
学习目标
resultMap中的标签字段不可以省略
第一章-核心配置文件解释
知识点-核心配置文件详解
1.目标
2.路径
- 核心配置文件的顺序
- properties
- typeAliases
- Mapper
3.讲解
3.1.核心配置文件的顺序
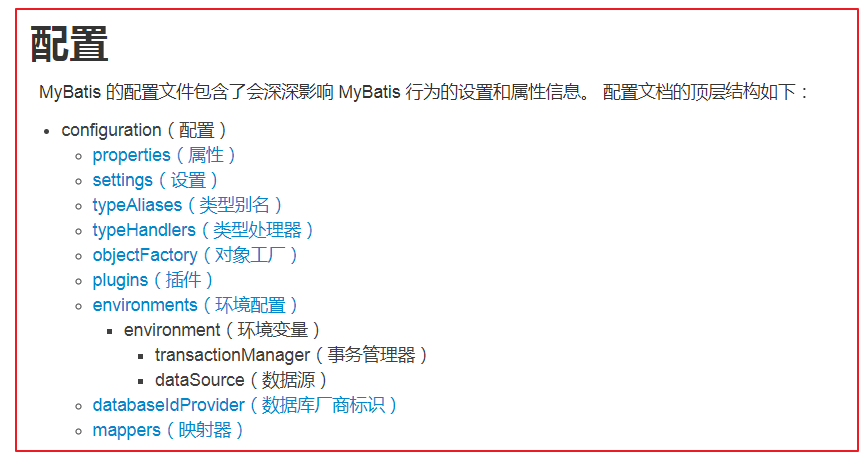
properties(引入外部properties文件)
settings(全局配置参数)
typeAliases(类型别名)
typeHandlers(类型处理器)
objectFactory(对象工厂)
plugins(插件)
environments(环境集合属性对象)
environment(环境子属性对象)
transactionManager(事务管理)
dataSource(数据源)
mappers(映射器)
3.2.properties
用于引入properties文件
- db.properties
在resources下面创建db.properties
driver=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/mybatis_day01
username=root
password=root
- 引入到核心配置文件
<configuration>
<!--
一、 properties标签:
1. 导入外部的properties文件
2. 在下面取值的时候,就可以使用 ${KEY}
-->
<properties resource="db.properties"/>
<environments default="dev">
<environment id="dev">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="${driver}"/>
<property name="url" value="${url}"/>
<property name="username" value="${username}"/>
<property name="password" value="${password}"/>
</dataSource>
</environment>
</environments>
....
</configuration>
3.3.typeAlias(类型别名)
3.3.1定义单个别名
- 核心配置文件
<!--
二、 typeAliases标签:
作用:
1.用来给JavaBean的类起别名,这个别名只能在映射文件中有效!
再具体一些就是在resultType 和 parameterType 有用!
2. 起好的别名,就是类的名字,大小写任意,只要写的是类的名字即可。不在乎是大写还是小写或者是混合
用法:
1. 单个起别名:给单独的一个类起别名。如果有多个类,那么每个类都要起别名。
<typeAliases>
<typeAlias type="com.itheima.bean.User"/>
<typeAlias type="com.itheima.bean.Teacher"/>
</typeAliases>
2. 批量起别名: 给指定包下的所有类起别名
<typeAliases>
<package name="com.itheima.bean"/>
</typeAliases>
-->
<typeAliases>
<typeAlias type="com.itheima.bean.User"/>
</typeAliases>
- 修改UserDao.xml
<!--使用别名-->
<select id="findByUid2" parameterType="int" resultType="uSEr">
select * from t_user where uid = #{id}
</select>
3.3.2批量定义别名
使用package定义的别名:就是pojo的类名,大小写都可以
- 核心配置文件
<typeAliases>
<package name="com.itheima.bean"/>
</typeAliases>
- 修改UserDao.xml
<!--使用别名-->
<select id="findByUid2" parameterType="int" resultType="uSEr">
select * from t_user where uid = #{id}
</select>
3.4.Mapper
3.4.1方式一:引入映射文件路径
<!--
三、 mappers
作用: 告诉mybatis,映射文件在哪里?
