关键字检索分析-导出到csv,txt或者excel-多文件或文件夹-使用python和asyncio和pandas的dataframe-案例:荷塘月色
-
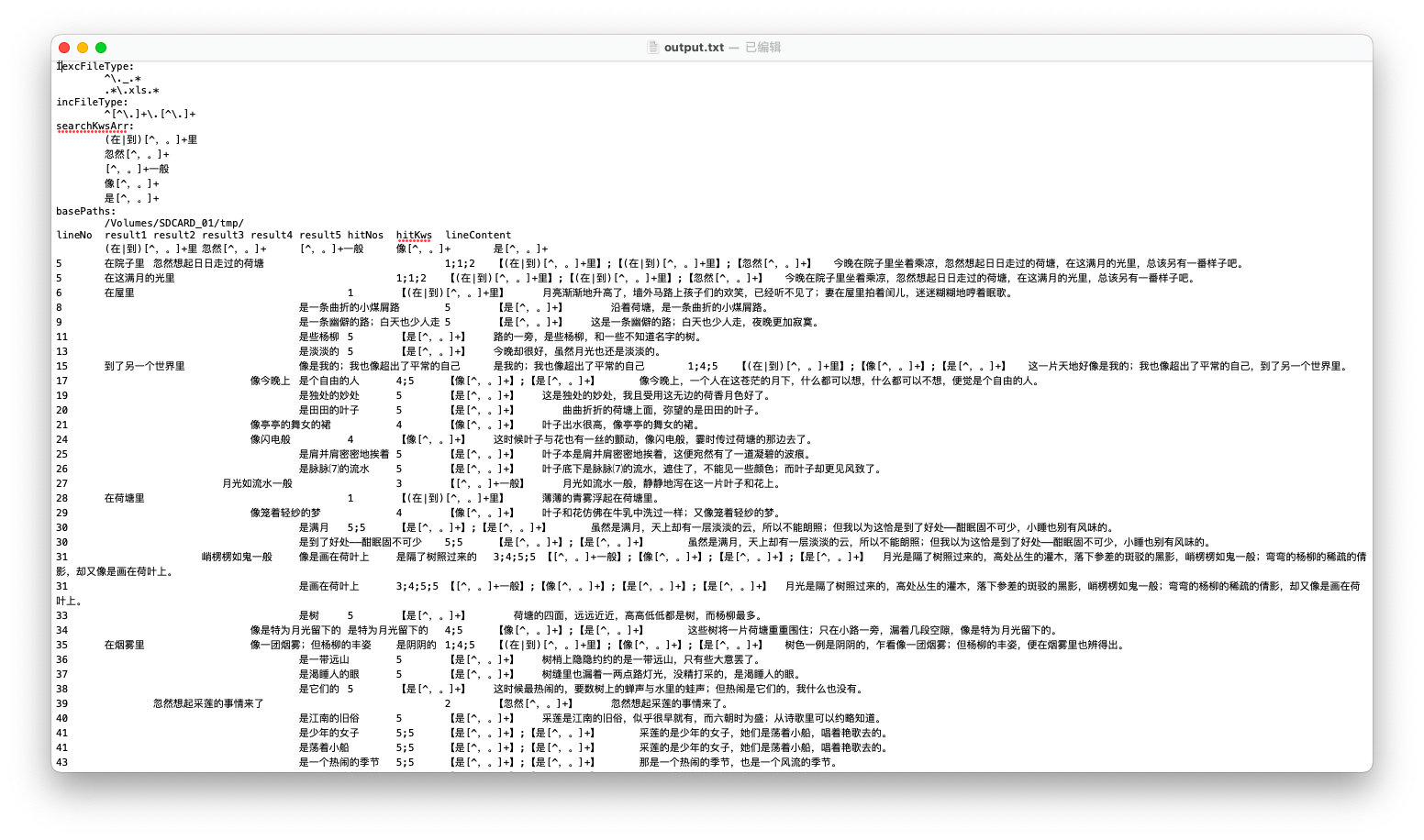
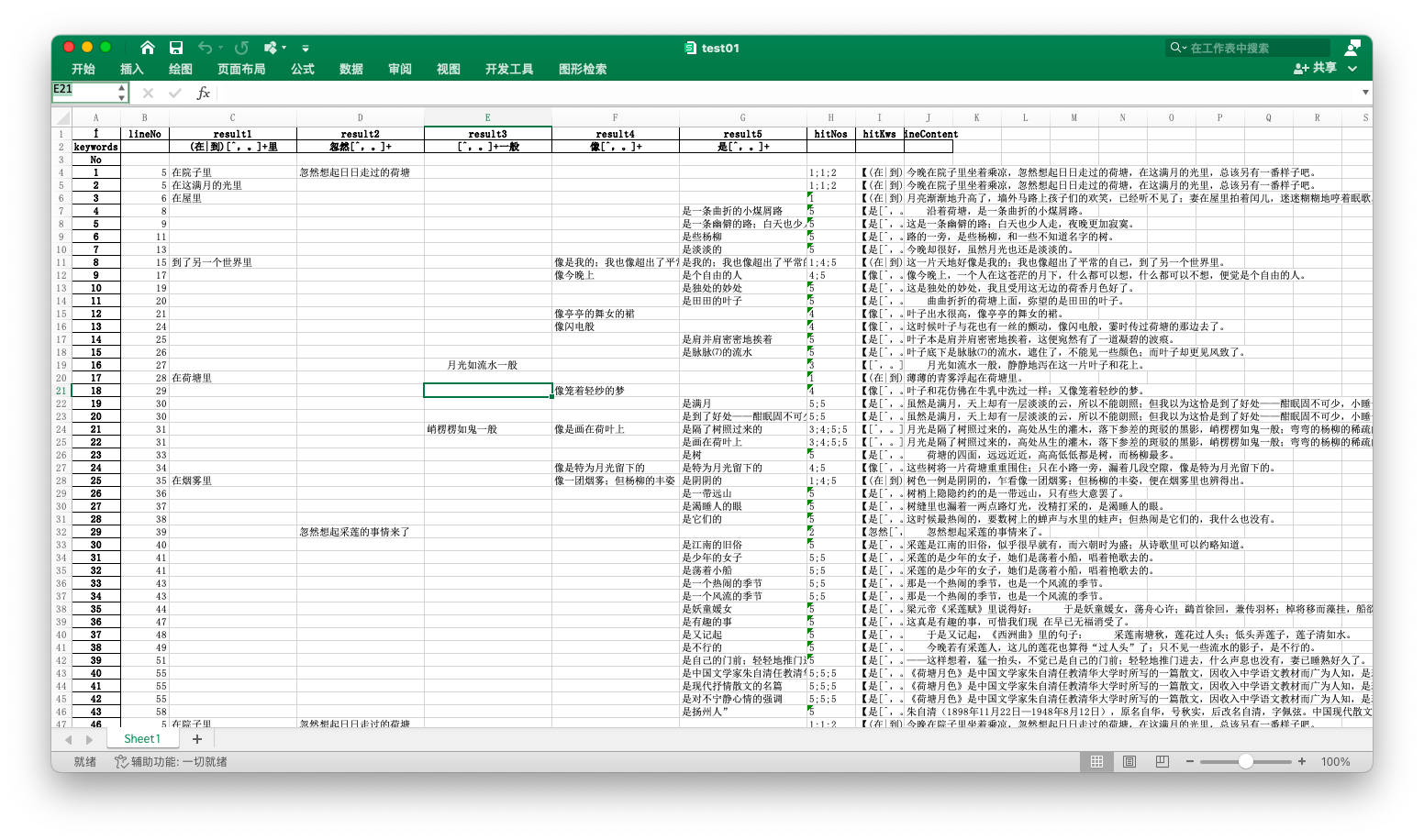
先看看效果图吧
- 荷塘月色,就一篇文章的分析结果
![image]()
![image]()
-
1.02版本
- 把原来的tab一个个拼接成文件输出,改成pandas的dataframe
- 使用asyncio库来使用协程,但是测试下来速度好像是差不多的。可能速度太快了,没能很好的测出来差异。
-
原来的最初的代码是java版本的,现在用python重写一遍
- java版本使用completableFuture来异步IO,主要是文件输出的时候,但是好像文件的顺序并没有发生变化。
- java版本没有使用什么特殊的类和库,结果打印到system.out,可以是控制台,或者是文件
-
代码的功能
- 打印出关键字
- 打印出检索到的文件名,行号,正则表达式命中的结果,多个结果就多行。同一行命中了几个正则表达式。当前行的原来的内容。
- 可以同时检索多个正则表达式
- 对检索的文件路径和文件名也做匹配和排除
- 同一个文件的结果需要在一起,同一行的多次命中也需要在一起
- 检索结果通过tab或者excel表格,每一列展示同一个正则表达式的命中结果
- 原来的java版本,可以设置参数,如果命中,把下一行也返回回来。
-
代码和本地代码的区别
- 路径修改成【您的检索路径】和【您的输出文件】
-
有什么用
- 同时检索多个关键字,能够把命中结果和行原来的内容一起输出到表格中。然后可以进行筛选和分析。这是现有IDE工具没有的定制化的功能
- 检索结果是对代码或者文件这些内容的直观分析,不需要再次打开文件查看和分析。
-
实际使用的案例
- 考试背题库,题解中有官网文档的链接,全部拷贝出来,通过检索【https:/这个url的正则表达式】的关键字,一次性抽取到同一列,然后贴在旁边。这样就可以快速看题解中找到的官网链接了。而且题解很多链接写错的地方,也能发现,调整后把个别错误的也修改好了。
