数据采集作业1
| 这个作业属于哪个课程 | 2024数据采集与融合技术实践 |
|---|---|
| 这个作业要求在哪里 | 作业1 |
| 这个作业的目标 | 1.爬虫设计 2.掌握requests库、BeautifulSoup库、re库 3.规范化打印输出结果 4.图片下载 |
| 学号 | 102202123 |
Gitee🔗:作业1
作业整体思路:
- 从用户输入获取要爬取的内容(如商品名、页码等)
- 构建目标URL
- 获取HTML文本(requests、urllib)
- 获取成功后解析数据(Beautiful Soup(bs4)、正则表达式(re))
- 打印结果(format格式化打印输出、生成相应文件)
作业①
题目
要求:用requests和BeautifulSoup库方法定向爬取给定网址2020年软科排名的数据,屏幕打印爬取的大学排名信息。
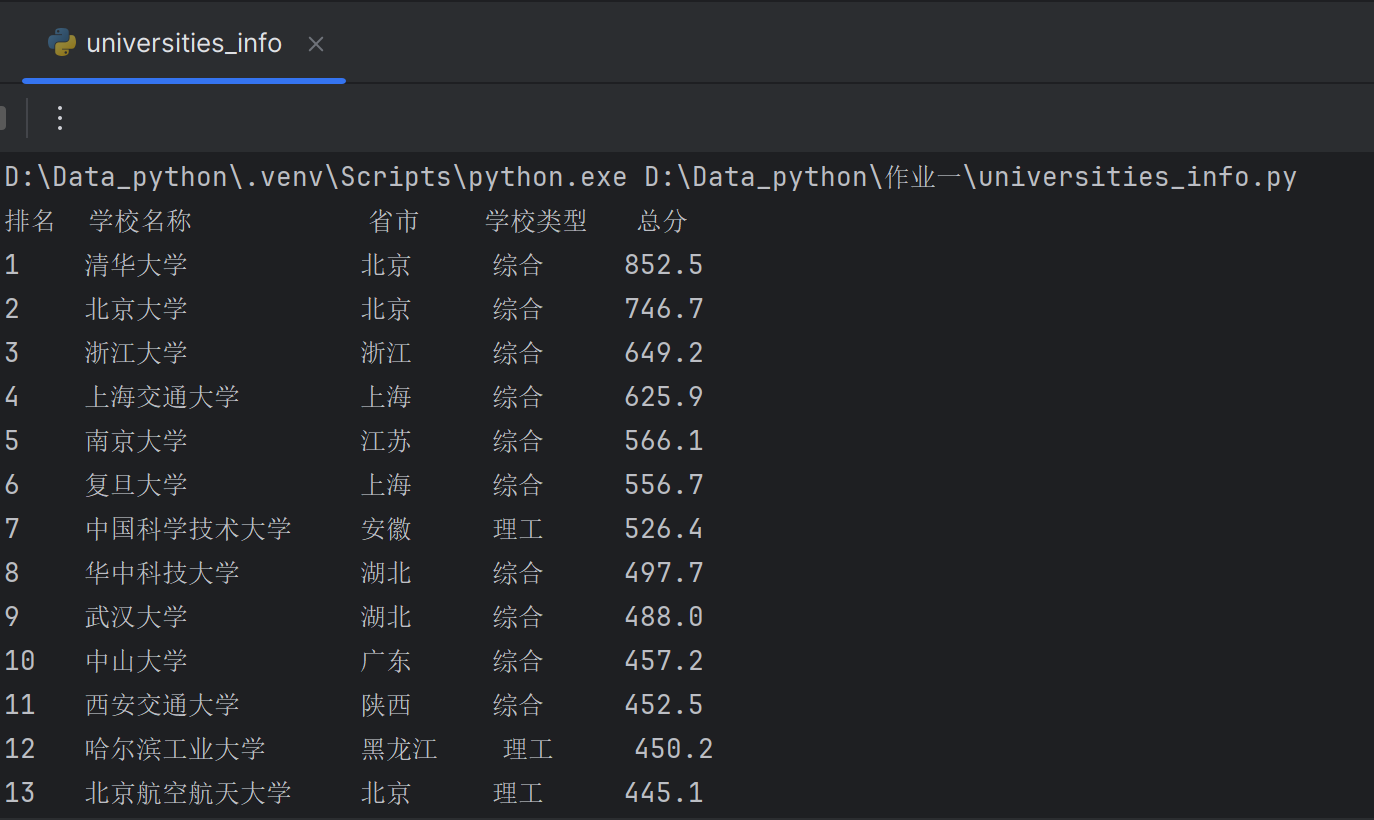
输出信息:排名 学校名称 省市 学校类型 总分
详细代码见gitee🔗:作业1-作业①
实践过程
1.网页检查
检查网页html得到爬取内容主要在tbody节点下的所有tr元素节点中
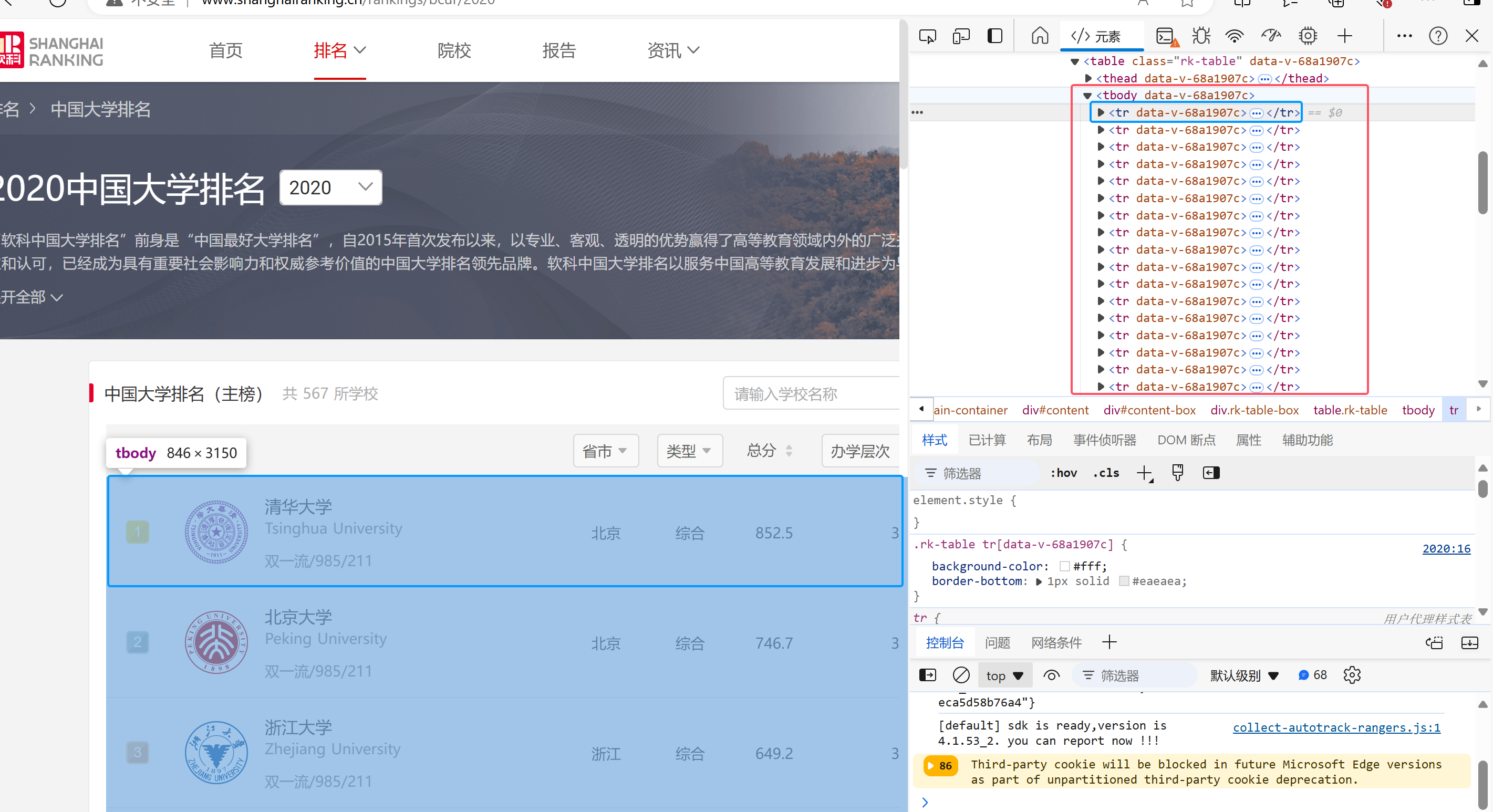
先用css语法查找对应内容并爬取,存入trs列表
soup = BeautifulSoup(data, "lxml")
trs = soup.select("tbody tr")
继续观察想要爬取的信息排名、学校名称、省市、学校类型、总分的位置
分别在下图五个红框中
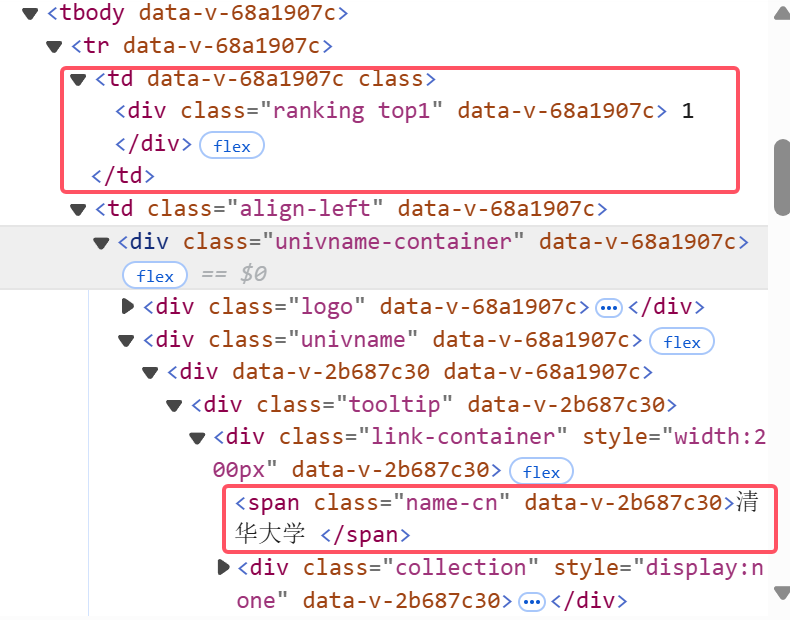