用法:
1.可以单个的配置,也可以批量配置
2. 单个配置:
<mapper resource="com/itheima/dao/UserDao.xml"/>
或者
<mapper class="com.itheima.dao.UserDao"/>
3. 批量配置
批量配置: 只要指定包名即可,mybatis会在这个包下找映射文件
<package name="com.itheima.dao"/>
-->
<mappers>
<mapper resource="com/itheima/dao/UserDao.xml"/>
</mappers>
3.4.2方式二:扫描接口
- 配置单个接口
<mappers>
<!--指定单个的dao接口位置-->
<mapper class="com.itheima.dao.UserDao"/>
</mappers>
- 批量配置
指定一个包即可,一般指定到dao的包,以后有任何的映射文件的增加,都不用来核心配置文件设置了
<mappers>
<!--批量配置: 只要指定包名即可,mybatis会在这个包下找映射文件。-->
<package name="com.itheima.dao"/>
</mappers>
4.小结
- 核心配置文件的顺序
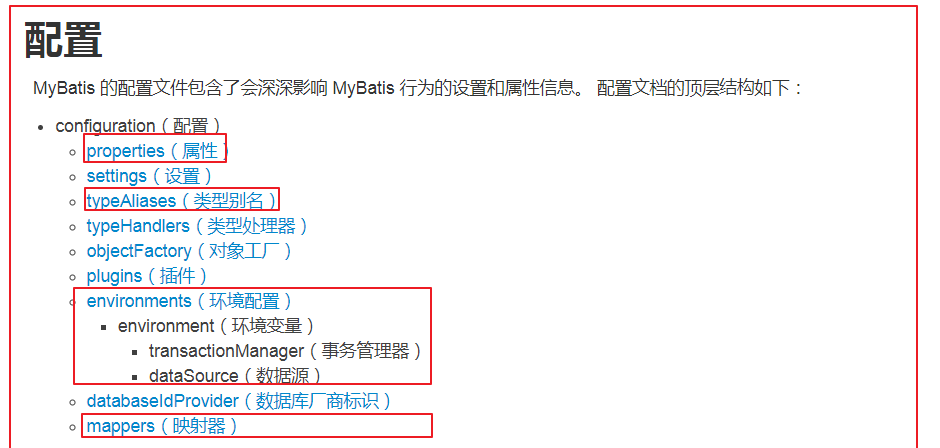
- properties 引入properties文件的
- 创建properties文件
- 使用
<properties resource="文件的路径"/> - 使用 ${key}来取值
- typeAliases(类型别名) 在Dao映射文件里面 直接写类(pojo)的名字, 不需要写类全限定名了
如果是java官方的类名: String类,直接简写即可。
<typeAliases>
<package name="com.itheima.bean"/>
</typeAliases>
- Mapper 引入Dao映射文件的
<mappers>
<package name="com.itheima.dao"></package>
</mappers>
第二章-Mybatis 连接池与事务【了解】
知识点-Mybatis 的连接池技术【了解】
1.目标
我们在前面的 WEB 课程中也学习过类似的连接池技术,而在 Mybatis 中也有连接池技术,但是它采用的是自己的连接池技术 。
在 Mybatis 的 SqlMapConfig.xml 配置文件中, 通过 <dataSource type=”pooled”>来实现 Mybatis 中连接池的配置.
2.路径
- Mybatis 连接池的分类
- Mybatis 中数据源的配置
- Mybatis 中 DataSource 配置分析
3.讲解
3.1Mybatis 连接池的分类
-
可以看出 Mybatis 将它自己的数据源分为三类:
- UNPOOLED 不使用连接池的数据源
- POOLED 使用连接池的数据源
- JNDI 使用 JNDI 实现的数据源,不一样的服务器获得的DataSource是不一样的. 注意: 只有是web项目或者Maven的war工程, 才能使用. 我们用的是tomcat, 用的连接池是dbcp.

-
在这三种数据源中,我们目前阶段一般采用的是 POOLED 数据源(很多时候我们所说的数据源就是为了更好的管理数据库连接,也就是我们所说的连接池技术),等后续学了Spring之后,会整合一些第三方连接池。
3.2Mybatis 中数据源的配置
-
我们的数据源配置就是在 SqlMapConfig.xml 文件中, 具体配置如下:
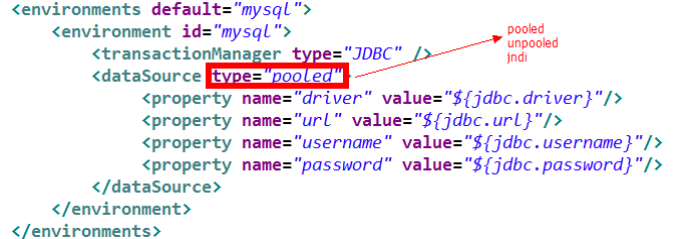
-
MyBatis 在初始化时,解析此文件,根据
的 type 属性来创建相应类型的的数据源DataSource,即: type=”POOLED”: MyBatis 会创建 PooledDataSource 实例, 使用连接池
type=”UNPOOLED” : MyBatis 会创建 UnpooledDataSource 实例, 没有使用的,只有一个连接对象的
type=”JNDI”: MyBatis 会从 JNDI 服务上(tomcat ... jboss...)查找 DataSource 实例,然后返回使用. 只有在web项目里面才有的,用的是服务器里面的. 默认会使用tomcat里面的dbcp
3.3Mybatis 中 DataSource 配置分析
