【Python 网络爬虫课程设计】——爬取关键词为“淄博烧烤”的微博帖子+数据分析报告
一、选题的背景
选择爬取关键词为“淄博烧烤”微博帖子的选题,主要是基于以下几个原因:首先,烧烤是一种受欢迎的美食,而淄博作为中国的一个历史悠久的城市,拥有着许多独特的美食文化,烧烤就是其中之一。“淄博烧烤”是一道享誉全国的美食,尤其是在夏季,淄博当地人及游客都会前往各大烧烤摊位享受美食。在社交平台微博上,也经常有人分享他们在淄博吃烧烤的经历和感受。本报告选取“淄博烧烤”为关键词进行网络爬虫,旨在收集分析与淄博烧烤相关的微博帖子数量、内容、微博作者IP属地等信息,以了解淄博烧烤在社交媒体上的普及程度和影响力。预期目标是搜集有效数据样本并进行分析,从而得出有关淄博烧烤的相关结论。最后,本选题的数据来源主要是微博,这是一种社交媒体平台,具有信息传播快、传播范围广、传播域多、传播形式多样等特点,是了解社会热点、消费者心理和市场变化的重要渠道。同时,Python作为一种程序语言,具有简单易学、便于掌握和高效的特点,非常适合用来爬取和处理数据。
二、主题式网络爬虫设计方案
1.主题式网络爬虫名称:关键词为“淄博烧烤”的微博帖子分析爬虫
2.主题式网络爬虫爬取的内容与数据特征分析
爬取的内容:爬取某个关键字的微博搜索结果,包括每条微博的发布时间、微博id、微博bid、微博作者、微博内容、转发数、评论数、点赞数、IP属地、页码
数据特征分析:通过分析微博文本内容和用户交互的数据(转发、评论、点赞),可以了解淄博烧烤的热度、用户情感倾向、用户评论内容等信息。
3.主题式网络爬虫设计方案概述(包括实现思路与技术难点)
实现思路:
- 使用Python的requests库发送HTTP请求,模拟用户访问微博页面,并获取页面内容。
- 使用正则表达式和jsonpath库解析页面内容,提取所需的数据字段。
- 对爬取的数据进行清洗和处理,去除HTML标签等无关信息。
- 使用pandas库将清洗后的数据保存到CSV文件中。
- 对提取出的字段进行分析和可视化,对微博的发布时间、转发数、评论数、点赞数等指标进行统计和可视化。
- 根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变量之间的回归方程;
- 将最终处理后的数据存储到 csv 文件中,以备后续分析和处理。
技术难点:1.因为微博是动态加载的页面,即需要翻页爬取的技术获取2.访问请求的阻挡,微博的访问链接有PC端、移动端、旧站点三个,PC端的反爬机制很强,所以本设计访问的是移动端。
3.JSON 数据解析、正则表达式的应用。 4.matplotlib绘图、LinearRegression建立线性回归模型
三、主题页面的结构特征分析(10 分)
1.主题页面的结构与特征分析
微博页面通常采用动态加载的方式,即通过发送请求获取数据,而不是静态的HTML页面,即需要模拟浏览器发送请求并解析返回的JSON数据来获取所需的信息。
微博页面的结构主要由一系列微博卡片(cards)组成,每个卡片(cards)包含了微博的各个字段信息,例如文本内容、发布时间、作者信息、转发数、评论数、点赞数等。
2.JSON页面解析
由于微博页面采用动态加载,返回的数据通常为JSON格式。所以本设计是解析JSON数据来提取所需的信息。
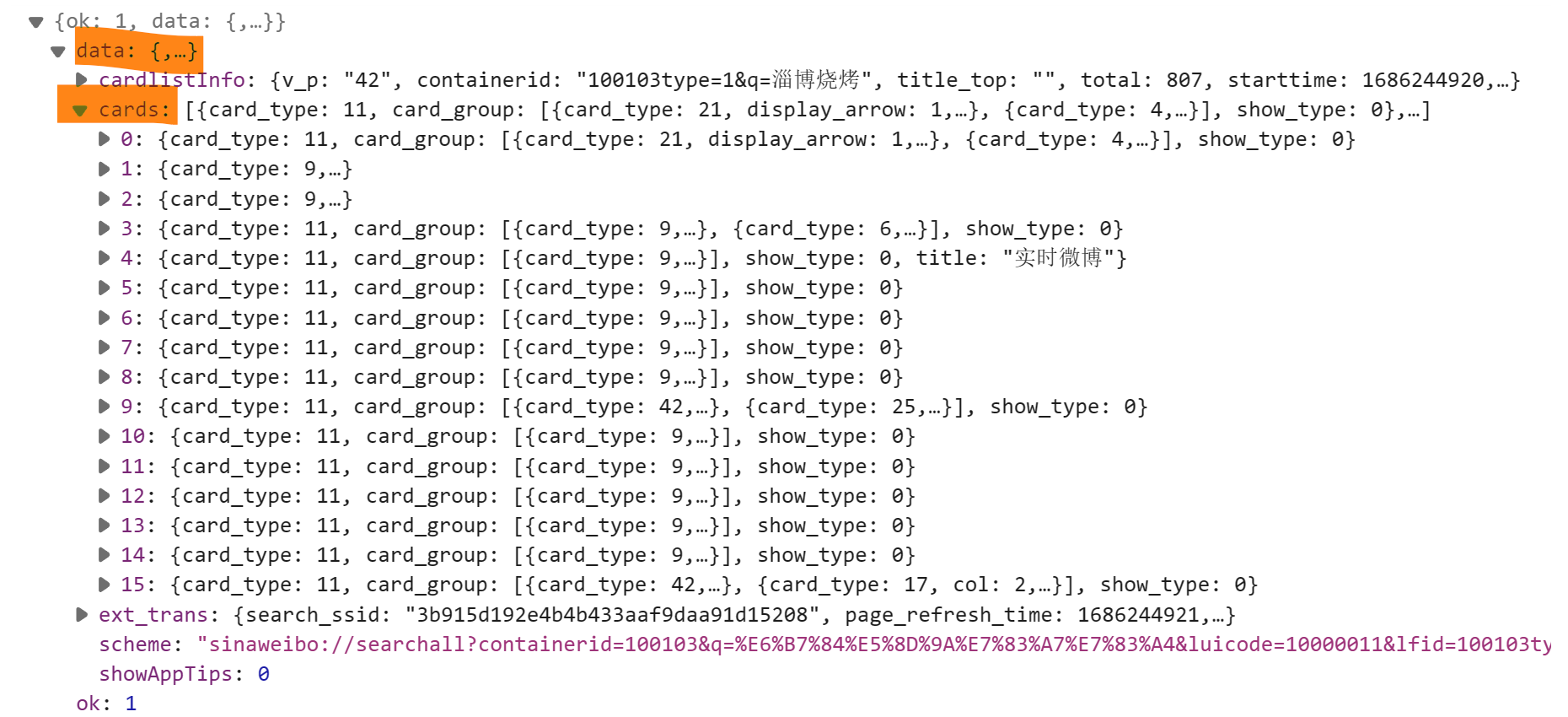
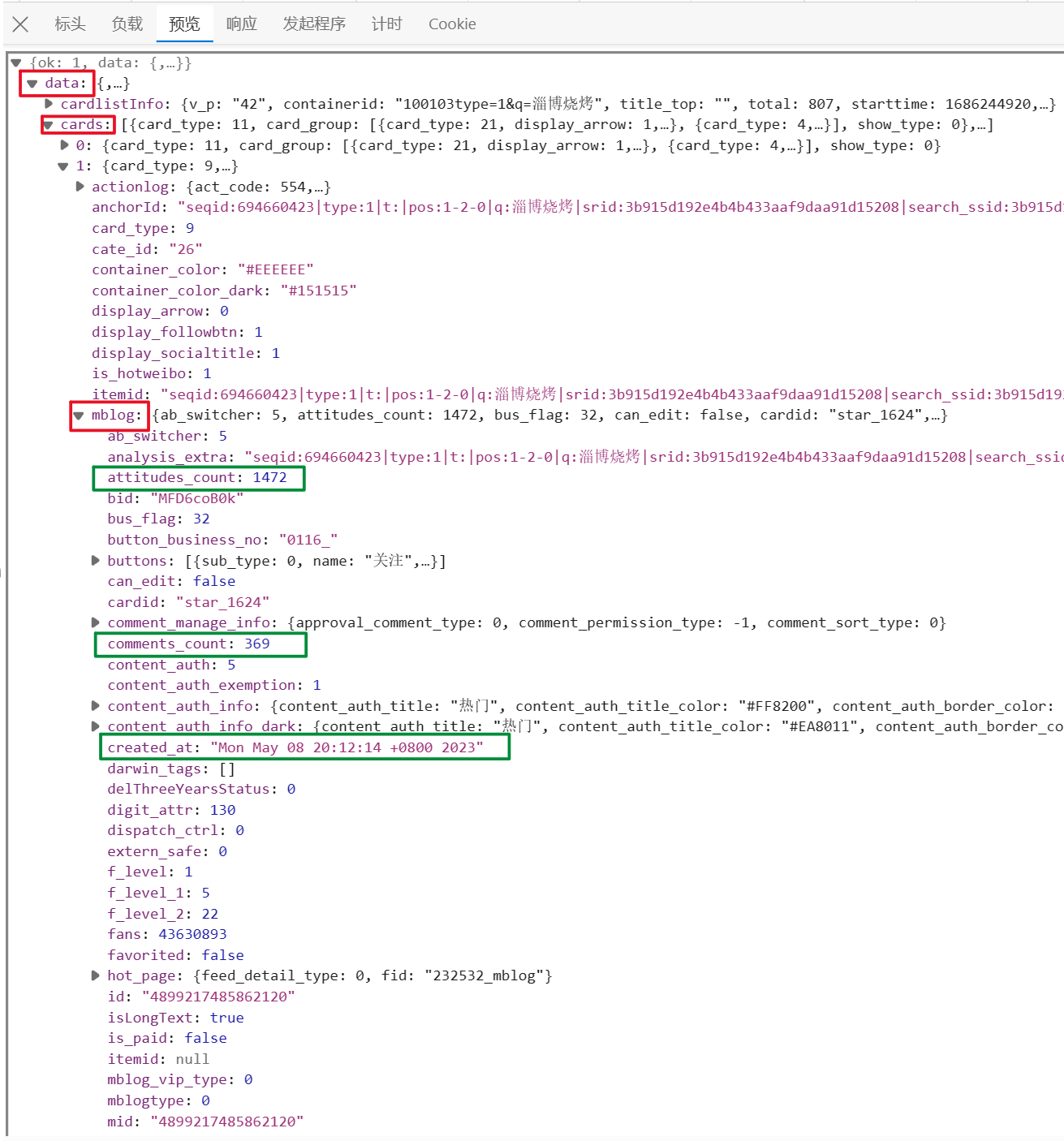
JSON数据包含了微博卡片(cards)的信息,通过调用 jsonpath 函数并传递相应的查询路径,获取了 cards 中每个 对象下特定字段的值,分别存储在各个字段列表。
每一页的json结构:
{ 'ok': 1,
'data': {
'cards': [
{'mblog':{'attitudes_count':34,'comments_count':45,'created_at':"Mon May 08 20:12:14 +08002023",'reposts_count':2,'status_province':"北京"},'user':{'id':3456789,'screen_name':"人民日报"},{....每一条帖子的json结构},{..........}
]
}
}
搜索词为“淄博烧烤”的微博搜索结果页面的json页面:

3.节点(标签)查找方法与遍历方法
节点的查找方法:在解析JSON数据之前,需要先定位到包含微博信息的节点或标签。常用的方法有使用CSS选择器或XPath表达式进行节点查找,本设计采用的是XPath表达式进行节点查找。
XPath表达式:通过路径表达式或条件表达式定位节点。本设计代码中使用了jsonpath库的jsonpath()方法,该方法可以根据XPath表达式来匹配和提取JSON数据中的节点。XPath是一种用于在XML和HTML文档中进行节点选择和提取的语言,它提供了一组表达式和函数,可以精确地定位和提取所需的节点。在代码中,通过传递合适的XPath表达式作为参数,可以选择匹配该表达式的节点。
遍历方法:使用用for循环遍历。本设计代码中是先将每个有效的微博内容进行正则表达式处理和存储到text_list列表中,使用 for 循环遍历 text_list 列表中的每个元素 text,然后对于每个元素,使用正则表达式 进行处理并存储到 text2_list 中。
四、网络爬虫程序设计(60 分)爬虫程序主体要包括以下各部分,要附源代码及较详细注释,并在每部分程序后 面提供输出结果的截图。
1.数据爬取与采集
#######1.数据爬取与采集 import os #操作文件、获取环境变量等。 import re #正则表达式提取文本,,可以用来匹配、查找和替换文本。 from jsonpath import jsonpath #解析json数据 import requests #发送请求,用于发送HTTP请求和处理HTTP响应。 import pandas as pd #存取csv文件 import datetime #转换时间 # 转换GMT时间为标准格式 def trans_time(v_str): GMT_FORMAT='%a %b %d %H:%M:%S +0800 %Y' timeArray = datetime.datetime.strptime(v_str ,GMT_FORMAT) ret_time = timeArray.strftime("%Y-%m-%d %H:%M:%S") return ret_time # 爬取微博内容列表函数 # s_keyword:关键字 # w_max_page:爬取前几页 # return:None def get_weibo_list(s_keyword,w_max_page): #请求开头 headers={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57", "accept": "application/json, text/plain, */*", "accept-encoding": "gzip, deflate, br", } # 循环爬取前w_max_page 页的微博内容。对于每一页,先构造请求地址和请求参数,然后发送请求并获取响应。 for page in range(1,w_max_page+1): print('==开始爬取第{}页微博=='.format(page)) #请求地址 url='https://m.weibo.cn/api/container/getIndex?containerid=100103type=1&q=淄博烧烤&page_type=searchall' # 请求参数 params={ "containerid":"100103type=1&q=淄博烧烤".format(s_keyword), "page_type":"searchall", "page":page } #发送请求 r=requests.get(url,headers=headers,params=params) #r.status_code 是 HTTP 响应状态码,表示服务器返回的请求处理结果。如果状态码为 200,则表示请求成功,否则表示请求失败 print(r.status_code) # 解析json数据 #解析 HTTP 响应中的 JSON 数据,并提取出关键字 cards 所对应的值,即搜索结果集合。 # 其中,r.json() 将响应解析成 JSON 格式的对象(Python 字典);r.json()["data"] 取出键为 data 的字典,其中包含了搜索结果的数据; cards=r.json()["data"]["cards"]#取出了 cards 字段,即淄博烧烤搜索结果的查询结果页信息。 # 微博内容 #解析响应,并使用 jsonpath 库从响应的 JSON 数据中提取微博的相关字段,如微博内容、微博创建时间、微博作者等。 #微博内容 text_list 中的数据采用正则表达式进行数据清洗,去掉 HTML 标签。 #其中 $..mblog.text 表示从 JSON 数据中查找键名为 mblog.text 的字段,$ 表示从根部开始查找,.. 表示在 JSON 数据中递归查找键名(或键值)为 mblog.text 的所有字段。接着,像操作列表一样访问这些字段,对于其中的每个元素,可以使用正则表达式将其内容中的 HTML 标签进行去除。 text_list=jsonpath(cards,'$..mblog.text') #提取 cards 中所需的字段。 #正则表达式数据清洗 # re.S:该标志表示在任何模式下都匹配所有字符,包括换行符。这样,正则表达式可以匹配多行的 HTML 代码。 dr=re.compile(r'<[^>]+>',re.S) #这是一个正则表达式,用来匹配 HTML 标签并去除。 #<[^>]+>:匹配以 < 开头,以 > 结尾的字符串。其中 [^>] 表示除了 > 之外的任意字符,+ 表示至少匹配一次,< 和 > 分别表示 HTML 标签的开头和结尾。 text2_list=[] #查看它所包含的微博内容列表。查看是否成功获取到了微博内容,并且检查其中是否存在无效数据,以方便进行后续的处理和清洗 print('text_list is:') print(text_list) #如果 text_list 为空,则跳过后续处理,继续执行下一个搜索结果的处理。 