noi.cn 访问量爬取
网课期间开始的一项无聊的项目,对 www.noi.cn 的访问量进行爬取。具体操作为直接访问对应的网址,获取其网站底部的总访问量信息。
爬虫使用 Python 编写,配合 bat 文件和 Windows 任务计划运行,设置的时间为每 15 分钟爬取一次。
源码和部署
from datetime import datetime
import requests
import re
f=open("\\日访问.txt","a")
response = requests.get('https://www.noi.cn/ccf/counter/site?Type=Total&SiteID=127&DomID=_zving_totalhitcount&VarName=_zving_totalhitcount')
response.encoding = 'utf-8'
p=re.search(r"\d+",response.text)
f.write(str(datetime.now().date())+' '+str(datetime.now().hour)+':'+str(datetime.now().minute)+' '+str(p.group(0))+'\n')
f.close()
其中 "日访问.txt" 自行改成希望储存的文件和位置。
使用方法:在同一文件夹下新建一个 .bat 脚本调用 .py 文件,然后在任务计划中添加对 .bat 的调用(设置为定时重复永不失效的)。
结果
以下是 2022-10-27 8:15 至 2022-11-15 8:30 共 1825 次有效结果。
信息中的时间表示这个时间之前 15 分钟的访问量信息(如第一个有效数据 8:30 是 8:15 到 8:30 的访问量)。
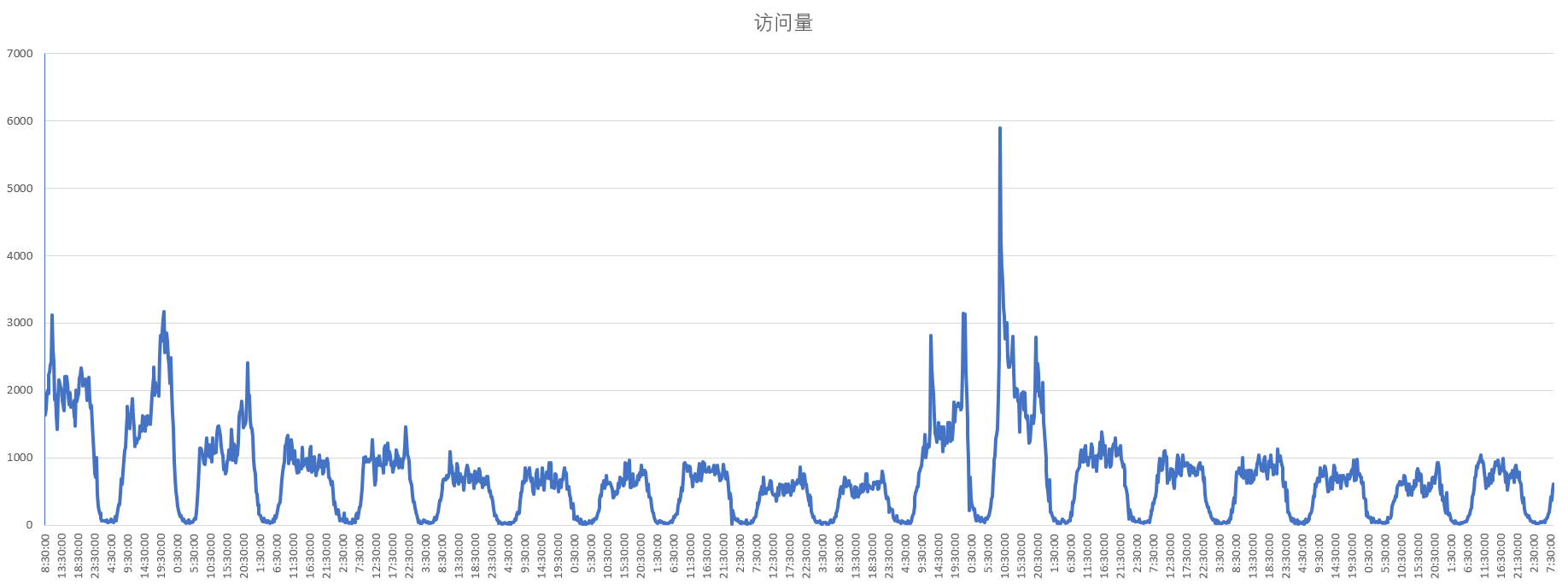
访问量折线图。前三天的高访问量是由于 CSP 前各地公布是否举办,后面的两天高访问量是 CSP 成绩公告和数据发布。
完整的文件(包括文本和表格):https://ofb.lanzoum.com/ivcnL0fy2vbe。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号