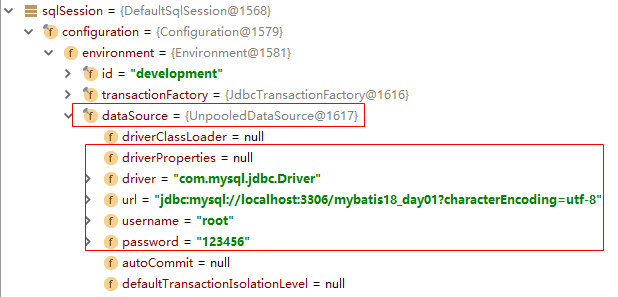
- 代码,在21行加一个断点, 当代码执行到21行时候,我们根据不同的配置(POOLED和UNPOOLED)来分析DataSource

-
当配置文件配置的是type=”POOLED”, 可以看到数据源连接信息
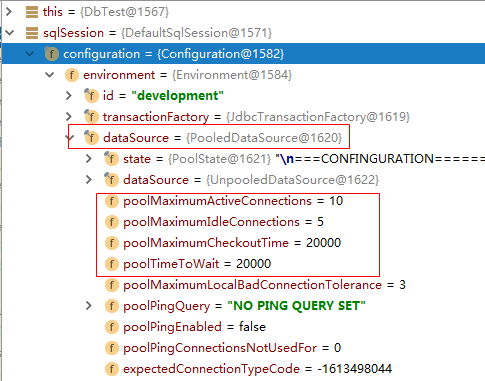
-
当配置文件配置的是type=”UNPOOLED”, 没有使用连接池
4.小结
-
配置
type="POOLED" 使用连接池(MyBatis内置的)
type="UNPOOLED" 不使用连接池 -
后面做项目, 工作里面的连接池, 我们都是使用的第三方的(C3P0,Druid,光连接池), 都有让Spring管理.此章节只做了解
知识点-Mybatis 的事务控制 【了解】
1.目标
2.路径
- JDBC 中事务的回顾
- Mybatis 中事务提交方式
- Mybatis 自动提交事务的设置
3.讲解
3.1 JDBC 中事务的回顾
在 JDBC 中我们可以通过手动方式将事务的提交改为手动方式,通过 setAutoCommit()方法就可以调整。通过 JDK 文档,我们找到该方法如下:

那么我们的 Mybatis 框架因为是对 JDBC 的封装,所以 Mybatis 框架的事务控制方式,本身也是用 JDBC的 setAutoCommit()方法来设置事务提交方式的。
3.2Mybatis 中事务提交方式
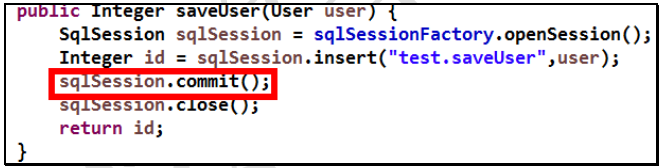
- Mybatis 中事务的提交方式,本质上就是调用 JDBC 的 setAutoCommit()来实现事务控制。我们运行之前所写的代码:

-
userDao 所调用的 saveUser()方法如下:
-
观察在它在控制台输出的结果:
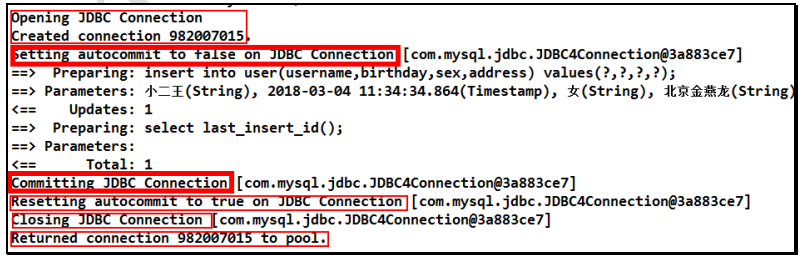
这是我们的 Connection 的整个变化过程, 通过分析我们能够发现之前的 CUD操作过程中,我们都要手动进行事务的提交,原因是 setAutoCommit()方法,在执行时它的值被设置为 false 了,所以我们在CUD 操作中,必须通过 sqlSession.commit()方法来执行提交操作。
3.3 Mybatis 自动提交事务的设置
通过上面的研究和分析,现在我们一起思考,为什么 CUD 过程中必须使用 sqlSession.commit()提交事务?主要原因就是在连接池中取出的连接,都会将调用 connection.setAutoCommit(false)方法,这样我们就必须使用 sqlSession.commit()方法,相当于使用了 JDBC 中的 connection.commit()方法实现事务提交。明白这一点后,我们现在一起尝试不进行手动提交,一样实现 CUD 操作。

我们发现,此时事务就设置为自动提交了,同样可以实现 CUD 操作时记录的保存。虽然这也是一种方式,但就编程而言,设置为自动提交方式为 false 再根据情况决定是否进行提交,这种方式更常用。因为我们可以根据业务情况来决定提交是否进行提交。
4.小结
- MyBatis的事务使用的是JDBC事务策略.
- 通过设置autoCommit()去控制的
- 默认情况下, MyBatis使用的时候 就把autoCommit(false)
- 也就是意味着, 我们要进行增删改的时候, 需要手动的commit
- 后面做项目, 工作里面的事务管理, 基本上都是交给Spring管理. 所以此章节只做了解
第三章-Mybatis 的动态SQL【重点】
Mybatis 的映射文件中,前面我们的 SQL 都是比较简单的,有些时候业务逻辑复杂时,我们的 SQL是动态变化的,此时在前面的学习中我们的 SQL 就不能满足要求了。
知识点-动态 SQL 之if标签 【重点】
1.目标
- 根据一个对象去查询数据库的数据,这个对象里面的属性可有可无,比如:
a. 如果对象的id属性值不为空,即表示要按照id来查询用户
b. 如果对象的username属性不为空,即表示要按照username来查询用户
c. 如果对象的id属性和username 都不为空,即表示要按照id和username来查询用户
d. 如果id属性和username 都为空, 即表示查询所有的用户
List<User> findUser(User user);
- 应用场景:
一般在分页展示效果的时候,有过滤条件!
