数据采集作业4
| 这个作业属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 这个作业要求在哪里 | 作业4 |
| 这个作业的目标 | 1.selenium爬虫设计 2.掌握selenium爬虫框架 3.学习selenium查找获取HTML元素 4.模拟用户登录 3.学习爬取ajax网站 4.mysql数据库的读写 5.flume日志采集 |
| 学号 | 102202123 |
Gitee🔗:作业4
作业前两题整体思路:
- 初始化浏览器驱动
- 启动MySQL,创建数据库、表
- 打开网站模拟进行指定操作
- 登录(如果需要)
- 查找所需数据并爬取(涉及页面滚动、点击、翻页等操作)
- 插入数据库(json格式存储:批量/爬取一项插入一项)
- 爬虫结束,关闭浏览器和数据库连接
此处标明了前两题的大体思路,后续实验过程只会详细介绍打开网站模拟进行指定操作
作业①
要求:
熟练掌握 Selenium 查找HTML元素、爬取Ajax网页数据、等待HTML元素等内容。
使用Selenium框架+ MySQL数据库存储技术路线爬取“沪深A股”、“上证A股”、“深证A股”3个板块的股票数据信息。
候选网站:东方财富网:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
输出信息:MYSQL数据库存储和输出格式如下,表头应是英文命名例如:序号id,股票代码:bStockNo……,自行定义设计表头
详细代码见gitee🔗:作业4-stock.py
实践说明
这题的爬取的数据会以json格式暂时存储,后续批量导入MySQL数据库
网页观察
1.该网站的每个板块都是一个ajax网页,翻页的时候url不会改变
2.点击别的板块后url会改变 http://quote.eastmoney.com/center/gridlist.html#{板块缩写}_a_board
3.所需数据HTML元素的观察与获取(略,在先前博客已经详细解释)
4.针对单个板块的ajax网站翻页爬取(略,上个博客已实现,模拟用户点击“下一页”)
5.点击不同板块,从而爬取不同板块信息
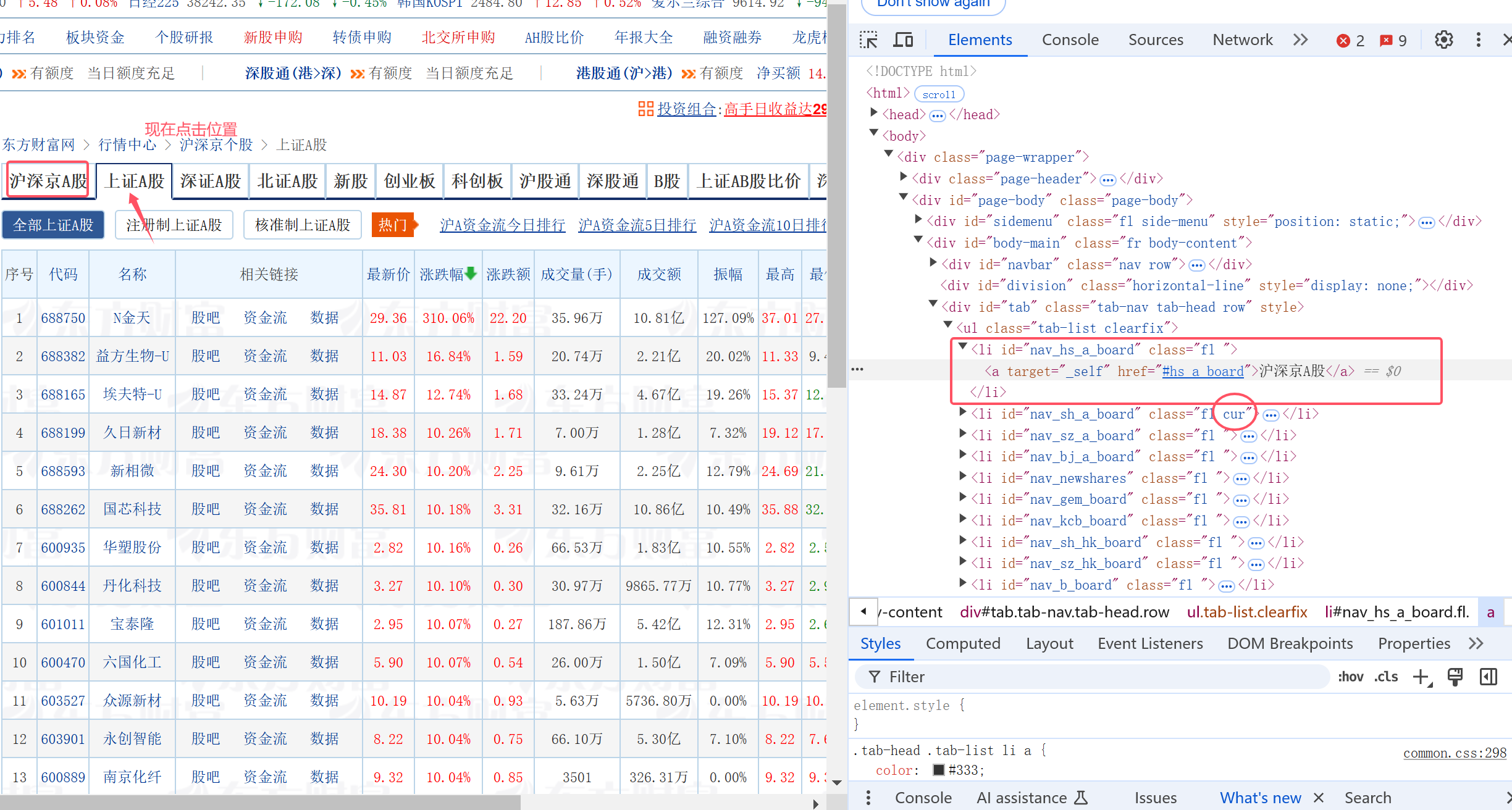
总的来说,每个板块的按键都有一个显著的id元素(nav_{板块缩写}_a_board)可迅速定位点击
"""点击板块标签并强制等待页面数据加载"""
try:
# 隐式等待板块标签可点击
WebDriverWait(self.driver, 20).until(
EC.element_to_be_clickable((By.ID, tab_id))
)
tab = self.driver.find_element(By.ID, tab_id)
tab.click()
time.sleep(5) # 强制等待页面数据加载,不然后面会报错
WebDriverWait(self.driver, 20).until(
EC.presence_of_all_elements_located((By.XPATH, '//table/tbody//tr'))
)
except Exception as e:
print(f"Error clicking {tab_id}: {e}")
return
单个板块内的爬取
stocks = self.driver.find_elements(By.XPATH, '//table/tbody//tr')
print(f"Found {len(stocks)} stocks on page 1.")
for i in range(len(stocks)):
try:
stocks = self.driver.find_elements(By.XPATH, '//table/tbody//tr')
stock = stocks[i]
item = {
# 由于这题采取统一存入数据库,这里需要用json方式存储股票数据
'stock_id': prefix + stock.find_element(By.XPATH, './td[1]').text,
'stock_code': stock.find_element(By.XPATH, './td[2]/a').text,
'stock_name': stock.find_element(By.XPATH, './td[3]/a').text,
'latest_price': stock.find_element(By.XPATH, './td[5]/span').text,
'change_percent': stock.find_element(By.XPATH, './td[6]/span').text,
'change_amount': stock.find_element(By.XPATH, './td[7]/span').text,
'volume': stock.find_element(By.XPATH, './td[8]').text,
'amplitude': stock.find_element(By.XPATH, './td[10]').text,
'high': stock.find_element(By.XPATH, './td[11]/span').text,
'low': stock.find_element(By.XPATH, './td[12]/span').text,
'open': stock.find_element(By.XPATH, './td[13]/span').text,
'prev_close': stock.find_element(By.XPATH, './td[14]').text
}
# 在控制台打印显示爬取情况作为调试
print(
f"Scraped stock: {item['stock_name']} ({item['stock_code']}) - Latest Price: {item['latest_price']}")
processed_item = self.process_item(item)
if processed_item:
all_items.append(processed_item)
except Exception as e:
print(f"Error processing stock: {e} - Stock data may be incomplete.")
多板块爬取存入数据库的问题与解决
由于每个板块的id都是以1-20排序
很容易出现当前序号已存在,会插入数据库失败的情况。
所以我对它们的序号进行了一定修正,强制存入stock_id前,要在对应板块的id前面加上板块缩写
而这个缩写prefix,会在爬取对应板块的函数方法中传入
'stock_id': prefix + stock.find_element(By.XPATH, './td[1]').text
爬虫思路汇总
把整个思路都汇总在scrape中
- 上述的单板块爬取一并写为
click_tab_and_scrape(先点击切换板块,再爬取内容) batch_insert以json格式插入MySQL数据库
def scrape(self):
"""爬取沪深京A股、上证A股和深证A股数据"""
self.driver.get(self.start_url)
self.driver.implicitly_wait(20) # 使用隐式等待,等待页面元素加载完成
# 存储所有页的数据
all_items = []
# 爬取沪深京A股数据
print("Scraping 沪深京A股...")
self.click_tab_and_scrape('nav_hs_a_board', 'hs_', all_items)
# 爬取上证A股数据
print("Scraping 上证A股...")
self.click_tab_and_scrape('nav_sh_a_board', 'sh_', all_items)
# 爬取深证A股数据
print("Scraping 深证A股...")
