数据采集作业2
| 这个作业属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 这个作业要求在哪里 | 作业2 |
| 这个作业的目标 | 1.爬虫设计 2.爬取数据存入数据库 3.F12调试模式抓包学习 |
| 学号 | 102202123 |
Gitee🔗:作业2
作业整体思路:
代码编写分为两大类:
- 数据库定义类(SQLite数据库)
- openDB
- closeDB
- insert
- show
- 数据爬取类(request、bs4/re)
- 下载
- 解析,获取需要内容
- 插入数据库(insert)
- process(主控制方法:1.获取用户输入的页码范围 2.初始化数据库 3.调用爬取方法 4.展示数据 5.关闭数据库)
作业①
题目
要求:在中国气象网给定城市集的7日天气预报,并保存在数据库。
输出信息:城市、日期、天气、温度
爬取网站地址🔗:中国气象网
详细代码见gitee🔗:作业2-实验2.1
实践过程
数据库定义
以下三题都使用了数据库定义,方便后续将爬取数据存入数据库。
博客里仅在此解释数据库定义的思路,后续不再赘述。
1.openDB(self)——打开/创建数据库
- 建立连接
sqlite3.connect() - 创建游标
self.con.cursor() - 创建表(存在即删除表)
self.cursor.execute(...)(create/delete语句)
2.closeDB(self)——关闭数据库
- 提交当前事务(增删改查)
self.con.commit() - 关闭连接
self.con.close()
3.insert(self,data)——插入数据库
- 插入
self.cursor.execute(...)(insert语句)