2.讲解
- UserDao.java
package com.itheima.dao;
import com.itheima.bean.User;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface UserDao {
/**
* 根据用户对象里面的属性来查询用户: id & username
* @param user
* @return
*/
List<User> findUser(User user);
}
- UserDao.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.UserDao">
<!--* 根据一个对象去查询数据库的数据,这个对象里面的属性可有可无,比如:
a. 如果对象的uid属性值不为空,即表示要按照uid来查询用户
b. 如果对象的username属性不为空,即表示要按照username来查询用户
c. 如果对象的uid属性和username 都不为空,即表示要按照uid和username来查询用户和username 都为空, 即表示查询所有的用户-->
<select id="findUser" parameterType="user" resultType="user">
<!-- 这里写where 1=1 主要是为了让where关键字在外面的语句上,先扎根,后面的拼接
就不用在去向这个where的问题了。之所以写1=1 主要是考虑这个条件是恒成立的条件。
当然可以写2=2 或者 3=3 -->
select * from t_user where 1=1
<!--
1. 判定uid值是否 > 0 ,如果 > 0,就追加id的条件
1.1 在test属性里面写条件即可。
1.2 在test里面要判断某个属性的值,那么直接写属性即可,不需要添加#{属性}
1.3 在if标签的中间写拼接的sql语句。在中间如果要取属性的值,需要用到 #{属性}
1.4 当test条件的返回值是 true , 那么就会在上面的语句后面拼接if中间的内容
-->
<if test="uid > 0">
and uid = #{uid}
</if>
<!-- 2. 判断username是否有值, 如果有值,就追加username的条件
2.1 一般判定字符串就是判定它不是null,并且它不是空字符串
2.2 如果都不是,那么就拼接SQL语句
2.3 多个条件一起判定,只能写 or 或者 and
-->
<if test="username !=null and username.length > 0">
and username = #{username}
</if>
</select>
</mapper>
- 测试
package com.itheima.test;
import com.itheima.bean.User;
import com.itheima.dao.UserDao;
import com.itheima.utils.SqlSessionFactoryUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.ArrayList;
import java.util.List;
public class TestUserDao {
@Test
public void testFindUser(){
//1. 问工具类要sqlsession
SqlSession session = SqlSessionFactoryUtil.getSession();
//2. 问sqlsession要代理对象
UserDao userDao = session.getMapper(UserDao.class);
//3. 调用方法
User u = new User();
//u.setUid(1);
//u.setUsername("ls");
List<User> list = userDao.findUser(u);
System.out.println("list = " + list);
//4. 收尾
}
}
3.小结
- if适合动态多条件查询
- 注意 if 里面的test属性不能写 #{}
知识点-动态 SQL 之where标签【重点】
1.目标
为了简化上面 where 1=1 的条件拼装,我们可以采用
2.讲解
修改 UserDao.xml 映射文件如下:
UserDao.java
package com.itheima.dao;
import com.itheima.bean.User;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface UserDao {
/**
* 根据用户对象里面的属性来查询用户: id & username
* @param user
* @return
*/
List<User> findUser2(User user);
}
UserDao.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.UserDao">
<!--where标签:
作用:
1. 为了顶替上面的where 1=1 ,它会做判断,当我们里面的条件成立之后,就会拼接上where关键字
如果没有成立,那么就不会拼接where关键字。
2. 它会自动的处理掉第一个and关键字,所以即是第一个if判断里面有and 也不用担心。-->
<select id="findUser2" parameterType="user" resultType="user">
select * from t_user
<where>
<if test="uid > 0">
and uid = #{uid}
</if>
<if test="username !=null and username.length > 0">
and username = #{username}
</if>
</where>
</select>
</mapper>
注意:
可以自动处理第一个 and
3.小结
- where标签用在自己写sql语句的时候 where关键字不好处理的情况,代替where 1 = 1
可以自动处理第一个 and , 建议全部加上and
知识点-动态SQL之foreach标签 【了解】
1.目标
2.讲解
2.1需求一
- 传入多个 id(个数不确定)查询用户信息,用下边sql 实现:
select * from t_user WHERE uid =1 OR uid =2 OR uid=6
这样我们在进行范围查询时,就要将一个集合中的值,作为参数动态添加进来。这样我们将如何进行参数的传递?
- UserDao.java
package com.itheima.dao;
import com.itheima.bean.User;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface UserDao {
/**
* 根据集合中的id,把用户给查询出来。
* @param ids 集合中的id个数不确定
* @return
*/
List<User> findUser3(@Param("ids") List<Integer> ids);
}
- UserDao.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.UserDao">
<!--根据集合中的id个数来查询用户,
1. 需要对id的集合进行遍历。如果有id值,就追加条件查询
2. 如果集合为空对象,或者集合的元素个数为0,那么就不用追加条件,表示查询所有用户-->
<select id="findUser3" parameterType="list" resultType="user">
select * from t_user
<where>
<!--1. 当集合不为null 并且集合的大小 > 0 才去做遍历操作-->
<if test="ids != null and ids.size > 0">
<!--collection : 遍历的集合是谁 ids = [1,2,6]
item : 遍历出来之后,用什么名字来接收这个值。
open : 还没开始遍历,就往sql语句里面追加什么内容
foreach标签中间内容: 遍历一次之后,就追加标签中间的内容到sql语句
separator : 住家完毕中间的内容之后,再追加这个separator ,即表示每次遍历的分隔内容是什么
close : 遍历结束之后,往sql语句追加什么内容
拼接的顺序: open === #{id} ==== separator === #{id} === separator #{id} ...=== close
-->
<foreach collection="ids" item="id" open="uid =" separator="OR uid =" close=";">
#{id}
</foreach>
</if>
</where>
</select>
</mapper>
- 测试
package com.itheima.test;
import com.itheima.bean.User;
import com.itheima.dao.UserDao;
import com.itheima.utils.SqlSessionFactoryUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.ArrayList;
import java.util.List;
public class TestUserDao {
@Test
public void testFindUser3(){
//1. 问工具类要sqlsession
SqlSession session = SqlSessionFactoryUtil.getSession();
//2. 问sqlsession要代理对象
UserDao userDao = session.getMapper(UserDao.class);
//3. 调用方法
List<Integer> ids = new ArrayList<Integer>();
ids.add(1);
ids.add(2);
ids.add(6);
List<User> list = userDao.findUser3(ids);
System.out.println("list = " + list);
//4. 收尾
session.close();
}
}
2.2需求二
- 传入多个 id 查询用户信息,用下边sql 实现:
select * from t_user WHERE uid IN (1,2,5)
- UserDao.java
package com.itheima.dao;
import com.itheima.bean.User;
import org.apache.ibatis.annotations.Param;
import java.util.List;
public interface UserDao {
/**
* 根据集合中的id,把用户给查询出来。
* @param ids 集合中的id个数不确定
* @return
*/
List<User> findUser4(@Param("ids") List<Integer> ids);
}
- UserDao.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.UserDao">
<select id="findUser4" parameterType="list" resultType="user">
select * from t_user
<where>
<if test="ids != null and ids.size > 0">
<foreach collection="ids" item="id" open="uid in (" separator="," close=")">
#{id}
</foreach>
</if>
</where>
</select>
</mapper>
3.小结
foreach标签用于遍历集合,它的属性:
- collection:代表要遍历的集合元素,注意编写时不要写#{}
- open:代表语句的开始部分(一直到动态的值之前)
- close:代表语句结束部分
- item:代表遍历集合的每个元素,生成的变量名(随便取)
- sperator:代表分隔符 (动态值之间的分割)

知识点-SQL 片段
1.目标
Sql 中可将重复的 sql 提取出来,使用时用 include 引入进来,最终达到 sql 重用的目的。我们先到 UserDao.xml 文件中使用
2.讲解
- 使用sql标签抽取
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.UserDao">
<!--定义SQL片段-->
<sql id="selectSQL">
select * from t_user
</sql>
...