self.click_tab_and_scrape('nav_sz_a_board', 'sz_', all_items)
# 批量插入数据
self.batch_insert(all_items)
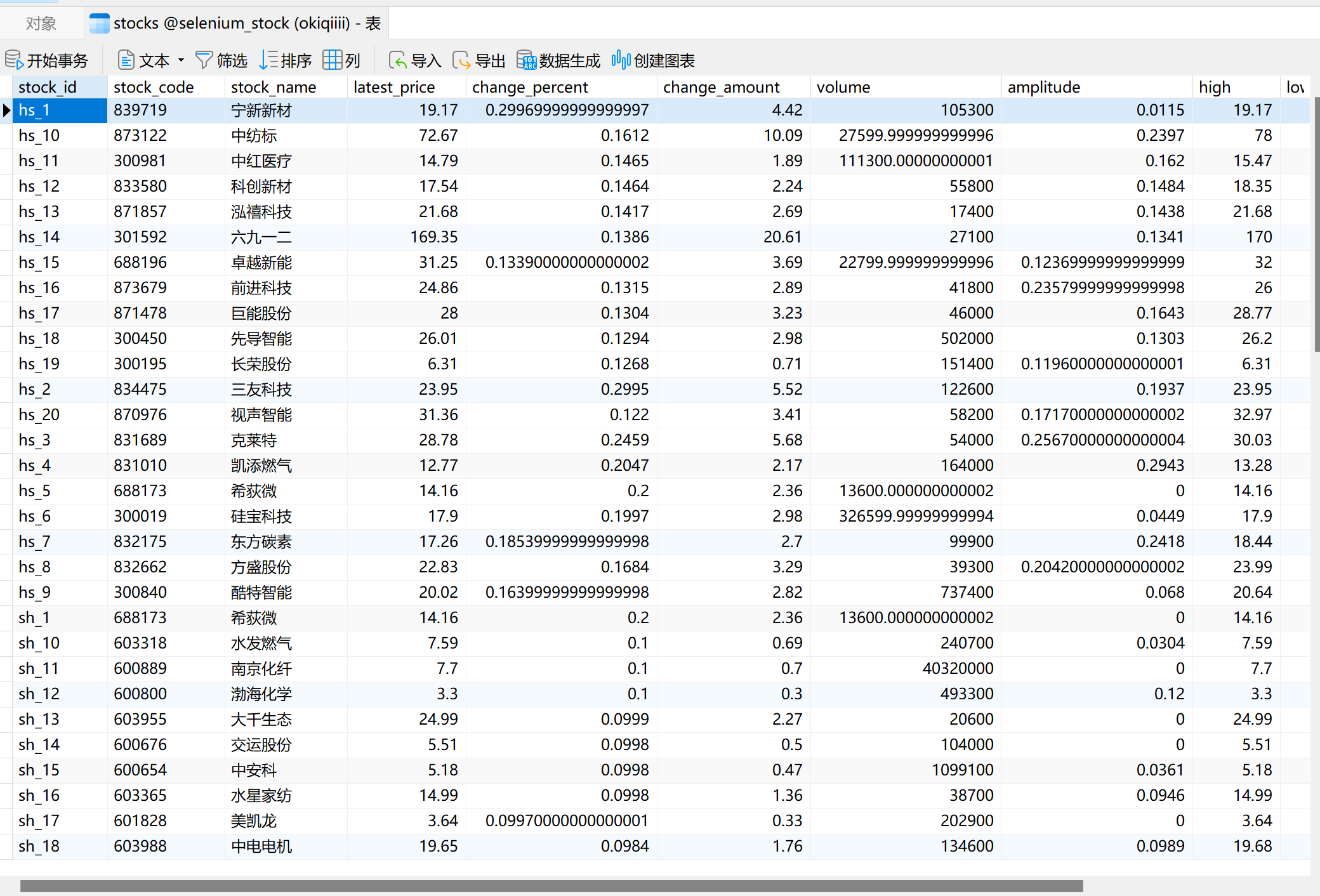
实践结果
实践心得
一开始爬取的时候经常会遇到一个问题:单个页面的数据不能完整地爬取就点击进入了下一个板块(适当添加隐式等待解决了),以及进入下一个板块还没加载完全就开始爬取,可能又会出现就头部一两条数据没爬下来的情况、、(后面强制等待一下解决了)
所以在代码中也不断地注意添加隐式等待和强制等待,让页面的数据完整显示再爬取。
这题采取了批量导入数据,和之前做的方法都很不一样,用到了其实现在比较常规的使用json文件批量将数据导入数据库,在爬取过程中也注重了爬取数据的格式化。
作业②
要求:
熟练掌握 Selenium 查找HTML元素、实现用户模拟登录、爬取Ajax网页数据、等待HTML元素等内容。
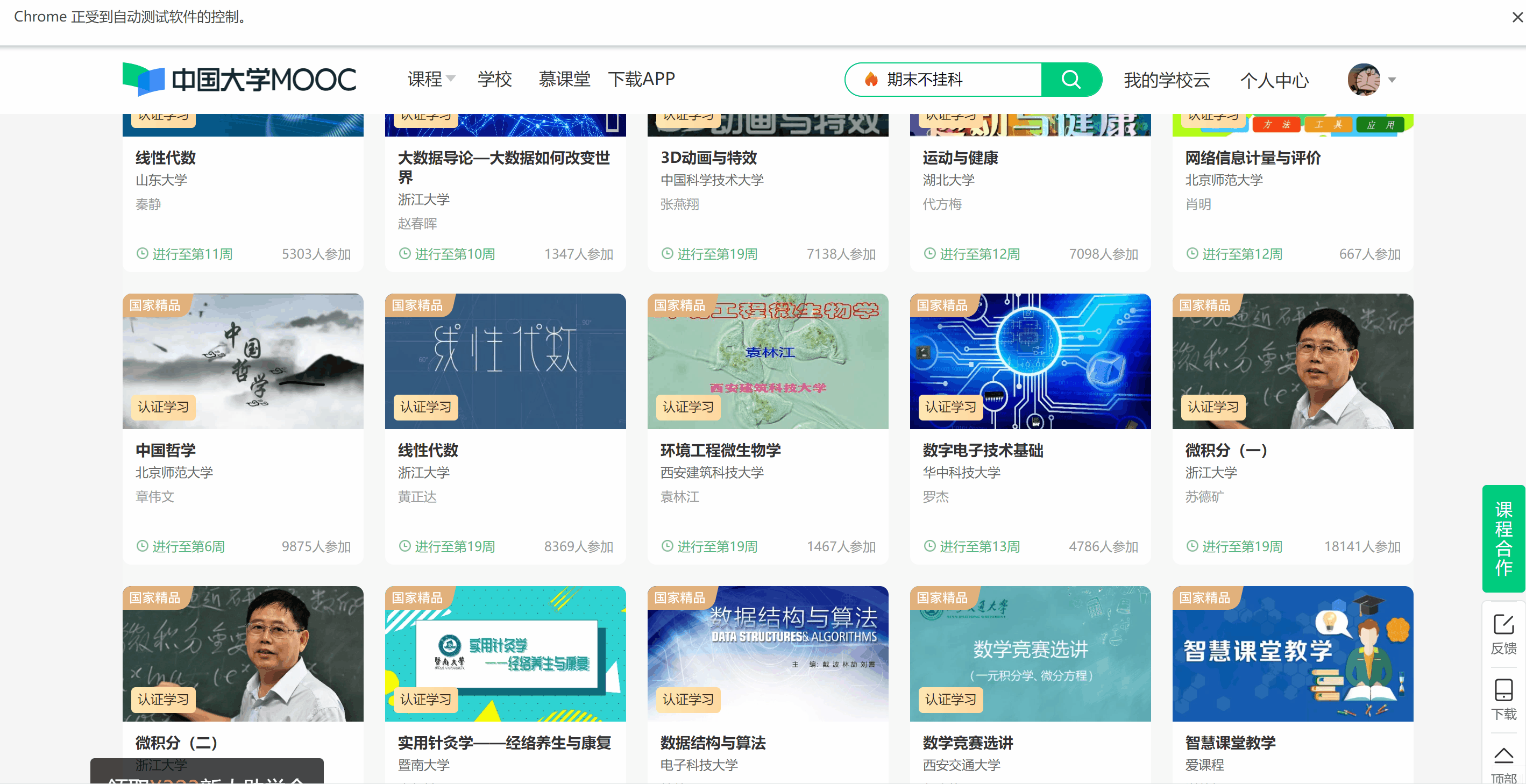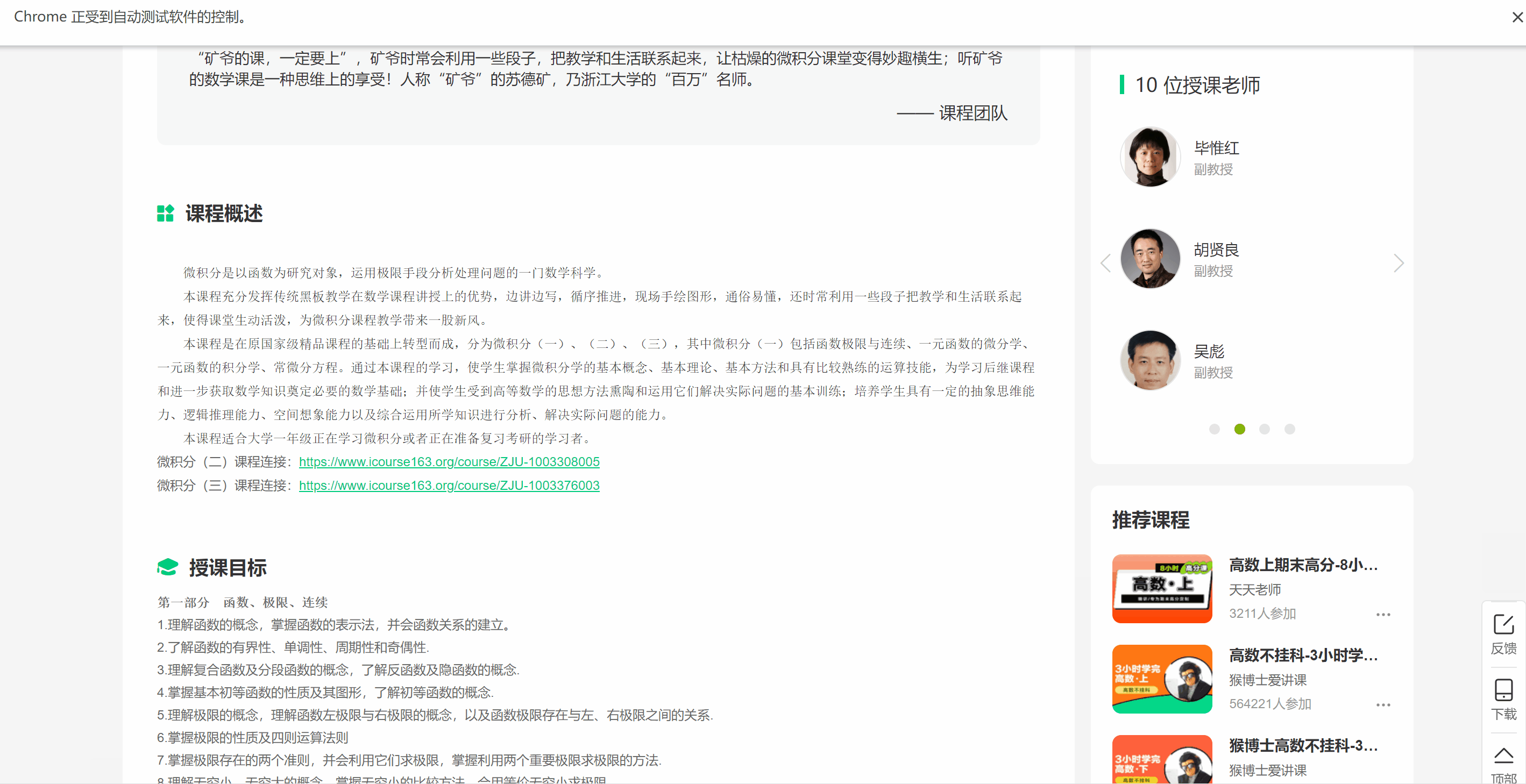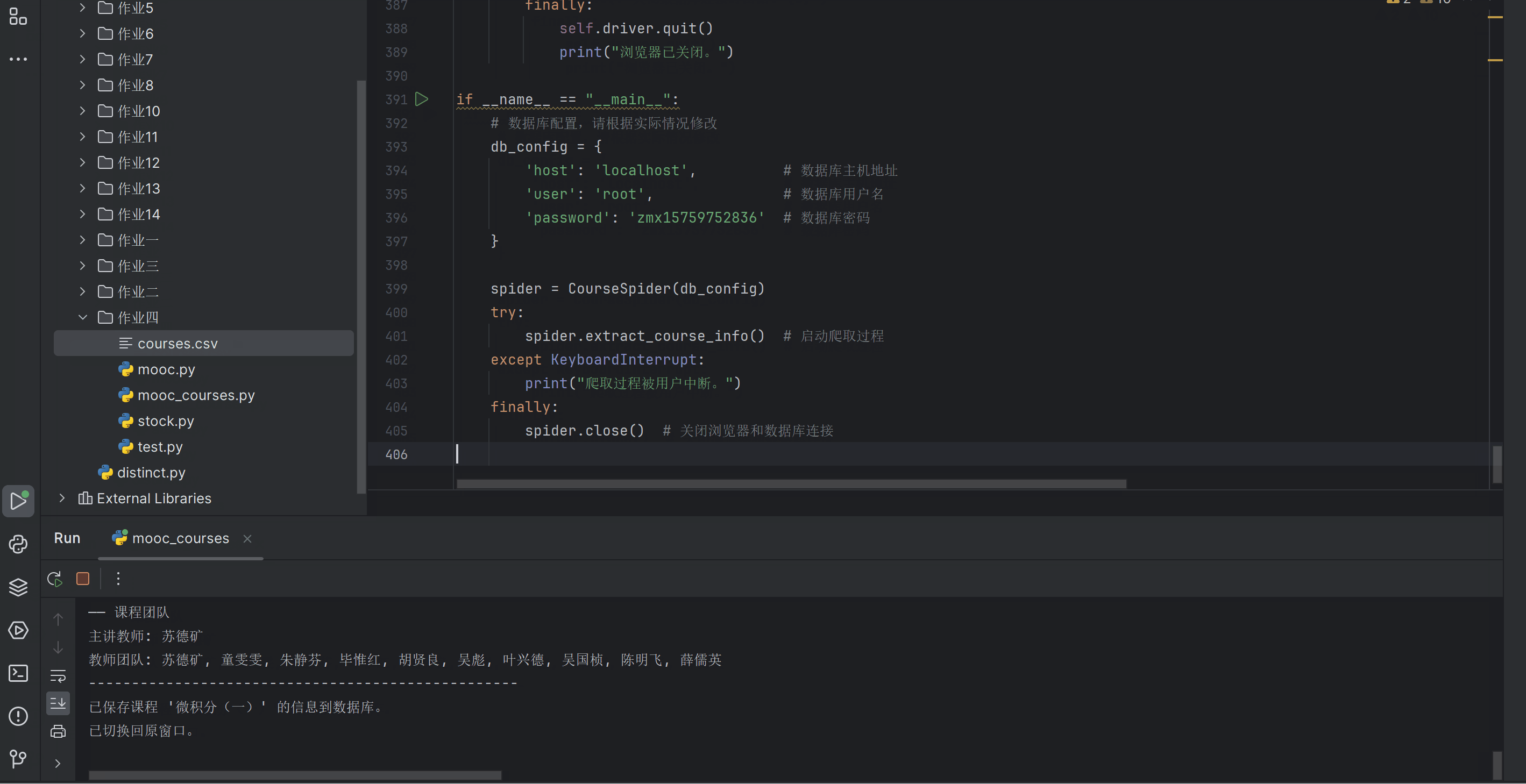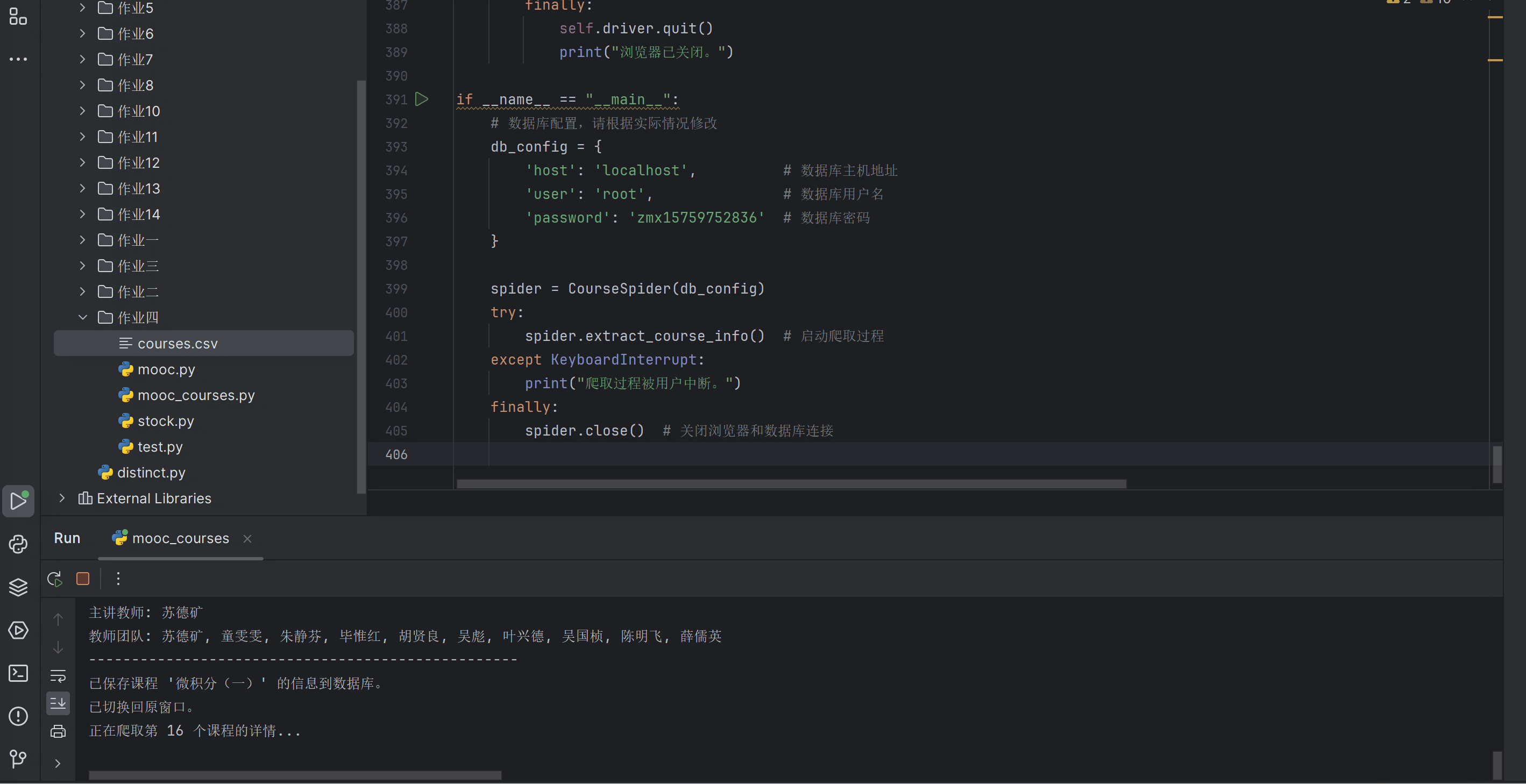
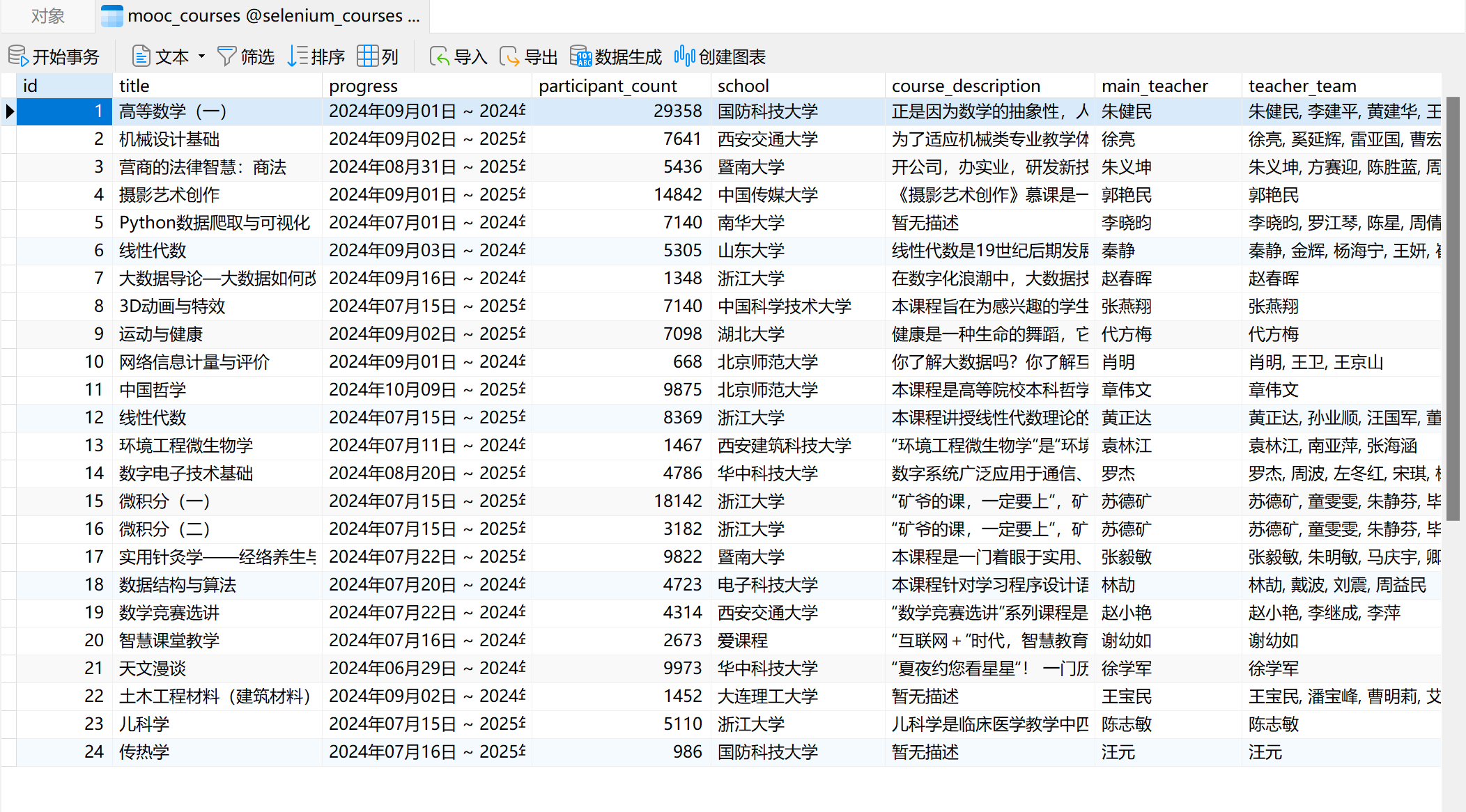
使用Selenium框架+MySQL爬取中国mooc网课程资源信息(课程号、课程名称、学校名称、主讲教师、团队成员、参加人数、课程进度、课程简介)