4.show(self)——打印数据库内容
- 查询数据库
self.cursor.execute(...)(select查询语句) - 逐行遍历数据库内容生成列表
self.cursor.fetchall() - 遍历列表打印
分析url
以福州为例:
观察得到url上带有城市编码
url = "http://www.weather.com.cn/weather/" + self.cityCode[city] + ".shtml"

爬虫类初始化时不仅定义请求头headers,而且以键值对形式定义了想要爬取的城市及其对应编码的字典cityCode
def __init__(self):
self.headers = {
"User-Agent": "Mozilla/5.0"}
self.cityCode = {"福州": "101230101", "泉州": "101230501", "厦门": "101230201", "漳州": "101230601"}
网页解析
所需信息为ul节点下的所有li节点元素
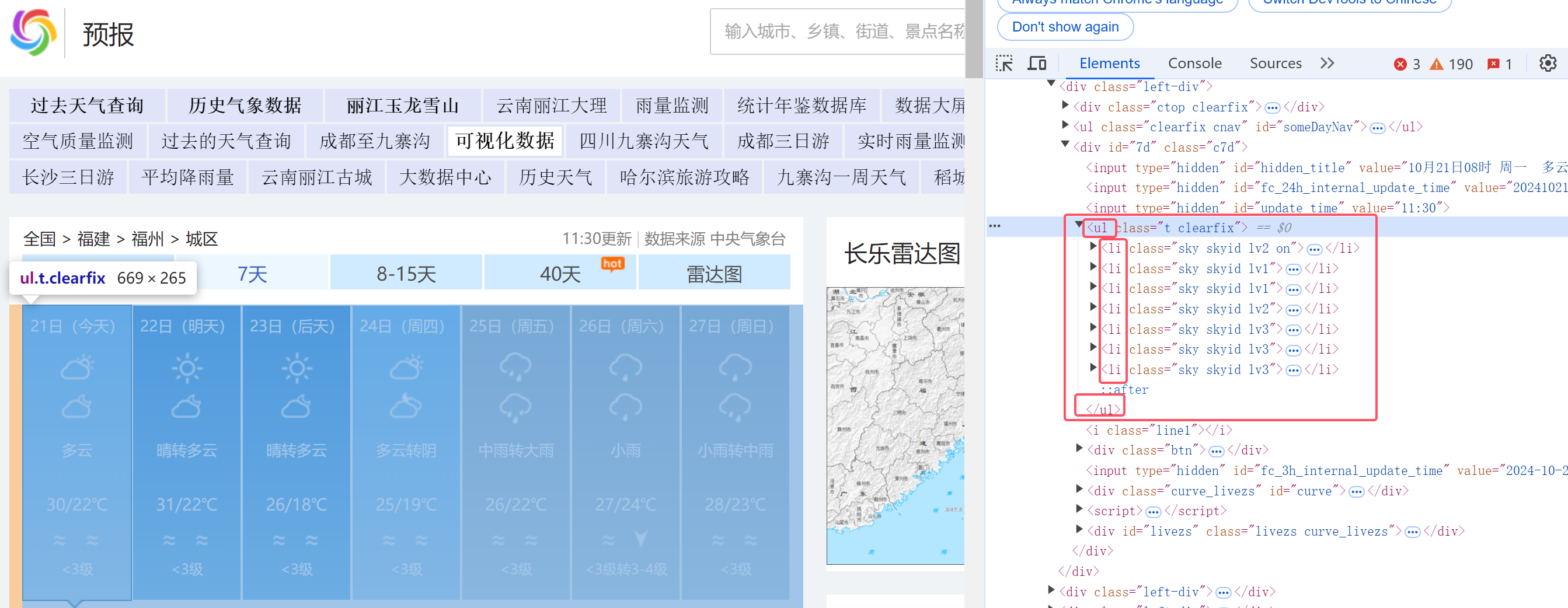
req = urllib.request.Request(url, headers=self.headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"]) # 传入数据和可能的编码列表,以便尝试解码
data = dammit.unicode_markup # 使用检测到的编码解码数据
soup = BeautifulSoup(data, "lxml")
# 选择类名为't clearfix'的ul元素下的所有li元素
lis = soup.select("ul[class='t clearfix'] li")
继续观察,得到日期、天气、温度内容对应的位置如下:
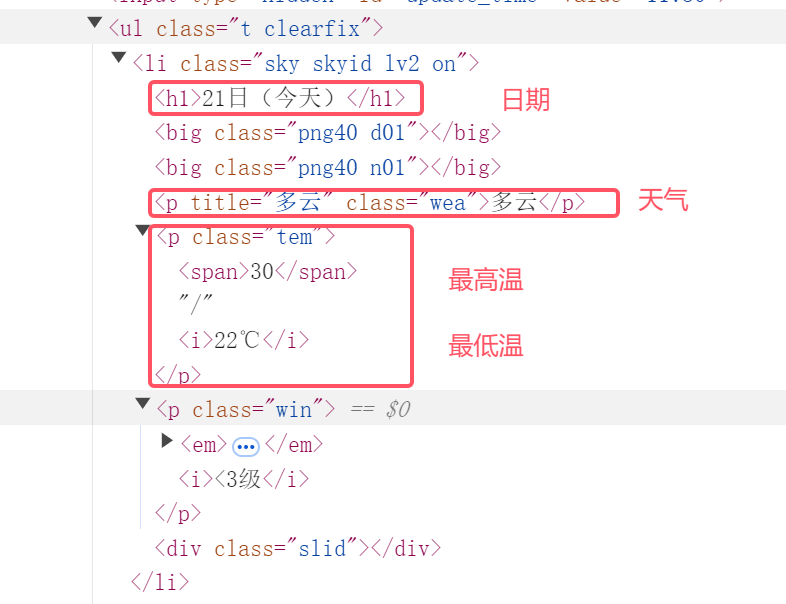
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
实践结果
存入数据库结果打印输出:

实践心得
通过本次实验,我更加熟悉了数据库的操作与应用。同时我再一次巩固了网页数据爬取,在这里还注意到了html文件下载编码的问题。
作业②
题目
要求:用requests和BeautifulSoup库方法定向爬取股票相关信息,并存储在数据库中。
候选网站:东方财富网、新浪股票
技巧:在谷歌浏览器中进入F12调试模式进行抓包,查找股票列表加载使用的url,并分析api返回的值,并根据所要求的参数可适当更改api的请求参数。根据URL可观察请求的参数f1、f2可获取不同的数值,根据情况可删减请求的参数。
参考链接:https://zhuanlan.zhihu.com/p/50099084
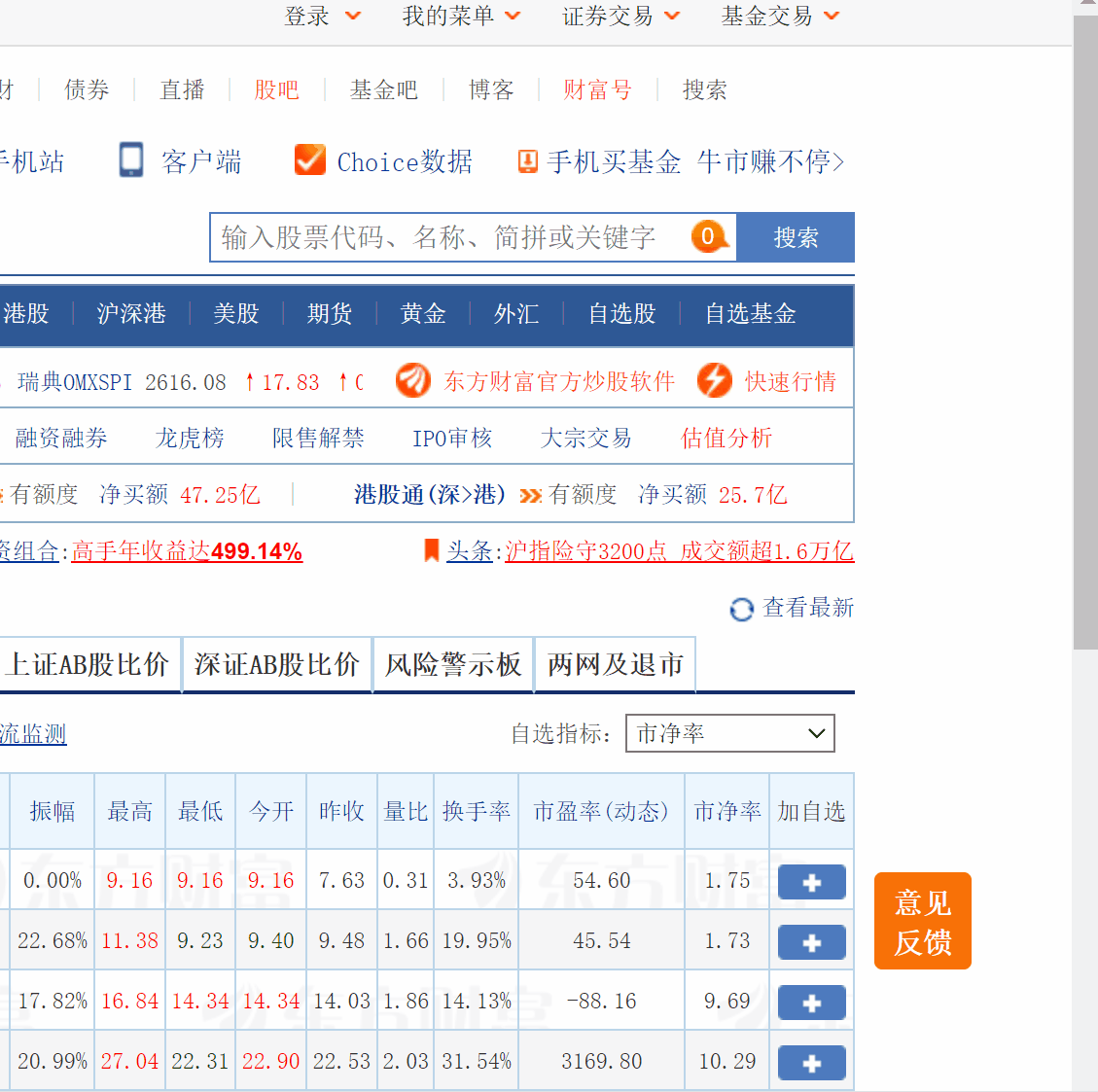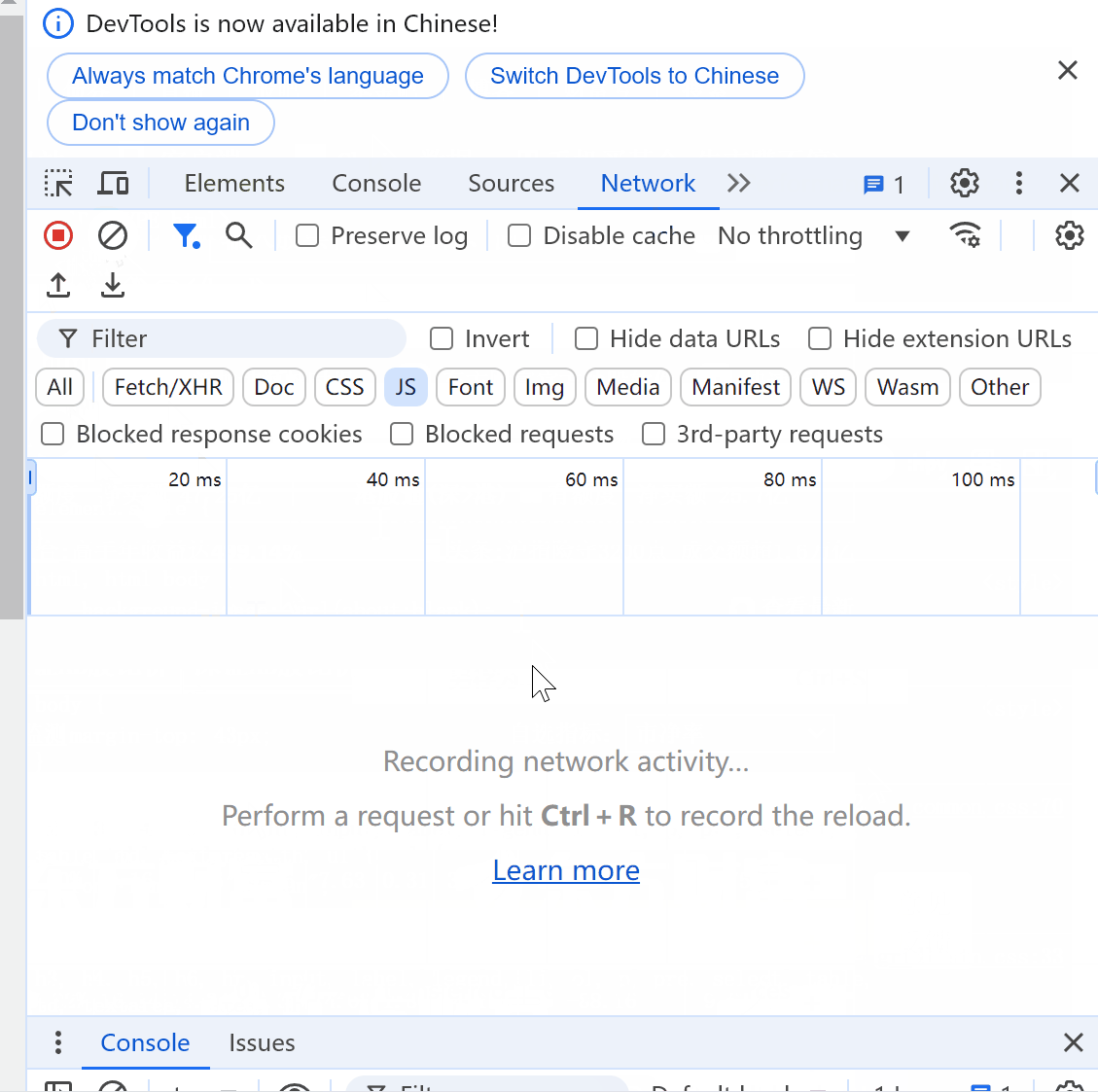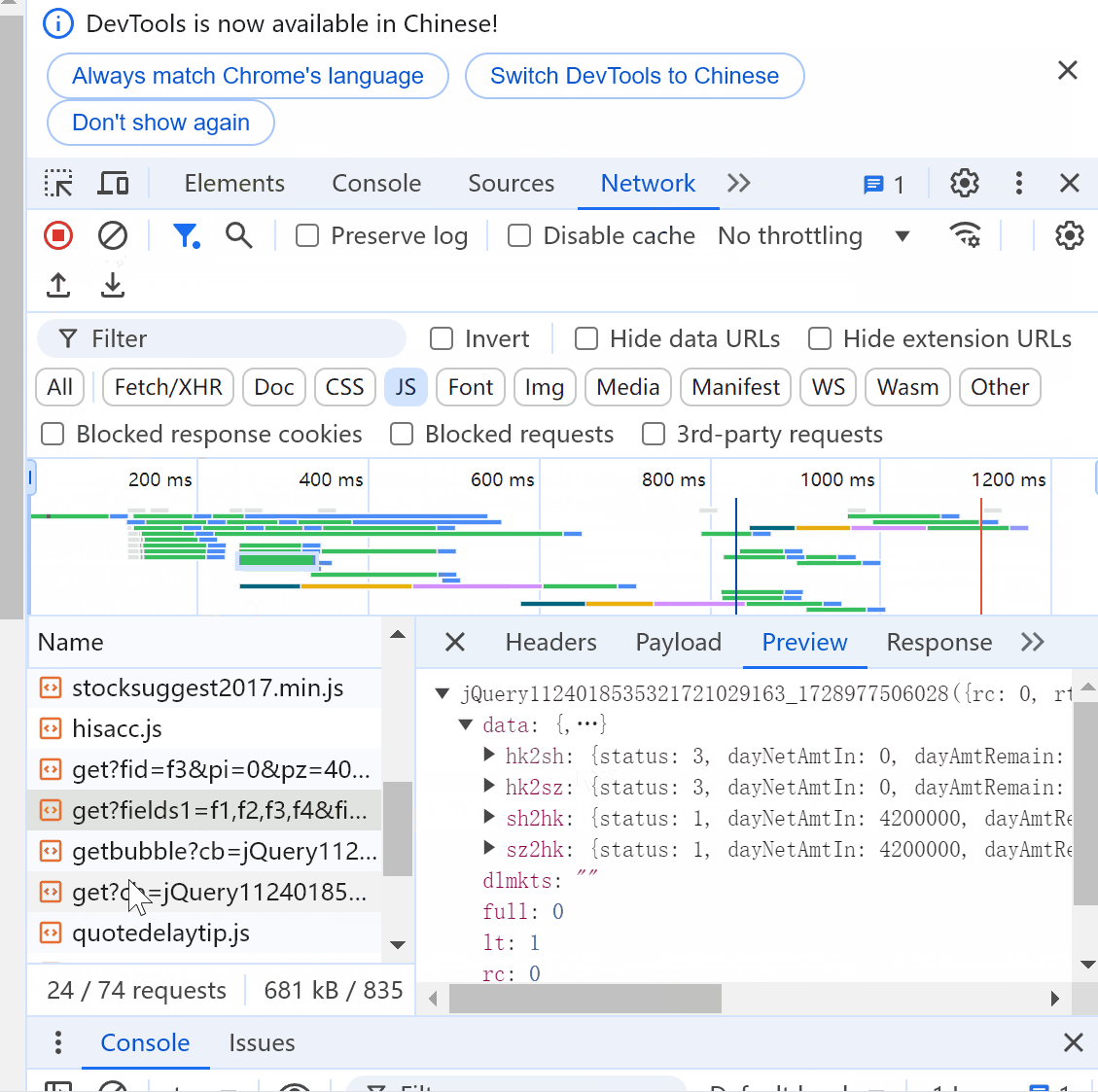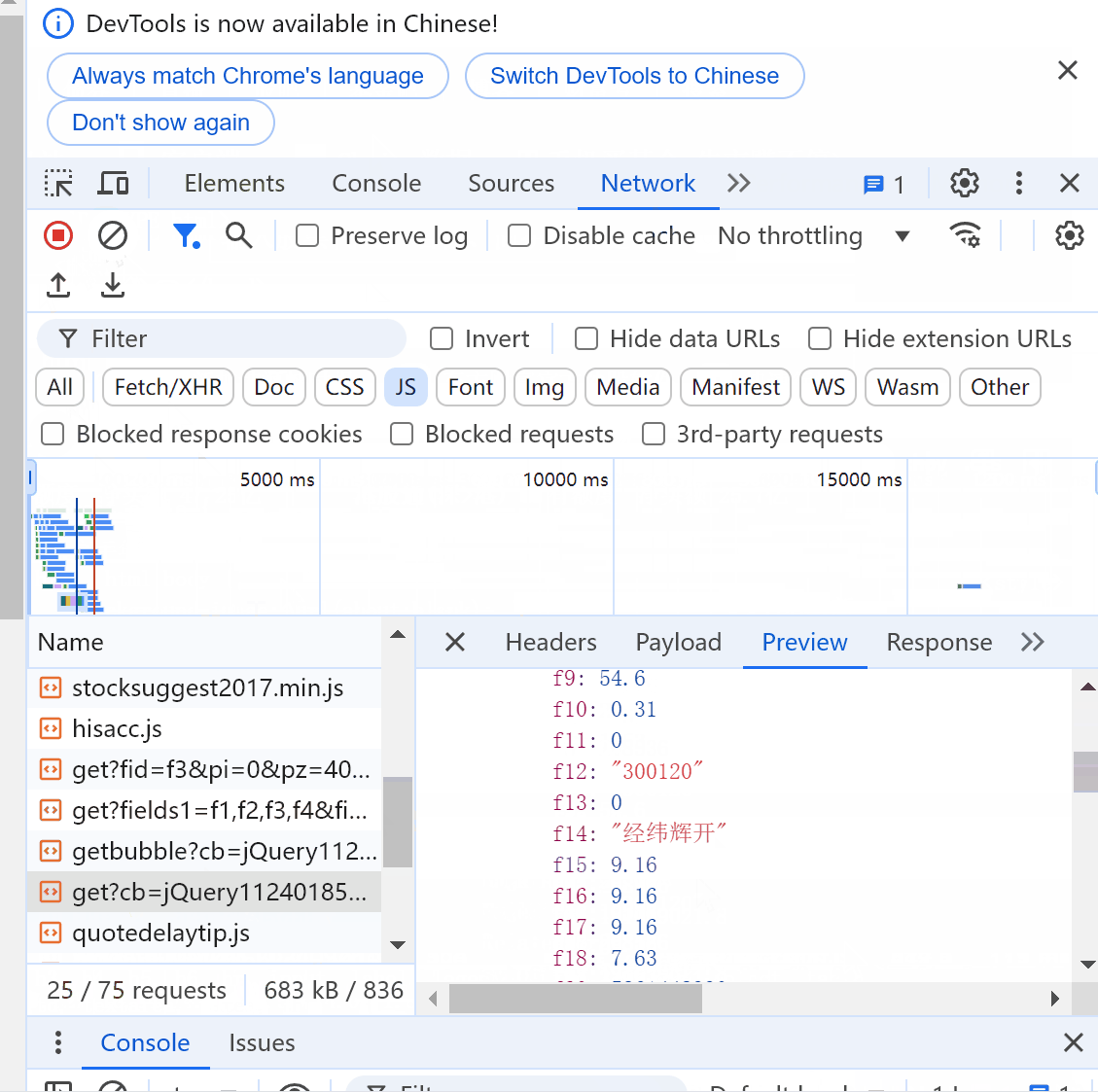
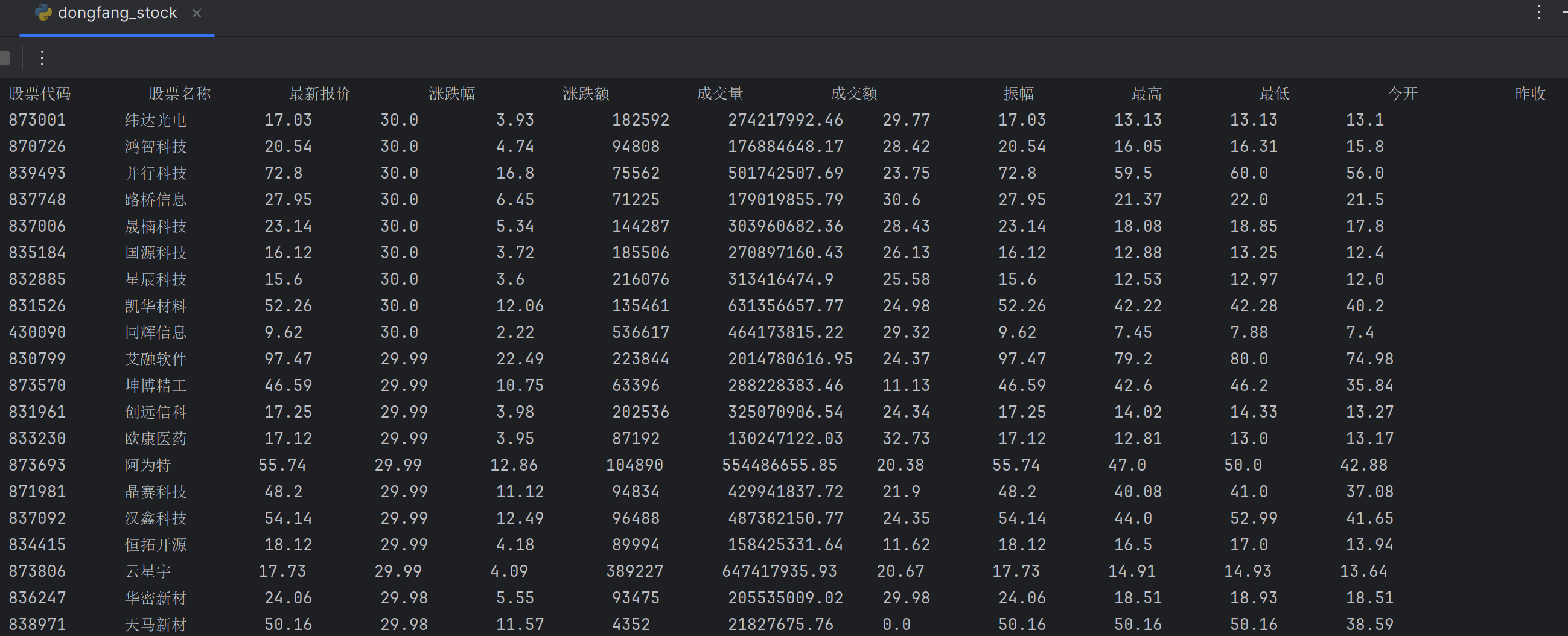
输出信息:股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收
爬取网站地址🔗:东方财富网-行情中心
详细代码见gitee🔗:作业2-实验2.2
实践过程
抓包过程
右键->检查->Network->JS->clear network log->ctrl R->找到抓包信息所在文件(get?cb=jQuery...)