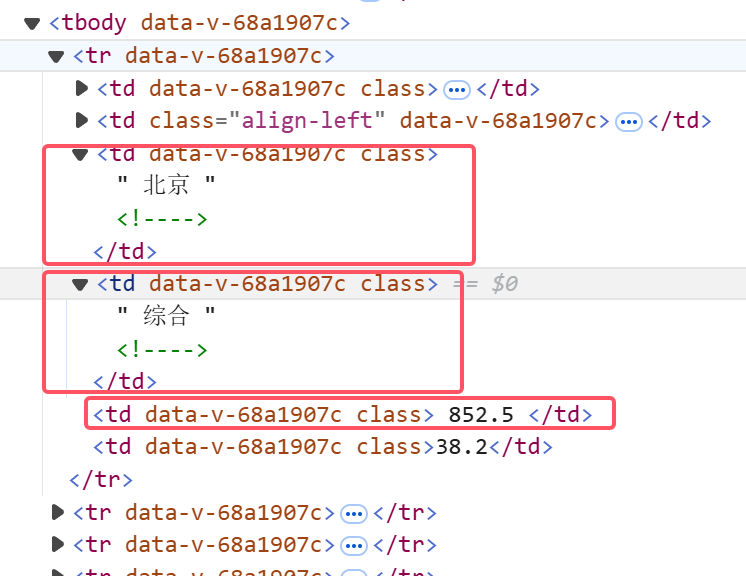
遍历trs列表的每个子元素(即每个学校的信息),用find和find_all函数查找指定元素,并用.text获取元素包含的文本值
ranking = tr.find('div', class_='ranking').text.strip()
university_name = tr.find('span', class_='name-cn').text.strip()
# 将变量 university_name 的值用全角空格(Unicode字符\u3000)填充到总长度为10个字符
university_name = university_name + "\u3000" * (10 - len(university_name))
location = tr.find_all('td')[2].text.strip()
category = tr.find_all('td')[3].text.strip()
score = tr.find_all('td')[4].text.strip()
# strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)
strip()方法用于移除字符串头尾指定的字符(默认为空格或换行符)
2.规范打印输出格式
由于学校名称长短不一致,而format统一格式时是以默认空格占位,其大小小于单个中文字符,会导致打印输出结果不整齐
因此需要调整university_name的输出:
用全角空格(Unicode字符\u3000)填充到总长度为10个字符