if not text_list: continue #如果 text_list 不为空,且类型是列表,且列表长度大于 0,说明获取到的数据是有效数据 if type(text_list)==list and len(text_list)>0: # 如果为获取到微博内容,进入下一轮循环 # 对每个有效的微博内容进行正则表达式处理和存储操作 # 首先,使用 for 循环遍历 text_list 列表中的每个元素 text。 # 然后,对于每个元素,使用正则表达式 dr 进行匹配,去除其中的 HTML 标签,并将处理后的微博内容存储到 text2_list 中。 # 最后,使用 print() 函数打印处理后的微博内容,方便调试和查看结果。 for text in text_list: text2=dr.sub('',text) #正则表达式提取微博内容 print(text2) text2_list.append(text2) #将处理后的微博内容添加到 text2_list 中,方便后续的处理和分析。 # 微博创建时间 time_list=jsonpath(cards,'$..mblog.created_at') time_list=[trans_time(v_str=i) for i in time_list] # 微博作者 author_list=jsonpath(cards,'$..mblog.user.screen_name') # 微博id id_list=jsonpath(cards,'$..mblog.id') # 微博bid bid_list=jsonpath(cards,'$..mblog.bid') # 转发数 reposts_count_list=jsonpath(cards,'$..mblog.reposts_count')#$表示根节点;..表示递归搜索子孙节点,mblog表示cards中的每一项中的mblog字段 # 评论数 comments_count_list=jsonpath(cards,'$..mblog.comments_count') # 点赞数 attitudes_count_list=jsonpath(cards,'$..mblog.attitudes_count') status_list=jsonpath(cards,'$..mblog.status_province') '''由于有些微博的省份/城市信息没有该字段信息,因此在抓取时可能会出现缺失值。 为保证所有的列表长度一致,这里使用了一个判断,判断 status_list 列表的长度是否小于 id_list 列表的长度。 如果长度不一致,则在 status_list 后面添加相应数量的 None 值,以保证所有列表长度一致。''' if len(status_list) < len(id_list): status_list += [None] * (len(id_list) - len(status_list)) df=pd.DataFrame( {'页码':[page]*len(id_list), '微博id':id_list, '微博bid':bid_list, '微博作者':author_list, '发布时间': time_list, '微博内容':text2_list, '转发数':reposts_count_list, '评论数':comments_count_list, '点赞数': attitudes_count_list, 'IP属地': status_list, } ) # 表头 # '''如果输出文件已经存在,则设置 header=None,表明输出文件已经含有字段名; # 否则设置 header 为包含字段名的列表 ['页码','微博id','微博bid','微博作者','发布时间','微博内容','转发数', '评论数','点赞数','IP属地']''' if os.path.exists(w_weibo_file): header=None else: header=['页码','微博id','微博bid','微博作者','发布时间','微博内容','转发数', '评论数','点赞数','IP属地'] # 保存到csv文件 # w_weibo_file:输出文件的路径和名称。 # mode='a+':输出文件的打开模式,'a+' 表示以追加模式(append mode)打开文件,即在文件末尾添加新的内容。 df.to_csv(w_weibo_file,mode='a+',index=False,header=header,encoding='utf_8_sig') print('csv保存成功:{}'.format(w_weibo_file)) # 主函数 if __name__== '__main__': max_search_page=80 # 爬取前几页 search_keyword='淄博烧烤' # 爬取关键字 w_weibo_file='微博清单_{}_前{}页.csv'.format(search_keyword,max_search_page) #保存文件名 if os.path.exists(w_weibo_file): # 如果csv文件存在,先删除之前的文件 os.remove(w_weibo_file) print('微博清单存在,已删除:{}'.format(w_weibo_file)) # 调用爬取微博函数 get_weibo_list(s_keyword=search_keyword,w_max_page=max_search_page)
运行时输出的结果:

生成的文件:(728行,10列)
import pandas as pd filename = '微博清单_淄博烧烤_前80页.csv' #指定读入的文件名 df = pd.read_csv(filename) df #显示前行数据

2.对数据进行清洗和处理
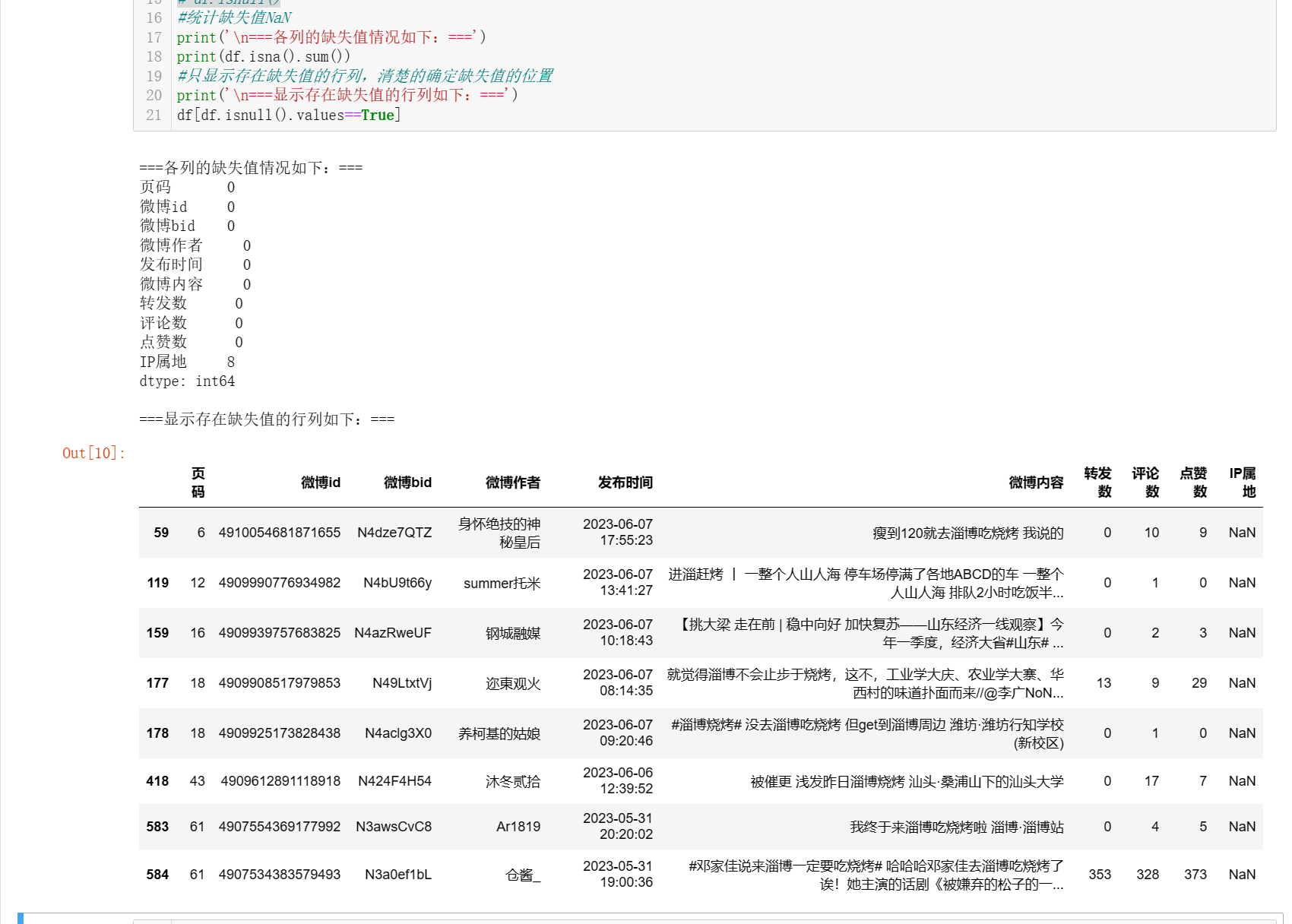
#统计各列的空值情况 print('\n===各列的空值情况如下:===') print(df.isnull().sum()) # 查询空值 df.isnull()

#统计缺失值NaN print('\n===各列的缺失值情况如下:===') print(df.isna().sum()) #只显示存在缺失值的行列,清楚的确定缺失值的位置 print('\n===显示存在缺失值的行列如下:===') df[df.isnull().values==True]
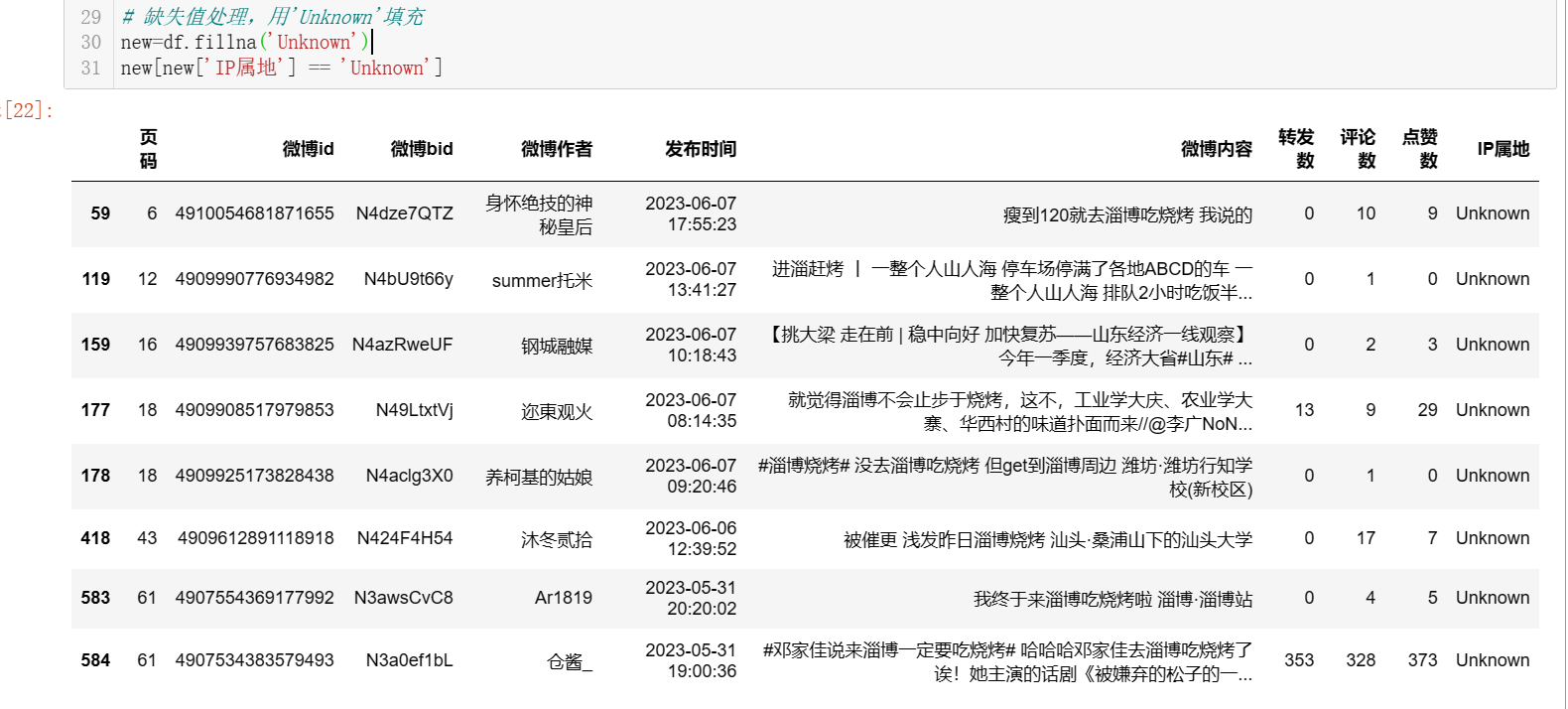
# 缺失值处理,用'Unknown'填充 new=df.fillna('Unknown') new[new['IP属地'] == 'Unknown']
# 查找重复值
print('\n===显示存在重复值的行列如下:===')
new[new.duplicated().values==True]
由结果得,无重复值
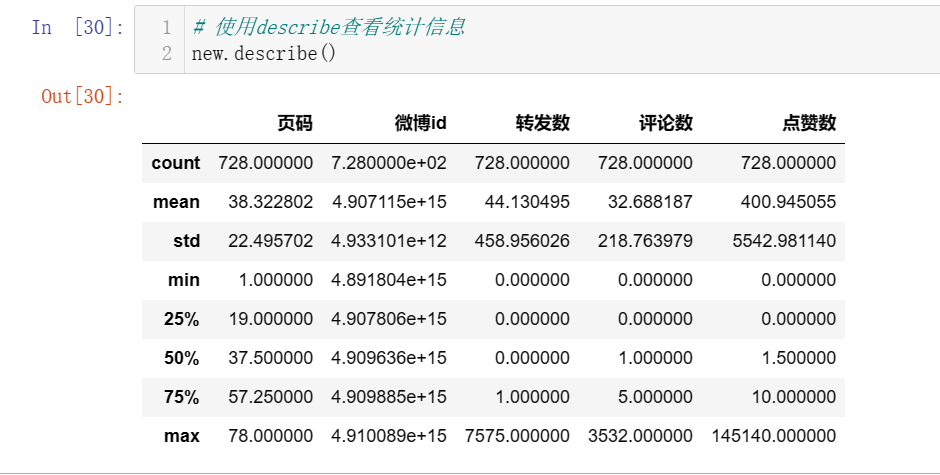
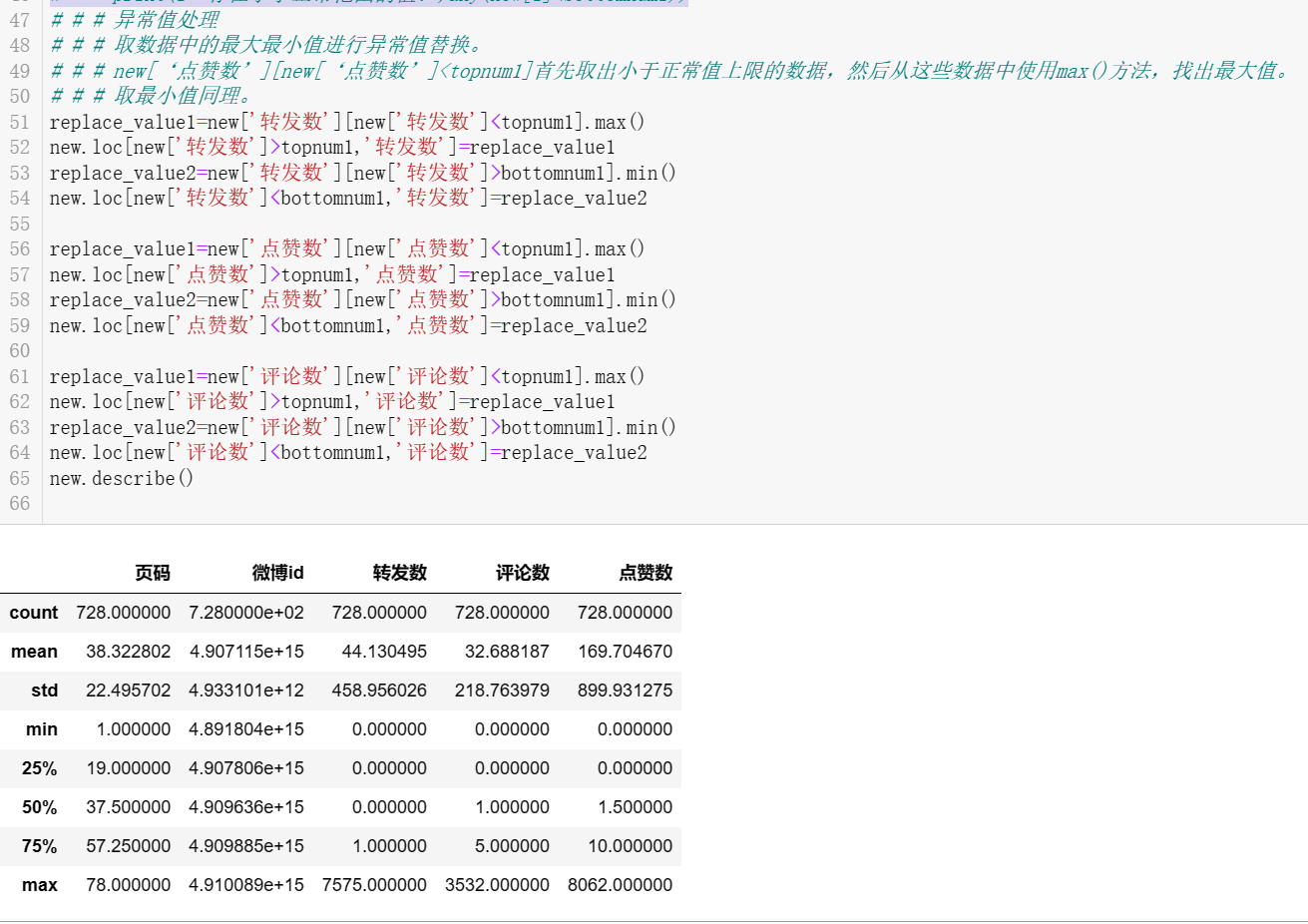
# 使用describe查看统计信息
print(new.describe())
# 异常值判断 # 使用均值和标准差进行判断 # mean 为数据的均值 # std 为数据的标准差 # 数据的正常范围为 [mean-2 × std,mean+2 × std for i in ['转发数','评论数','点赞数']: mean=new[i].mean() std = new[i].std() topnum1 =mean+2*std #上限 bottomnum1 = mean-2*std #下限 print(i+"的正常值的范围:[{b},{t}]".format(t=topnum1,b=bottomnum1)) print(i+"存在超出正常范围的值:",any(new[i]>topnum1)) print(i+"存在小于正常范围的值:",any(new[i]<bottomnum1))
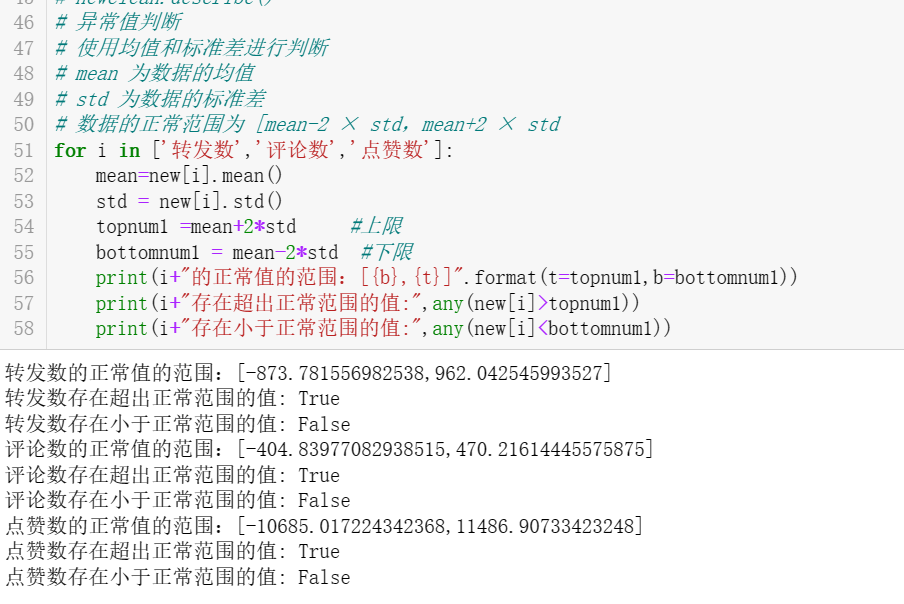
由结果可知,转发数、评论数、点赞数都存在超出正常范围的值
# 异常值处理 # 取数据中的最大最小值进行异常值替换。 # new[‘点赞数’][new[‘点赞数’]<topnum1]首先取出小于正常值上限的数据,然后从这些数据中使用max()方法,找出最大值。 # 取最小值同理。 replace_value1=new['转发数'][new['转发数']<topnum1].max() new.loc[new['转发数']>topnum1,'转发数']=replace_value1 replace_value2=new['转发数'][new['转发数']>bottomnum1].min() new.loc[new['转发数']<bottomnum1,'转发数']=replace_value2 replace_value1=new['点赞数'][new['点赞数']<topnum1].max() new.loc[new['点赞数']>topnum1,'点赞数']=replace_value1 replace_value2=new['点赞数'][new['点赞数']>bottomnum1].min() new.loc[new['点赞数']<bottomnum1,'点赞数']=replace_value2 replace_value1=new['评论数'][new['评论数']<topnum1].max() new.loc[new['评论数']>topnum1,'评论数']=replace_value1 replace_value2=new['评论数'][new['评论数']>bottomnum1].min() new.loc[new['评论数']<bottomnum1,'评论数']=replace_value2 new.describe()
# 再次保存文件 new.to_csv('cleanfile.csv',index=False,encoding='utf_8_sig') print('数据清洗成功')
数据清洗和处理的完整代码:
# 数据清洗 import pandas as pd filename = '微博清单_淄博烧烤_前80页.csv' #指定读入的文件名 df = pd.read_csv(filename) print(df.head(10)) #显示前10行数据 # 查询空值 print(df.isnull()) #统计各列的空值情况 print('\n===各列的空值情况如下:===') print(df.isnull().sum()) # #统计缺失值NaN print('\n===各列的缺失值情况如下:===') print(df.isna().sum()) #只显示存在缺失值的行列,清楚的确定缺失值的位置 print('\n===显示存在缺失值的行列如下:===') df[df.isnull().values==True].head(11) # 缺失值处理,用'Unknown'填充 new=df.fillna('Unknown') new[new['IP属地'] == 'Unknown'] # 查找重复值 print('\n===显示存在重复值的行列如下:===') new[new.duplicated().values==True] #使用describe查看统计信息 print(new.describe()) # 异常值判断 # 使用均值和标准差进行判断 # mean 为数据的均值 # std 为数据的标准差 # 数据的正常范围为 [mean-2 × std,mean+2 × std for i in ['转发数','评论数','点赞数']: mean=new[i].mean() std = new[i].std() topnum1 =mean+2*std #上限 bottomnum1 = mean-2*std #下限 print(i+"的正常值的范围:[{b},{t}]".format(t=topnum1,b=bottomnum1)) print(i+"存在超出正常范围的值:",any(new[i]>topnum1)) print(i+"存在小于正常范围的值:",any(new[i]<bottomnum1)) # 异常值处理 # 取数据中的最大最小值进行异常值替换。 # new[‘点赞数’][new[‘点赞数’]<topnum1]首先取出小于正常值上限的数据,然后从这些数据中使用max()方法,找出最大值。 # 取最小值同理。 replace_value1=new['转发数'][new['转发数']<topnum1].max() new.loc[new['转发数']>topnum1,'转发数']=replace_value1 replace_value2=new['转发数'][new['转发数']>bottomnum1].min() new.loc[new['转发数']<bottomnum1,'转发数']=replace_value2 replace_value1=new['点赞数'][new['点赞数']<topnum1].max() new.loc[new['点赞数']>topnum1,'点赞数']=replace_value1 replace_value2=new['点赞数'][new['点赞数']>bottomnum1].min() new.loc[new['点赞数']<bottomnum1,'点赞数']=replace_value2 replace_value1=new['评论数'][new['评论数']<topnum1].max() new.loc[new['评论数']>topnum1,'评论数']=replace_value1 replace_value2=new['评论数'][new['评论数']>bottomnum1].min() new.loc[new['评论数']<bottomnum1,'评论数']=replace_value2 new.describe() # 再次保存文件 new.to_csv('cleanfile.csv',index=False,encoding='utf_8_sig') print('数据清洗成功')
3.文本分析(可选):jieba 分词、wordcloud 的分词可视化
# 打开清洗后的数据文件'cleanfile.csv'
import pandas as pd df_new = pd.read_csv('cleanfile.csv')
df_new

#jieba分词 import re #正则表达式模块 re import jieba #jieba是一款中文分词库 import emoji #emoji是一个用于处理表情符号的库 comments = df_new['微博内容'].values.astype(str) #将微博内容取出,存储在一个名为comments的数组中 # print(comments) #查看微博内容 # 'hit_stopwords.txt'为停用词表(本代码用的是哈尔滨工业大学停用词表)导入了停用词表, # 将停用词表中的每个单词存储到列表stop_words中,并增加了一些手动定义的停用词,去除无意义的词语。 with open('hit_stopwords.txt','r',encoding='utf8') as f: stop_words=f.readlines() stop_words = [i.strip() for i in stop_words] stop_words.extend({'nan','还','不','不是','人','都','去','很','全文','没有','没','真的','现在','微博','视频','2023','徐明浩'}) # 分词并去掉停用词 cut_words_list = [] for comment in comments: comment= re.sub( r'【|】', "", comment) # 去除 【xx】 comment=re.sub(r'#\w+ ?', "", comment) #去除话题引用 comment=emoji.replace_emoji(comment, replace="") #去除表情包 #使用jieba库的cut()方法对文本进行切词,将切好的词语存储到cut_words变量中。cut_all=False表示使用精确模式分词 cut_words = jieba.cut(comment, cut_all=False) # if i not in stop_words,表示只有当某个词语不在停用词表stop_words中时才将其加入到cut_words_list中去,使得cut_words_list中的每个元素都是一个非停用词且有实际含义的词语。 cut_words_list.extend([i for i in cut_words if i not in stop_words]) print(cut_words_list) # 输出分词结果列表

# 统计关键词的出现次数 from collections import Counter # collections模块中的Counter类,用于统计每个元素出现的次数。 # Counter(cut_words_list)统计出cut_words_list中每个元素(即分词后的词语)出现的次数,并返回一个字典(Counter对象),该字典的键为每个词语,值为该词语出现的次数; word_counts = Counter(cut_words_list) words = list(word_counts.keys()) counts = list(word_counts.values()) data = list(zip(words, counts)) # zip(words,counts)将words和counts打包成一个元组列表; print(data)
data_sort = sorted(data, key=lambda x: x[1], reverse=True)[:200]#选取词语出现次数排名前200的元素 from pyecharts.charts import WordCloud #导入绘制词云图的WordCloud类 from pyecharts.globals import SymbolType #导入符号类型SymbolType from pyecharts import options as opts #导入全局设置options模块,简写为opts wc = WordCloud(init_opts=opts.InitOpts(width='1000px', height='500px')) #函数生成一个词云对象wc,就是一张空白的白色画布 wc.add("", data_sort, word_size_range=[20, 100] ,shape='diamond') wc.set_global_opts(title_opts=opts.TitleOpts(title="淄博烧烤词云图")) #设置词云图的全局属性,设置了标题为“淄博烧烤词云图” wc.render_notebook() #将生成的词云图渲染到notebook中。