</mapper>
- 使用include标签引入使用
<select id="findUser4" parameterType="list" resultType="user">
<!-- select * from t_user-->
<!-- 导入sql片段 -->
<include refid="selectSQL"/>
<where>
<if test="ids != null and ids.size > 0">
<foreach collection="ids" item="id" open="uid in (" separator="," close=")">
#{id}
</foreach>
</if>
</where>
</select>
3.小结
- sql标签可以把公共的sql语句进行抽取, 再使用include标签引入. 好处:好维护, 提示效率
第四章-Mybatis 的多表关联查询【重点】
知识点-一(多)对一
1.需求
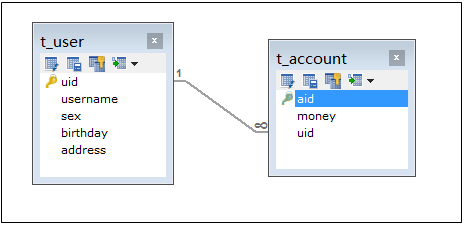
本次案例以简单的用户和账户的模型来分析 Mybatis 多表关系。用户为 User 表,账户为Account 表。一个用户(User)可以有多个账户(Account),但是一个账户(Account)只能属于一个用户(User)。 类比到生活中的: 一个人可以有多张银行卡账户,但是一个银行卡账户只能属于一个人。具体关系如下:
-
需求
查询所有账户信息, 顺便查询出来这个账户所属的用户信息
因为一个账户信息只能供一个用户使用,所以从查询账户信息出发关联查询用户信息为一(多)对一查询。
- 数据库的准备
CREATE TABLE t_account(
aid INT PRIMARY KEY auto_increment,
money DOUBLE,
uid INT
);
ALTER TABLE t_account ADD FOREIGN KEY(uid) REFERENCES t_user(uid);
INSERT INTO `t_account` VALUES (null, '1000', '1');
INSERT INTO `t_account` VALUES (null, '2000', '1');
INSERT INTO `t_account` VALUES (null, '1000', '2');
INSERT INTO `t_account` VALUES (null, '2000', '2');
INSERT INTO `t_account` VALUES (null, '800', '3');
2.分析
- 查询语句
A: 内连接 inner join B : 外连接 outer join
SELECT a.*,u.username,u.address FROM t_account a,t_user u WHERE a.uid = u.uid
3.实现
3.1方式一【不太常用】
上面的sql语句是要查询两张表的,得到的结果必然是两张表的集合(包含了两张表的所有列) ,但是目前没有直接的一个javabean能够包容(包装)多张表的数据。
- Account.java
package com.itheima.bean;
import lombok.Data;
@Data
public class Account {
private int aid;
private double money;
private int uid;
}
-
AccountCustom.java
为了能够封装上面 SQL 语句的查询结果,定义 AccountCustom类中要包含账户信息同时还要包含用户信息,所以我们要在定义 AccountCustom类时可以继承 User类
package com.itheima.bean;
import lombok.Data;
import lombok.ToString;
import java.util.Date;
/*
包含了Account类的属性和User类的属性
1. 由于User的属性比较多,所以在这里选择继承User,这样可以省略很多属性不用写。
2. 由于lombok生成toString默认不会打父类的属性,所以需要我们手动在ToString注解里面
配置callSuper属性,设置为true, 表示要打父类的属性。
*/
@Data
@ToString(callSuper = true)
public class AccountCustom extends User{
private int aid;
private double money;
private int uid;
}
- AccountDao.java
package com.itheima.dao;
import com.itheima.bean.AccountCustom;
import java.util.List;
public interface AccountDao {
/**
* 查询所有的账户信息,并且把该账户所属的用户信息也查询出来
* @return
*/
List<AccountCustom> findAll();
}
- AccountDao.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.AccountDao">
<!--需求:查询所有的账户信息,并且把该账户所属的用户信息也查询出来-->
<select id="findAll" resultType="accountCustom">
select * from t_account a , t_user u where a.uid = u.uid
</select>
</mapper>
- 单元测试
package com.itheima.test;
import com.itheima.bean.AccountCustom;
import com.itheima.dao.AccountDao;
import com.itheima.utils.SqlSessionFactoryUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.List;
public class TestAccountDao {
//查询所有账户
@Test
public void testFindAll(){
SqlSession session = SqlSessionFactoryUtil.getSession();
AccountDao dao = session.getMapper(AccountDao.class);
List<AccountCustom> list = dao.findAll();
System.out.println("list = " + list);
session.close();
}
}
3.2方式二【重点】
刚才方式一、需要创建一个额外的中间JavaBean,来容纳 User类和Account类的属性。如果项目的表很多,那么要创建的中间的javaBean 就很多了。是否可以考虑一种方式,不用创建中间的JavaBean!