university_name = university_name + "\u3000" * (10 - len(university_name))
# 格式化打印输出
print('{:<4} {:<10} {:<6} {:<6} {:<6}'.format(ranking, university_name, location, category, score))
3.输出结果(部分)
实践心得
直接打印输出在打印台,让我注意到了爬取数据后打印输出格式的问题。而在format的填充字符中没有全角空格,故需要直接更改爬取的学校名称。
作业②
题目
要求:用requests和re库方法设计某个商城(自已选择)商品比价定向爬虫,爬取该商城,以关键词“书包”搜索页面的数据,爬取商品名称和价格。
输出信息:序号 价格 商品名
本题选取购物商城🛒:当当网
详细代码见gitee🔗:作业1-作业②
实践过程
1.反爬虫
通过设置 User-Agent,代码伪装成一个具体的浏览器,这有助于避免一些网站对自动化脚本(如爬虫)的封锁
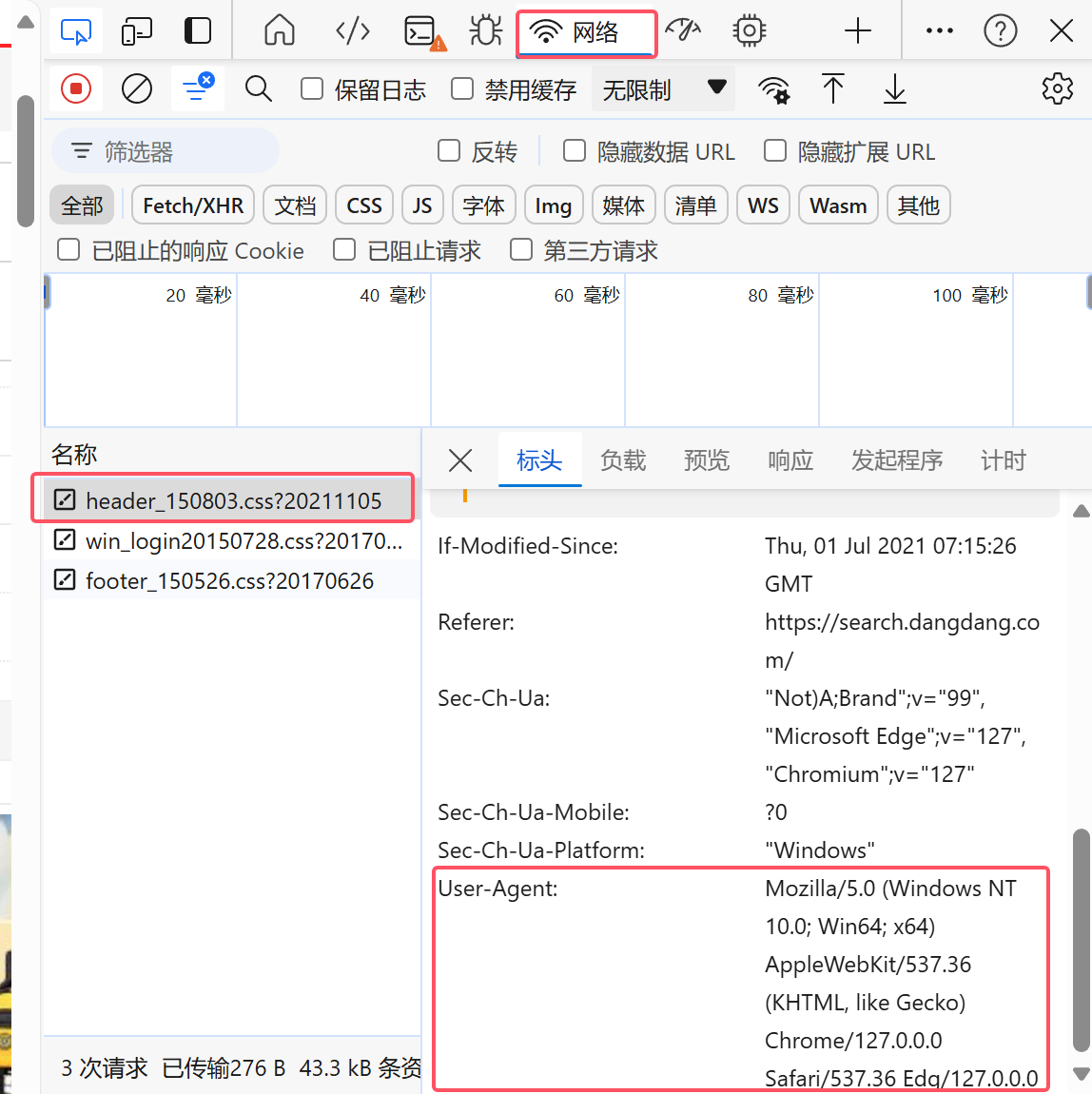
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/127.0.0.0 Safari/537.36'
}
try:
response = requests.get(url, headers=headers)
2.翻页观察url变化
第一页:
https://search.dangdang.com/?key=����&act=input&page_index=1
第二页:
https://search.dangdang.com/?key=����&act=input&page_index=2