# jieba分词,生成词云的完整代码 import jieba #jieba是一款中文分词库 import emoji #emoji是一个用于处理表情符号的库 from pyecharts.charts import WordCloud #导入绘制词云图的WordCloud类 from pyecharts.globals import SymbolType #导入符号类型SymbolType from pyecharts import options as opts #导入全局设置options模块,简写为opts from collections import Counter # collections模块中的Counter类,用于统计每个元素出现的次数。 import pandas as pd # 打开清洗后的数据文件'cleanfile.csv' df_new = pd.read_csv('cleanfile.csv') df_new comments = df_new['微博内容'].values.astype(str) #将微博内容取出,存储在一个名为comments的数组中 # print(comments) #查看微博内容 # 'hit_stopwords.txt'为停用词表(本代码用的是哈尔滨工业大学停用词表)导入了停用词表, # 将停用词表中的每个单词存储到列表stop_words中,并增加了一些手动定义的停用词,去除无意义的词语 with open('hit_stopwords.txt','r',encoding='utf8') as f: stop_words=f.readlines() stop_words = [i.strip() for i in stop_words] stop_words.extend({'nan','还','不','不是','人','都','去','很','全文','没有','没','真的','现在','微博','视频','2023','徐明浩'}) # 分词并去掉停用词 cut_words_list = [] for comment in comments: comment= re.sub( r'【|】', "", comment) # 去除 【xx】 comment=re.sub(r'#\w+ ?', "", comment) #去除话题引用 comment=emoji.replace_emoji(comment, replace="") #去除表情包 #使用jieba库的cut()方法对文本进行切词,将切好的词语存储到cut_words变量中。cut_all=False表示使用精确模式分词 cut_words = jieba.cut(comment, cut_all=False) # if i not in stop_words,表示只有当某个词语不在停用词表stop_words中时才将其加入到cut_words_list中去,使得cut_words_list中的每个元素都是一个非停用词且有实际含义的词语 cut_words_list.extend([i for i in cut_words if i not in stop_words]) print(cut_words_list) # 输出分词结果列表 # 统计关键词的出现次数 # Counter(cut_words_list)统计出cut_words_list中每个元素(即分词后的词语)出现的次数,并返回一个字典(Counter对象),该字典的键为每个词语,值为该词语出现的次数 word_counts = Counter(cut_words_list) words = list(word_counts.keys()) counts = list(word_counts.values()) data = list(zip(words, counts)) # zip(words,counts)将words和counts打包成一个元组列表 print(data) data_sort = sorted(data, key=lambda x: x[1], reverse=True)[:200]#选取词语出现次数排名前200的元素 wc = WordCloud(init_opts=opts.InitOpts(width='1000px', height='500px')) #函数生成一个词云对象wc,就是一张空白的白色画布 wc.add("", data_sort, word_size_range=[20, 100] ,shape='diamond') wc.set_global_opts(title_opts=opts.TitleOpts(title="淄博烧烤词云图")) #设置词云图的全局属性,设置了标题为“淄博烧烤词云图” wc.render_notebook() #将生成的词云图渲染到notebook中
4.数据分析与可视化(例如:数据柱形图、直方图、散点图、盒图、分布图)
# 打开清洗后的数据文件'cleanfile.csv' import panda df_new = pd.read_csv('cleanfile.csv') df_new import matplotlib.pyplot as plt #导入matplotlib库中的pyplot模块,pyplot是用于创建图表的主要函数 df_new['IP属地'].value_counts().nlargest(10).plot.bar(figsize=(14,6),fontsize= 13) plt.title('IP属地前10统计(柱形图)',fontsize= 20) plt.xlabel('省份',fontsize= 16) plt.xticks(rotation=0) #设置X轴刻度标签的旋转角度。xticks是指X轴上的刻度,rotation参数指定刻度标签的旋转度数,0表示不旋转。若刻度标签内容过长,旋转角度可以调整为其他角度,以便更好地展示文本。 plt.ylabel('数量',fontsize= 16) plt.legend() #显示标签 plt.rcParams['font.sans-serif'] = ['SimHei'] #设置显示中文字符的字体 plt.grid() #显示网格线 plt.show() #s显示图形,
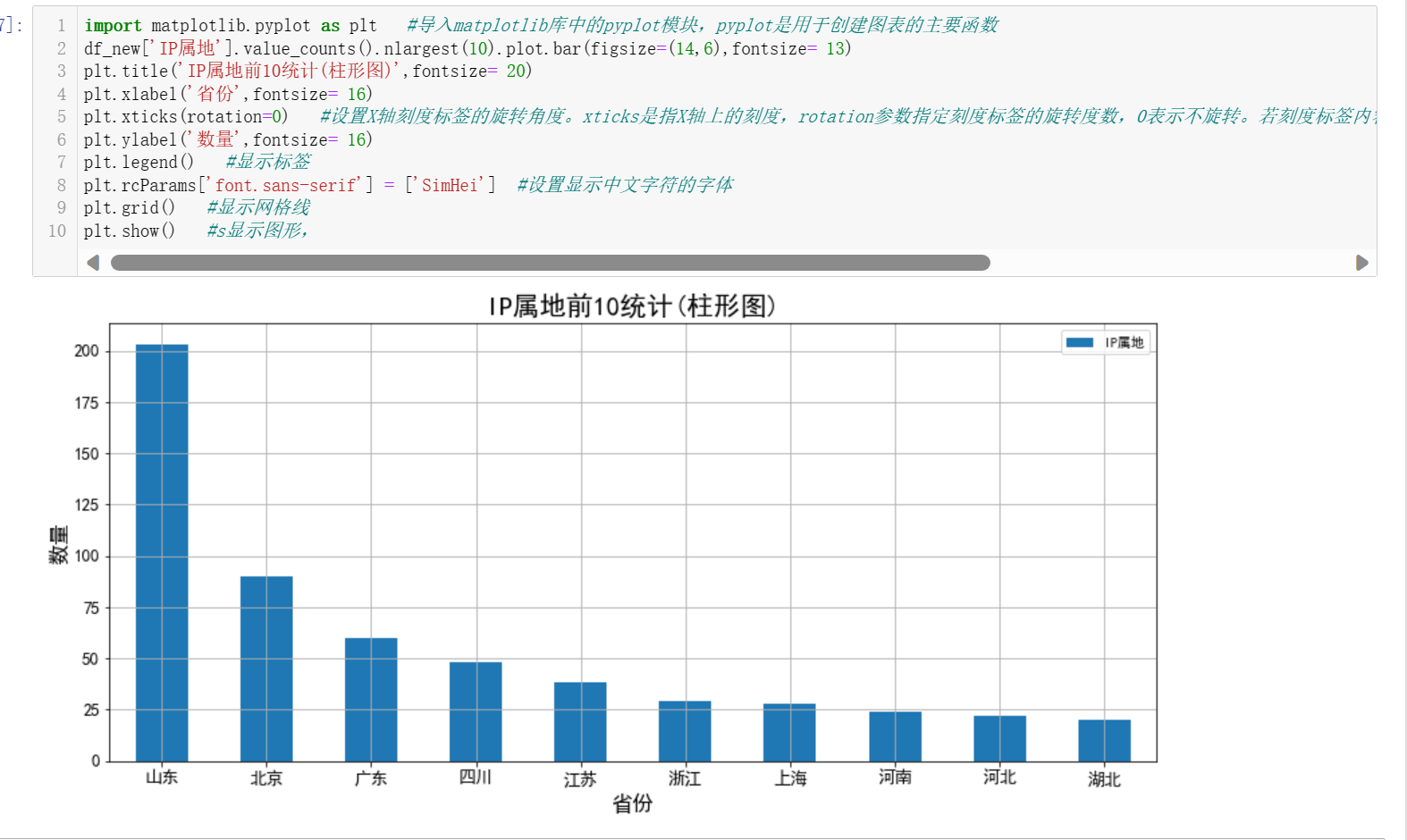
由此可以得出淄博烧烤在山东的影响力最大,其次为北京,再次为广东。可能是因为淄博烧烤在山东比较有名气和口碑,并且山东是淄博烧烤所在地,因此在该地区的微博讨论量最大。而在北京和广东地区,淄博烧烤也受到了不少关注。
import matplotlib.pyplot as plt import matplotlib.dates as mdates #matplotlib库中的dates模块。dates模块主要用于处理日期格式 df_new['发布时间2']=pd.to_datetime(df_new['发布时间']) #将 df_new 中的 发布时间 字段转换成日期格式 df_new['发布日期']=df_new['发布时间2'].dt.date #新增一列 发布日期 作为日期数据 df_new_cm_date=df_new['发布日期'].value_counts() #然后统计每个日期的帖子数量,将其赋给 df_new_cm_date df_new_cm_date.colums=['发布日期','发布帖子数量'] df_new_cm_date.plot(x='发布日期',y='发布帖子数量',figsize=(14,6)) #绘制折线图 plt.title('发布帖子数量统计图(折线图)') plt.grid() plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d')) plt.show()
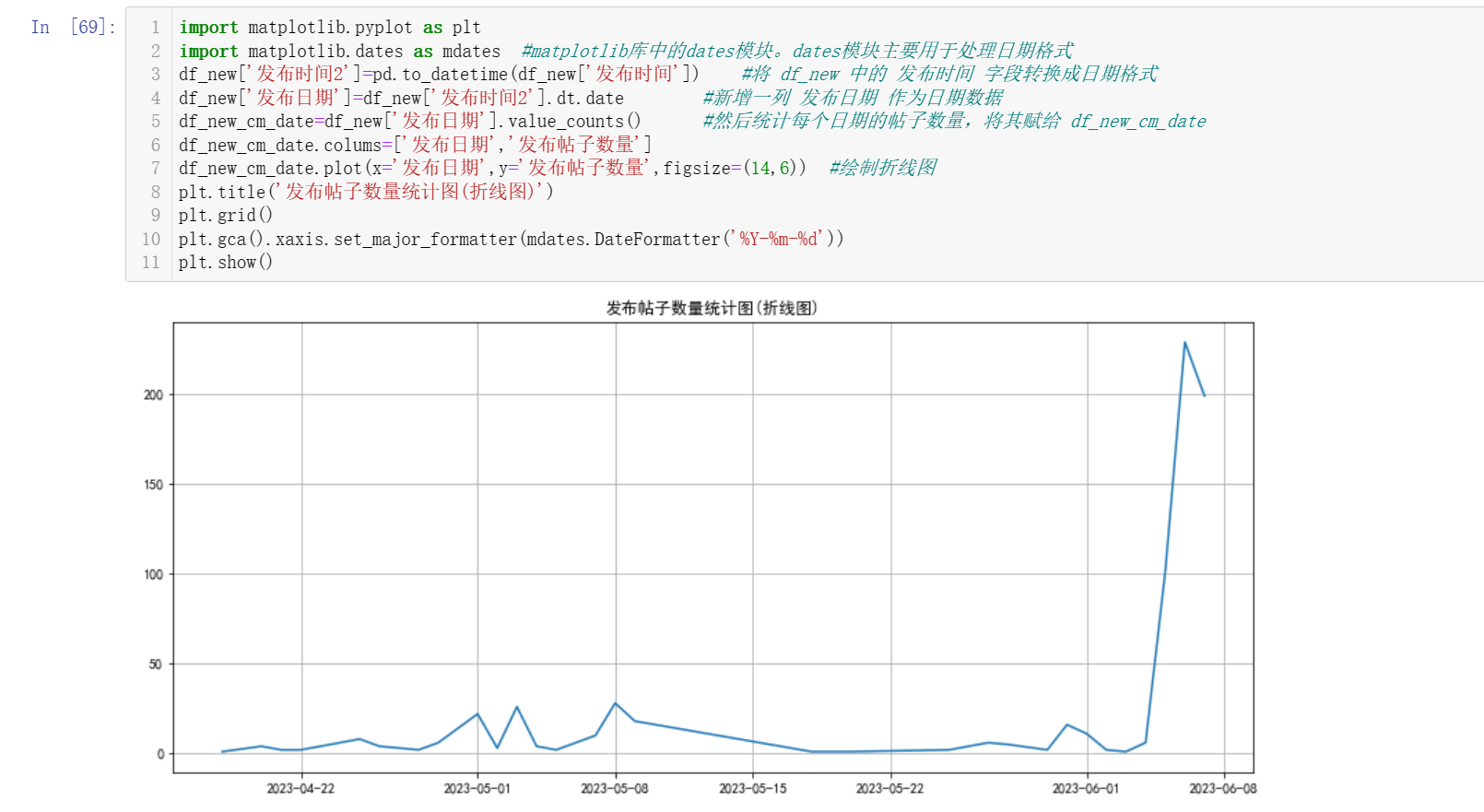
由该折线图可以得出,在2023年4月至2023年6月期间,淄博烧烤的发布帖子数量呈现波动状态。具体来说,发布帖子数量在4月初开始逐渐上升,达到一个高峰值后开始下降,然后在5月中旬起开始逐渐上升,6月初达到新的高峰值,随后开始下降。若处于上升阶段,可能是因为在这段时间内,淄博烧烤在社交媒体上的曝光度有所提升,吸引了更多用户的关注和讨论。若处于下降阶段可能因为天气的影响。比如天气逐渐变热等因素的影响。波动的变化可能受到多种因素的影响,比如节假日、季节变化、社交平台曝光率等。
import matplotlib.pyplot as plt df2=df_new[df_new['点赞数']<=10] #因为大部分点赞数小于10,所以取出小于10的画图 df_comment=df2['点赞数'].values.tolist() #提取其中点赞数字段的值,并将其转化为列表类型。tolist()方法则将NumPy数组转换成Python列表 plt.figure(figsize=(14,6)) plt.boxplot(df_comment,labels=['点赞数分析'],) #绘制盒图 plt.ylabel('数量') plt.title('点赞数分布(盒图)') plt.rcParams['font.sans-serif'] = ['SimHei'] #设置显示中文字符的字体 plt.grid( axis='y') plt.show()

根据箱线图的特性,箱线图的中位数位于0到2之间,这意味着有一半的帖子点赞数在0到2之间,另一半的帖子点赞数在2以上。箱体的上边沿和下边沿也很接近,这说明数据比较集中,没有太大的波动。少数点赞数较高的离群值,这说明有一部分的数据点数量超过10个赞,而这些数据没有被包括在箱线图中。少数点赞数较高的离群值,可能说明有一些帖子的内容可能非常有趣、新颖或者有深度,受到了大量用户的点赞,从而产生了较高的点赞数。又或者是因社交影响力的因素, 一些微博号拥有很高的粉丝量或影响力,其发表的相关帖子会吸引大量用户互动,从而产生较高的点赞数。
import matplotlib.pyplot as plt df2=df_new[df_new['评论数']<=10] df_comment=df2['评论数'].values.tolist() plt.figure(figsize=(14,6)) plt.boxplot(df_comment,labels=['评论数分析'],) plt.ylabel('数量') plt.title('评论数分布—箱线图') plt.rcParams['font.sans-serif'] = ['SimHei'] #设置显示中文字符的字体 plt.grid( axis='y') plt.show()

由此可以得出以下结论:该微博帖子的评论数较少,大多数评论数量为0。有一部分的数据点数量超过10个评论数,因此这些数据没有被包括在箱线图中。箱线图的中位数为0,这意味着有一半的帖子评论数为0,另一半的帖子评论数为1或更多。上四分位线在2,这说明存在较多评论数较高的帖子,超过了中位数,并且集中在2个评论及以上。
5.根据数据之间的关系,分析两个变量之间的相关系数,画出散点图,并建立变 量之间的回归方程(一元或多元)。