-
修改Account02.java
在 Account 类中加入 User类的对象作为 Account 类的一个属性。
package com.itheima.bean;
import lombok.Data;
import java.util.Date;
@Data
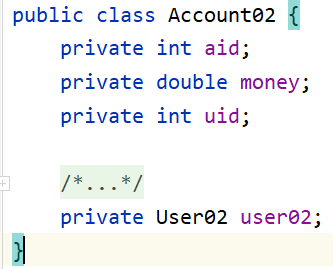
public class Account02 {
private int aid;
private double money;
private int uid;
/*
为了让这个类能够容纳的数据更多,这里可以选择把另一个类的对象属性定义来出来。
以后要想存放|装 user的数据,就可以往这个对象里面装即可。
其实这也就是体现了: 一个账户属于一个用户的关系。
表示一对一的关系,通常都是使用对象来定义!
*/
private User02 user02;
}
- User02.java
package com.itheima.bean;
import lombok.Data;
import java.util.Date;
@Data
public class User02 {
private int uid;
private String username;
private String sex;
private Date birthday;
private String address;
}
- AccountDao02.java
package com.itheima.dao;
import com.itheima.bean.Account02;
import com.itheima.bean.AccountCustom;
import java.util.List;
public interface AccountDao02 {
/**
* 查询所有的账户信息,并且把该账户所属的用户信息也查询出来
* @return
*/
List<Account02> findAll();
}
- AccountDao02.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.AccountDao02">
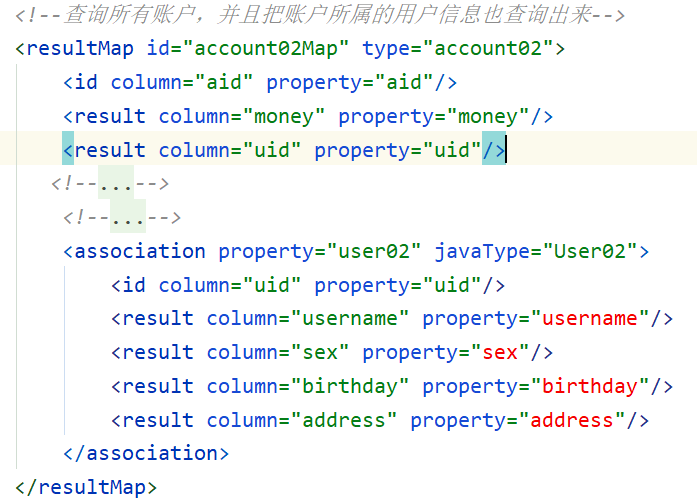
<!--结果映射处理-->
<resultMap id="accountMap" type="account02">
<id property="aid" column="aid"/>
<result property="money" column="money"/>
<result property="uid" column="uid"/>
<!--要想表达出来一个账户属于哪个用户,需要用到一个新的标签:
也就是说,属性是一个对象的时候,现在要告诉mybatis,把什么列的数据,装到这个对象里面的什么属性身上。
association : 通常是用来处理一(多)对一的映射关系
property : 属性的名字,通常是一个对象的属性
javaType : 属性的类型, 可以写别名,也可以写全路径
id和result 就是对这个user02里面的属性进行映射配置
-->
<association property="user02" javaType="user02">
<id property="uid" column="uid"/>
<result property="username" column="username"/>
<result property="sex" column="sex"/>
<result property="birthday" column="birthday"/>
<result property="address" column="address"/>
</association>
</resultMap>
<!--需求:查询所有的账户信息,并且把该账户所属的用户信息也查询出来-->
<select id="findAll" resultMap="accountMap">
select * from t_account a , t_user u where a.uid = u.uid
</select>
</mapper>
- 单元测试
package com.itheima.test;
import com.itheima.bean.Account02;
import com.itheima.bean.AccountCustom;
import com.itheima.dao.AccountDao;
import com.itheima.dao.AccountDao02;
import com.itheima.utils.SqlSessionFactoryUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.List;
public class TestAccountDao02 {
//查询所有账户
@Test
public void testFindAll(){
SqlSession session = SqlSessionFactoryUtil.getSession();
AccountDao02 dao = session.getMapper(AccountDao02.class);
List<Account02> list = dao.findAll();
System.out.println("list = " + list);
session.close();
}
}
4.小结
-
表达关系:
-
实体类里面
-
映射文件
-
知识点-一对多
1.需求
查询所有用户信息及用户关联的账户信息。
2.分析
分析: 用户信息和他的账户信息为一对多关系,并且查询过程中如果用户没有账户信息,此时也要将用户信息查询出来,我们想到了左外连接查询比较合适。
这里不能使用内连接,考察的是两张表必须存在一一对应的关系,才能把这条数据给查询出来。
- 前面的多(一)对一的需求:
需求:查询所有的账户,并且把该账户所属的用户信息给查询出来
sql: 外连接或者内连接都可以。 一定是根据账户的信息能查到这个账户属于谁。不会出现一种情况就是: 有账户但是不知道这个账户属于谁的情况!!!
