
统计Github项目信息
项目总述
主要任务是从之前同项目的组员建的关系型数据库里提取出我们需要的GitHub的数据,并把结果保存到文件,以便之后插入到数据库。
从已经建立好的关系型数据库上多线程地读取GitHub的项目信息。主要信息包括项目的名称,用户名,被Star的数量,是否被fork,以及该项目用到的编程语言。
在统计之前的neo4j数据库长这样,其中紫色的是项目信息,蓝色的是用户信息,灰色的是commit信息,这些大量的信息中我们需要提取出我们需要的数据:
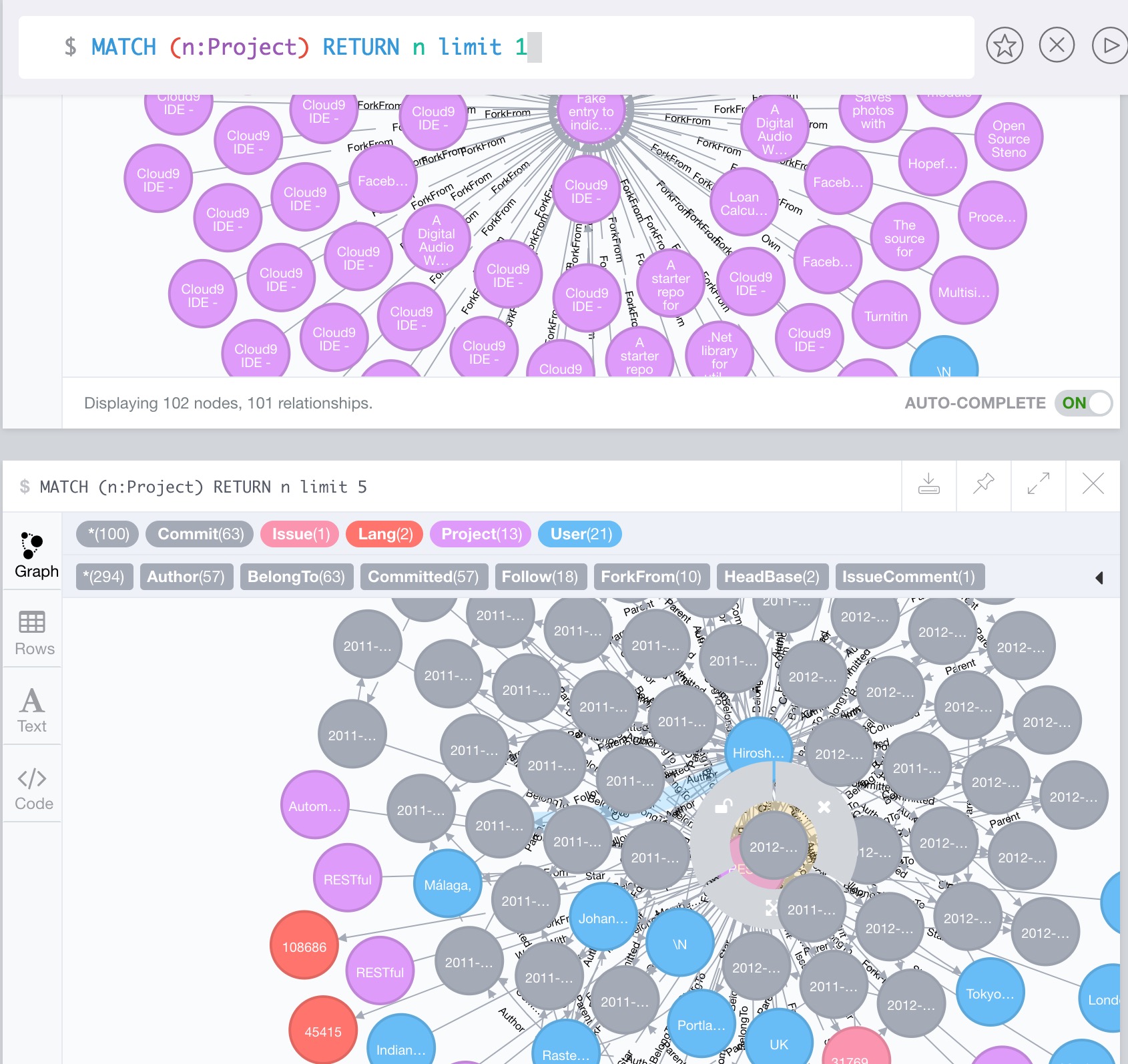
结果呈现
实验室的分项目,运行需要内网。最后的结果保存在ssh root@192.168.7.106:usr/zy里的30个out点txt文件。
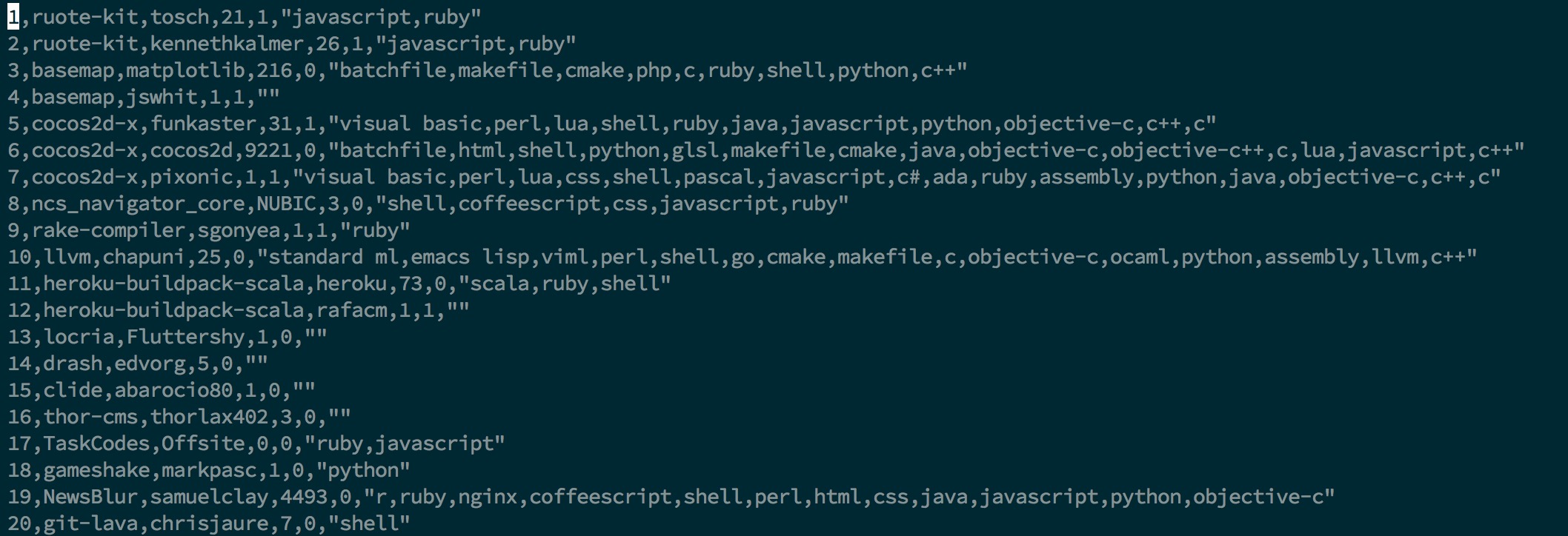
最后的输出文件大致如下:
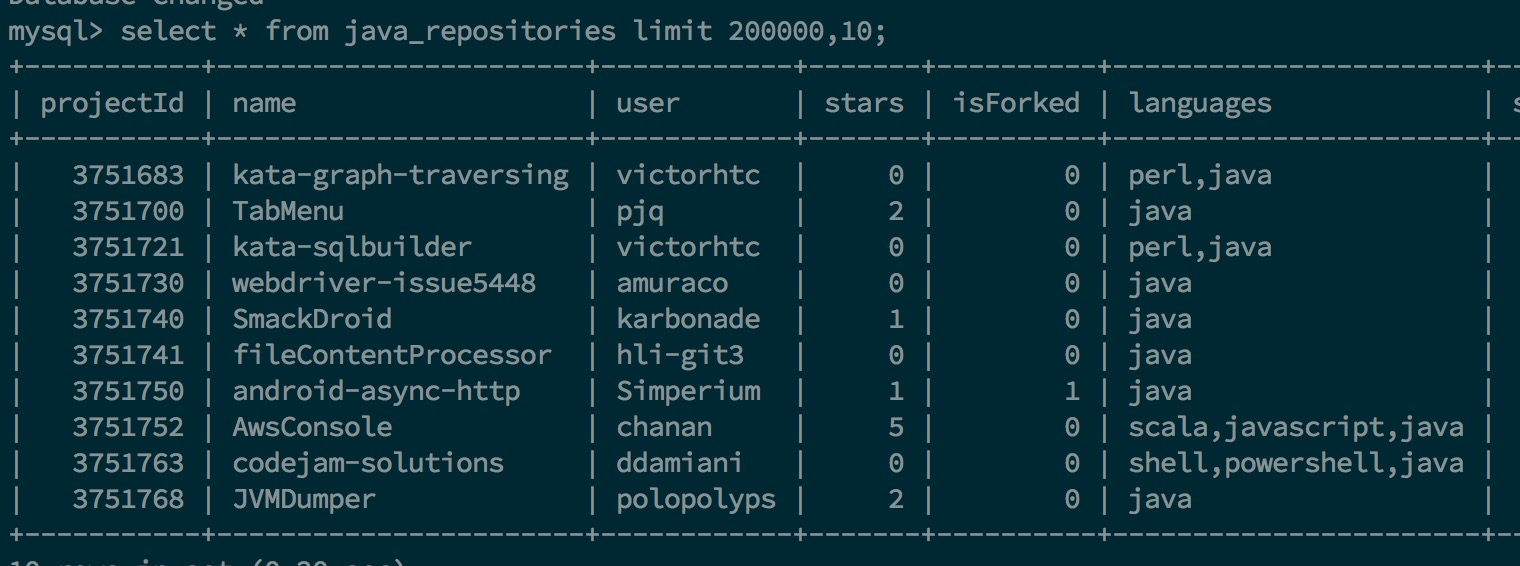