找到目标文件后,点击Headers查看请求url
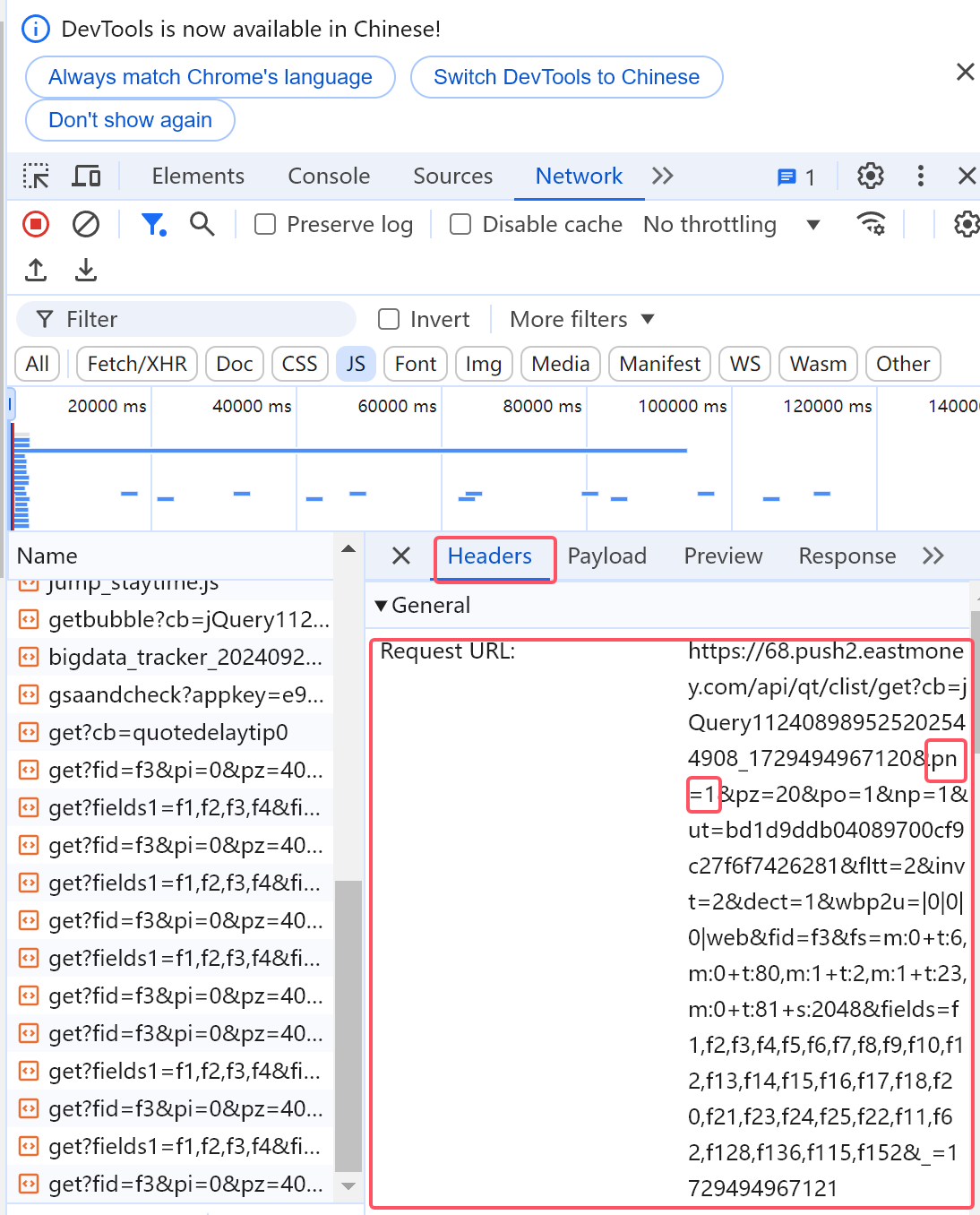
翻页改变:
第一页:
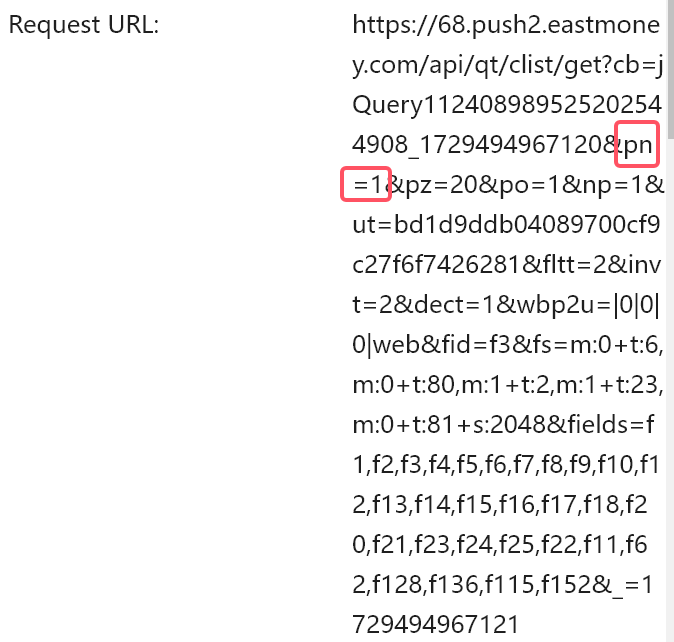
第二页:
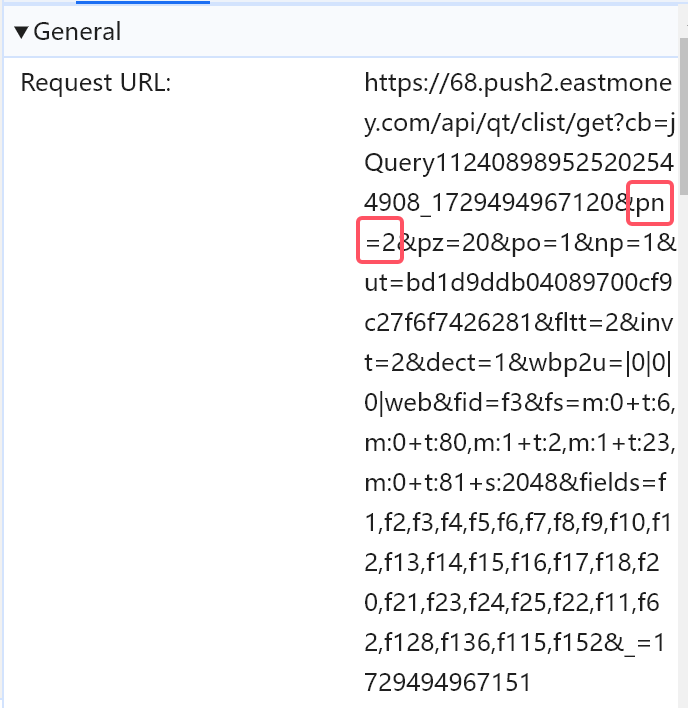
观察得到pn={page}
解析网页
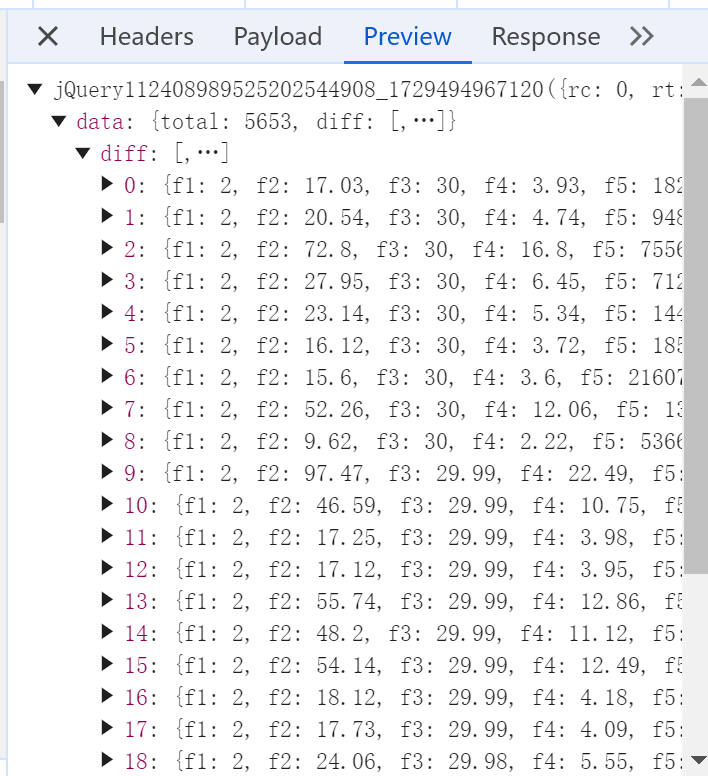
- 其中需要爬取的内容在被jQuery...()方法包着的字典里
- 字典中又嵌套字典
- 一层:关于键
data的值——一个字典 - 二层:上述字典里,关于键
diff的值——一个列表
- 一层:关于键
- 列表里面每个元素又是一个字典,每个字典代表一条股票信息
- 股票信息的每个具体内容(值)都有一个名为
f(num)的键对应
继续观察得到股票代码 股票名称 最新报价 涨跌幅 涨跌额 成交量 成交额 振幅 最高 最低 今开 昨收内容对应的位置如下:
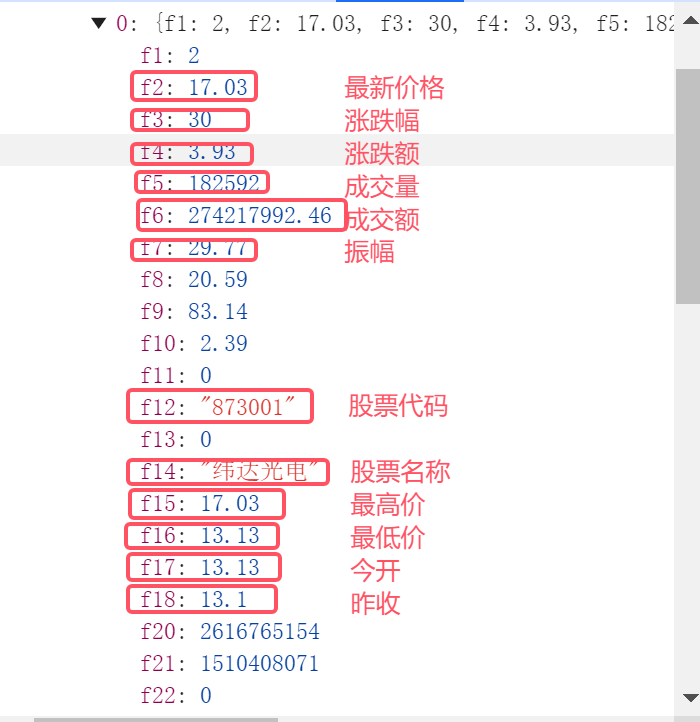
爬取网页,获取需要内容下载为json格式,并把行行情信息内容转化为列表,方便后续遍历获取
def get_stock_data(self, url):
response = requests.get(url)
if response.status_code == 200:
try:
# 正如解析网页得到,需要爬取的内容在被jQuery...()方法包着的字典里
json_start = response.text.find('(') + 1 # 标记开头
json_end = response.text.rfind(')') # 标记结尾
json_str = response.text[json_start:json_end] # 以标记位置提取字符串
data_json = json.loads(json_str) # 转换为json文件
return data_json.get('data', {}).get('diff', []) # 进一步提取行情信息内容为列表并返回
except (ValueError, KeyError) as e:
print("JSON 数据解析失败。", e)
return []
else:
print(f"请求失败,状态码: {response.status_code}")
return []
循环逐页爬取需要的信息,遍历列表stocks,以字典方式get(key)提取所需数据项(值),插入数据库insert
def StockInformation(self, start_page, end_page):
for page in range(start_page, end_page + 1):
print(f"正在爬取第 {page} 页数据...")