候选网站:中国mooc网:https://www.icourse163.org
输出信息:MYSQL数据库存储和输出格式
详细代码见gitee🔗:作业4-mooc_courses.py
实践说明
非常值得注意的是,这题一直在进行窗体的切换
switch_to_it
登录
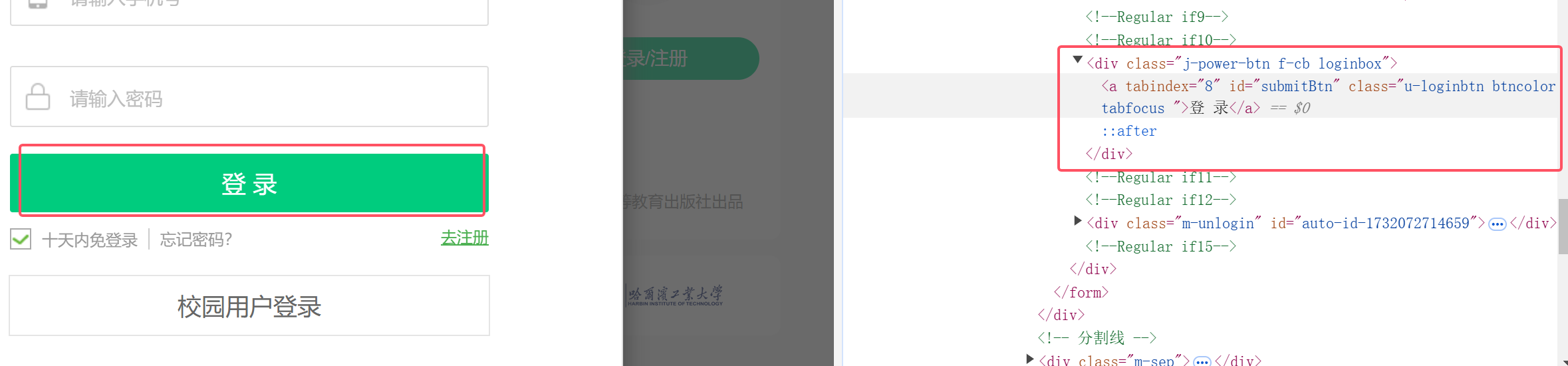
1.进行网页观察
点击这个网页上的登录/注册键
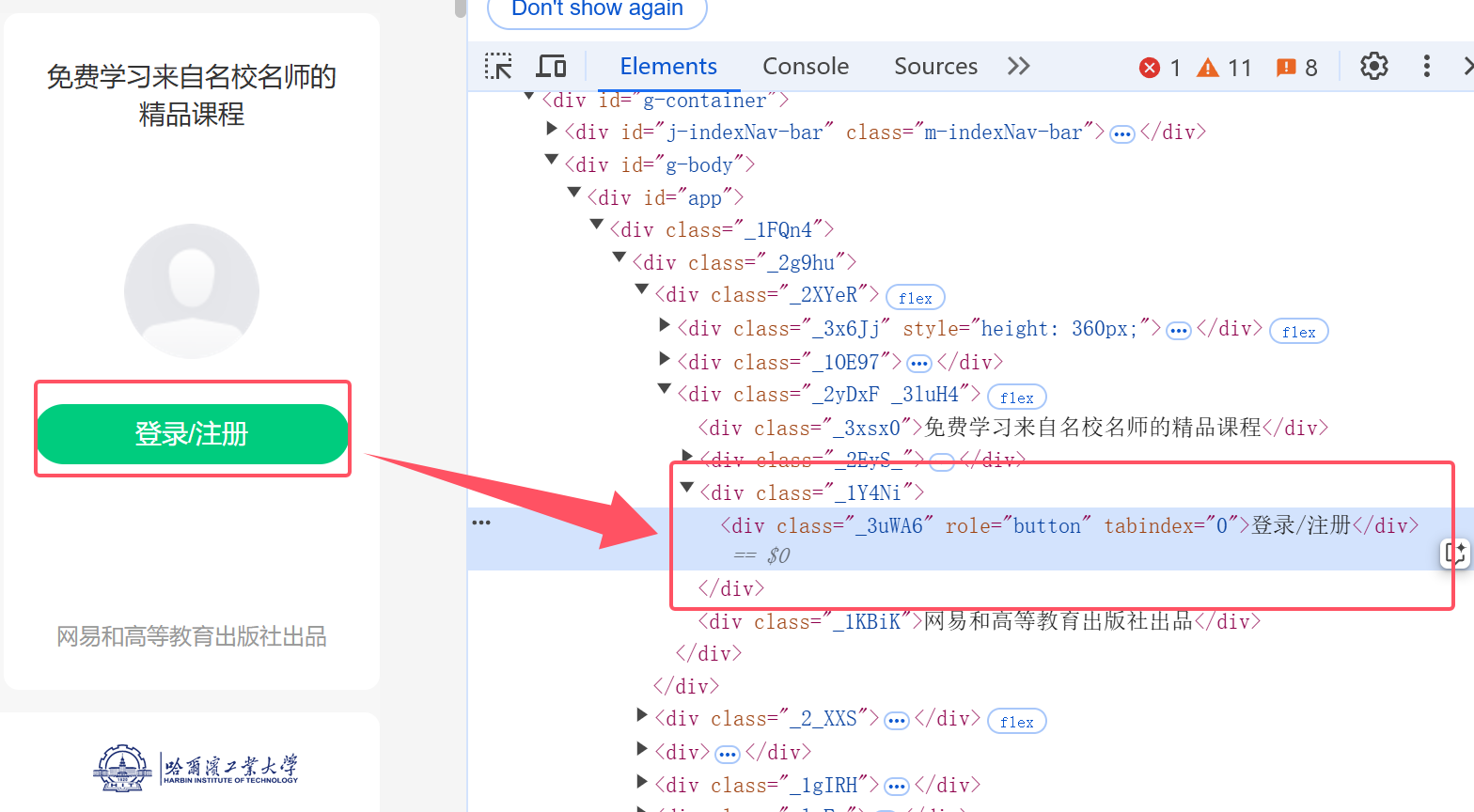
会出现登录操作弹窗,手机号与密码的输入框如下,都有id可以迅速抓取
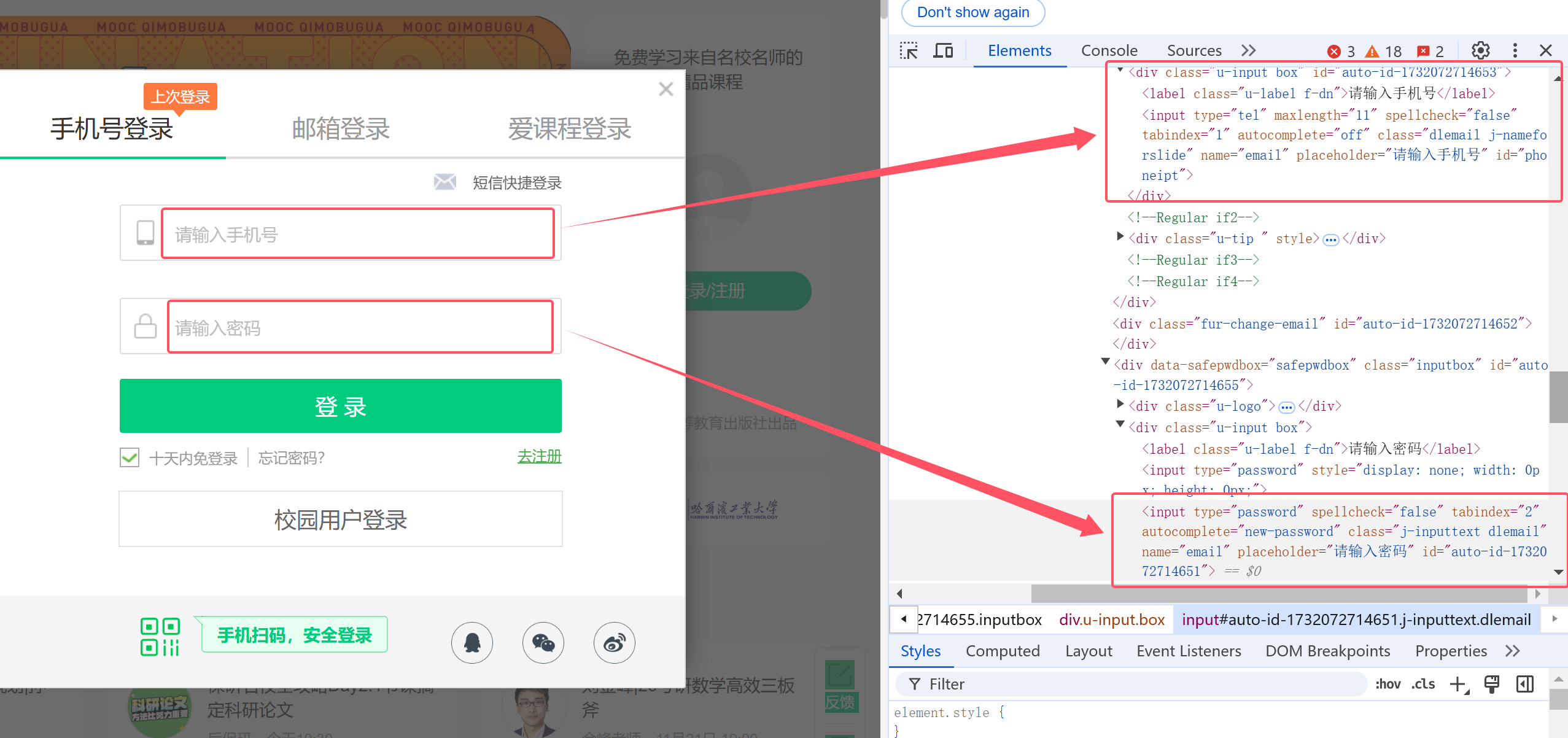
键入完毕再点击登录键就可以实现登录了
2.发现问题
Q:等下,但这样就行了吗?
A:我发现了上面那样定位什么都输入不了,浏览器超时为获取操作之后就关闭了
3.切换窗体实现登录

在老师的提醒下,发现登录输入框这些都是建立在iframe框架中的
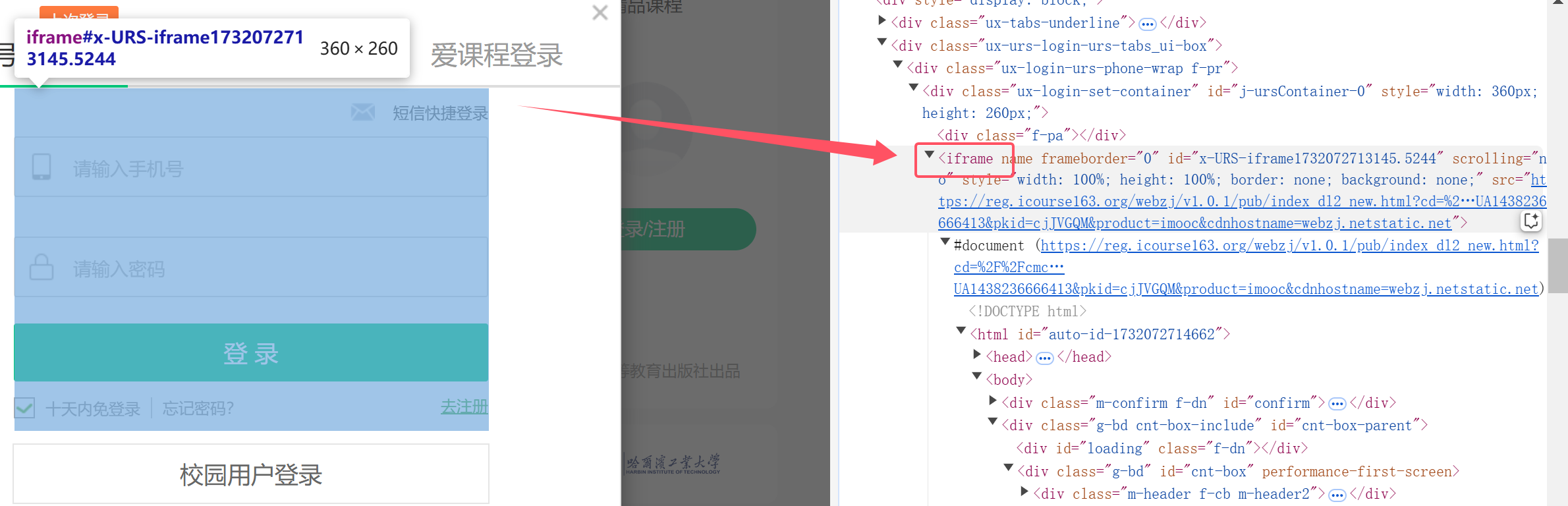
所以应该先把窗体切换到iframe处,再进行模拟用户键入账号密码的操作!
注意使用完还要切回原本的窗体
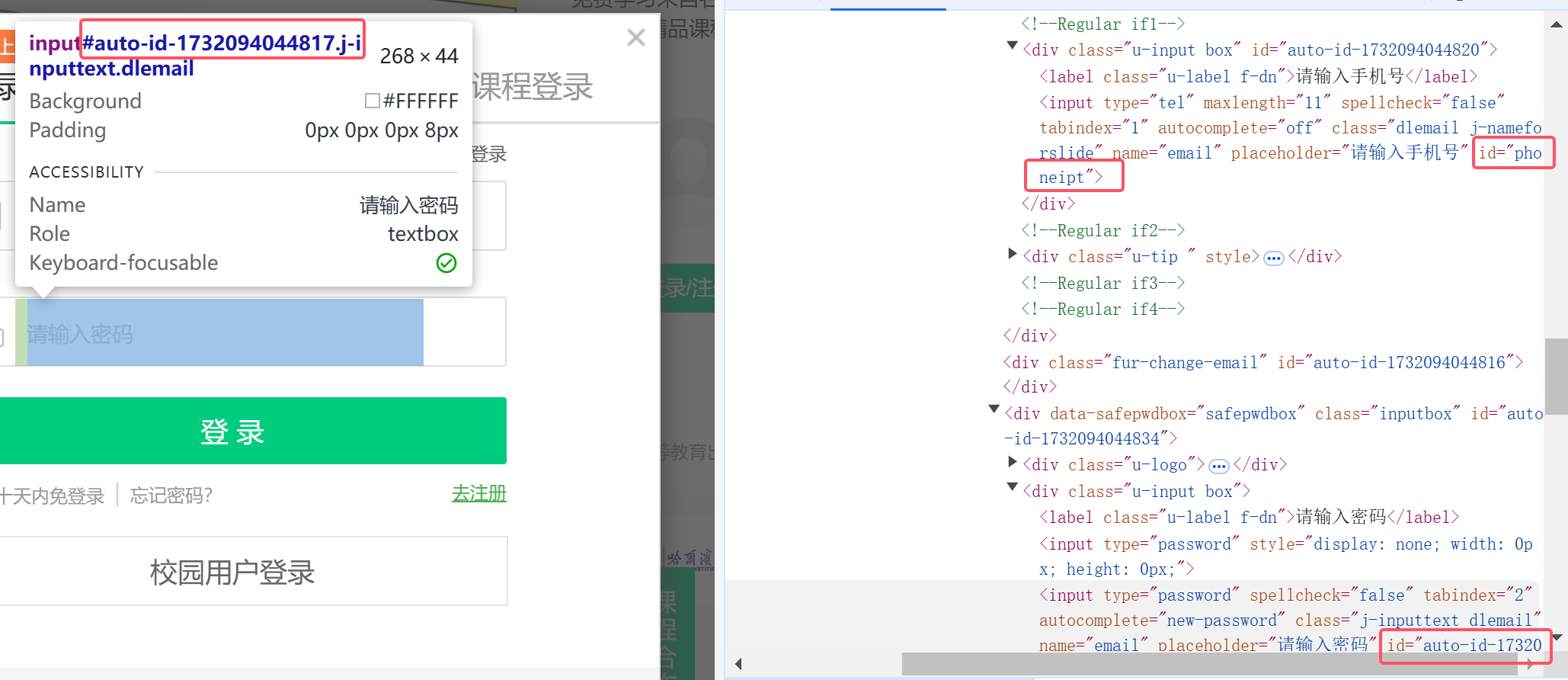
4.HTML元素查找问题
原本我是直接用find_element(By.ID, "")来实现手机号和密码输入框的定位的
但多次尝试发现,手机号输入得进去(手机号输入的id是固定的"phoneipt"),密码输入不进去。