插入到数据库之后的数据(该数据放在192.168.7.118的mysql上)
一些注意点
user和starNum这两个信息不是project里所属的字段,而是通过有边连接来查询相应的数据。例如:
MATCH (m:User)-[r:Star]->(n:Project) where n.projectId='1' RETURN count(r) as fx
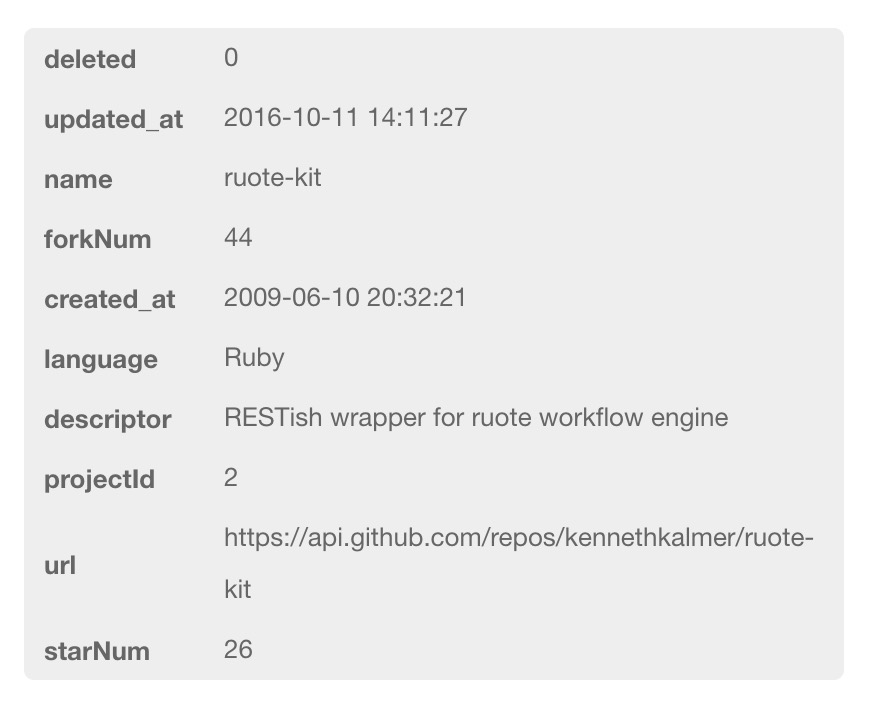
project里面有的字段信息如图:
关于多线程
对于起多少线程比较合适的问题,看到网上一般的回答是:
CPU核心数量*2 + 2
查看一下服务器的cpu嘻嘻
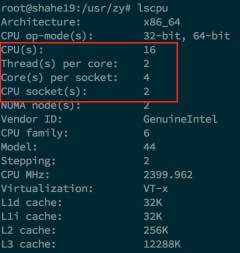
看到16个cpu(包括8个物理8个逻辑),于是34个线程走起。实测好像还好,带宽还行,基本没有出现被几个线程独占资源的情况。
踩过的一些坑
neo4j的连接的关闭,网上的代码说的都是session.close(); driver.close(); 我一开始也是按照这么来的,但最初我是查询一条连接一次,就发现始终会报Too Many Open Files的异常,也就是打开了太多文件,文件句柄超过了服务器的限制(一般Linux机器的限制是1024,可以通过ulimt -a来查看当前系统最大的文件打开数)这样的问题我通过一步步排查发现每次连接数据库会打开两个文件,但关闭只会关闭一个就导致打开的文件越堆越多。
后来的解决方法是,只开一个连接,一直不关。因为同一类型的查询用的是同一个数据库,因此我们可以一直连着这个连接,直至用完再关闭(好像也可以用连接池来解决这个问题)这样直接在构造函数连接就行了。
以及保存的时候注意一下服务器的空间是不是够存。有的时候代码卡在那儿只是因为服务器放不下了owo.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号