结对第二次—文献摘要热词统计及进阶需求
格式描述 ----------- - 这个作业属于哪个课程:[软件工程实践](https://edu.cnblogs.com/campus/fzu/SoftwareEngineering1916W) - 这个作业要求在哪里:[作业要求](https://edu.cnblogs.com/campus/fzu/SoftwareEngineering1916W/homework/2688) - 结对学号: **欧福源221600431 朱伟榜221600441** - 这个作业的目标:**实现一个能够对文本文件中的单词的词频进行统计的控制台程序。并在此基础上,编码实现顶会热词统计器。** - 结对同学的博客链接:[朱伟榜221600441](https://www.cnblogs.com/banglc/) - Github项目地址:[Github地址](https://github.com/mengying666) - Github的代码签入记录:
- 具体分工: - 221600431欧福源 - 需求分析 - 爬虫程序编写 - 代码测试 - 博客撰写,熟悉Github的操作 - 221600441朱伟榜 - 需求分析 - 主要代码实现 - 辅助博客撰写 - 代码测试
PSP ----------- |PSP2.1|Personal Software Process Stages|预估耗时(分钟)|实际耗时(分钟)| |:--|:--|:--|:--| |Planning|计划||| |• Estimate|• 估计这个任务需要多少时间|610|630| |Development|开发||| |• Analysis|• 需求分析 (包括学习新技术)|70|90| |• Design Spec|• 生成设计文档|60|50| |• Design Review|• 设计复审|30|40| |• Coding Standard|• 代码规范 (为目前的开发制定合适的规范)|40|30| |• Design|• 具体设计|70|90| |• Coding|• 具体编码|310|300| |• Code Review|• 代码复审|30|30| |• Test|• 测试(自我测试,修改代码,提交修改)|40|70| |Reporting|报告||| |• Test Report|• 测试报告|60|80| |• Size Measurement|• 计算工作量|30|40| |• Postmortem & Process Improvement Plan|• 事后总结, 并提出过程改进计划|40|55| ||合计|740|820|
解题思路描述 ----------- 刚开始拿到题目时,是比较迷茫的,毕竟题目看起来很繁琐,但仔细思考一下,发现不是很难。我们通过百度以及CSDN论坛等渠道找到了需要的资料,这些资料对我们起到了很大的帮助。
设计实现过程 ----------- ###基本需求 类图如下: 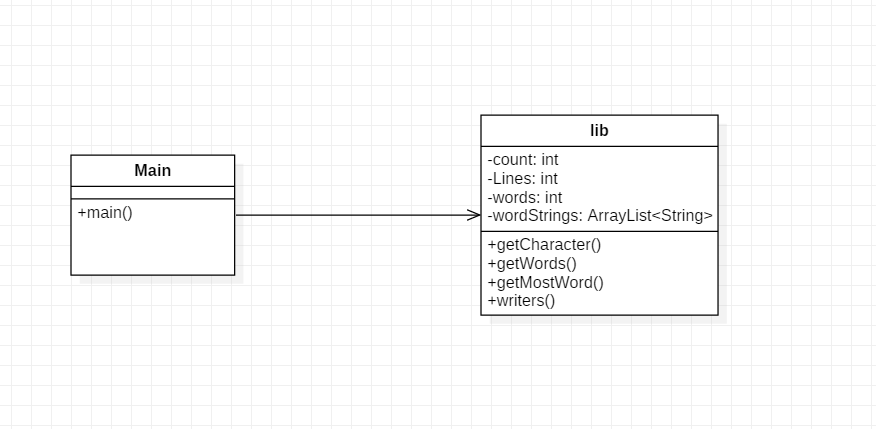 关键函数是getWords。基本思路是每一行读取后根据正则表达式匹配,每找到一个符合的单词就加一。 流程图如下: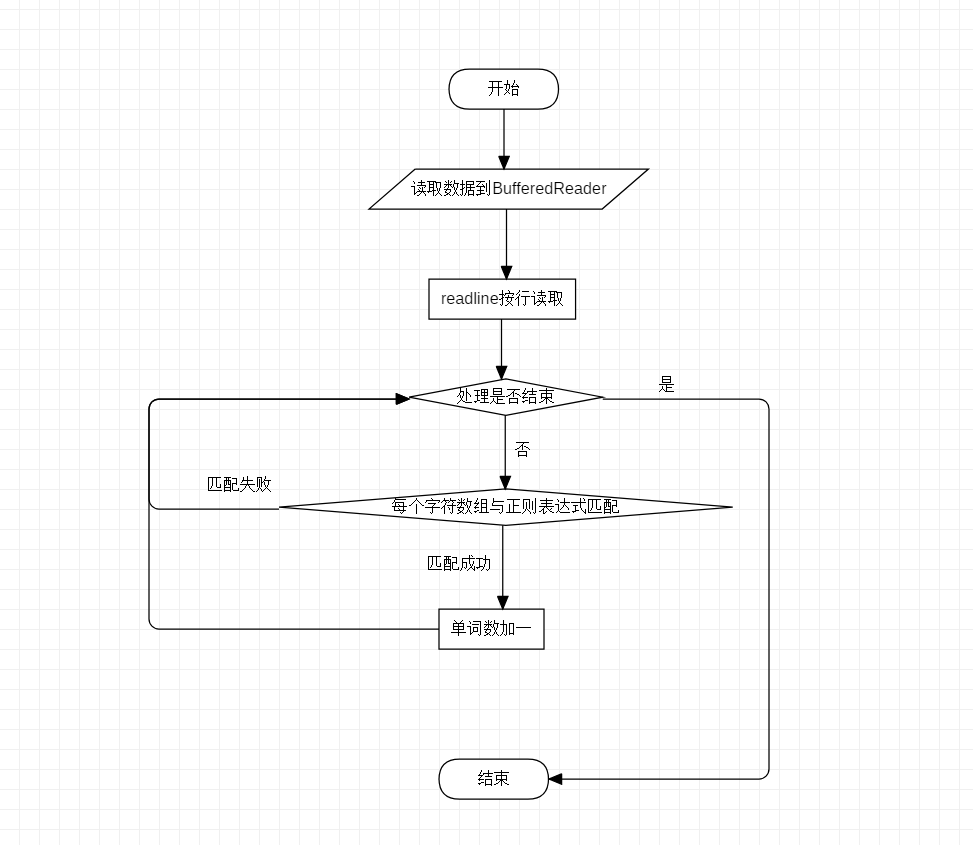 这些代码的关键在于细节的处理。
爬虫程序
使用了Jsoup工具进行网站页面的爬取。通过对CVPR2018官网的首页,我们发现文章标题都属于一个class,即ptitle。于是我们先用 Jsoup.connect(url).get( )得到整个页面,用getElementsByClass(ptitle)得到标题,接着用attr(href)得到该文章的链接,并用它得到该文章的页面,接着用getElementById("abstract")得到文章的摘要,最后将它们输入到result.txt中。
进阶需求
进阶需求在基本需求上增加了自定义输入输出文件、加入权重的词频统计(词组未实现)、自定义词频统计输出(词组未实现)、多参数的混合使用等功能。
改进程序性能 ----------- 花费的时间:55分钟 改进思路:优化了算法。
具体代码 ----------- ###基本需求代码
import java.io.*;
import java.util.Map.Entry;
import java.util.regex.Pattern;
import java.util.*;
import java.util.regex.Matcher;
class EntryComparator implements Comparator<Entry<String, Integer>> {
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
if(o2.getValue() == o1.getValue()) {
return o1.getKey().compareTo(o2.getKey());
}
else return (o2.getValue() - o1.getValue());
}
}
public class Main {
private static ArrayList<String> wordStrings =new ArrayList<String>();
private static int count = 0;
private static int lines = 0;
private static int words = 0;
//获取字符数
private static void getCharacter(String filename)
{
int ch, ef = 0;
try {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(new File(filename)));
BufferedReader in = new BufferedReader(new InputStreamReader(bis, "utf-8"), 20* 1024* 1024 );
while (in.ready()) {
ch = in.read();
count++;
if((char)ch == '\n') count--;
if((char)ch != ' ' && (char)ch != '\t' && (char)ch != '\n' && (char)ch != '\r') ef++;
if((char)ch == '\n' && ef > 0) {
lines++;