- 而且这个脚本的功能是实际工作经验中,一点点的发现的痛点,然后把工具的功能降到最基础和简单。最一开始是用vba,后来用java,现在再用python。不过确实上述的提起官网链接,这个通过某些IDE的搜索功能也能实现。有一些最新版的IDE也有了更多的功能。但我这个是每天承受巨大压力,实战中得出的功能,和自由定制化。功能又很接地。
-
不能解决的问题
- 如果搜索到的代码,是一个赋值,变量名称不一样。那么需要再次检索,或者把变量名称作为关键字再次加入进来来检索。所以需要代码比较规范,或者变量名称统一。
- 检索中文的时候,没有tokenizer的分词器功能的情况下,那么只是所有一个字,需要把这个字的前一个字和后一个字都检索出来,才能找到完整的结果,比如【知识】和【识别】,那么命中结果会不美观和直接。和AI的word词汇的处理没有什么关系。一开始的初衷是处理代码的。
-
没有上传到github和gitee的原因
- 基本的文本处理工具,很实用,就一段代码
- 比较仓促,容易找不到,可以上传到github,然后把输入的文件,和输出的两种文件也上传,但是这个工具就在于手搓和轻便,有需要的时候,随时加功能
-
源代码
- 草草上传,未做很多修改的版本。后面修改的版本在这里
# %任务,直接转变成 使用dataframe来操作
# % 然后,。。啥,就完成上面这个就行 完成file操作的async
# 打印检索结果的开头和title,条件,限制条件
# 然后提供一个api,自己curl测试一下。
# 然后用docker打包一下。把文件内容传送过去,然后返回处理的结果。
# 然后做一个页面,把内容填写进去,然后点击按钮,另外一边显示出来。
# 做一个备忘录,或者白板功能
# 做一个小程序界面
# 做一个搜索功能,把关键字写进去,然后能够查询出结果
# java也重新写一写
# 3大功能
# 搜索文件夹和文件名称
# (vscode是comman + P)
# 独特功能:可以选择多个文件夹,添加子文件夹排除条件
# 搜索文件内容
# (vscode command + shift + F)
# 独特功能: 可以检索多个正则表达式,然后先匹配上的作为变量向下复制,同一行,或者同文件,
# 但是因为没有结束匹配。所以开头和结尾的地方会出现数据不匹配。如果能添加一个结束匹配的正则表达式。那么默认是文件内作为变量
# 提取表格中的列的内容,然后命中分类
# 独特功能:同一行抽取多个特征,一个正则表达式提取多个token
# 独特功能:多个正则表达式的命中,同时分类
# 同一行多个命中,分成多行。
# 配置常量
import datetime
from datetime import date
from operator import concat
import os
import asyncio
from asyncio import Lock
import pandas as pd
import numpy as np
# from traceback import print_list
# import tornado
# from threading import Thread
import re
# from typing import Concatenate
def getChildFiles(basePath):
return [f for f in os.listdir(basePath) if os.path.isfile(basePath + f)]
def getChildFolders(basePath):
return [f for f in os.listdir(basePath) if os.path.isdir(basePath + f)]
isFirstExcelOutput = True
# mac的设置里面一旦访问过了,就会有允许和不允许,下面的是可移除卷宗,然后网络卷宗现在vscode是没有勾选上
# async def使用方法
# https://superfastpython.com/asyncio-async-def/
# https://docs.python.org/3/library/index.html
# 正则表达式 中文例子 https://www.jb51.net/article/177521.htm
# https://blog.csdn.net/weixin_40907382/article/details/79654372
# 官网 正则表达式 https://docs.python.org/3/library/re.html
async def writeToFile(filout, finalStrArr, lock: Lock, oneFileData: pd.DataFrame):
async with lock:
# for finalStr in finalStrArr:
# filout.wirte(oneFileData.)
# note 输出的是,有的是多个空格的字符
# oneFileData.to_string(filout)
#
# filout.write("\n\n")
# filout.write("".join(finalStrArr))
# 不包含表头,表头已经打印出来了。
oneFileData.to_csv(filout, sep='\t', index=False, header=None)
# 不写到excel文件了。因为excel文件不知道什么位置是文件末尾。没办法append。
# 如果要append,需要用到pd.ExcelWriter mode=append 然后sheet名称,开始的行数是maxrow
file_path = '您的输出文件/output/test01.xlsx'
global isFirstExcelOutput
oneFileData = oneFileData.fillna(" ")
if isFirstExcelOutput:
oneFileData.index.name = "No"
oneFileData.columns.name = "No2" # 这个设置了好像就显示不出来了。
oneFileData.index = oneFileData.index + 1
# oneFileData.rename(columns={"result1":"result1"+"\nresult1_1"}, inplace=True)
multHd = []
multHd.append((t_hitNos,""))
resultNoCnt = 1
for kw in searchKwsArr:
multHd.append((t_result_tmp+str(resultNoCnt),kw))
resultNoCnt+=1
multHd.append((t_hitNos,""))
multHd.append((t_hitKws,""))
multHd.append((t_lineContent,""))
oneFileData.columns = pd.MultiIndex.from_tuples(multHd,names=["titles","keywords"])
# oneFileData.columns = pd.MultiIndex.from_tuples([("lineNo",""),("result1",""),("result2", "result1_1"),("result3",""),("result4",""),("result5",""),("hitNos",""),("hitKws",""),("lineContent","")])
# oneFileData.columns[2] = ("result1",r"(在|到).+里")
oneFileData.to_excel(file_path)
isFirstExcelOutput = False
else:
with pd.ExcelWriter(file_path, mode='a', if_sheet_exists='overlay') as writer:
oneFileData.index = oneFileData.index + 1 - 1 + writer.sheets['Sheet1'].max_row
oneFileData.to_excel(writer, sheet_name='Sheet1', startrow=writer.sheets['Sheet1'].max_row, header=None)
# with pd.ExcelWriter(file_path) as writer:
# oneFileData.to_excel(writer, sheet_name='Sheet1', startrow=writer.sheets['Sheet1'].max_row, header=None)
# oneFileData.to_excel(writer, sheet_name='Sheet1', startrow=writer.sheets['Sheet1'].max_row, index=False, header=None)
# oneFileData.to_excel("您的输出文件output/test01.xlsx")
# print("fileout" + str(datetime.datetime.now()))
# def writeToFile(filout, finalStr):
# filout.write(finalStr)
def multiMatch(content, kwsArr):
for kw in kwsArr:
if re.match(kw, content):
return True
return False
excFileType = [
r"^\._.*",
r".*\.xls.*"
]
incFileType = [
r"^[^\.]+\.[^\.]+"
]
searchKwsArr = [
r"(在|到)[^,。]+里",
r"忽然[^,。]+",
r"[^,。]+一般",
r"像[^,。]+",
r"是[^,。]+"
]
t_lineNo="lineNo"
t_result_tmp="result"
t_hitNos="hitNos"
t_hitKws="hitKws"
t_lineContent="lineContent"
async def searchInFile(f, basePath, filout, lock: Lock):
print("filename: " + f)
# if not re.match(r"^\._.*", f) and not re.match(r".*\.xls.*", f):
if not multiMatch(f,excFileType):
# if not re.match(r"^\.", f):
col_title=[t_lineNo]
resultNoCnt = 1
for kw in searchKwsArr:
col_title.append(t_result_tmp+str(resultNoCnt))
resultNoCnt+=1
# col_title.extend([t_hitNos,t_hitKws,t_lineContent])
col_title.append(t_hitNos)
col_title.append(t_hitKws)
col_title.append(t_lineContent)