我才反应过来密码输入框对应的auto_id值其实是动态变化的,所以不能以此查找元素。
这里采用了右键复制xpath获得了一个比较具体的路径来查找元素
5.汇总登录实现代码
# 模拟用户键入账号密码登录
def login(self):
try:
# 找到并点击登录/注册按钮
login_button = WebDriverWait(self.driver, 20).until(
EC.element_to_be_clickable((By.XPATH, '//div[@class="_3uWA6" and text()="登录/注册"]'))
)
login_button.click()
# 等待iframe加载并切换到它
WebDriverWait(self.driver, 10).until(
EC.frame_to_be_available_and_switch_to_it((By.TAG_NAME, 'iframe'))
)
# 在iframe中找到并填写手机号和密码
phone_input = WebDriverWait(self.driver, 10).until(
EC.visibility_of_element_located((By.ID, 'phoneipt'))
)
phone_input.send_keys("手机号已遮盖")
password_input = WebDriverWait(self.driver, 10).until(
EC.visibility_of_element_located((By.XPATH, \
'/html/body/div[2]/div[2]/div[2]/form/div/div[4]/div[2]/input[2]')) # 密码输入框
)
password_input.send_keys("密码已遮盖")
# 点击登录按钮
submit_button = self.driver.find_element(By.ID, 'submitBtn')
submit_button.click()
# 切回主文档
self.driver.switch_to.default_content()
print("登录成功。")
except TimeoutException:
print("登录相关元素未找到或无法点击。")
except Exception as e:
print(f"登录过程出错: {e}")
6.实现过程展示
先前我是采用扫码来登录的,没有那么多顾虑,甚至有点“逃课写法”,代码如下
def login(self):
# 模拟登录
try:
# 找到并点击 登录/注册 按钮(点击之后跳出输入弹窗)
login_button = WebDriverWait(self.driver, 20).until(
EC.element_to_be_clickable((By.XPATH, '//div[@class="_3uWA6" and text()="登录/注册"]'))
)
login_button.click()
# 等待扫码登录,这里可以通过time.sleep调整扫码等待时间
print("请扫码登录...")