import pandas as pd df = pd.read_csv('cleanfile.csv') new_data=df.drop(labels=['微博id','微博bid','微博内容','IP属地','微博作者','发布时间','页码'],axis=1) new_data.corr()#corr()函数可以计算DataFrame中每对列之间的相关性,默认使用皮尔逊相关系数来衡量相关性的强度,相关系数的取值范围为 [-1 ,1]。具体来说,相关系数为1表示完全正相关,0表示无相关性,-1表示完全负相关。

由此,可得评论数、点赞数、转发数三者之间两两都呈正相关性,这意味着当其中一个变量增加时,其他两个变量也应该随之增加。这种关系表明了社交媒体上用户对某篇文章或帖子的兴趣程度,因为用户在评论、点赞和转发一篇内容时通常表示对这篇内容的喜爱或关注。在某些情况下,这种关系也可能反映了内容本身的质量,因为更好的内容通常会受到更多的关注和交互。因此,评论数、点赞数和转发数在某种程度上可以用来评估淄博烧烤的受欢迎程度和大众对淄博烧烤的评价。
# 因为评论数、点赞数、转发数的数据大部分集中在0-20,所以取0-20之间的400个数据进行相关性分析 import pandas as pd df1=[] #建立df1为一个空表,用来存放100个评论数为0-20之间的数据 for i in df['评论数']: if i>=0 and i<=20: df1.append(i) if len(df1)==400: break df1 = pd.DataFrame(df1,columns = ['评论数']) #将df1列表转换为dataframe print(df1.head(50)) df2=[] #建立df2为一个空表,用来存放100个点赞数为0-20之间的数据 for i in df['点赞数']: if i>=0 and i<=20: df2.append(i) if len(df2)==400: break df2= pd.DataFrame(df2,columns = ['点赞数']) #将df2列表转换为dataframe print(df2.head(50)) df3=[] #建立df3为一个空表,用来存放100个转发数为0-20之间的数据 for i in df['转发数']: if (i>=0)and (i<=20): df3.append(i) if len(df3)==400: break df3 = pd.DataFrame(df3, columns = ['转发数']) #将df3列表转换为dataframe print(df3.head(50))
# 评论数与点赞数的散点图 import matplotlib.pyplot as plt plt.scatter(df1['评论数'], df2['点赞数']) plt.xlabel('评论数') plt.ylabel('点赞数') plt.show()
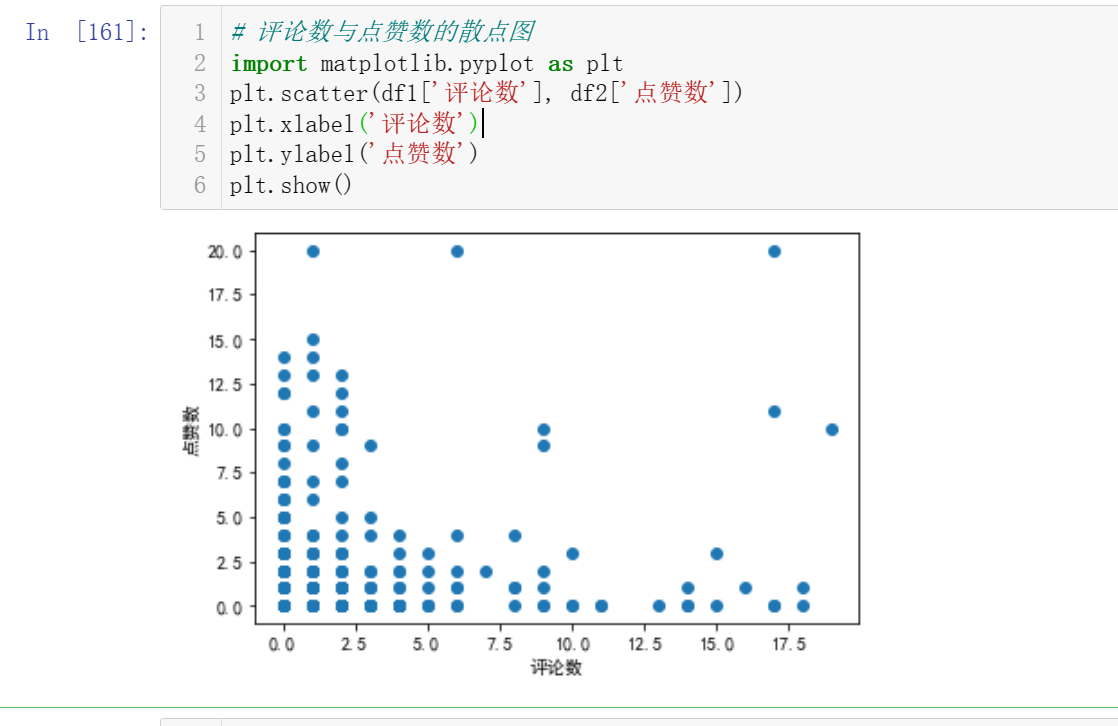
因为评论数、点赞数大部分为0,散点图呈现的效果不佳。
#评论数与点赞数的一元回归方程 from sklearn.linear_model import LinearRegression # 将评论数和点赞数分别作为自变量和因变量 X = df1[['评论数']] Y = df2 ['点赞数'] # 建立回归模型 model = LinearRegression() #使用LinearRegression()函数创建一个线性回归模型对象。 model.fit(X, Y) # 输出回归方程 print('y = %.2fx + %.2f' % (model.coef_, model.intercept_))

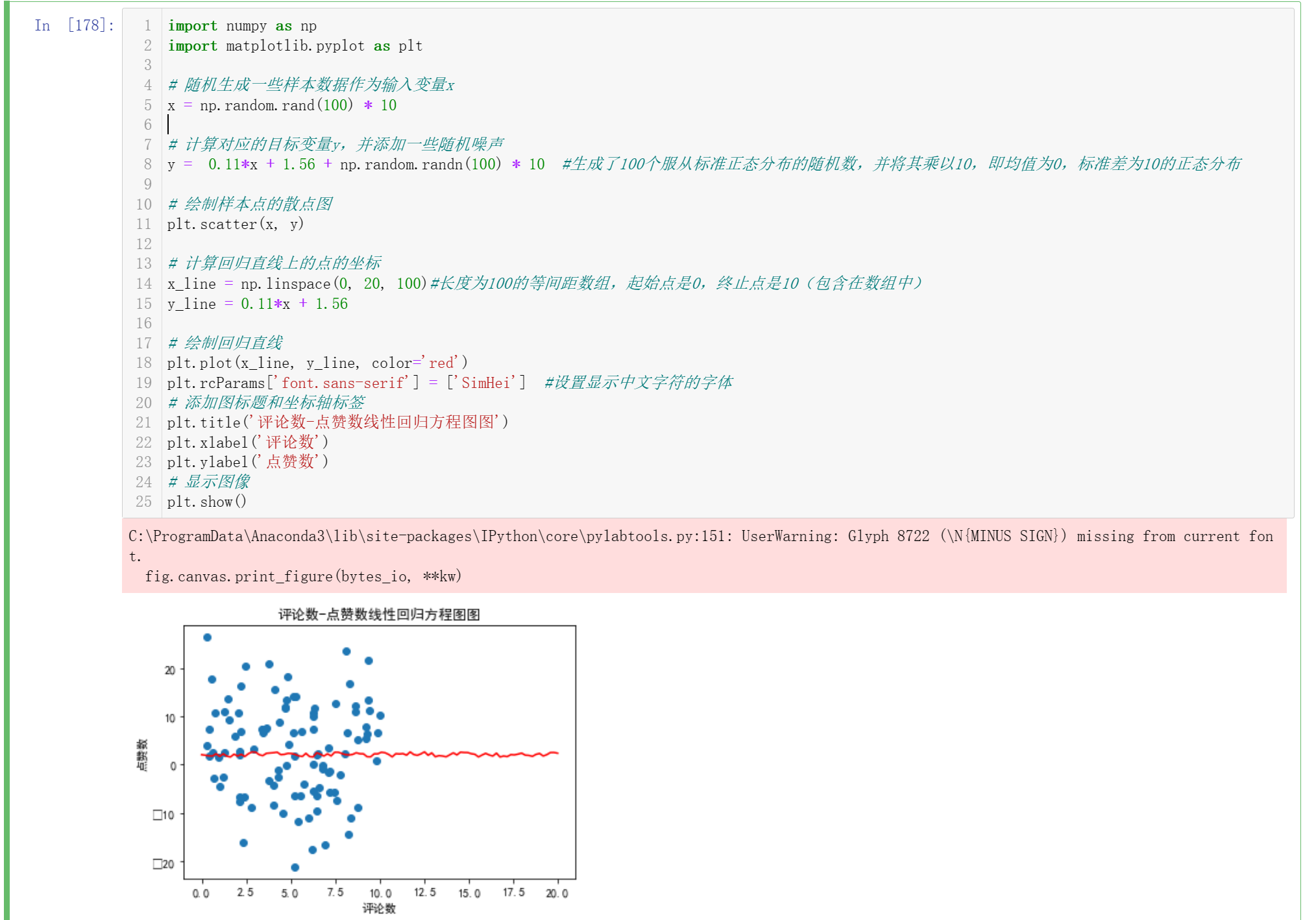
该结果表明,微博上的评论数与点赞数之间可能存在正相关关系,这意味着评论数越多,点赞数也可能会越多。因此,增加微博上的评论数量有可能提高微博的曝光度和影响力。具体来说,根据回归方程 y = 0.11x + 1.56,当微博上的评论数(自变量 x)每增加1时,微博上的点赞数(因变量 y)将平均增加0.11。此外,当微博上的评论数为0时,预测的点赞数为1.56。
import numpy as np import matplotlib.pyplot as plt # 随机生成一些样本数据作为输入变量x x = np.random.rand(100) * 10 # 计算对应的目标变量y,并添加一些随机噪声 y = 0.11*x + 1.56 + np.random.randn(100) * 10 #生成了100个服从标准正态分布的随机数,并将其乘以10,即均值为0,标准差为10的正态分布 # 绘制样本点的散点图 plt.scatter(x, y) # 计算回归直线上的点的坐标 x_line = np.linspace(0, 20, 100)#长度为100的等间距数组,起始点是0,终止点是10(包含在数组中) y_line = 0.11*x + 1.56 # 绘制回归直线 plt.plot(x_line, y_line, color='red') plt.rcParams['font.sans-serif'] = ['SimHei'] #设置显示中文字符的字体 # 添加图标题和坐标轴标签 plt.title('评论数-点赞数线性回归方程图图') plt.xlabel('评论数') plt.ylabel('点赞数') # 显示图像 plt.show()
6.数据持久化
# 将清洗完的数据再次保存文件为'cleanfile.csv'
new.to_csv('cleanfile.csv',index=False,encoding='utf_8_sig')
以及将分析结果的图保存起来。
7.将以上各部分的代码汇总,附上完整程序代码。
1 #######1.数据爬取与采集 2 import os #操作文件、获取环境变量等。 3 import re #正则表达式提取文本,,可以用来匹配、查找和替换文本。 4 from jsonpath import jsonpath #解析json数据 5 import requests #发送请求,用于发送HTTP请求和处理HTTP响应。 6 import pandas as pd #存取csv文件 7 import datetime #转换时间 8 9 # 转换GMT时间为标准格式 10 def trans_time(v_str): 11 GMT_FORMAT='%a %b %d %H:%M:%S +0800 %Y' 12 timeArray = datetime.datetime.strptime(v_str ,GMT_FORMAT) 13 ret_time = timeArray.strftime("%Y-%m-%d %H:%M:%S") 14 return ret_time 15 16 # 爬取微博内容列表函数 17 # s_keyword:关键字 18 # w_max_page:爬取前几页 19 # return:None 20 21 def get_weibo_list(s_keyword,w_max_page): 22 #请求开头 23 headers={ 24 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/113.0.0.0 Safari/537.36 Edg/113.0.1774.57", 25 "accept": "application/json, text/plain, */*", 26 "accept-encoding": "gzip, deflate, br", 27 } 28 # 循环爬取前w_max_page 页的微博内容。对于每一页,先构造请求地址和请求参数,然后发送请求并获取响应。 29 for page in range(1,w_max_page+1): 30 print('==开始爬取第{}页微博=='.format(page)) 31 #请求地址 32 url='https://m.weibo.cn/api/container/getIndex?containerid=100103type=1&q=淄博烧烤&page_type=searchall' 33 # 请求参数 34 params={ 35 "containerid":"100103type=1&q=淄博烧烤".format(s_keyword), 36 "page_type":"searchall", 37 "page":page 38 } 39 #发送请求 40 r=requests.get(url,headers=headers,params=params) 41 #r.status_code 是 HTTP 响应状态码,表示服务器返回的请求处理结果。如果状态码为 200,则表示请求成功,否则表示请求失败 42 print(r.status_code) 43 # 解析json数据 44 #解析 HTTP 响应中的 JSON 数据,并提取出关键字 cards 所对应的值,即搜索结果集合。 45 # 其中,r.json() 将响应解析成 JSON 格式的对象(Python 字典);r.json()["data"] 取出键为 data 的字典,其中包含了搜索结果的数据; 46 cards=r.json()["data"]["cards"]#取出了 cards 字段,即淄博烧烤搜索结果的查询结果页信息。 47 # 微博内容 48 #解析响应,并使用 jsonpath 库从响应的 JSON 数据中提取微博的相关字段,如微博内容、微博创建时间、微博作者等。 49 #微博内容 text_list 中的数据采用正则表达式进行数据清洗,去掉 HTML 标签。 50 #其中 $..mblog.text 表示从 JSON 数据中查找键名为 mblog.text 的字段,$ 表示从根部开始查找,.. 表示在 JSON 数据中递归查找键名(或键值)为 mblog.text 的所有字段。接着,像操作列表一样访问这些字段,对于其中的每个元素,可以使用正则表达式将其内容中的 HTML 标签进行去除。 51 text_list=jsonpath(cards,'$..mblog.text') #提取 cards 中所需的字段。 52 #正则表达式数据清洗 53 # re.S:该标志表示在任何模式下都匹配所有字符,包括换行符。这样,正则表达式可以匹配多行的 HTML 代码。 