Pandas结构
DataFrame结构
DataFrame对象既有行索引,又有列索引
行索引,表明不同行,横向索引,叫index,0轴,axis=0
列索引,表名不同列,纵向索引,叫columns,1轴,axis=1
DatatFrame的属性
-
shape
-
df.shape—形状
-
df.index--行索引
-
df.columns--列索引
-
df.values—值—ndarray
-
df.T-转置—注意:转置后行索引-列索引互换
-
df.head(n)—看头部的n(默认5)行
-
df.tail(n)—看尾部的n(同上)行
DatatFrame索引的设置
-
修改索引
- df.index=新索引
- 注意:只能整体修改--Index类型是一个不可变(immutable)对象
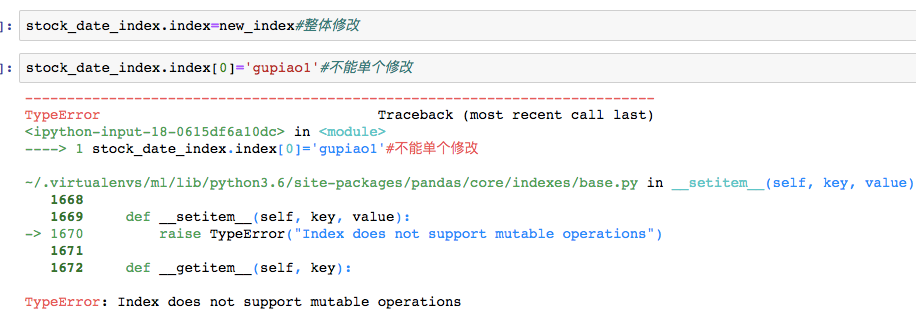
-
重设索引
- df.reset_index(drop=Fasle)
- 注意:df中的索引本身也是数据的一部分
- drop:默认为False,不删除原来索引,如果为True,删除原来的索引值
-
列设为索引
- df.set_index(keys)
- keys:列索引名成或者列索引名称的列表---可以设置多列(类似于数据库表中的组合主键)
- drop : boolean, default True.当做新的索引,删除原来的列
MultiIndex
多级或分层索引对象。
- index属性
- names:levels的名称
- levels:每个level的元组值
df.index.names
FrozenList(['year', 'month'])
df.index.levels
FrozenList([[1, 2], [1, 4, 7, 10]])
Panel
注:Pandas从版本0.20.0开始弃用:推荐的用于表示3D数据的方法是通过DataFrame上的MultiIndex方法
- class pandas.Panel(data=None, items=None, major_axis=None, minor_axis=None, copy=False, dtype=None)
- 存储3维数组的Panel结构
Series结构
- 只有行索引--没有列索引
# series
type(data['2017-01-02'])
pandas.core.series.Series
# 这一步相当于是series去获取行索引的值
data['2017-01-02']['股票_0']
-0.18753158283513574
创建series
- 直接给值--同时可以指定行索引
# 指定内容,默认索引
pd.Series(np.arange(10))
# 指定索引
pd.Series([6.7,5.6,3,10,2], index=[1,2,3,4,5])
- 通过字典
pd.Series({'red':100, ''blue':200, 'green': 500, 'yellow':1000})
- series获取属性和值--没有columns属性
- index
- values
基本数据操作——索引
- 直接使用行列索引(先列后行)—series式访问
data['open']['2018-02-23']先拿到seriess,再通过行索引拿到值
# 直接使用行列索引名字的方式(先列后行)
data['open']['2018-02-27']
23.53
# 不支持的操作
# 错误
data['2018-02-27']['open']
# 错误
data[:1, :2]

- 结合loc或者iloc使用索引—数组式访问
- 跟numpy类似 一定是方括号
- df.loc—只能给索引名
- df.iloc--只认识下标
# 使用loc:只能指定行列索引的名字
data.loc['2018-02-27':'2018-02-22', 'open']
2018-02-27 23.53
2018-02-26 22.80
2018-02-23 22.88
Name: open, dtype: float64
# 使用iloc可以通过索引的下标去获取
# 获取前100天数据的'open'列的结果
data.iloc[0:100, 0:2].head()
open high close low
2018-02-27 23.53 25.88 24.16 23.53
2018-02-26 22.80 23.78 23.53 22.80
2018-02-23 22.88 23.37 22.82 22.71
- 使用ix组合索引
- 下标和索引名都认识---效率问题
- 推荐使用loc和iloc来获取的方式
# 通过df.index[0:4] 拿到下标对应的索引名
# 通过df.columns.get_indexer([索引名]) 拿到索引名对应的下标
data.loc[data.index[0:4],['open', 'close', 'high', 'low']]
data.iloc[0:4, data.columns.get_indexer(['open', 'close', 'high', 'low'])]
- 赋值
- 直接访问到谁直接可以复制
# 直接修改原来的值
data['close'] = 1
# 或者
data.close = 1
基本数据操作——排序
- 索引排序—df.sort_index(ascending=)
# 对索引进行排序
data.sort_index()
- 使用df.sort_values(by=, ascending=)
- 单个键或者多个键进行排序,默认升序
- ascending=False:降序
- ascending=True:升序
# 按照多个键进行排序
data = data.sort_values(by=['open', 'high'])
series的排序--没有by参数--因为只有一列
- 使用series.sort_values(ascending=True)进行排序
data['p_change'].sort_values(ascending=True).head()
- 使用series.sort_index()进行排序
# 对索引进行排序
data['p_change'].sort_index().head()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号