time.sleep(30) # 根据需要调整扫码时间
print("登录成功。")
except TimeoutException:
print("登录按钮未找到或无法点击。")
except Exception as e:
print(f"登录过程出错: {e}")
课程数据爬取
1.先定位并获取所有课程
# 获取所有课程元素
courses = WebDriverWait(self.driver, 20).until(
EC.presence_of_all_elements_located((By.XPATH, "//div[@class='_15K5J']\
//div[contains(@class, 'commonCourseCardItem')]"))
)
print(f"找到 {len(courses)} 个课程。")
2.每个课程内容的爬取
作业要求的数据内容,不是单纯能在一个页面爬取的,比如像教师团队、课程简介等都需要点击进入课程详情页才能查找到对应的HTML元素
索性把所有数据的爬取都定位在进入详情页后
注意:有的课程没有简介,需要录入:暂无描述
def extract_course_details(self):
# 提取课程详情页面的信息
try:
# 等待课程标题元素出现
WebDriverWait(self.driver, 20).until(
EC.presence_of_element_located((By.XPATH, "//span[@class='course-title f-ib f-vam']"))
)
time.sleep(2) # 确保页面完全加载
# 课程标题
title = self.driver.find_element(By.XPATH, "//span[@class='course-title f-ib f-vam']").text
# 课程进度
progress = self.driver.find_element(By.XPATH,
"//div[contains(@class, 'course-enroll-info_course-info_term-info_term-time')]//span[2]").text
# 参加人数
participant_count_text = self.driver.find_element(By.XPATH, "//span[@class='count']").text
participant_count = int(''.join(filter(str.isdigit, participant_count_text)))
# 学校名称
school = self.driver.find_element(By.XPATH, "//img[@class='u-img']").get_attribute("alt")
# 课程描述
try:
course_description = self.driver.find_element(By.XPATH, "//div[@class='course-heading-intro']").text.strip()
if not course_description:
course_description = "暂无描述"
except NoSuchElementException:
course_description = "暂无描述"
# 教师团队(包括主讲教师)
teacher_elements = self.driver.find_elements(By.XPATH, "//h3[@class='f-fc3']")
teacher_team = []
main_teacher = "N/A"
if teacher_elements:
main_teacher = teacher_elements[0].text
teacher_team.extend([elem.text for elem in teacher_elements])
# 处理教师团队的分页
self.handle_teacher_pagination(teacher_team)
else:
teacher_team = ["N/A"]
# 打印课程详情
print(f"课程名称: {title}")
print(f"进度: {progress}")
print(f"参加人数: {participant_count}")
print(f"学校: {school}")
print(f"课程描述: {course_description}")
print(f"主讲教师: {main_teacher}")
print(f"教师团队: {', '.join(teacher_team)}")
print("-" * 50)
# 保存数据到数据库
self.process_item({
'title': title,
'progress': progress,
'participant_count': participant_count,
'school': school,
'course_description': course_description,
'main_teacher': main_teacher,
'teacher_team': ', '.join(teacher_team)
})
except (NoSuchElementException, TimeoutException) as e:
print(f"提取课程详情时出错: {e}")
except Exception as e:
print(f"提取课程详情时发生未知错误: {e}")
3.窗体切换爬取
值得注意的是,点击进入课程详情页面已经算是在新窗体了,但是selenium还是只会在原本的窗体查找课程元素,所以一开始一直失败
直到老师二次提示TT

def switch_new_window(self):
# 切换到新窗口
try:
WebDriverWait(self.driver, 10).until(
lambda d: len(d.window_handles) > 1
)
new_window = self.driver.window_handles[-1] # 获取所有窗口句柄,选择最新窗口(最后一个)
self.driver.switch_to.window(new_window) # 切换到该窗口
print("已切换到新窗口。")
except TimeoutException:
print("新窗口加载超时。")
except Exception as e:
print(f"切换到新窗口时出错: {e}")
def switch_origin_window(self):
# 切换回原窗口
try:
origin_window = self.driver.window_handles[0] # 获取第一个窗口句柄
self.driver.switch_to.window(origin_window) # 切换回原窗口
print("已切换回原窗口。")
except NoSuchElementException:
print("原窗口未找到。")
except Exception as e:
print(f"切换回原窗口时出错: {e}")
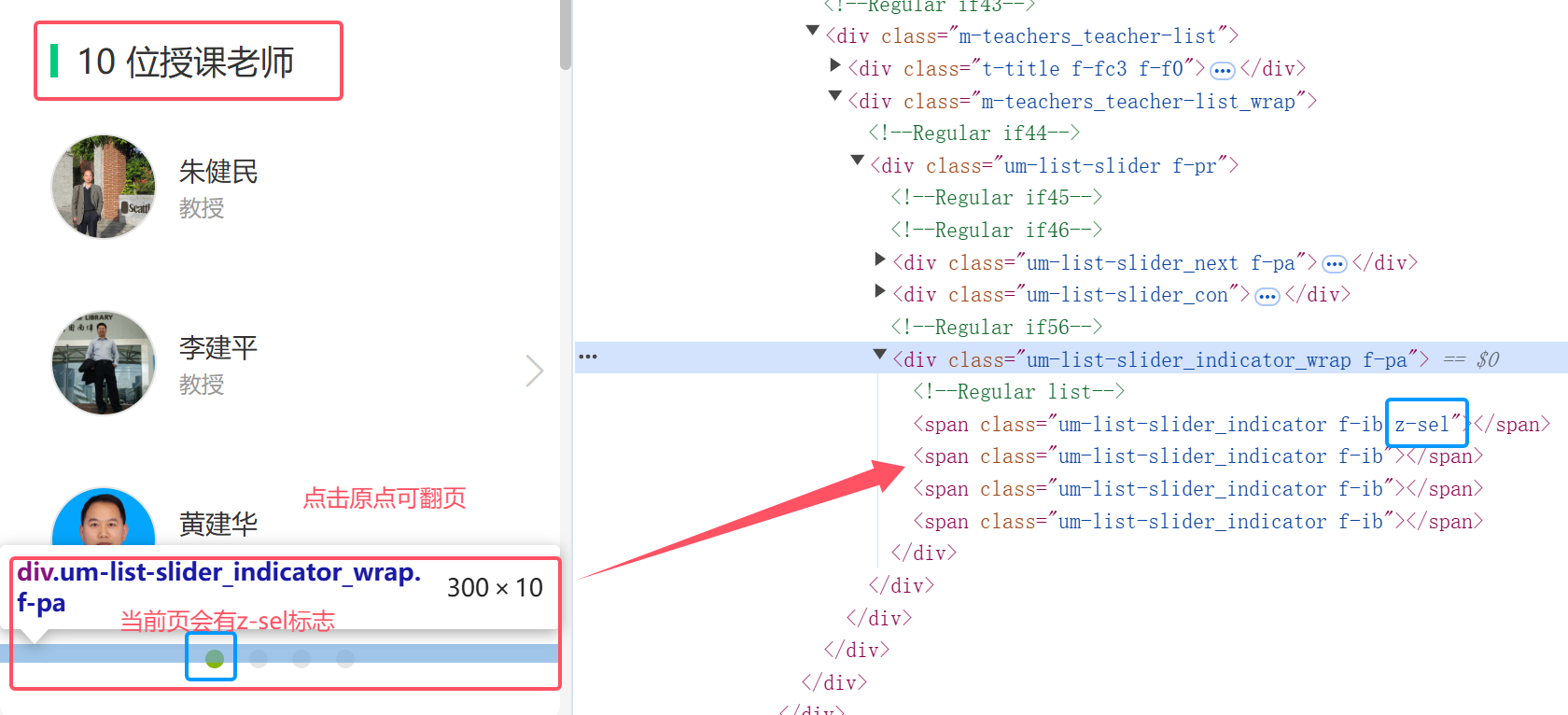
4.教师团队爬取
在上面的爬取流程逐渐明晰之后,又出现了一个新的问题:
有的课程涉及多页的教师参与(教师团队人数超过3个),所以要进行一个小翻页爬取了(循环实现)
教师团队爬取详细代码,比较长,点击可以展开查看详情
def handle_teacher_pagination(self, teacher_team):
# 处理教师团队的分页,累积所有教师信息
while True:
try:
# 找到所有教师分页指示器
page_spans = self.driver.find_elements(By.XPATH, "//div[contains(@class, 'um-list-slider_indicator_wrap')]/span[contains(@class, 'um-list-slider_indicator')]")
print(f"找到 {len(page_spans)} 个教师页面指示器。")
# 找到当前选中的教师页指示器
current_page_span = None
for span in page_spans:
classes = span.get_attribute("class").split()
if "z-sel" in classes:
current_page_span = span
break
if not current_page_span:
print("当前教师页指示器未找到,无法进行翻页。")
break
# 获取当前教师页的索引
current_index = page_spans.index(current_page_span)
print(f"当前教师页索引为: {current_index + 1}")
# 判断是否有下一个教师页面
if current_index + 1 < len(page_spans):
next_page_span = page_spans[current_index + 1]
print("找到教师下一页指示器,准备点击。")
# 滚动到“下一页”按钮
self.driver.execute_script("arguments[0].scrollIntoView({block: 'center'});", next_page_span)
time.sleep(1) # 确保滚动完成
# 点击下一页
try:
next_page_span.click()
print("点击了教师下一页,继续爬取...")