54 dr=re.compile(r'<[^>]+>',re.S) #这是一个正则表达式,用来匹配 HTML 标签并去除。 55 #<[^>]+>:匹配以 < 开头,以 > 结尾的字符串。其中 [^>] 表示除了 > 之外的任意字符,+ 表示至少匹配一次,< 和 > 分别表示 HTML 标签的开头和结尾。 56 text2_list=[] 57 #查看它所包含的微博内容列表。查看是否成功获取到了微博内容,并且检查其中是否存在无效数据,以方便进行后续的处理和清洗 58 print('text_list is:') 59 print(text_list) 60 #如果 text_list 为空,则跳过后续处理,继续执行下一个搜索结果的处理。 61 if not text_list: 62 continue 63 #如果 text_list 不为空,且类型是列表,且列表长度大于 0,说明获取到的数据是有效数据 64 if type(text_list)==list and len(text_list)>0: 65 66 # 如果为获取到微博内容,进入下一轮循环 67 # 对每个有效的微博内容进行正则表达式处理和存储操作 68 # 首先,使用 for 循环遍历 text_list 列表中的每个元素 text。 69 # 然后,对于每个元素,使用正则表达式 dr 进行匹配,去除其中的 HTML 标签,并将处理后的微博内容存储到 text2_list 中。 70 # 最后,使用 print() 函数打印处理后的微博内容,方便调试和查看结果。 71 for text in text_list: 72 text2=dr.sub('',text) #正则表达式提取微博内容 73 print(text2) 74 text2_list.append(text2) #将处理后的微博内容添加到 text2_list 中,方便后续的处理和分析。 75 # 微博创建时间 76 time_list=jsonpath(cards,'$..mblog.created_at') 77 time_list=[trans_time(v_str=i) for i in time_list] 78 # 微博作者 79 author_list=jsonpath(cards,'$..mblog.user.screen_name') 80 # 微博id 81 id_list=jsonpath(cards,'$..mblog.id') 82 # 微博bid 83 bid_list=jsonpath(cards,'$..mblog.bid') 84 # 转发数 85 reposts_count_list=jsonpath(cards,'$..mblog.reposts_count')#$表示根节点;..表示递归搜索子孙节点,mblog表示cards中的每一项中的mblog字段 86 # 评论数 87 comments_count_list=jsonpath(cards,'$..mblog.comments_count') 88 # 点赞数 89 attitudes_count_list=jsonpath(cards,'$..mblog.attitudes_count') 90 status_list=jsonpath(cards,'$..mblog.status_province') 91 '''由于有些微博的省份/城市信息没有该字段信息,因此在抓取时可能会出现缺失值。 92 为保证所有的列表长度一致,这里使用了一个判断,判断 status_list 列表的长度是否小于 id_list 列表的长度。 93 如果长度不一致,则在 status_list 后面添加相应数量的 None 值,以保证所有列表长度一致。''' 94 if len(status_list) < len(id_list): 95 status_list += [None] * (len(id_list) - len(status_list)) 96 df=pd.DataFrame( 97 {'页码':[page]*len(id_list), 98 '微博id':id_list, 99 '微博bid':bid_list, 100 '微博作者':author_list, 101 '发布时间': time_list, 102 '微博内容':text2_list, 103 '转发数':reposts_count_list, 104 '评论数':comments_count_list, 105 '点赞数': attitudes_count_list, 106 'IP属地': status_list, 107 } 108 ) 109 # 表头 110 # '''如果输出文件已经存在,则设置 header=None,表明输出文件已经含有字段名; 111 # 否则设置 header 为包含字段名的列表 ['页码','微博id','微博bid','微博作者','发布时间','微博内容','转发数', '评论数','点赞数','IP属地']''' 112 if os.path.exists(w_weibo_file): 113 header=None 114 else: 115 header=['页码','微博id','微博bid','微博作者','发布时间','微博内容','转发数', '评论数','点赞数','IP属地'] 116 # 保存到csv文件 117 # w_weibo_file:输出文件的路径和名称。 118 # mode='a+':输出文件的打开模式,'a+' 表示以追加模式(append mode)打开文件,即在文件末尾添加新的内容。 119 df.to_csv(w_weibo_file,mode='a+',index=False,header=header,encoding='utf_8_sig') 120 print('csv保存成功:{}'.format(w_weibo_file)) 121 # 主函数 122 if __name__== '__main__': 123 max_search_page=80 # 爬取前几页 124 search_keyword='淄博烧烤' # 爬取关键字 125 w_weibo_file='微博清单_{}_前{}页.csv'.format(search_keyword,max_search_page) #保存文件名 126 if os.path.exists(w_weibo_file): # 如果csv文件存在,先删除之前的文件 127 os.remove(w_weibo_file) 128 print('微博清单存在,已删除:{}'.format(w_weibo_file)) 129 # 调用爬取微博函数 130 get_weibo_list(s_keyword=search_keyword,w_max_page=max_search_page) 131 #-----------------------------------------------------------------------------------------------------------------------# 132 #######2.数据清洗 133 import pandas as pd 134 filename = '微博清单_淄博烧烤_前80页.csv' #指定读入的文件名 135 df = pd.read_csv(filename) 136 print(df.head(10)) #显示前10行数据 137 # 查询空值 138 print(df.isnull()) 139 #统计各列的空值情况 140 print('\n===各列的空值情况如下:===') 141 print(df.isnull().sum()) 142 # #统计缺失值NaN 143 print('\n===各列的缺失值情况如下:===') 144 print(df.isna().sum()) 145 #只显示存在缺失值的行列,清楚的确定缺失值的位置 146 print('\n===显示存在缺失值的行列如下:===') 147 df[df.isnull().values==True].head(11) 148 # 缺失值处理,用'Unknown'填充 149 new=df.fillna('Unknown') 150 new[new['IP属地'] == 'Unknown'] 151 # 查找重复值 152 print('\n===显示存在重复值的行列如下:===') 153 new[new.duplicated().values==True] 154 #使用describe查看统计信息 155 print(new.describe()) 156 # 异常值判断 157 # 使用均值和标准差进行判断 158 # mean 为数据的均值 159 # std 为数据的标准差 160 # 数据的正常范围为 [mean-2 × std,mean+2 × std 161 for i in ['转发数','评论数','点赞数']: 162 mean=new[i].mean() 163 std = new[i].std() 164 topnum1 =mean+2*std #上限 165 bottomnum1 = mean-2*std #下限 166 print(i+"的正常值的范围:[{b},{t}]".format(t=topnum1,b=bottomnum1)) 167 print(i+"存在超出正常范围的值:",any(new[i]>topnum1)) 168 print(i+"存在小于正常范围的值:",any(new[i]<bottomnum1)) 169 # 异常值处理 170 # 取数据中的最大最小值进行异常值替换。 171 # new[‘点赞数’][new[‘点赞数’]<topnum1]首先取出小于正常值上限的数据,然后从这些数据中使用max()方法,找出最大值。 172 # 取最小值同理。 