url = f"https://1.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112402758990905568719_1728977574693&pn={page}&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&dect=1&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80,m:1+t:2,m:1+t:23,m:0+t:81+s:2048&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1728977574694"
stocks = self.get_stock_data(url)
try:
for stock in stocks:
stock_data = (
stock.get('f12'), # 股票代码
stock.get('f14'), # 股票名称
stock.get('f2'), # 最新价格
stock.get('f3'), # 涨跌幅
stock.get('f4'), # 涨跌额
stock.get('f5'), # 成交量
stock.get('f6'), # 成交额
stock.get('f7'), # 振幅
stock.get('f15'), # 最高价
stock.get('f16'), # 最低价
stock.get('f17'), # 今开
stock.get('f18'), # 昨收
)
self.db.insert(stock_data) # 插入数据库
except Exception as err:
print(f"Error processing page {page}: {err}")
实践结果
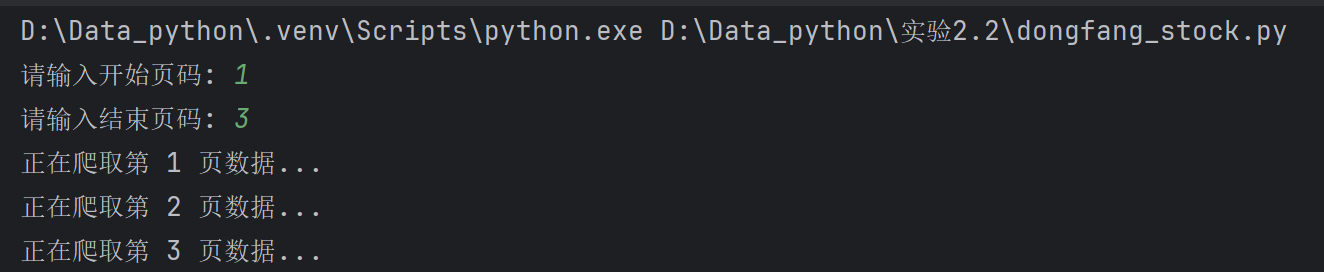
用户输入与加载过程:
存入数据库结果打印输出:
实践心得
本次抓包的文件有相对清晰的json格式,也便于直接用字典的键值对模式获取需要的内容。值得注意的是,在这里也需要观察随着翻页url的变化,加入这个注意点,更便于自定义爬取页数。
疑问:
本身具有合理的json格式,可以用字典的方法获取需要数据项,题目要求的beautifulsoup似乎并不适用于本题。