time.sleep(3) # 等待教师列表加载
# 获取新的教师元素
new_teacher_elements = self.driver.find_elements(By.XPATH, "//h3[@class='f-fc3']")
new_teachers = [elem.text for elem in new_teacher_elements if elem.text not in teacher_team]
if new_teachers:
teacher_team.extend(new_teachers)
print(f"累积了 {len(new_teachers)} 个新的教师。")
else:
print("没有找到新的教师信息,停止翻页。")
break
except Exception as e:
print(f"点击教师下一页时出错: {e}")
# 使用 Selenium 重试点击
try:
print("尝试再次点击教师下一页。")
next_page_span.click()
print("再次点击教师下一页成功。")
time.sleep(3)
# 获取新的教师元素
new_teacher_elements = self.driver.find_elements(By.XPATH, "//h3[@class='f-fc3']")
new_teachers = [elem.text for elem in new_teacher_elements if elem.text not in teacher_team]
if new_teachers:
teacher_team.extend(new_teachers)
print(f"累积了 {len(new_teachers)} 个新的教师。")
else:
print("没有找到新的教师信息,停止翻页。")
break
except Exception as e_inner:
print(f"重试点击教师下一页时出错: {e_inner}")
# 预留时间让用户手动翻页
print("无法通过 Selenium 自动点击教师下一页,请手动翻页。")
input("请手动翻页后,按回车键继续...")
# 重新获取教师元素
new_teacher_elements = self.driver.find_elements(By.XPATH, "//h3[@class='f-fc3']")
new_teachers = [elem.text for elem in new_teacher_elements if elem.text not in teacher_team]
if new_teachers:
teacher_team.extend(new_teachers)
print(f"累积了 {len(new_teachers)} 个新的教师。")
else:
print("没有找到新的教师信息,停止翻页。")
break
else:
print("已经是最后一页教师列表,停止翻页。")
break
except NoSuchElementException:
print("教师分页指示器未找到,可能没有分页。")
break
except Exception as e:
print(f"处理教师分页时出错: {e}")
break
5.爬虫流程阐释
实际上爬取每个课程都要经历如下过程:
点击进入课程详情页->切换到新窗口->爬取课程信息->关闭并返回原窗口
for index, course in enumerate(courses, start=1):
try:
# 滚动到课程元素,确保元素可见
self.driver.execute_script("arguments[0].scrollIntoView({block: 'center'});", course)
time.sleep(1) # 稍作等待,确保滚动完成
# 点击进入每个课程的详情页
course_details_button = course.find_element(By.CLASS_NAME, "_3KiL7")
course_details_button.click()
print(f"正在爬取第 {index} 个课程的详情...")
time.sleep(5) # 增加延时,等待详情页加载
# 切换到新窗口
self.switch_new_window()
# 提取详细课程信息
self.extract_course_details()
# 关闭详情页窗口
self.driver.close()
# 切换回原窗口
self.switch_origin_window()
# 等待页面加载完成
time.sleep(3)
except (NoSuchElementException, TimeoutException, ElementClickInterceptedException, StaleElementReferenceException) as e:
print(f"爬取第 {index} 个课程详情时出错: {e}")
# 尝试关闭可能打开的窗口并切换回原窗口
if len(self.driver.window_handles) > 1:
self.driver.close()
self.switch_origin_window()
continue # 跳过当前课程,继续下一个
6.爬虫过程gif展示
实践结果
实践心得
这题在发现窗体的切换前,我是认为,只要我点击进入详情页,再在详情页里点击“首页”返回就行了,但是这样也什么也爬不出来。
直到老师提醒,我加入了窗体的切换开始有数据爬下来了,但是还会出现一个问题,就是教师团队的翻页爬取怎么样都没有反应。
后面我才发现我,我的代码逻辑有问题,把翻页切到了课程爬取那边,但其实国家精品课程就24个,都在一个板块里,根本不用翻页,是我把翻页写岔了。
修正以上问题的同时,发现教师处的翻页不仅可以点翻页按钮,也可用下面的小圆点,进行index计数翻页处理,更具有稳健性。
最后修改的代码就同gitee上一样了。
但后续我还是决定修改一下登录操作逻辑,不要采用扫码这种比较逃课的方法,让整个页面爬取更加自动化一点,也是在定位输入框iframe的研究上花费了一定时间。
作业③
要求:
掌握大数据相关服务,熟悉Xshell的使用
完成文档 华为云_大数据实时分析处理实验手册-Flume日志采集实验(部分)v2.docx 中的任务,即为下面5个任务,具体操作见文档。
环境搭建:
任务一:开通MapReduce服务
实时分析开发实战:
任务一:Python脚本生成测试数据
任务二:配置Kafka
任务三: 安装Flume客户端