with open(basePath + f, "r") as file:
one_file_result = pd.DataFrame(columns=
col_title)
finalStrArr = []
# ["lineNo","result1","result2","result3","result4","result5","hitNos","hitKws","lineContent"])
# one_file_result =
# note 明明可以看到append,但是提示没有这个append,说是一种方法是降低版本,但是因为和很多其他裤捆绑,所以不建议
# pip install pandas==1.3.4
# 大多数还是说用concat来代替
# one_file_result = pd.concat([one_file_result,pd.DataFrame({"lineNo":[5],"result1":["tmp"],"result2":["tmp"],"result3":["tmp"],"result4":["tmp"]
# ,"result5":["tmp"],"hitNos":["tmp"],"hitKws":["tmp"],"lineContent":["tmp"]})], ignore_index=True)
# one_file_result.add(pd.DataFrame({"lineNo":5,"result1":"tmp","result2":"tmp","result3":"tmp","result4":"tmp","result5":"tmp"
# ,"hitNos":"tmp","hitKws":"tmp","lineContent":"tmp"}), ignore_index=True)
# one_file_result = pd.append([one_file_result,pd.DataFrame({"lineNo":5,"result1":"tmp","result2":"tmp","result3":"tmp","result4":"tmp","result5":"tmp"
# ,"hitNos":"tmp","hitKws":"tmp","lineContent":"tmp"})], ignore_index=True)
# print(one_file_result)
linNo = 0
lines = file.readlines()
for line in lines:
linNo += 1
ptStrs = list()
resultPD_key = pd.DataFrame(columns=col_title)
ptStrTmp = str(linNo) + "\t"
resultPD_tmp = pd.DataFrame(columns=col_title)
resultPD_tmp.loc[0,t_lineNo]=linNo
maxFnd = 0
hitKws = []
hitNos = []
kwsSeq = 0
# for pp in [r"https://hXXXXXXXXXXXXXXXXXXl/[0-9]+\.html"]:
# for pp in [r"(在|到).+里", r"忽然[^,。]+", r"[^,。]+一般", r"像[^,。]+", r"是[^,。]+"]:
for pp in searchKwsArr:
kwsSeq = kwsSeq + 1
# for pp in [r".风.", r".香", r"一.", r".{2,4}(地)" , r"荷.", r".塘", r"月.", r".色"]:
lastFnd = "\t"
findCnt = 0
for m in re.finditer(
pp
, line
, flags=re.IGNORECASE):
findCnt += 1
if findCnt > maxFnd:
maxFnd = findCnt
ptStrs.append(ptStrTmp)
resultPD_key = pd.concat([resultPD_key,resultPD_tmp], ignore_index=True)
ptStrs[findCnt-1] = ptStrs[findCnt-1] + pp + ": " + m.group() + "\t"
# resultPD_key.loc[findCnt-1,t_result_tmp+str(kwsSeq)] = pp + ": " + m.group()
resultPD_key.loc[findCnt-1,t_result_tmp+str(kwsSeq)] = m.group()
lastFnd = pp + ": " + m.group() + "\t"
hitNos.append(str(kwsSeq))
hitKws.append(pp)
if False:
ptStrTmp = ptStrTmp + lastFnd
else:
ptStrTmp = ptStrTmp + "\t"
# pd这里单个key搜索就不用填充了
notfnd = 0
for fnd in ptStrs:
notfnd += 1
if notfnd > findCnt:
ptStrs[notfnd-1] = ptStrs[notfnd-1] + "\t"
# 统计一行的命中结果
fndNo = 0
for fnd in ptStrs:
fndNo += 1
ptStrs[fndNo-1] = ptStrs[fndNo-1] + ";"+";".join(hitNos) +";"+ "\t" +";"+ ";".join(hitKws) +";"+ "\t"
# for i in range(0,maxFnd-1):
# 这里是单行搜索,单行的多个结果拼接到一起
if maxFnd > 0:
finalStr = ""
for st in (ptStrs): finalStr = finalStr + st + line # + "\n"
finalStrArr.append(finalStr)
resultPD_key[t_hitNos]=";".join(hitNos)
resultPD_key[t_hitKws]="【"+"】;【".join(hitKws)+"】"
resultPD_key[t_lineContent]=line.replace("\n","").replace("\r","")
one_file_result = pd.concat([one_file_result,resultPD_key], ignore_index=True)
