文件读取与存储
pandas的API支持众多的文件格式,如CSV、SQL、XLS、JSON、HDF5。
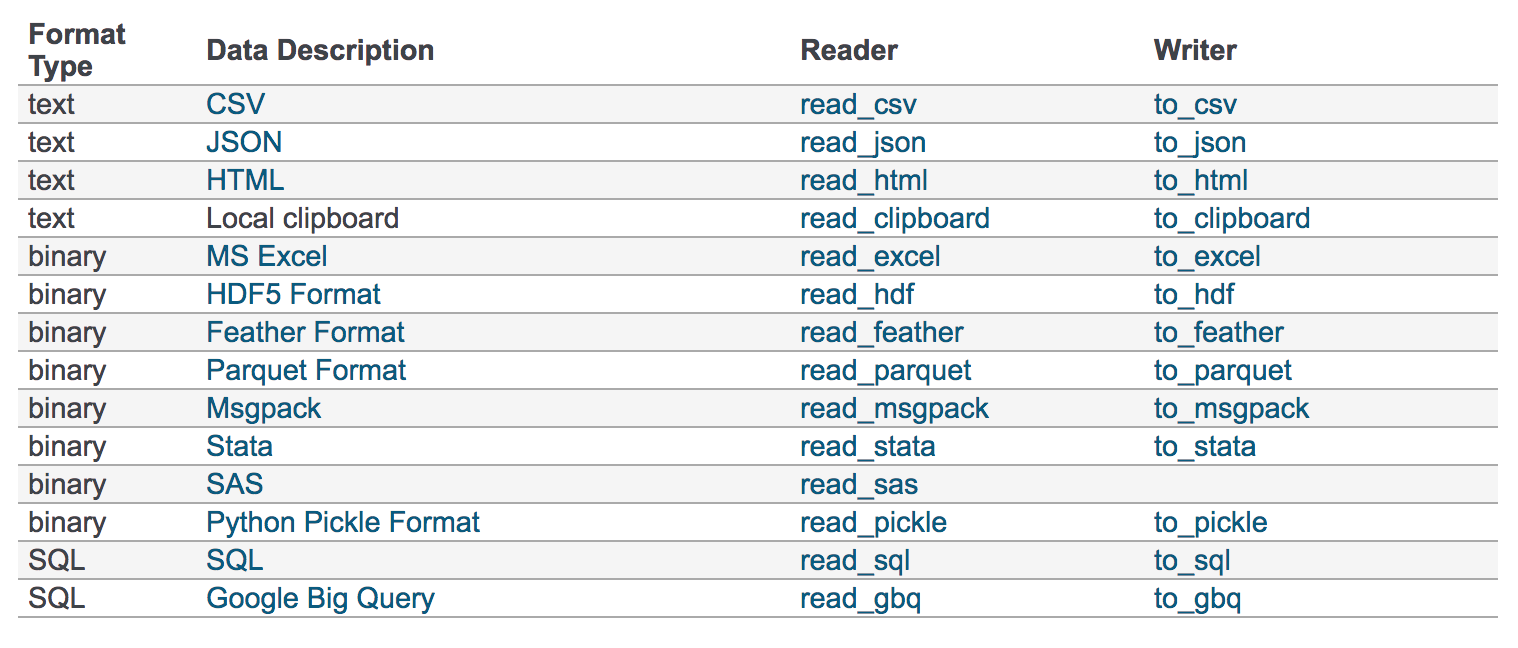
CSV
- pandas.read_csv(filepath_or_buffer, sep =',' )
- filepath_or_buffer:文件路径
- usecols:指定读取的列名,列表形式
- sep-分割字符 默认','
# 读取文件,并且指定只获取'open', 'close'指标
data = pd.read_csv("./data/stock_day.csv", usecols=['open', 'close'])
- to_csv
- DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, mode='w', encoding=None)
- path_or_buf :string or file handle, default None
- sep :character, default ‘,’
- columns :sequence, optional
- mode:'w':重写, 'a' 追加
- index:是否写进行索引
- header :boolean or list of string, default True,是否写进列索引值
- DataFrame.to_csv(path_or_buf=None, sep=', ’, columns=None, header=True, index=True, mode='w', encoding=None)
HDF5
HDF5文件的读取和存储需要指定一个键,值为要存储的DataFrame
从h5文件当中读取数据
- pandas.read_hdf(path_or_buf,key =None,** kwargs)
- path_or_buffer:文件路径
- key:读取的键
- return:Theselected object
- DataFrame.to_hdf(path_or_buf, key, \kwargs)
- key:指定保存的键名
JSON
-
read_json—读取文件
- orient--指定读取数据的字典格式
- records—一行一个记录
- lines—是否分行--一个记录一行
-
DataFrame.to_json(path_or_buf=None, orient=None, lines=False)
- 将Pandas 对象存储为json格式
- path_or_buf=None:文件地址
- orient:存储的json形式,
- lines:一个对象存储为一行
-
to_json--存储文件—注意:lines=True
优先选择使用HDF5文件存储
- HDF5在存储的时候支持压缩,使用的方式是blosc,这个是速度最快的也是pandas默认支持的
- 使用压缩可以提磁盘利用率,节省空间
- HDF5还是跨平台的,可以轻松迁移到hadoop 上面

 浙公网安备 33010602011771号
浙公网安备 33010602011771号