Pandas中的map(), apply()和applymap()
它们的区别在于应用的对象不同。
1、map()
map() 是一个Series的函数,DataFrame结构中没有map()。map()将一个自定义函数应用于Series结构中的每个元素(elements)。
例子:
df = pd.DataFrame({'key1' : ['a', 'a', 'b', 'b', 'a'],
'key2' : ['one', 'two', 'one', 'two', 'one'],
'data1' : np.arange(5),
'data2' : np.arange(5,10)})
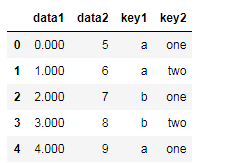
df

我们现在用map来对列data1改成保留小数点后三位:
df['data1'] = df['data1'].map(lambda x : "%.3f"%x)
df
你也可以用map把key1的a改成c,b改成d
df['key1'] = df['key1'].map({'a':'c',"b":"d"})
df

2、apply()
apply()将一个函数作用于DataFrame中的每个行或者列
例子:
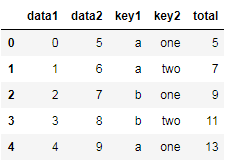
我们现在用apply来对列data1,data2进行相加
#axis =1 ,作用于行.
#axis =0,作用于列,默认为0
df['total'] = df[['data1','data2']].apply(lambda x : x.sum(),axis=1 )
df
df.loc['total'] = df[['data1','data2']].apply(lambda x : x.sum(),axis=0 )
df

3、applymap()
将函数做用于DataFrame中的所有元素(elements)
例子:
例如,在所有元素前面加个字符A
def addA(x):
return "A" + str(x )
df.applymap(addA)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号