url组成:key={商品名称} url编码——每个非ASCII字符被转换成以 "%" 开头的两个十六进制数字
翻页改变字段:page_index={页码}
url通式:
url = f'https://search.dangdang.com/?key={goods}&act=input&page_index={page}'
3.网页检查
检查网页html得到爬取内容主要在ul节点下的所有li元素节点中
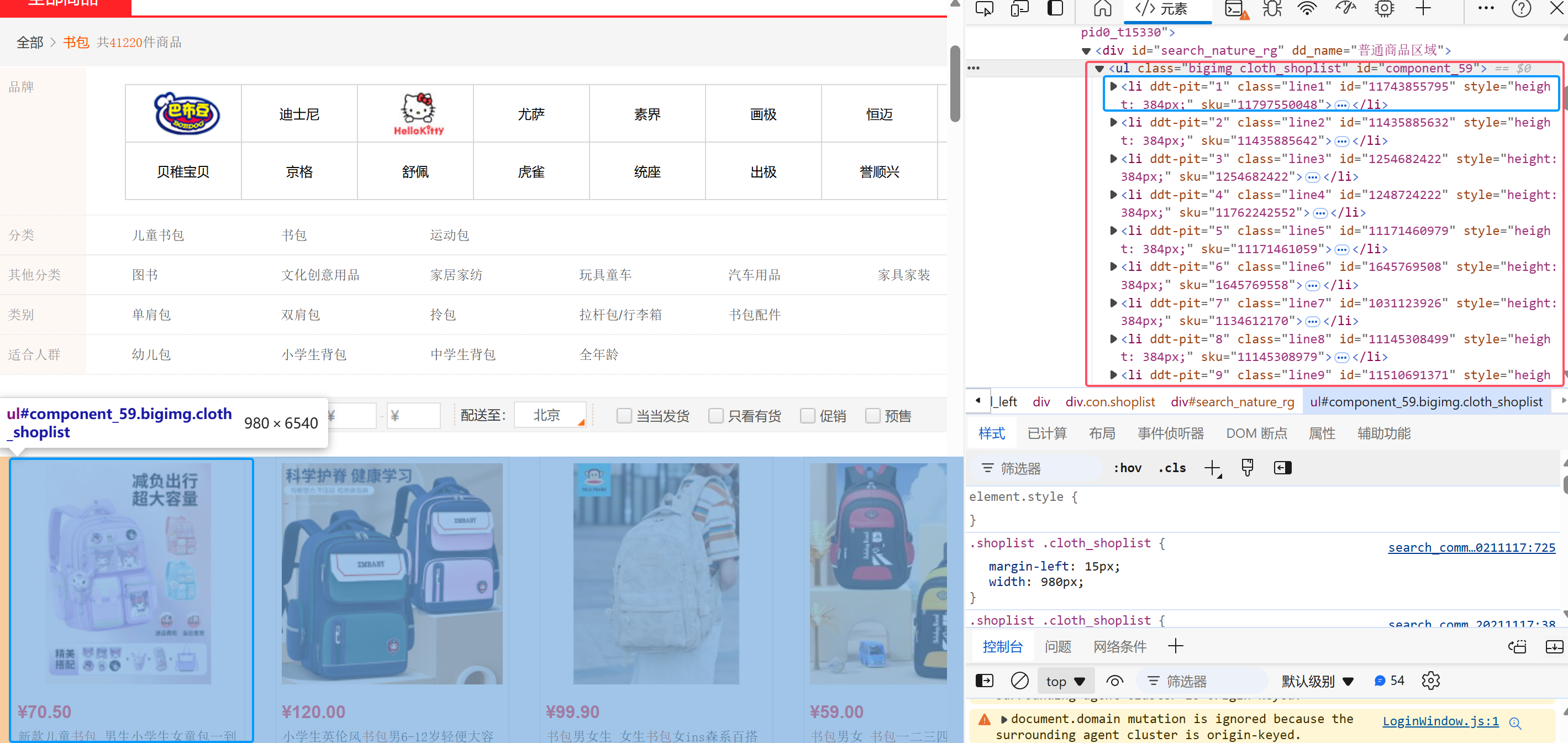
继续观察,要爬取信息价格、商品名位置如下:
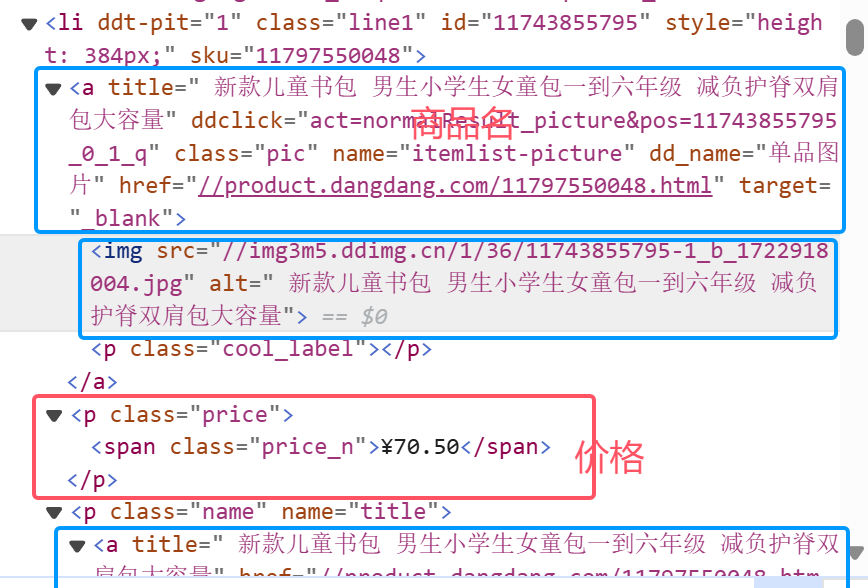
而商品名就有三个爬取选项,如何选择?

向上搜索发现,品牌名称的显示格式与商品名称有冲突
故选择alt属性名称作为商品名称信息爬取来源
4.爬取问题与解决
通过调试打印爬取的数据data文件,得知price在爬取后特殊字符¥编译为了¥

正式更改re表达式:
prices = re.findall(r'¥([\d,]+\.\d{2})', data)
names = re.findall(r'alt=\'(.*?)\'', data)
5.规范打印输出格式
为了规范打印输出格式,将爬取的价格、商品名称,连同自增商品序号一并存入列表uinfo,最后用format方法实现格式化输出
for i in range(min(len(names), len(prices))):
price = prices[i].strip()
name = names[i].strip()
uinfo.append([i + 1, price, name])