ef = 0;
}
}
if(ef > 0) {
lines++;
ef = 0;
}
in.close();
} catch (IOException ex) {
ex.printStackTrace();
}
}
//获取单词数
private static void getWords(String filename)throws IOException {
FileReader fr = new FileReader(filename);
String s = "([A-Za-z]{4,})([A-Za-z0-9]*)";
BufferedReader br = new BufferedReader(fr);
String line = "";
while((line = br.readLine()) != null) {
line = line.replaceAll("[^a-zA-Z0-9]([0-9]{1,})([a-zA-Z0-9]*)", "");
Pattern pattern=Pattern.compile(s);
Matcher ma=pattern.matcher(line);
while(ma.find()){
words++;
//System.out.println(ma.group());
}
}
br.close();
fr.close();
}
//输出前10的单词及个数
private static void getMostWord(String filename)throws IOException {
FileReader fr = new FileReader(filename);
String s = "([A-Za-z]{4,})([A-Za-z0-9]*)";
ArrayList<String> text = new ArrayList<String>();
BufferedReader br = new BufferedReader(fr);
String line = "";
while((line = br.readLine()) != null) {
line = line.toLowerCase();
line = line.replaceAll("[^a-z0-9]([0-9]{1,})([a-z0-9]*)", "");
Pattern pattern=Pattern.compile(s);
Matcher ma=pattern.matcher(line);
while(ma.find()){
text.add(ma.group());
//System.out.println(ma.group());
}
}
br.close();
fr.close();
Map<String, Integer> map = new HashMap<String, Integer>();
for(String st : text) {
if(map.containsKey(st)) {
map.put(st, map.get(st)+1);
}else {
map.put(st, 1);
}
}
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String,Integer>>();
for(Entry<String, Integer> entry : map.entrySet()) {
list.add(entry);
}
Collections.sort(list,new EntryComparator());
int i = 0;
String ssString;
for(Entry<String, Integer> obj : list) {
if(i>9) break;
ssString="<"+obj.getKey()+">: " + obj.getValue()+"\r\n";
wordStrings.add(ssString);
++i;
// System.out.print(ssString);
}
}
private static void writers(String c,String w,String l,ArrayList<String>ws,String path) {
try {
File file1 =new File(path);
Writer out =new FileWriter(file1);
out.write(c);
out.write(w);
out.write(l);
for(int i=0;i<ws.size();i++)out.write(ws.get(i));
out.close();
}catch (Exception e) {
// TODO: handle exception
}
}
public static void main(String[] args) throws IOException {
String path = "input3.txt";
//String path = args[0];
//long start = System.currentTimeMillis();//要测试的程序或方法
getCharacter(path);
getWords(path);
getMostWord(path);
String c,w,l;
c = "characters: "+count+"\r\n";
w = "words: "+words+"\r\n";
l = "lines: "+lines+"\r\n";
writers(c, w, l, wordStrings, "result.txt");
//long end = System.currentTimeMillis();
//System.out.println("程序运行时间:"+(end-start)+"ms");
}
}
###爬虫代码
package 爬虫;
import java.io.File;
import java.io.FileWriter;
import java.io.IOException;
import java.io.Writer;
import org.jsoup.Connection;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class 爬虫 {
public static void main(String []args)
{
String url1="http://openaccess.thecvf.com/CVPR2018.py";