作业③
题目
要求:爬取中国大学2021主榜所有院校信息,并存储在数据库中,同时将浏览器F12调试分析的过程录制Gif加入至博客中。
技巧:分析该网站的发包情况,分析获取数据的api
输出信息:排名 学校 省市 类型 总分
爬取网站地址🔗:中国大学2021主榜
详细代码见gitee🔗:作业2-实验2.3
实践过程
抓包过程
右键->检查->Network->JS->clear network log->ctrl R->找到抓包信息所在文件(payload.js)
找不到可以点search🔍搜索关键字找到文件
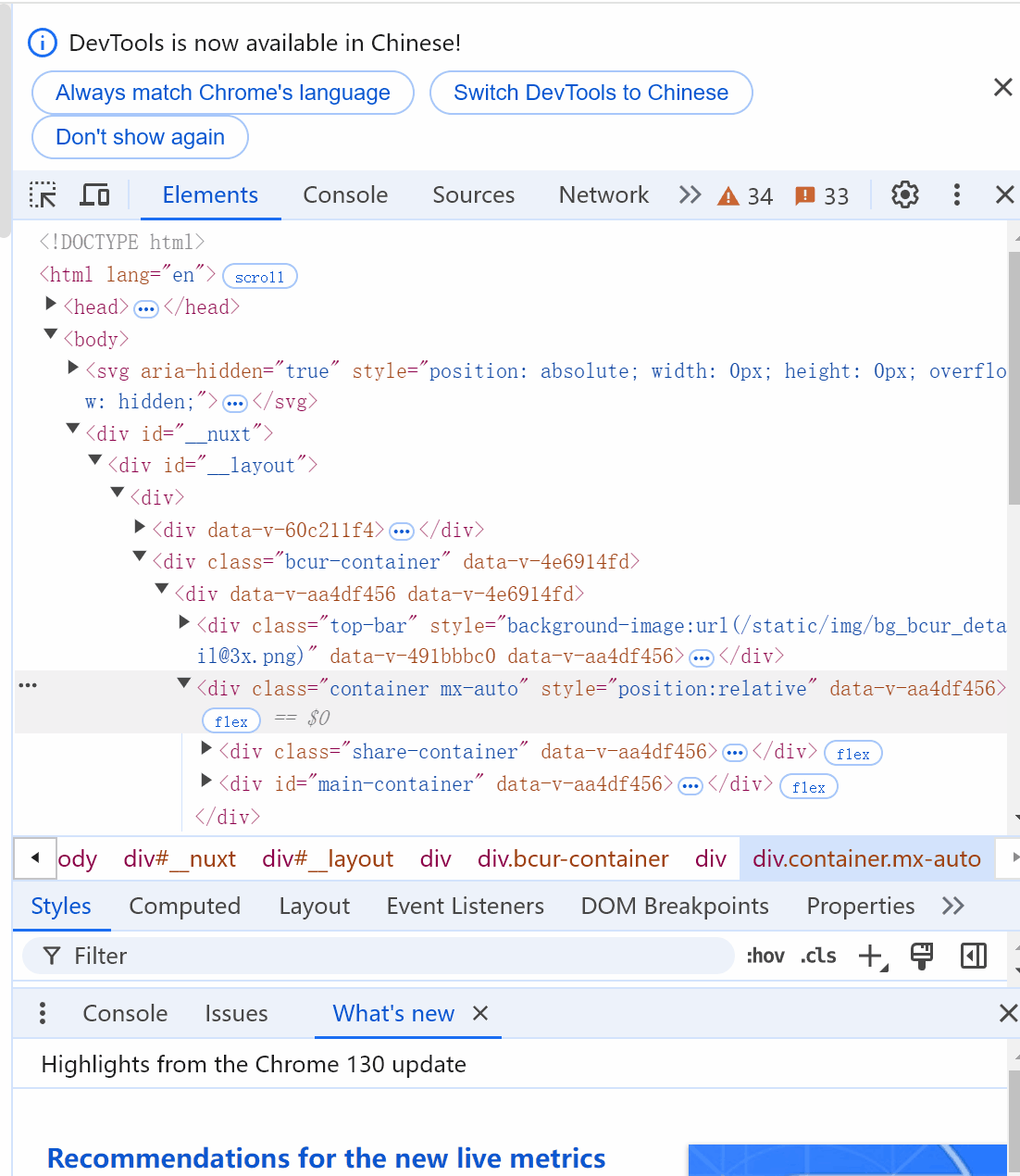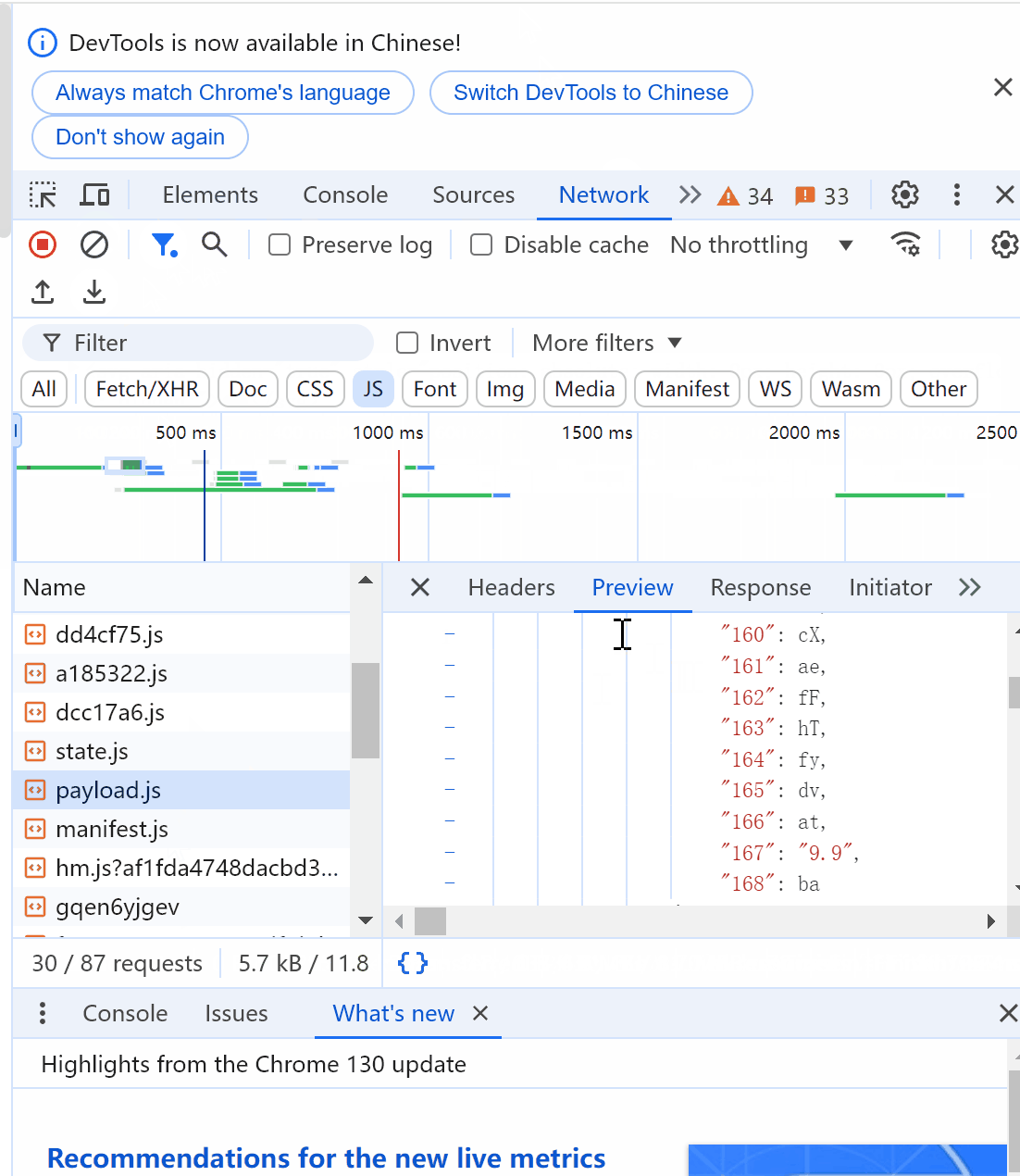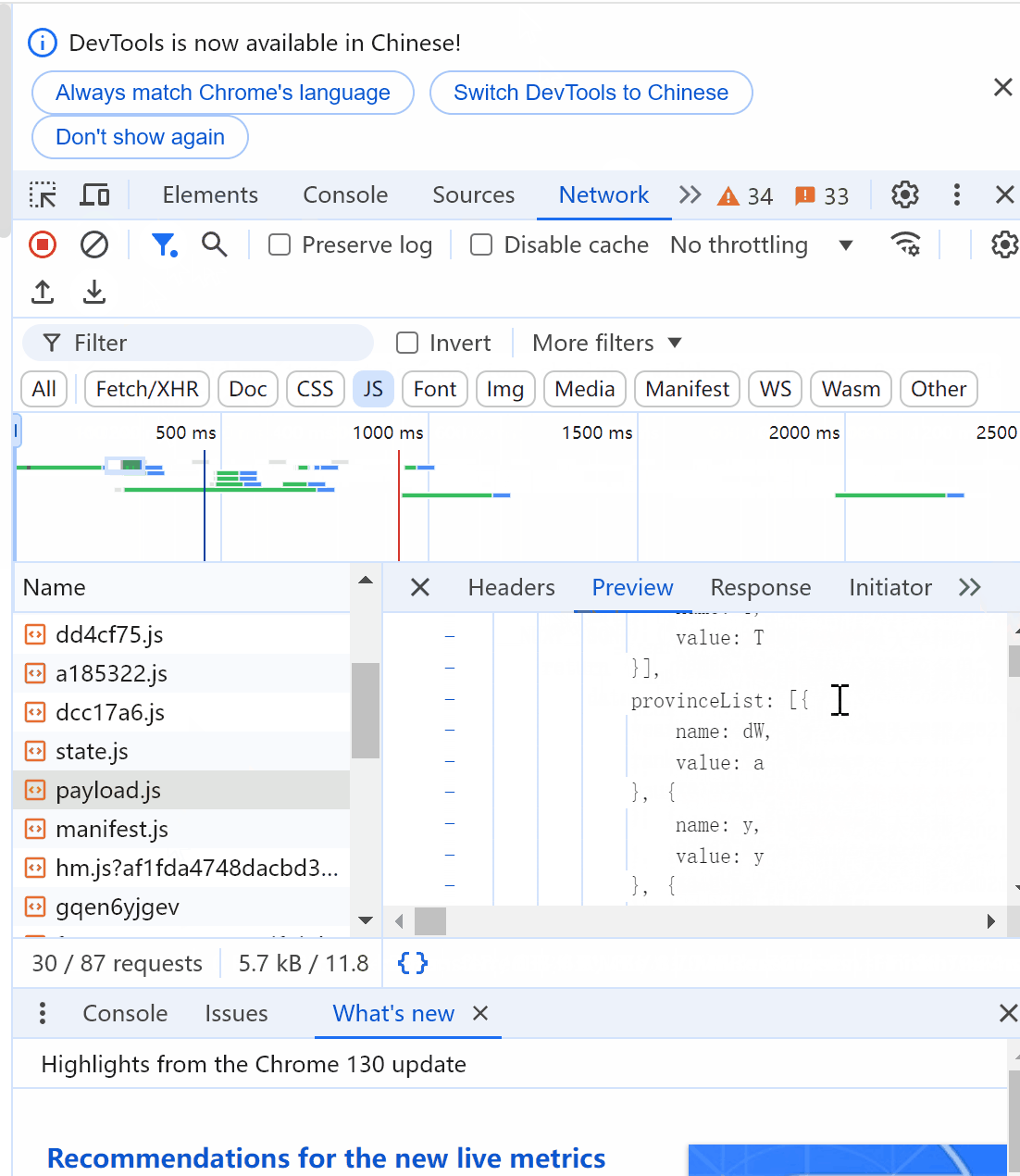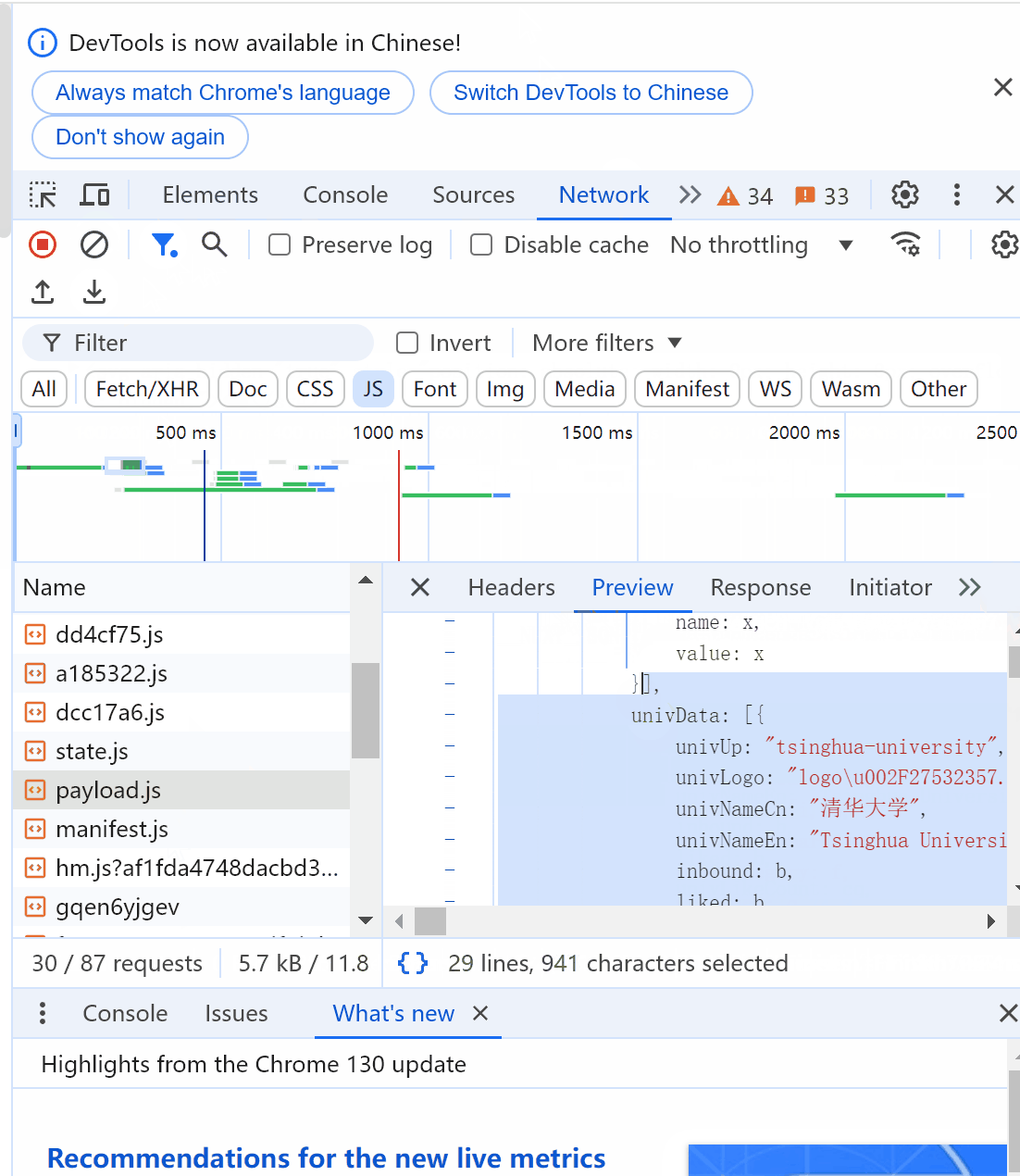
找到目标文件后,点击Headers查看请求url
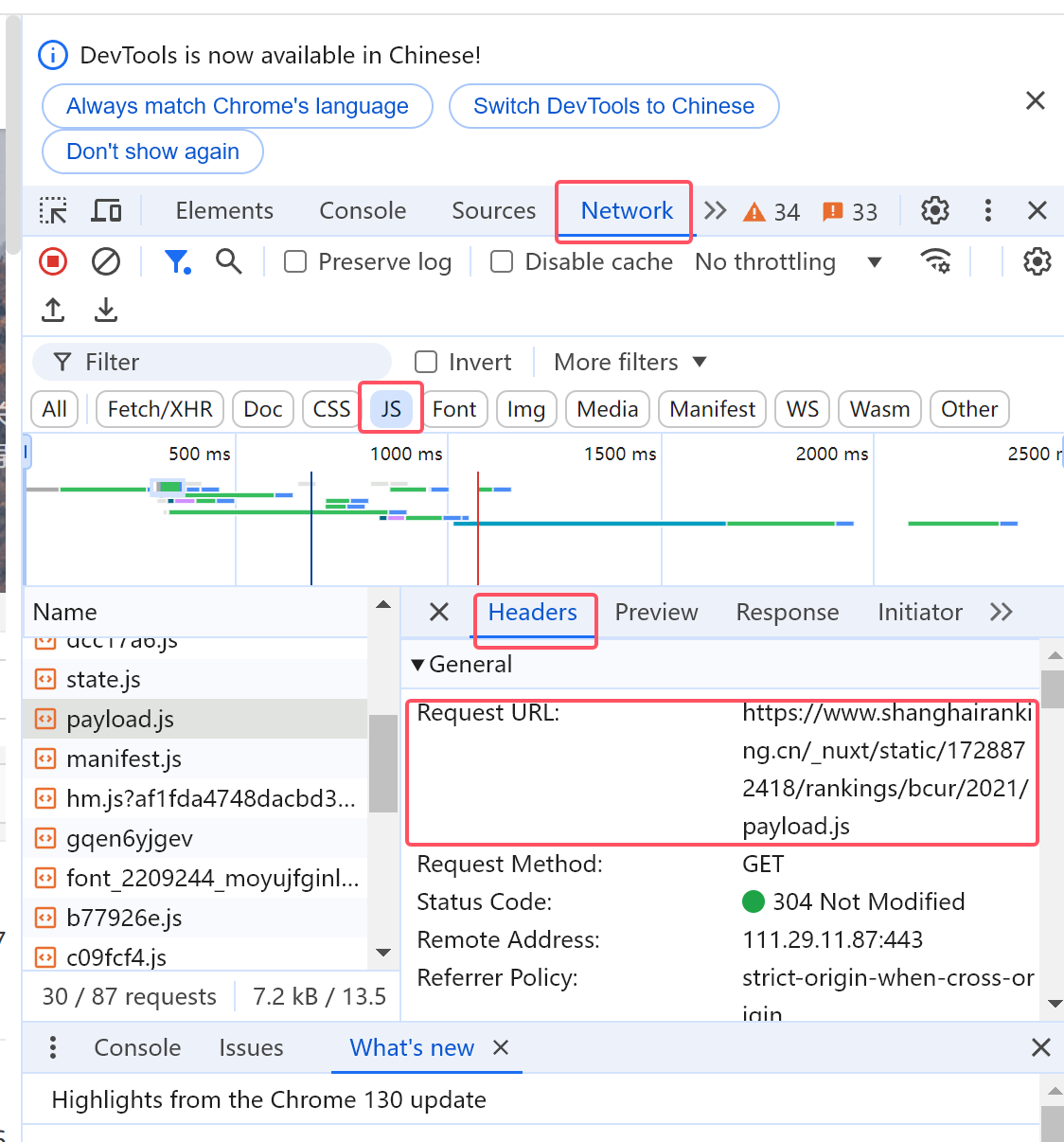
# 目标 URL
url = "https://www.shanghairanking.cn/_nuxt/static/1728872418/rankings/bcur/2021/payload.js"
# 发送请求获取文件内容
response = requests.get(url)
# 检查请求是否成功
if response.status_code == 200:
data = response.text # 将文本内容保存到 data 变量中
print("文件内容已成功存储在 data 变量中")
else:
print(f"请求失败,状态码: {response.status_code}")
解析网页
观察js文件得到排名、学校、省市、类型、总分内容对应的位置如下:
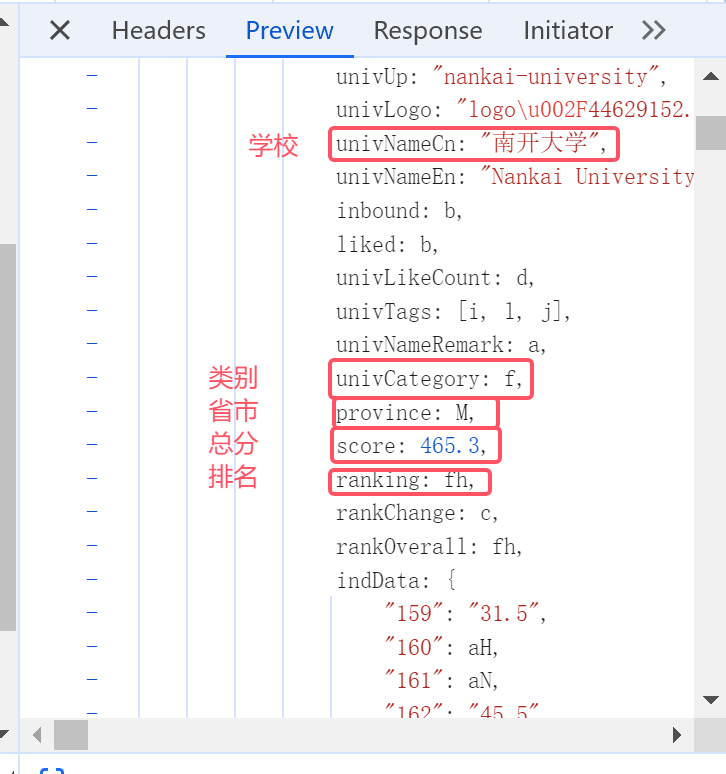
# 用正则表达式提取数据
ranking = re.findall(r'ranking:(.*?),rankChange', data)
names = re.findall(r'univNameCn:"(.*?)"', data)
province = re.findall(r'province:(.*?),score:', data)