return uinfo
def printGoodslist(uinfo):
tplt = "{0:^5}\t{1:^10}\t{2:^20}"
print(tplt.format("序号", "价格", "商品名"))
for i in uinfo:
print(tplt.format(i[0], i[1], i[2]))
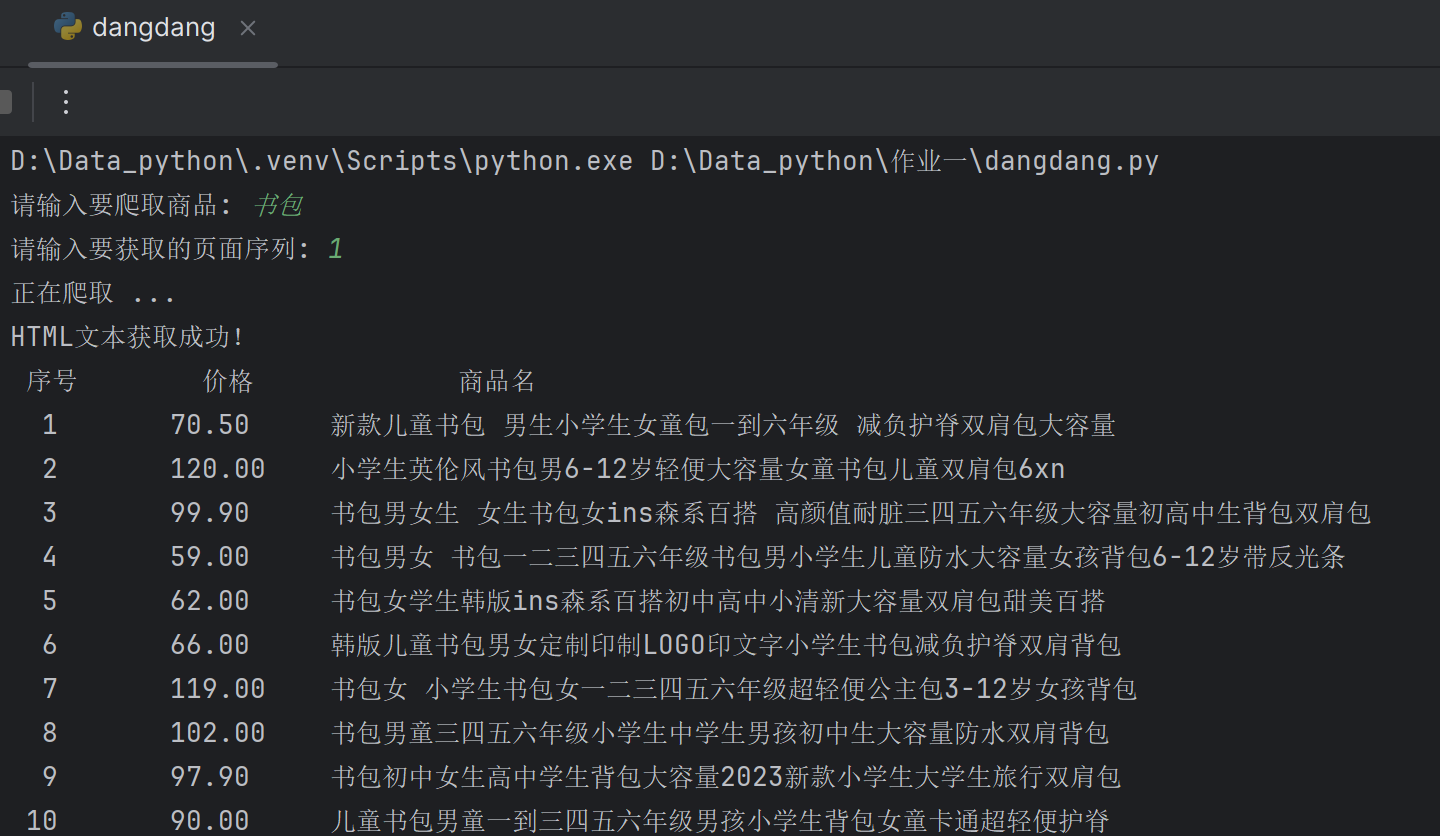
6.输出结果(部分)
实践心得
通过实操爬取当当网,我首次接触到网站的反爬虫机制,在一个网站重复爬取,会有一次突然失败。此时应该把爬取内容存为文件,针对文件进行爬取更合适。
这次爬取我也学会了调试的重要性,我在编写正则表达式时也经历了print(data),print(price),print(name)三个打印调试,最终才得以确认正确的表达式。
作业③
题目
要求:爬取一个给定网页影像福大或者自选网页的所有JPEG和JPG格式文件
输出信息:将自选网页内的所有JPEG和JPG文件保存在一个文件夹中
本题选取网页🔗:影像福大
详细代码见gitee🔗:作业1-作业③
实践过程
1.翻页观察url变化
第一页:
https://news.fzu.edu.cn/yxfd.htm
第二页:
https://news.fzu.edu.cn/yxfd/5.htm
第三页:
https://news.fzu.edu.cn/yxfd/4.htm
...
翻页改变字段:
- 第1页:/yxfd.htm
- 第2-6页:/yxfd/{6-页码+1}.htm
url通式:
if page == '1':
url = 'https://news.fzu.edu.cn/yxfd.htm'