Document document1 = null,document2 = null;
try
{
File file1 =new File("result.txt");
Writer out =new FileWriter(file1);
Connection connection = Jsoup.connect(url1);
connection.maxBodySize(0);
document1 = connection.get();
Elements x = document1.getElementsByClass("ptitle");
//System.out.print(x.size());
for(int i=0;i<x.size();i++)
{
//System.out.print(i+1+" ");
//System.out.print("Title: "+x.get(i).text()+" ");
String n = i+"\r\n";
String t="Title: "+x.get(i).text()+"\r\n";
Elements links = document1.select("dt a");
String url2=links.get(i).attr("href");
url2="http://openaccess.thecvf.com/"+url2;
document2 = Jsoup.connect(url2).get();
Element y= document2.getElementById("abstract");
//System.out.println("Abstract:"+y.text()+"\n\n");
String a="Abstract: "+y.text()+"\r\n\r\n\r\n";
out.write(n);
out.write(t);
out.write(a);
}
out.close();
}
catch (IOException e)
{
System.out.println("爬取失败");
}
}
}
###进阶需求代码 import java.io.*; import java.util.Map.Entry; import java.util.*;
//排序
class EntryComparator implements Comparator<Entry<String, Integer>> {
public int compare(Entry<String, Integer> o1, Entry<String, Integer> o2) {
if(o2.getValue() == o1.getValue()) {
return o1.getKey().compareTo(o2.getKey());
}
else return (o2.getValue() - o1.getValue());
}
}
public class WordCount {
private static ArrayList<String> wordStrings =new ArrayList<String>();
private static int count = 0;
private static int lines = 0;
private static int words = 0;
//获取字符数
private static void getCharacter(String filename)
{
int ls=0;
String chhString="";
try {
BufferedInputStream bis = new BufferedInputStream(new FileInputStream(new File(filename)));
BufferedReader in = new BufferedReader(new InputStreamReader(bis, "utf-8"), 20* 1024* 1024 );
while (in.ready()) {
chhString = in.readLine();
ls++;
if(chhString.indexOf("Abstract:") == 0||chhString.indexOf("Title:") == 0) {
chhString = chhString.replaceAll("[^\\u0000-\\u007f]", "");
count +=chhString.length();
lines++;
}
}
ls = ls/5*2;
count += ls;
in.close();
} catch (IOException ex) {
ex.printStackTrace();
}
count -= lines/2*17;
}
private static boolean isWord(String s) {
char[] temp = s.toCharArray();
if(temp.length>3)
if(temp[0]>=97 && temp[0]<=122 && temp[1]>=97 && temp[1]<=122 &&temp[2]>=97 && temp[2]<=122 && temp[3]>=97 && temp[3]<=122)
return true;
else return false;
else return false;
}
//获取单词数
private static void getWords(String filename )throws IOException {
try {
FileReader fr = new FileReader(filename);
BufferedReader br = new BufferedReader(fr);
String line = "";
while((line = br.readLine()) != null) {
line = line.replace("[^\\u0000-\\u007f]", "");
line = line.toLowerCase();
String[] strings = line.split("[^a-z0-9]");
for(int i=1;i<strings.length;i++) {
if(isWord(strings[i])) words++;
}
}
br.close();
fr.close();
}catch (Exception e) {
e.printStackTrace();
}
}
//输出前n的单词及个数