173 replace_value1=new['转发数'][new['转发数']<topnum1].max() 174 new.loc[new['转发数']>topnum1,'转发数']=replace_value1 175 replace_value2=new['转发数'][new['转发数']>bottomnum1].min() 176 new.loc[new['转发数']<bottomnum1,'转发数']=replace_value2 177 178 replace_value1=new['点赞数'][new['点赞数']<topnum1].max() 179 new.loc[new['点赞数']>topnum1,'点赞数']=replace_value1 180 replace_value2=new['点赞数'][new['点赞数']>bottomnum1].min() 181 new.loc[new['点赞数']<bottomnum1,'点赞数']=replace_value2 182 183 replace_value1=new['评论数'][new['评论数']<topnum1].max() 184 new.loc[new['评论数']>topnum1,'评论数']=replace_value1 185 replace_value2=new['评论数'][new['评论数']>bottomnum1].min() 186 new.loc[new['评论数']<bottomnum1,'评论数']=replace_value2 187 new.describe() 188 # 再次保存文件 189 new.to_csv('cleanfile.csv',index=False,encoding='utf_8_sig') 190 print('数据清洗成功') 191 #---------------------------------------------------------------------------------------------------------------------------------# 192 #######3.jieba分词,生成词云的完整代码 193 import jieba #jieba是一款中文分词库 194 import emoji #emoji是一个用于处理表情符号的库 195 from pyecharts.charts import WordCloud #导入绘制词云图的WordCloud类 196 from pyecharts.globals import SymbolType #导入符号类型SymbolType 197 from pyecharts import options as opts #导入全局设置options模块,简写为opts 198 from collections import Counter # collections模块中的Counter类,用于统计每个元素出现的次数。 199 import pandas as pd 200 # 打开清洗后的数据文件'cleanfile.csv' 201 df_new = pd.read_csv('cleanfile.csv') 202 df_new 203 comments = df_new['微博内容'].values.astype(str) #将微博内容取出,存储在一个名为comments的数组中 204 205 # print(comments) #查看微博内容 206 # 'hit_stopwords.txt'为停用词表(本代码用的是哈尔滨工业大学停用词表)导入了停用词表, 207 # 将停用词表中的每个单词存储到列表stop_words中,并增加了一些手动定义的停用词,去除无意义的词语 208 with open('hit_stopwords.txt','r',encoding='utf8') as f: 209 stop_words=f.readlines() 210 stop_words = [i.strip() for i in stop_words] 211 stop_words.extend({'nan','还','不','不是','人','都','去','很','全文','没有','没','真的','现在','微博','视频','2023','徐明浩'}) 212 # 分词并去掉停用词 213 cut_words_list = [] 214 for comment in comments: 215 comment= re.sub( r'【|】', "", comment) # 去除 【xx】 216 comment=re.sub(r'#\w+ ?', "", comment) #去除话题引用 217 comment=emoji.replace_emoji(comment, replace="") #去除表情包 218 #使用jieba库的cut()方法对文本进行切词,将切好的词语存储到cut_words变量中。cut_all=False表示使用精确模式分词 219 cut_words = jieba.cut(comment, cut_all=False) 220 # if i not in stop_words,表示只有当某个词语不在停用词表stop_words中时才将其加入到cut_words_list中去,使得cut_words_list中的每个元素都是一个非停用词且有实际含义的词语 221 cut_words_list.extend([i for i in cut_words if i not in stop_words]) 222 print(cut_words_list) # 输出分词结果列表 223 224 # 统计关键词的出现次数 225 # Counter(cut_words_list)统计出cut_words_list中每个元素(即分词后的词语)出现的次数,并返回一个字典(Counter对象),该字典的键为每个词语,值为该词语出现的次数 226 word_counts = Counter(cut_words_list) 227 words = list(word_counts.keys()) 228 counts = list(word_counts.values()) 229 data = list(zip(words, counts)) # zip(words,counts)将words和counts打包成一个元组列表 230 print(data) 231 data_sort = sorted(data, key=lambda x: x[1], reverse=True)[:200]#选取词语出现次数排名前200的元素 232 wc = WordCloud(init_opts=opts.InitOpts(width='1000px', height='500px')) #函数生成一个词云对象wc,就是一张空白的白色画布 233 wc.add("", data_sort, word_size_range=[20, 100] ,shape='diamond') 234 wc.set_global_opts(title_opts=opts.TitleOpts(title="淄博烧烤词云图")) #设置词云图的全局属性,设置了标题为“淄博烧烤词云图” 235 wc.render_notebook() #将生成的词云图渲染到notebook中 236 #---------------------------------------------------------------------------------------------------------------------------------# 237 #######4.打开清洗后的数据文件'cleanfile.csv' 238 import pandas ad pd 239 df_new = pd.read_csv('cleanfile.csv') 240 df_new 241 242 # IP属地前10统计(柱形图) 243 import matplotlib.pyplot as plt #导入matplotlib库中的pyplot模块,pyplot是用于创建图表的主要函数 244 df_new['IP属地'].value_counts().nlargest(10).plot.bar(figsize=(14,6),fontsize= 13) 245 plt.title('IP属地前10统计(柱形图)',fontsize= 20) 246 plt.xlabel('省份',fontsize= 16) 247 plt.xticks(rotation=0) #设置X轴刻度标签的旋转角度。xticks是指X轴上的刻度,rotation参数指定刻度标签的旋转度数,0表示不旋转。若刻度标签内容过长,旋转角度可以调整为其他角度,以便更好地展示文本。 248 plt.ylabel('数量',fontsize= 16) 249 plt.legend() #显示标签 250 plt.rcParams['font.sans-serif'] = ['SimHei'] #设置显示中文字符的字体 251 plt.grid() #显示网格线 252 plt.show() #显示图形 253 254 #发布帖子数量统计图(折线图) 255 import matplotlib.pyplot as plt 256 import matplotlib.dates as mdates #matplotlib库中的dates模块。dates模块主要用于处理日期格式 257 df_new['发布时间2']=pd.to_datetime(df_new['发布时间']) #将 df_new 中的 发布时间 字段转换成日期格式 258 df_new['发布日期']=df_new['发布时间2'].dt.date #新增一列 发布日期 作为日期数据 259 df_new_cm_date=df_new['发布日期'].value_counts() #然后统计每个日期的帖子数量,将其赋给 df_new_cm_date 260 df_new_cm_date.colums=['发布日期','发布帖子数量'] 261 df_new_cm_date.plot(x='发布日期',y='发布帖子数量',figsize=(14,6)) #绘制折线图 262 plt.title('发布帖子数量统计图(折线图)') 263 plt.grid() 264 plt.gca().xaxis.set_major_formatter(mdates.DateFormatter('%Y-%m-%d')) 265 plt.show() 266 #点赞数分布(盒图) 267 import matplotlib.pyplot as plt 268 df2=df_new[df_new['点赞数']<=10] #因为大部分点赞数小于10,所以取出小于10的画图 269 df_comment=df2['点赞数'].values.tolist() #提取其中点赞数字段的值,并将其转化为列表类型。