# one_file_result = one_file_result.fillna({t_result_tmp+str(1):"b"})
# writeToFile(filout, finalStr)
# print(one_file_result)
# one_file_result.columns[2].
await asyncio.create_task(writeToFile(filout, finalStrArr, lock, one_file_result))
async def searchInFolder(basePath, filout, lock: Lock):
tasklist = []
for fo in getChildFolders(basePath):
asyncio.create_task(searchInFolder(basePath + fo + "/", filout, lock))
files = getChildFiles(basePath)
for f in files:
tasklist.append(asyncio.create_task(searchInFile(f, basePath, filout, lock)))
# if f
await asyncio.wait(tasklist)
async def main():
lock = Lock()
starttime =datetime.datetime.now()
basePaths = ['/Volumes/XXX/tmp/']
filout = open("/Volumes/XXXXX/output/"+"output.txt","w")
filout.write("excFileType:" + "\n")
filout.write("\t" + "\n\t".join(excFileType) + "\n")
filout.write("incFileType:" + "\n")
filout.write("\t" + "\n\t".join(incFileType) + "\n")
filout.write("searchKwsArr:" + "\n")
filout.write("\t" + "\n\t".join(searchKwsArr) + "\n")
filout.write("basePaths:" + "\n")
filout.write("\t" + "\n\t".join(basePaths) + "\n")
titleStr = "lineNo\t"
titleStrDes = "\t"
resultNo = 1
for kw in searchKwsArr:
titleStr = titleStr + "result" + str(resultNo) + "\t"
titleStrDes = titleStrDes + kw + "\t"
resultNo = resultNo + 1
titleStr = titleStr + "hitNos" + "\t" + "hitKws" + "\t" + "lineContent" + "\t"
filout.write(titleStr + "\n")
filout.write(titleStrDes + "\n")
task_fol_list = []
for basePath in basePaths:
task_fol_list.append(asyncio.create_task(searchInFolder(basePath, filout, lock)))
await asyncio.wait(task_fol_list)
# await coro
print('search complete!')
print("start" + str(starttime))
print("end " + str(datetime.datetime.now()))
# 2024-03-04 21:53:57.998985
# 2024-03-04 21:53:58.041339
# 2024-03-04 22:10:00.298639
# 2024-03-04 22:10:00.443002
# async
# 2024-03-04 21:55:17.430653
# 2024-03-04 21:55:17.490983
# lock
# 2024-03-04 22:07:11.735860
# 2024-03-04 22:07:11.850801
# 2024-03-04 22:11:36.540289
# 2024-03-04 22:11:36.595845
# create task
# start2024-03-04 22:40:18.462565
# end 2024-03-04 22:40:18.653983
if __name__ == "__main__":
# loop = asyncio.get_event_loop()
# result = loop.run_until_complete(main())
asyncio.run(main())
# print(date.ctime())
def foldersSample():
basePath = '您的检索文件夹的路径/'
print("当前目录下的文件夹名称为:", getChildFolders(basePath))
# print("当前目录下的文件夹名称为:", getChildFolders(basePath))
files = getChildFiles(basePath)
print("当前目录下的文件名称为:", getChildFiles(basePath))
# TODO 觉得可以修改一下快捷键 ctrl + K
# TODO 读取文件,按照行读取,哪个好
# TODO 文件名可以先用正则表达式筛选一下。如果是多次匹配来试一下比如a有两个,测试的时候print一下
# foldersSample()
def sample():
pattern = re.compile("(d)[o|a](g)")
matc = pattern.search("abcdogabcdagabc") # Match at index 0
matc = pattern.search("abcdogabcdagabc",3) # Match at index 0
matcs = re.findall(pattern, "abcdogabcdagabc", flags=0)
print(re.findall(re.compile("c(d([o|a])g)"), "abcdogabcdagabc", flags=0))
iter = re.finditer(re.compile("c(d([o|a])g)"), "abcdogabcdagabc", flags=0)
for m in re.finditer(
"c(d([o|a])g)"
, "abcdogabcdagabc"
, flags=re.IGNORECASE):
print(m.group())
for g in m.groups():
print(g)
print(m.span())
# 应该用findall就能满足了。就是没有all的index,
print(re.match(r'l','liuyan1').group())
print(re.match(r'y','liuyan1'))
print(re.search(r'y','liuyan1').groups())
pattern.search("dog", 1) # No match; search doesn't include the "d"
# sample()
# 协程使用方法
# asyncio walkthrough
# https://realpython.com/async-io-python/
# Coroutines and Tasks官网文档
# https://docs.python.org/3/library/asyncio-task.html
# async def main2():
# print('hello')
# await asyncio.sleep(1)
# print('world')
# loop = asyncio.get_event_loop()
# result = loop.run_until_complete(main2())

 浙公网安备 33010602011771号
浙公网安备 33010602011771号