
Guard Band
ATI的driver code里已经有我修改的几十行代码了
对于整个版本控制和check in code的严谨性非常值得学习
最近手上有个EPR是关于Vista下WDM(Window Desktop Manager)在MultiMonitor下的issue
跟来跟去最后发现是所谓Guard Band这么一说
这玩意的实际意义是
1. Vertex的浮点精度控制在已知范围内
这样在设计对应管线时就可以使用定点数
算得也快一些,成本也相应降低
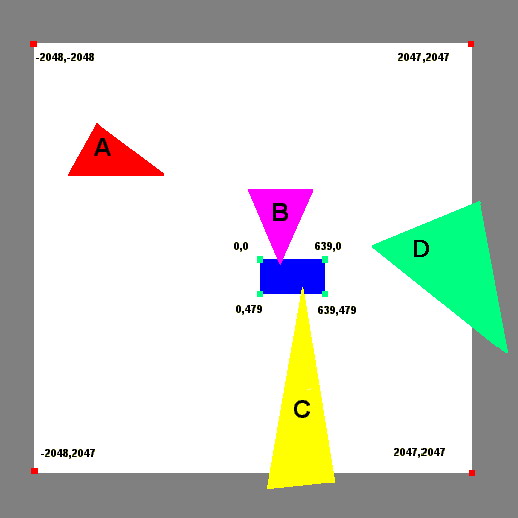
2. 避免昂贵的View frustum clipping,一旦出现下图C的这种情况,其代价为
Extra vertices produced, costing more bandwidth
CPU cost for interpolation of x,y,z, u,v, color, specular, alpha and fog
Breaking up of strips and fans
Poor vertex locality of new vertices, which hurts CPU and vertex cache coherency
MS的standard是说16K就够了(d3dref里的实现好象就是这么多)
ATI(亚鼎)的不同系列卡有不同处理(俺不泄蜜:)
NVIDIA(硬威大)比较吊,就文中看来,RIVA就有4K了,而从Geforce256起竟然有-100,000,000 to +100,000,000
我只能说够硬够威够大,NVIDIA的确比较不鸟MS,的确够超前(高精度下一些critical的问题就少多了),的确有钱(别忘了这是成本)
PS,大家的中文名字都起得比较有创意~
附参考文献: /Files/oiramario/Guard_Band_Clipping.rar
对于整个版本控制和check in code的严谨性非常值得学习
最近手上有个EPR是关于Vista下WDM(Window Desktop Manager)在MultiMonitor下的issue
跟来跟去最后发现是所谓Guard Band这么一说
这玩意的实际意义是
1. Vertex的浮点精度控制在已知范围内
这样在设计对应管线时就可以使用定点数
算得也快一些,成本也相应降低
2. 避免昂贵的View frustum clipping,一旦出现下图C的这种情况,其代价为
Extra vertices produced, costing more bandwidth
CPU cost for interpolation of x,y,z, u,v, color, specular, alpha and fog
Breaking up of strips and fans
Poor vertex locality of new vertices, which hurts CPU and vertex cache coherency
MS的standard是说16K就够了(d3dref里的实现好象就是这么多)
ATI(亚鼎)的不同系列卡有不同处理(俺不泄蜜:)
NVIDIA(硬威大)比较吊,就文中看来,RIVA就有4K了,而从Geforce256起竟然有-100,000,000 to +100,000,000
我只能说够硬够威够大,NVIDIA的确比较不鸟MS,的确够超前(高精度下一些critical的问题就少多了),的确有钱(别忘了这是成本)
PS,大家的中文名字都起得比较有创意~
附参考文献: /Files/oiramario/Guard_Band_Clipping.rar