classification = re.findall(r"univCategory:(.*?),province", data)
scores = re.findall(r"score:(.*?),ranking", data)
内容更新
明显地,其中排名、省市、类型都用了一些编码代替,所以需要寻找解码方法:
(后续发现同分同排名的学校,它们的总分都被同一个编码代替)
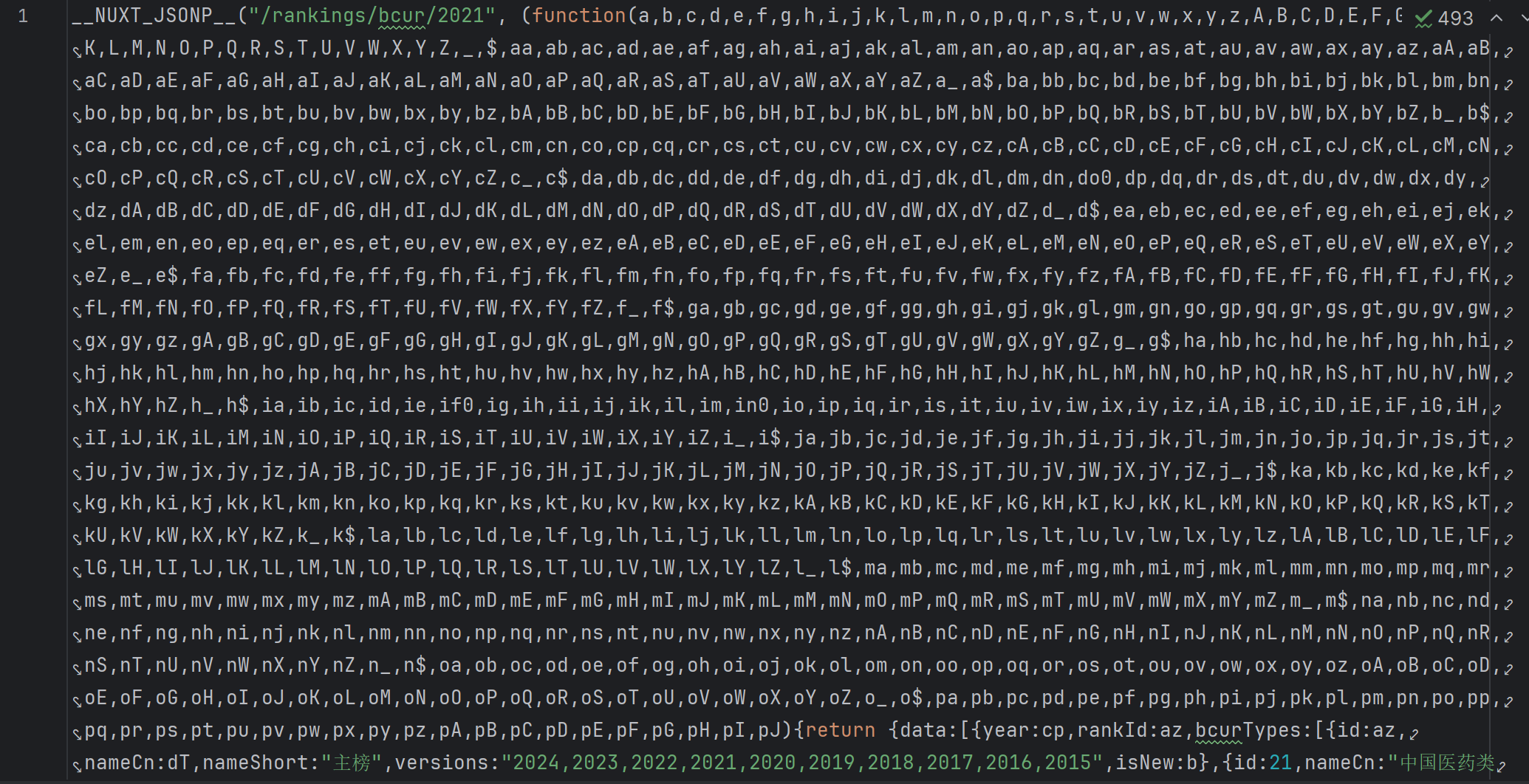
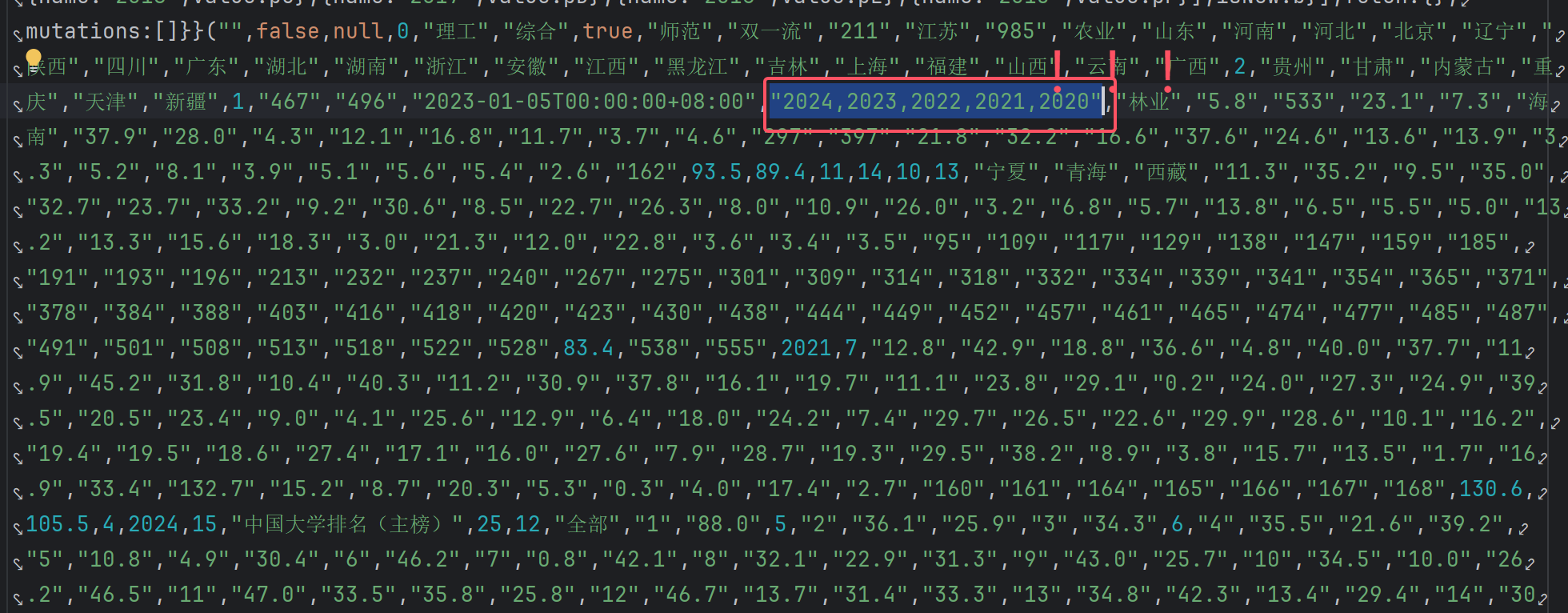
合理比对,发现括号里的内容存在一一对应关系
把内容爬取下来,做成映射字典mapping,再将排名、省市、类型、总分做对应的解码并存入数据库insert
# 用正则表达式提取内容
function_content = re.search(r'function\(([^)]*)\)', data).group(1)
mutations_content = re.search(r'mutations:\[\]\}\}\(([^)]*)\)', data).group(1)
# 由于字符串存在一个元素"2024,2023,2022,2021,2020",如果直接用逗号分隔会变成五个元素,进行字符串替换处理
mutations_content = mutations_content.replace("2024,2023,2022,2021,2020", "2024-2023-2022-2021-2020")
# 分隔成列表,直接以逗号分隔
function_list = function_content.split(',')
mutations_content_new = mutations_content.split(',')
# 由于分隔前集合元素都是字符串,其中内容包含带有双引号""的值,所以在这里把它去掉
mutations_list = [item.strip('"').strip("'") for item in mutations_content_new]
# 调试,看打印结果有没有出错
print(function_list)
print(mutations_list)
# 以长度是否相等判断处理结果是否正确
print(len(function_list))