private static void getMostWord(String filename,boolean w,int times)throws IOException {
int t=1;
if(w) t=10;
int a=t;
ArrayList<String> text = new ArrayList<String>();
try {
FileReader fr = new FileReader(filename);
BufferedReader br = new BufferedReader(fr);
String line = "";
while((line = br.readLine()) != null) {
line = line.toLowerCase();
line = line.replace("[^\\u0000-\\u007f]", "");
if(line.indexOf("title:")==0) {
String[] strings = line.split("[^a-z0-9]");
for(int nu=1;nu<strings.length;nu++) {
if(isWord(strings[nu])) {
while((t)>0) {
t--;
text.add(strings[nu]);
}
t = a;
}
}
}
if(line.indexOf("abstract:")==0) {
String[] strings = line.split("[^a-z0-9]");
for(int nu=1;nu<strings.length;nu++) {
if(isWord(strings[nu])) text.add(strings[nu]);
}
}
}
br.close();
fr.close();
}catch (Exception e) {
e.printStackTrace();
}
Map<String, Integer> map = new HashMap<String, Integer>();
for(String st : text) {
if(map.containsKey(st)) {
map.put(st, map.get(st)+1);
}else {
map.put(st, 1);
}
}
List<Map.Entry<String, Integer>> list = new ArrayList<Map.Entry<String,Integer>>();
for(Entry<String, Integer> entry : map.entrySet()) {
list.add(entry);
}
Collections.sort(list,new EntryComparator());
int ii = 0;
String ssString;
for(Entry<String, Integer> obj : list) {
if(ii>(times-1)) break;
ssString="<"+obj.getKey()+">: " + obj.getValue()+"\r\n";
wordStrings.add(ssString);
++ii;
}
}
private static void writers(String c,String w,String l,ArrayList<String>ws,String path) {
try {
File file1 =new File(path);
Writer out =new FileWriter(file1);
out.write(c);
out.write(w);
out.write(l);
for(int i=0;i<ws.size();i++)out.write(ws.get(i));
out.close();
}catch (Exception e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws IOException {
//long start = System.currentTimeMillis();//要测试的程序或方法
String ifile = "";
String ofile = "";
String w;
boolean b = false;
int times = 10;
for(int ar=0;ar<args.length;ar=ar+2) {
if("-i".equals(args[ar])) ifile = args[ar+1];
if("-o".equals(args[ar])) ofile = args[ar+1];
if("-w".equals(args[ar])) {
w = args[ar+1];
if(w.equals("1")) {
b = true;
}
else if(w.equals("0")) {
b = false;
}
}
if("-n".equals(args[ar])) {
times = Integer.valueOf(args[ar+1]).intValue();
}
/*if("-m".equals(args[ar])) {
nl = Integer.valueOf(args[ar+1]).intValue();
}*/
}
getCharacter(ifile);
getWords(ifile);
getMostWord(ifile, b, times);
String c,ws,l;
c = "characters: "+count+"\r\n";
ws = "words: "+words+"\r\n";
l = "lines: "+lines+"\r\n";
writers(c, ws, l, wordStrings, ofile);
//long end = System.currentTimeMillis();
//System.out.println("程序运行时间:"+(end-start)+"ms");
}
}
遇到的困难及解决方法 -----------
困难描述
需求比较模糊,理解用了较长的时间,有些理解错误导致走了弯路;还有对爬虫jsoup不熟悉;细节上出现了错误。
解决方法
与同学讨论;上网查教程;细心处理。
对队友的评价 ---------- - 221600431欧福源 - 细节把握不错,但写代码的速度有点慢
- 221600441朱伟榜
- 对需求理解透彻,很清楚解题思路,编码能力强

 浙公网安备 33010602011771号
浙公网安备 33010602011771号