任务四:配置Flume采集数据
输出:实验关键步骤或结果截图。
实践说明
这里都是用putty实现远程连接,没有使用Xshell
Python脚本生成测试数据
1.登录MRS的master节点服务器
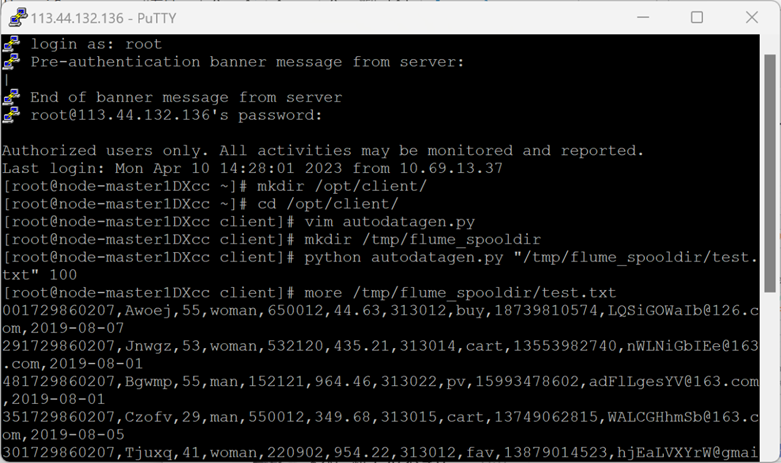
2.编写python脚本
进入/opt/client/目录,使用vi命令编写Python脚本:autodatagen.py
3.创建存放测试数据的目录
使用mkdir命令在/tmp下创建目录flume_spooldir,我们把Python脚本模拟生成的数据放到此目录下,后面Flume就监控这个文件下的目录,以读取数据。
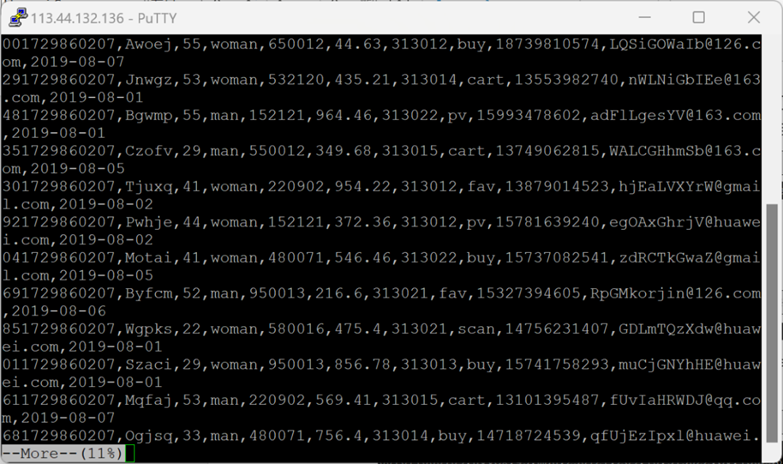
4.执行脚本测试,生成100条数据
More命令查看
以上四步截图如下
配置Kafka
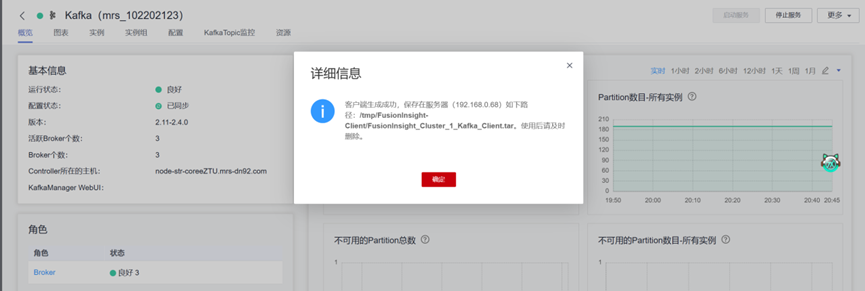
1.进入MRS Manager集群管理
2.在MRS Manager集群管理界面下载Kafka
3.校验下载的客户端文件包
4.安装Kafka运行环境,执行命令配置环境变量
5.安装Kafka客户端
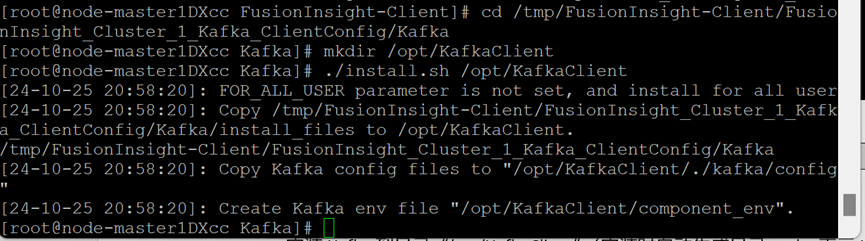
客户端运行环境安装成功
6.设置环境变量
使用Putty登录MRS的master节点服务器后,首先使用source命令进行环境变量的设置使得相关命令可用
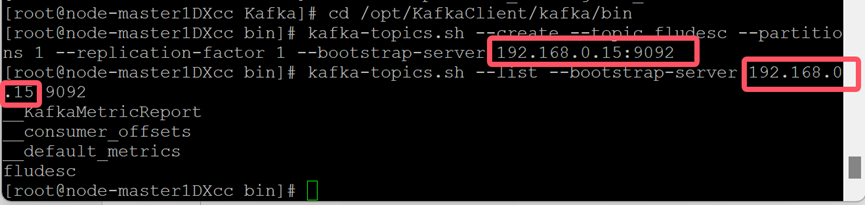
7.在kafka中创建topic并查看topic信息
获取kafka的IP:
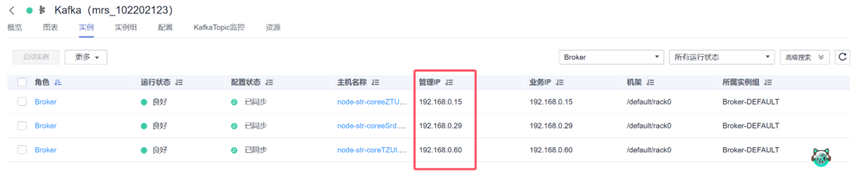
选择:192.168.0.15
安装Flume客户端
1.进入MRS Manager集群管理
2.下载Flume客户端
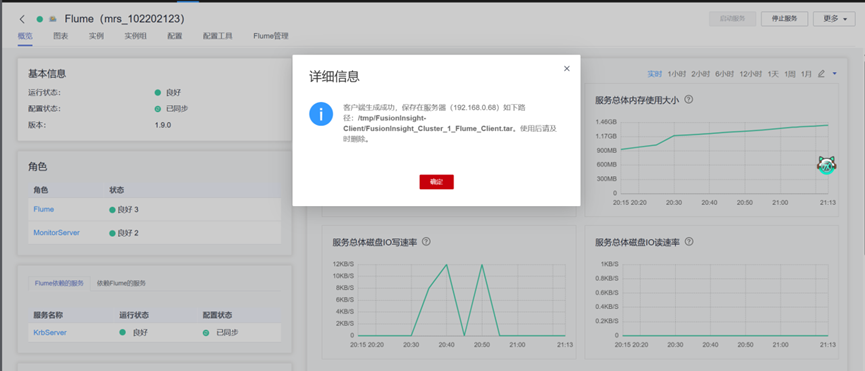
3.校验下载的客户端文件包
4.安装Flume运行环境
执行命令配置环境变量
5.安装Flume客户端
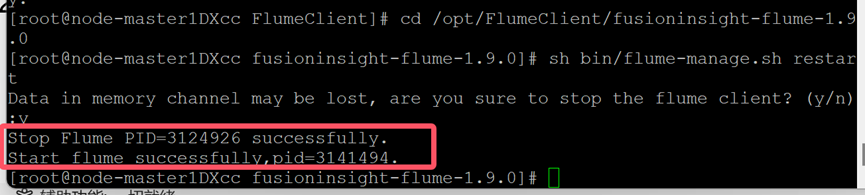
6.重启Flume服务
配置Flume采集数据
1.修改配置文件
添加内容如下
client.sources = s1
client.channels = c1
client.sinks = sh1
# the source configuration of s1
client.sources.s1.type = spooldir
client.sources.s1.spoolDir = /tmp/flume_spooldir
client.sources.s1.fileSuffix = .COMPLETED
client.sources.s1.deletePolicy = never
client.sources.s1.trackerDir = .flumespool
client.sources.s1.ignorePattern = ^(.)*\\.tmp$
client.sources.s1.batchSize = 1000
client.sources.s1.inputCharset = UTF-8
client.sources.s1.deserializer = LINE
client.sources.s1.selector.type = replicating
client.sources.s1.fileHeaderKey = file
client.sources.s1.fileHeader = false
client.sources.s1.basenameHeader = true
client.sources.s1.basenameHeaderKey = basename
client.sources.s1.deserializer.maxBatchLine = 1
client.sources.s1.deserializer.maxLineLength = 2048
client.sources.s1.channels = c1
# the channel configuration of c1
client.channels.c1.type = memory
client.channels.c1.capacity = 10000
client.channels.c1.transactionCapacity = 1000
client.channels.c1.channlefullcount = 10
client.channels.c1.keep-alive = 3
client.channels.c1.byteCapacityBufferPercentage = 20
# the sink configuration of sh1
client.sinks.sh1.type = org.apache.flume.sink.kafka.KafkaSink
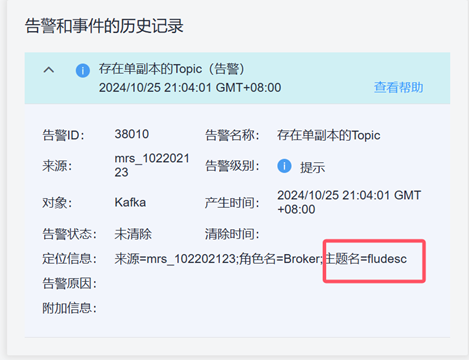
client.sinks.sh1.kafka.topic = fludesc
client.sinks.sh1.flumeBatchSize = 1000
client.sinks.sh1.kafka.producer.type = sync
client.sinks.sh1.kafka.bootstrap.servers = 192.168.0.15:9092
client.sinks.sh1.kafka.security.protocol = PLAINTEXT
client.sinks.sh1.requiredAcks = 0
client.sinks.sh1.channel = c1
其中client.sinks.sh1.kafka.topic确认:
2.创建消费者消费kafka中的数据
Duplicate session打开一个新的会话窗口
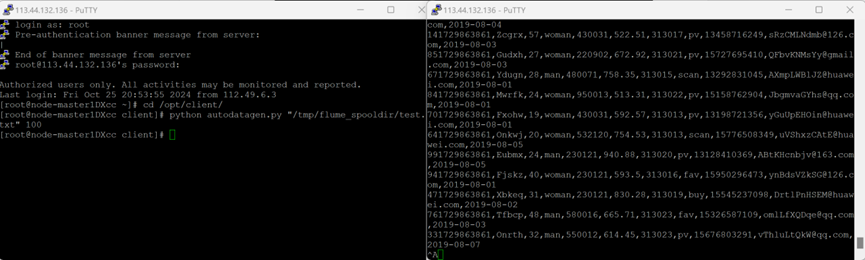
表明Flume到Kafka目前是打通的
测试完毕,在新打开的窗口输入exit关闭窗口,在原窗口输入 Ctrl+c退出进程
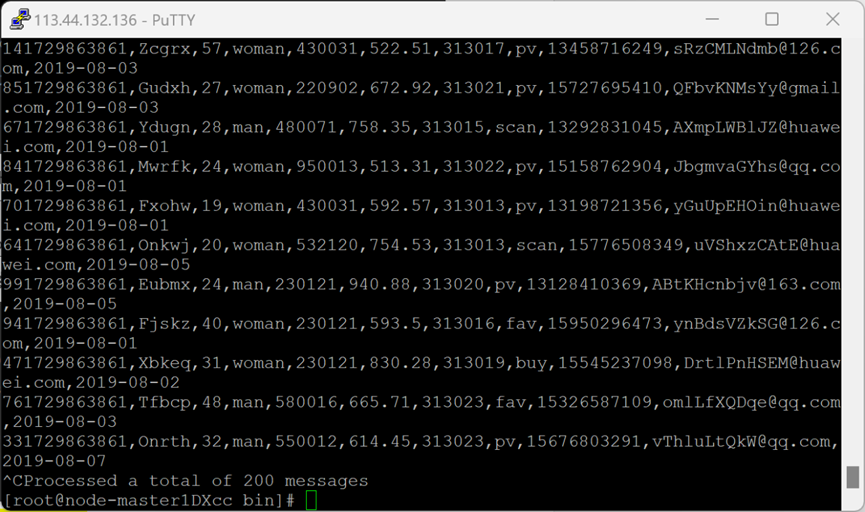
实践心得
通过编写Python脚本模拟实时销售数据,我感受到了数据生成的灵活性和重要性。这些数据是后续分析的基础,其质量和准确性直接关系到分析结果的可靠性。Flume和Kafka的组合则展示了数据采集的高效与稳定,它们能够轻松应对大量数据的实时传输,确保了数据的及时性和完整性。