print(len(mutations_list))
# 构建字典映射
mapping = {}
for func, mut in zip(function_list, mutations_list):
mapping[func] = mut # 将func和mut对应
print(mapping) # 打印映射查看结果
print(len(mapping)) # 以长度是否相等判断处理结果是否正确
# 解码并存入数据库
decoded_ranking = [mapping.get(r.strip(), r) for r in ranking]
decoded_province = [mapping.get(p.strip(), p) for p in province]
decoded_classification = [mapping.get(c.strip(), c) for c in classification]
decoded_scores = [mapping.get(s.strip(), s) for s in scores]
for r, n, p, c, s in zip(decoded_ranking, names, decoded_province, decoded_classification, decoded_scores):
self.db.insert(r, n, p, c, s)
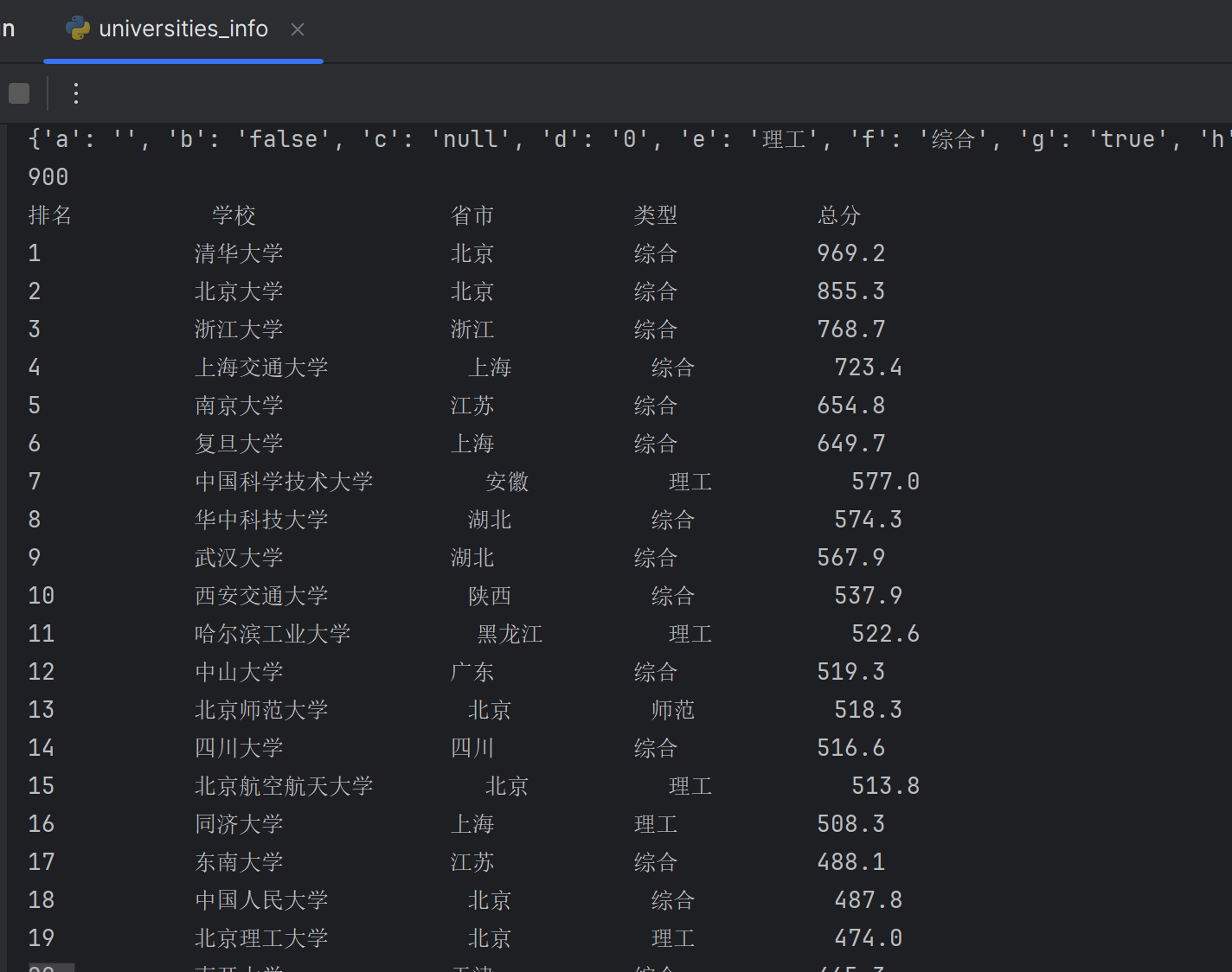
实践结果
核对:

存入数据库结果打印输出:
实践心得
这题大学数据抓包不像前一题股票抓包,有明显合理的json格式,可以直接用字典获取所需数据,但每个抓取内容前面标志都很统一,因此直接用正则表达式解析文档是最合适的。
同时,这题里面存在一个解码的问题,需要自行构造映射字典,再一一解码存入数据库,是很新颖的体验,具体思考过程也写在实践过程板块中了。
实践总结
由于在做题的过程中,将整体思路分为比较清晰的两大类:数据库定义类和数据爬取类,最后又以process简单调用方法完成爬虫并存入数据库的五步走。也就是说,在编写代码时,提前编排好了做题逻辑,也能保持相对清醒的头脑。
在这次作业,我初次实践了抓包过程,一开始还会遇到找不到抓包文件的问题,后面也逐渐熟练,可以更有目的地去使用F12开发者工具。