- 一对多的需求
需求: 查询所有的用户,以及这个用户有哪些账户,都查询出来。
sql : 不能使用内连接了,内连接的核心就是查询出来两张表都有对等关系的记录信息。但是有一种极端的情况: 有的用户可能没有账户。此时就必须使用外连接。其实左外和右外都可以,只是他们的区别就是谁在左边谁在右边而已。
- sql语句
SELECT u.*, a.aid, a.money FROM t_user u LEFT OUTER JOIN t_account a ON u.uid = a.uid
3.实现
- Account03.java
package com.itheima.bean;
import lombok.Data;
@Data
public class Account03 {
private int aid;
private double money;
private int uid;
}
-
User03.java
为了能够让查询的 User 信息中,带有他的个人多个账户信息,我们就需要在 User 类中添加一个集合,
用于存放他的多个账户信息,这样他们之间的关联关系就保存了。
package com.itheima.bean;
import lombok.Data;
import java.util.Date;
import java.util.List;
@Data
public class User03 {
private int uid;
private String username;
private String sex;
private Date birthday;
private String address;
//表示一个用户有多个账户! 通常用集合来表示。
private List<Account03> account03List;
}
- UserDao03.java
package com.itheima.dao;
import com.itheima.bean.User03;
import java.util.List;
public interface UserDao03 {
/**
* 查询所有的用户,并且把这个用户所拥有的账户也查询出来!
* @return
*/
List<User03> findAll();
}
- UserDao03.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.UserDao03">
<resultMap id="user03Map" type="user03">
<id property="uid" column="uid"/>
<result property="username" column="username"/>
<result property="sex" column="sex"/>
<result property="birthday" column="birthday"/>
<result property="address" column="address"/>
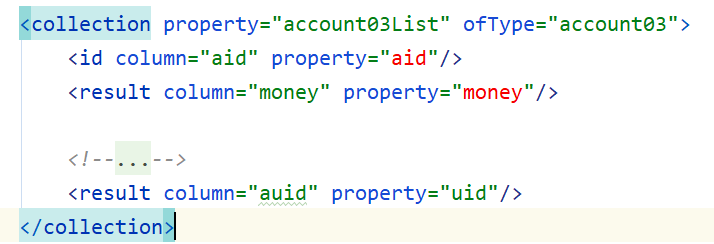
<!--
针对集合属性的映射处理,
collection: 主要是用来处理一对多的映射关系
property : 属性名,就是那个集合属性的名字
ofType : 集合里面的元素的类型,可以写别名,也可以写全路径
id 和 result:就是具体的映射了。
-->
<collection property="account03List" ofType="account03">
<id property="aid" column="aid"/>
<result property="money" column="money"/>
<result property="uid" column="auid"/>
</collection>
</resultMap>
<!--
查询所有的用户,并且把这个用户所拥有的账户也查询出来!
由于用户表里面有一个列叫做: uid
账户表里面也有一个列叫做: uid
当进行多表查询的时候,表的列名有重复的时候,mybatis可能会赋错值,所以需要给
其中一个表的列,起别名。比如下面就是给账户表的uid列起别名为 auid
-->
<select id="findAll" resultMap="user03Map">
select u.* , a.aid , a.money , a.uid auid from t_user u left join t_account a on u.uid = a.uid
</select>
</mapper>
- 单元测试
package com.itheima.test;
import com.itheima.bean.AccountCustom;
import com.itheima.bean.User03;
import com.itheima.dao.AccountDao;
import com.itheima.dao.UserDao03;
import com.itheima.utils.SqlSessionFactoryUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.List;
public class TestUserDao03 {
//查询所有用户
@Test
public void testFindAll(){
SqlSession session = SqlSessionFactoryUtil.getSession();
UserDao03 dao = session.getMapper(UserDao03.class);
List<User03> list = dao.findAll();
System.out.println("list = " + list);
session.close();
}
}
4.小结
- 语句, 建议使用外连接. 用户可以没有账户的, 但是用户信息需要查询出来, 账户的个数就为0
SELECT u.*, a.aid, a.money FROM t_user u LEFT OUTER JOIN t_account a ON u.uid = a.uid
-
表达关系
- 实体类

- 映射文件
-
多表关系下的查询,列名同名的情况
查询A表,关联查询了B表,A表里面和B表里面有一样名字的列。此时查询就会有数据错误的情况,有可能把A表的数据放到了B表对应的bean类身上,也有可能B表的数据放到了A表对应的bean类身上。
知识点-多对多
1. 需求
通过前面的学习,我们使用 Mybatis 实现一对多关系的维护。多对多关系其实我们看成是双向的一对多关系。用户与角色的关系模型就是典型的多对多关系.