else:
page_need = str(6 - int(page) + 1)
url = f'https://news.fzu.edu.cn/yxfd/{page_need}.htm'
2.网页检查
检查网页html得到爬取内容主要在ul节点下的所有li元素节点中
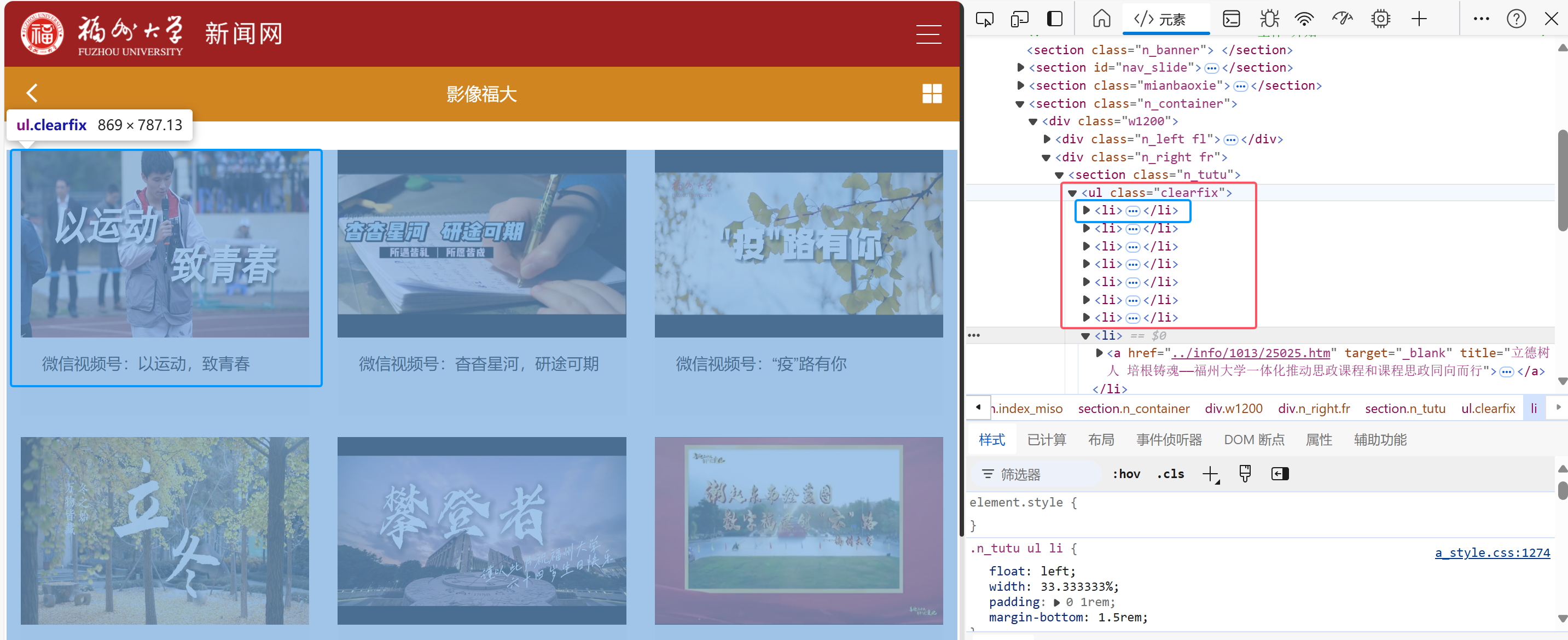
继续观察,要下载图片路径位置如下:
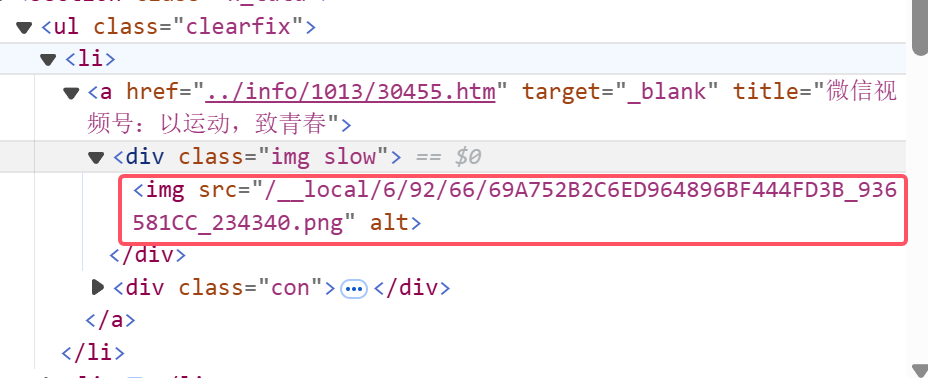
3.图片下载路径获取
检查网页时看得出来html中的图片url并不带http/https头
右键->在新标签页中打开图像->得到隐藏路径头https://news.fzu.edu.cn/
由于要求仅爬取所有JPEG和JPG格式文件
总结得到完整的图片路径爬取代码:
def parsePage(uinfo, data):
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='clearfix'] li")
for li in lis:
img_tag = li.find('img')
if img_tag:
img_src = img_tag['src']
if not img_src.startswith(('http:', 'https:')):
img_src = 'https://news.fzu.edu.cn' + img_src
if img_src.lower().endswith(('.jpg', '.jpeg')):
uinfo.append(img_src)
else:
print(f"跳过该图片: {img_src}")
return uinfo
4.图片下载
def download_image(image_url, index, max_retries=3):
for attempt in range(max_retries):
try:
# 使用requests.get()方法尝试从URL获取图像数据
image_data = requests.get(image_url).content
# 使用with语句打开文件,确保文件在操作完成后正确关闭
# f'images/image_{index}.jpg' 使用f-string格式化文件名
# 'wb'模式表示以二进制写入方式打开文件
with open(f'images/image_{index}.jpg', 'wb') as f:
f.write(image_data) # 将图像数据写入文件
# 打印成功下载的消息
print(f"Downloaded image_{index}.jpg")
return # 成功下载后退出函数
except Exception as e:
# 捕获任何异常,并打印错误信息
print(f"Error downloading {image_url}: {e}")
# 如果当前尝试次数小于最大重试次数减一,表示还有重试的机会
if attempt < max_retries - 1:
print("Retrying...") # 打印重试消息
time.sleep(1) # 等待1秒后再次尝试
# 如果达到最大重试次数仍然失败,打印最终失败的消息
print(f"Failed to download {image_url} after {max_retries} attempts.")