tolist()方法则将NumPy数组转换成Python列表 270 plt.figure(figsize=(14,6)) 271 plt.boxplot(df_comment,labels=['点赞数分析'],) #绘制盒图 272 plt.ylabel('数量') 273 plt.title('点赞数分布(盒图)') 274 plt.rcParams['font.sans-serif'] = ['SimHei'] #设置显示中文字符的字体 275 plt.grid( axis='y') 276 plt.show() 277 #评论数分布—箱线图 278 import matplotlib.pyplot as plt 279 df2=df_new[df_new['评论数']<=10] 280 df_comment=df2['评论数'].values.tolist() 281 plt.figure(figsize=(14,6)) 282 plt.boxplot(df_comment,labels=['评论数分析'],) 283 plt.ylabel('数量') 284 plt.title('评论数分布—箱线图') 285 plt.rcParams['font.sans-serif'] = ['SimHei'] #设置显示中文字符的字体 286 plt.grid( axis='y') 287 plt.show() 288 #---------------------------------------------------------------------------------------------------------------------------------# 289 #######5.分析两个变量之间的相关系数 290 import pandas as pd 291 df = pd.read_csv('cleanfile.csv') 292 new_data=df.drop(labels=['微博id','微博bid','微博内容','IP属地','微博作者','发布时间','页码'],axis=1) 293 new_data.corr()#corr()函数可以计算DataFrame中每对列之间的相关性,默认使用皮尔逊相关系数来衡量相关性的强度,相关系数的取值范围为 [-1 ,1]。具体来说,相关系数为1表示完全正相关,0表示无相关性,-1表示完全负相关。 294 # 因为评论数、点赞数、转发数的数据大部分集中在0-20,所以取0-20之间的400个数据进行相关性分析 295 import pandas as pd 296 df1=[] #建立df1为一个空表,用来存放100个评论数为0-20之间的数据 297 for i in df['评论数']: 298 if i>=0 and i<=20: 299 df1.append(i) 300 if len(df1)==400: 301 break 302 df1 = pd.DataFrame(df1,columns = ['评论数']) #将df1列表转换为dataframe 303 print(df1.head(50)) 304 df2=[] #建立df2为一个空表,用来存放100个点赞数为0-20之间的数据 305 for i in df['点赞数']: 306 if i>=0 and i<=20: 307 df2.append(i) 308 if len(df2)==400: 309 break 310 df2= pd.DataFrame(df2,columns = ['点赞数']) #将df2列表转换为dataframe 311 print(df2.head(50)) 312 df3=[] #建立df3为一个空表,用来存放100个转发数为0-20之间的数据 313 for i in df['转发数']: 314 if (i>=0)and (i<=20): 315 df3.append(i) 316 if len(df3)==400: 317 break 318 df3 = pd.DataFrame(df3, columns = ['转发数']) #将df3列表转换为dataframe 319 print(df3.head(50)) 320 # ------------评论数与点赞数的散点图-------------# 321 import matplotlib.pyplot as plt 322 plt.scatter(df1['评论数'], df2['点赞数']) 323 plt.xlabel('评论数') 324 plt.ylabel('点赞数') 325 plt.show() 326 327 #-------------- 评论数与点赞数的一元回归方程-------------# 328 from sklearn.linear_model import LinearRegression 329 # 将评论数和点赞数分别作为自变量和因变量 330 X = df1[['评论数']] 331 Y = df2 ['点赞数'] 332 # 建立回归模型 333 model = LinearRegression() #使用LinearRegression()函数创建一个线性回归模型对象。 334 model.fit(X, Y) 335 # 输出回归方程 336 print('y = %.2fx + %.2f' % (model.coef_, model.intercept_)) 337 338 #-------------- 绘制回归直线-------------# 339 import numpy as np 340 import matplotlib.pyplot as plt 341 # 随机生成一些样本数据作为输入变量x 342 x = np.random.rand(100) * 10 343 # 计算对应的目标变量y,并添加一些随机噪声 344 y = 0.11*x + 1.56 + np.random.randn(100) * 10 #生成了100个服从标准正态分布的随机数,并将其乘以10,即均值为0,标准差为10的正态分布 345 # 绘制样本点的散点图 346 plt.scatter(x, y) 347 # 计算回归直线上的点的坐标 348 x_line = np.linspace(0, 20, 100)#长度为100的等间距数组,起始点是0,终止点是10(包含在数组中) 349 y_line = 0.11*x + 1.56 350 # 绘制回归直线 351 plt.plot(x_line, y_line, color='red') 352 plt.rcParams['font.sans-serif'] = ['SimHei'] #设置显示中文字符的字体 353 # 添加图标题和坐标轴标签 354 plt.title('评论数-点赞数线性回归方程图图') 355 plt.xlabel('评论数') 356 plt.ylabel('点赞数') 357 # 显示图像 358 plt.show()
五、总结(10 分)
1.经过对主题数据的分析与可视化,可以得到哪些结论?是否达到预期的目标?
经过对主题数据的分析与可视化,可以得到以下结论:
- 淄博烧烤在微博平台上的讨论相对活跃,表现为大量的微博内容和用户参与。
- 用户对淄博烧烤的态度和情感倾向多种多样,可以通过文本分析可以了解用户观点和对淄博烧烤的喜爱程度。
- 点赞数和评论数可以反映淄博烧烤的在社交媒体上的影响度。如果这些交互数据很高,说明大众对淄博烧烤的关注和认可度比较高。然而,仅仅通过这些数据就判断淄博烧烤的评价好坏是不够准确的。除此之外,还需要结合其他信息,例如“淄博烧烤”在其他社交媒体上的分布,以更加全面和客观的方式来评估淄博烧烤的评价好坏。
- 本报告选取“淄博烧烤”为关键词进行网络爬虫,旨在收集分析与淄博烧烤相关的微博帖子数量、内容、微博作者IP属地等信息,以了解淄博烧烤在社交媒体上的普及程度和影响力。预期目标是搜集有效数据样本并进行分析,从而得出有关淄博烧烤的相关结论。对淄博烧烤的评论的词云图会显示出社交媒体上的一些关键词和热门话题,这些关键词和话题是用户在文章中经常提到的,可以了解到大众对淄博烧烤的评价。一些常见的关键词可能包括“味道好”、“美食”、“服务态好”等等。在分析评论数、点赞数、转发数的相关性时,可以得出淄博烧烤在社交媒体上的存在一定的普及程度和影响力。综上,相对来说是达到预期的目标。
2.在完成此设计过程中,得到哪些收获?以及要改进的建议
- 学习了网络爬虫的基本原理和技术,包括反爬虫机制、模拟浏览器请求、翻页获取数据、用正则表达式对json网页进行解析、数据提取和清洗。
- 掌握了文本分析和数据可视化的方法,例如使用jieba分词和生成词云图。
- 了解了数据分析和统计的方法,例如绘制柱状图、散点图和计算相关系数。
- 学会了使用Python编程语言和相关库进行数据处理和分析。
- 因为所获取到的评论数、点赞数、转发数的数值大部分为0,,需要掌握一些方法选取出较好的数据进行数据可视化分析。
改进的建议包括:
- 增加更多的数据源,以获得更全面和准确的数据,可以提却更多的字段信息,从不同角度去分析“淄博烧烤”的普及程度。
- 进一步优化爬虫程序的效率和稳定性。
- 进一步深入数据分析和建模,例如使用机器学习算法进行情感分析或预测模型的构建。
- 增加更多的数据可视化方法和图表类型,以更好地展示数据和结论。
- 要对所获取的文本进行更加精确的分词以及进行聚类,使所得到的分词更具有主题性,从而更好地把握大众对淄博烧烤的观点和态度。
- 通过不断改进和完善,可以使网络爬虫程序更具实用性和可靠性,并为淄博烧烤相关的数据分析提供更有价值的见解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号