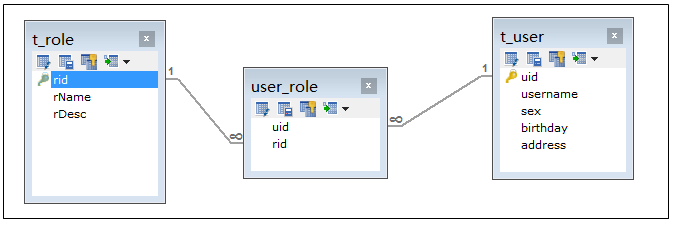
需求:实现查询所有角色对象并且加载它所分配的用户信息。
- 建表语句
CREATE TABLE t_role(
rid INT PRIMARY KEY AUTO_INCREMENT,
rName varchar(40),
rDesc varchar(40)
);
INSERT INTO `t_role` VALUES (null, '校长', '负责学校管理工作');
INSERT INTO `t_role` VALUES (null, '副校长', '协助校长负责学校管理');
INSERT INTO `t_role` VALUES (null, '班主任', '负责班级管理工作');
INSERT INTO `t_role` VALUES (null, '教务处主任', '负责教学管理');
INSERT INTO `t_role` VALUES (null, '班主任组长', '负责班主任小组管理');
-- 中间表(关联表)
CREATE TABLE user_role(
uid INT,
rid INT
);
ALTER TABLE user_role ADD FOREIGN KEY(uid) REFERENCES t_user(uid);
ALTER TABLE user_role ADD FOREIGN KEY(rid) REFERENCES t_role(rid);
INSERT INTO `user_role` VALUES ('1', '1');
INSERT INTO `user_role` VALUES ('3', '3');
INSERT INTO `user_role` VALUES ('2', '3');
INSERT INTO `user_role` VALUES ('2', '5');
INSERT INTO `user_role` VALUES ('3', '4');
2.分析
查询角色我们需要用到 Role 表,但角色分配的用户的信息我们并不能直接找到用户信息,而是要通过中间表(USER_ROLE 表)才能关联到用户信息。
下面是实现的 SQL 语句:
内连接:
SELECT r.*, u.uid, u.username,u.sex,u.birthday,u.address FROM t_role r INNER JOIN user_role ur
ON r.rid = ur.rid INNER JOIN t_user u ON ur.uid = u.uid
或者
SELECT r.*, u.uid, u.username,u.sex,u.birthday,u.address FROM t_role r, user_role ur, t_user u
WHERE r.rid = ur.rid AND ur.uid = u.uid
左外连接:
-- 只要用户的数据和角色表的数据
select r.* , u.* from t_role r left join user_role ur on r.rid = ur.rid
left join t_user u on ur.uid = u.uid
3.实现
- User04.java
package com.itheima.bean;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.util.Date;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class User04 {
private int uid;
private String username;
private String sex;
private Date birthday;
private String address;
}
- Role04.java
package com.itheima.bean;
import lombok.Data;
import java.util.List;
@Data
public class Role04 {
private int rid;
private String rName;
private String rDesc;
//要表示出来一个角色有多少个用户担任:这是一对多的关系。
//因为一个角色可以有多个用户担任
private List<User04> user04List;
}
- RoleDao04.java
package com.itheima.dao;
import com.itheima.bean.Role04;
import com.itheima.bean.User03;
import java.util.List;
public interface RoleDao04 {
/**
* 查询所有的角色,并且把这个角色有哪些用户担任也给查询出来
* @return
*/
List<Role04> findAll();
}
- RoleDao04.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.itheima.dao.RoleDao04">
<!-- 多对多的关系,最终演变的还是要换成一对多来处理-->
<resultMap id="role04Map" type="role04">
<id property="rid" column="rid"/>
<result property="rName" column="rName"/>
<result property="rDesc" column="rDesc"/>
<collection property="user04List" ofType="user04">
<id property="uid" column="uid"/>
<result property="username" column="username"/>
<result property="sex" column="sex"/>
<result property="birthday" column="birthday"/>
<result property="address" column="address"/>
</collection>
</resultMap>
<select id="findAll" resultMap="role04Map">
select * from t_role r left join user_role ur on r.rid = ur.rid left join t_user u on u.uid = ur.uid
</select>
</mapper>
- 单元测试
package com.itheima.test;
import com.itheima.bean.Role04;
import com.itheima.bean.User03;
import com.itheima.dao.RoleDao04;
import com.itheima.dao.UserDao03;
import com.itheima.utils.SqlSessionFactoryUtil;
import org.apache.ibatis.session.SqlSession;
import org.junit.Test;
import java.util.List;
public class TestRoleDao04 {
//查询所有角色
@Test
public void testFindAll(){
SqlSession session = SqlSessionFactoryUtil.getSession();
RoleDao04 dao = session.getMapper(RoleDao04.class);
List<Role04> list = dao.findAll();
System.out.println("list = " + list);
session.close();
}
}
4.小结
-
多对多本质就是两个1对多. 实现起来基本和1对多是一样的
-
表达关系
多表之间,表示关系,都是类里面表示的。
- 实体类

- 映射文件

总结
- 核心配置文件
properties:
1. 导入外部的properties文件
2. 在SqlMapConfig里面,使用${KEY}
typeAlias:
1. 给JavaBean起别名,别名只能在parameterType & resultType
2. 有给单个类起别名,也有给包下的所有列起别名
<typeAlias>
<package name="com.itheima.bean"/>
</typeAlias>
mappers:
1. 用于配置映射文件
1. 可以单个配置,也可以批量配置
<mappers>
<package name="com.itheima.dao"/>
</mappers>
- 动态SQL:
if标签:用来做判断
<if test="id > 0">
and uid = #{id}
</if>
where标签 :用来追加where关键字
<where>
<if test="id > 0">
and uid = #{id}
</if>
</where>
foreach标签【了解】 : 主要是做遍历用的,但是一般我们很少往dao层里面传递集合,
所以这个标签很少会用到
SQL片段:
其实就是抽取xml里面的重复的sql语句
-
多表查询:
一对一:
1. 在JavaBean里面首先表示出来它们的关系,一般是使用对象来表示@Data public class Account{ ... private User user; } 2. 在xml里面使用resultMap 和 association 来处理映射关系 <resultMap id="" type=""> <id></id> <result></result> <association property="user" javaType="user"> <id></id> <result></result>一对多:
1. 在JavaBean里面首先表示出来它们的关系,一般是使用集合来表示 @Data public class User{ ... private List<Account> accountList; } 2. 在xml里面使用resultMap 和 collection 来处理映射关系 <resultMap id="" type=""> <id></id> <result></result> <collection property="user" ofType="user"> <id></id> <result></result>多对多:
其实多对多可以看成是两个一对多,处理办法和一对多是一样的!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号