].mode()
print('sal_mode',sal_mode)
# 众数2 scipy
from scipy import stats
print(stats.mode(df['sal']))
# 3.画图
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family'] = 'SimHei'
sns.displot(df['sal'])
plt.axvline(sal_mean,ls='-',color='r',label='均值')
plt.axvline(sal_meedian, ls='-', color='g', label='中位数')
# plt.axvline(sal_mode, ls='-', color='b', label='众数')
plt.legend()
plt.show()
问:
国家城市统计居民收入水平,使用哪个指标衡量更合适?(2)
1.均值
2.中位数
3.中位数或者众数
4.都可以
意义:
衡量数据综合水平
思考:
缺失值填充 如何处理
1.数据 =》 0
2.数据 去掉
3.补充 =》 中位数
分位数:
通过 (n-1) 分为 划分 n 个区间
每个区间的数据个数都是相等的(近似相等)
意义:
利用分位数 + 极值 可以判断 数据的分布状态
集中趋势分析:
弊端:
5 5 5 5 =》 5
0 -5 20 5 =》 5
-100 100 120 -100 =》 5
import warnings
import pandas as pd
import numpy as np
if __name__ == '__main__':
x = [1,3,10,15,18,21,24,40]
# 1.numpy
print(np.quantile(x, q=[0.25,0.5,0.75])) # q = 0 ~ 1
print(np.percentile(x, q=[25,50,60])) # q = 0 ~ 100
# 2.pd
x = [1,3,10,15,18,21,24,40]
df = pd.Series(x)
print(df.describe())
print(df.describe(percentiles=[0.2,0.9]))
3.离散程度分析:
极差、方差、标准差
极差:一组数据中,最大值 - 最小值
方差:一组数据中 每个元素 与 均值的偏离 大小
标准差:就是方差的开方
意义:
方差/标准差:
1.数据的分散性
越大 数据越分散
越小 数据越集中
2.数据的波动性
import warnings
import pandas as pd
import numpy as np
if __name__ == '__main__':
df = pd.read_csv(r"D:\chinasoft international\python-sk\0413study\emp.csv",index_col="eid")
print(df.head())
# sal 字段 方差、标准差
sal_std = df['sal'].std()
sal_var = df['sal'].var()
print(sal_std,sal_var)
# 2.画图
warnings.filterwarnings("ignore")
import matplotlib.pyplot as plt
import seaborn as sns
plt.figure(figsize=(10,4))
plt.plot(df['sal'],np.zeros(len(df)),ls='',marker='o',ms='10',color='g',label='sal')
plt.axvline(df['sal'].mean(),ls='--',color='g',label='sal')
plt.show()
4.分布形状:
偏度、峰度
1.偏度:
倾斜程度的度量
eg :
数据 -> 正态分布 偏度就是 0
数据 -> 左偏分布 偏度就是 小于0
数据 -> 右偏分布 偏度就是 大于0
import warnings
import pandas as pd
import numpy as np
if __name__ == '__main__':
# 1.构造左偏数据
t1 = np.random.randint(1,11,size=100)
t2 = np.random.randint(11,21,size=500)
concat = np.concatenate([t1, t2])
df_left = pd.Series(concat)
# 2.构造右偏数据
t1 = np.random.randint(1,11,size=500)
t2 = np.random.randint(11,21,size=100)
concat = np.concatenate([t1, t2])
df_right = pd.Series(concat)
# 3.计算偏度
print(df_left.skew(),df_right.skew())
# 4.画图
import matplotlib.pyplot as plt
import seaborn as sns
plt.rcParams['font.family'] = 'SimHei'
warnings.filterwarnings("ignore")
sns.kdeplot(df_left,shade=True,label='左偏')
sns.kdeplot(df_right, shade=True, label='右偏')
plt.legend()
plt.show()
2.峰度:
描述 数据分布 陡缓的成都
1.标准 正态分布 峰度 0
2.如果 峰度 > 0
数据在分布上 数据比 标准 正态分布 密集 =》 方差比较小
2.如果峰度 < 0
数据在分布上 数据比 标准 正态分布 分散 =》 方差比较大
意义:
1.通过这两个指标 =》 数据的分布特征
2.数据正态校验
import pandas as pd
import numpy as np
if __name__ == '__main__':
df = pd.read_csv(r"D:\chinasoft international\python-sk\0413study\emp.csv",index_col="eid")
print(df.head())
# sal 峰度
sal__kurt = df['sal'].kurt()
print(sal__kurt)
# 构造一个 标准正态的数据
stand_df = pd.Series(np.random.normal(0, 1, size=100))
print(stand_df.kurt())
# sal 数据标准化
df_sal = (df['sal'] - df['sal'].mean())/df['sal'].std()
# 画图
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
plt.rcParams['font.family'] = 'SimHei'
sns.kdeplot(stand_df,label='标准正态')
sns.kdeplot(df_sal,label='sal')
plt.legend()
plt.show()


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 无需6万激活码!GitHub神秘组织3小时极速复刻Manus,手把手教你使用OpenManus搭建本
· Manus爆火,是硬核还是营销?
· 终于写完轮子一部分:tcp代理 了,记录一下
· 别再用vector<bool>了!Google高级工程师:这可能是STL最大的设计失误
· 单元测试从入门到精通