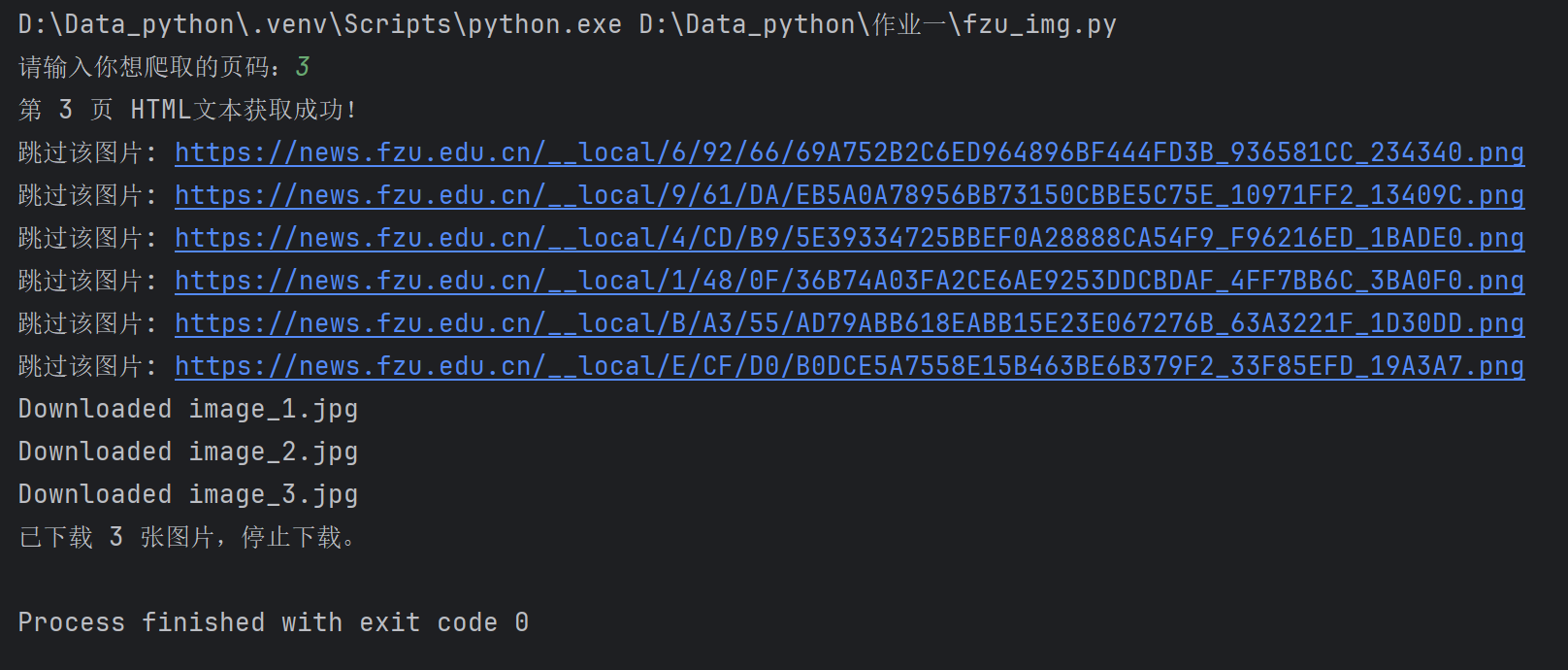
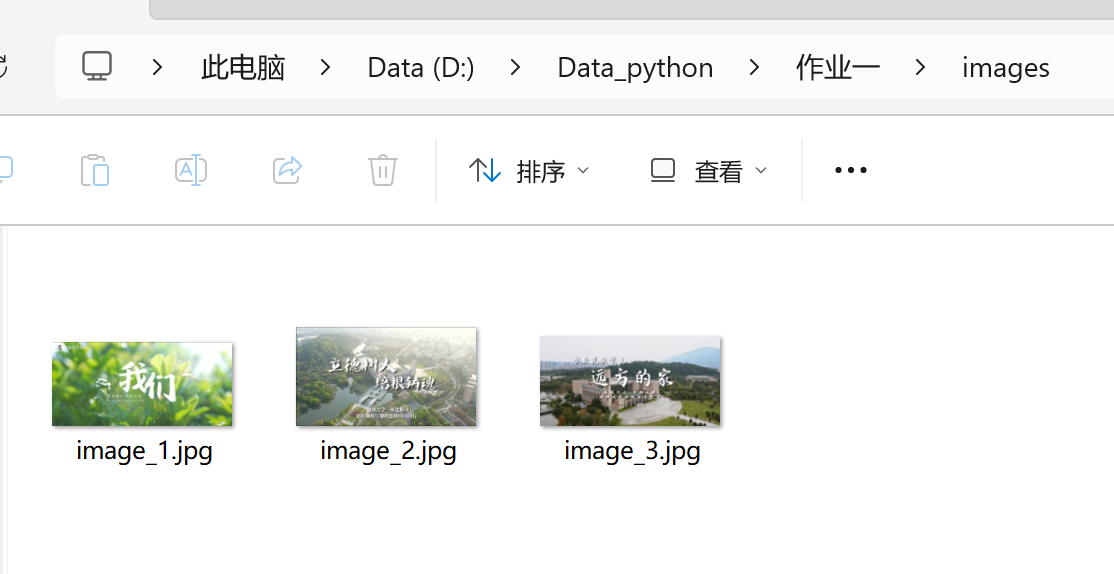
5.输出结果展示
打印第3页内容为例:
实践心得
需要注意审题,要爬取的是所有JPEG和JPG格式文件,需要特别保留endswith(('.jpg', '.jpeg'))的爬取路径
同时,此题在爬取图像链接的同时结合了图片下载,增强了可操作性

