Hadoop综合大作业
Hadoop综合大作业 要求:
1.用Hive对爬虫大作业产生的文本文件(或者英文词频统计下载的英文长篇小说)进行词频统计。
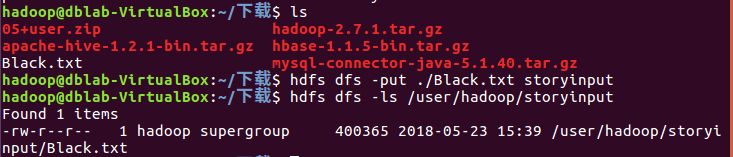
我下载了英文长篇小说《The Souls of Black Folk》,全文69100个单词,下载完更改名字为Black.txt方便操作。
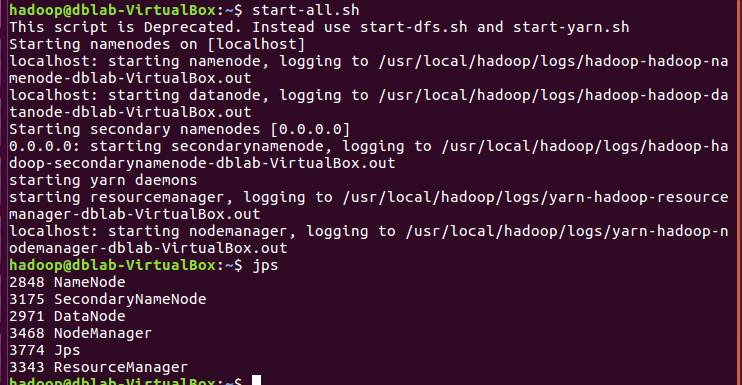
start-all.sh
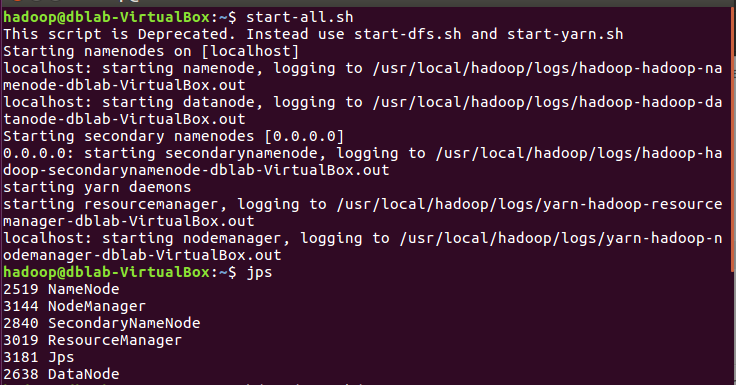
Hdfs上创建文件夹
hdfs dfs -mkdir storyinput hdfs dfs -ls /user/hadoop
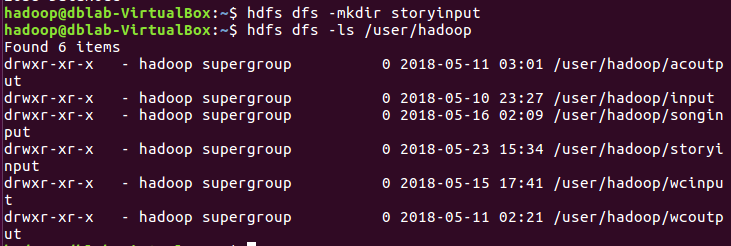
上传文件至hdfs:
下载story.txt保存在~/下载里,查询目录,上传至hdfs
cd ~/下载 ls hdfs dfs -put ./story.txt storyinput hdfs dfs -ls /user/hadoop/storyinput
![]()
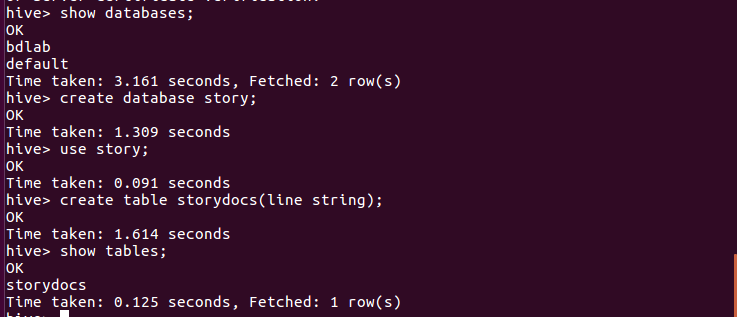
启动Hive
hive

创建数据库story,在数据库里建原始文档表
show databases;
create database story;
use story;
create table storydocs(line string);
show tables;
导入文件内容到表storydocs并查看
load data inpath '/user/hadoop/storyinput/Black.txt' overwrite into table storydocs;
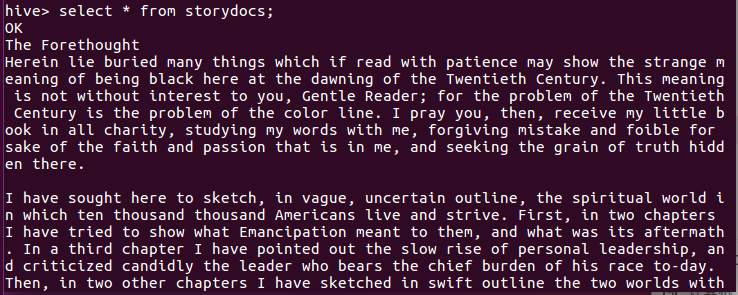
select * from storydocs;


用HQL进行词频统计,结果放在表story_count里
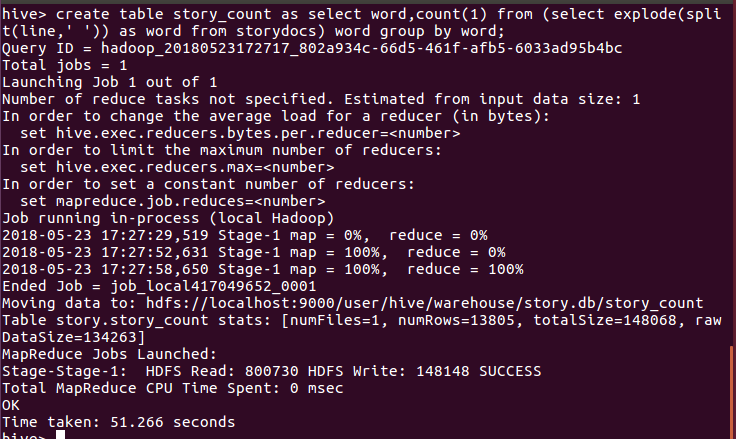
create table story_count as select word,count(1) from (select explode(split(line,' ')) as word from storydocs) word group by word;
查看统计结果
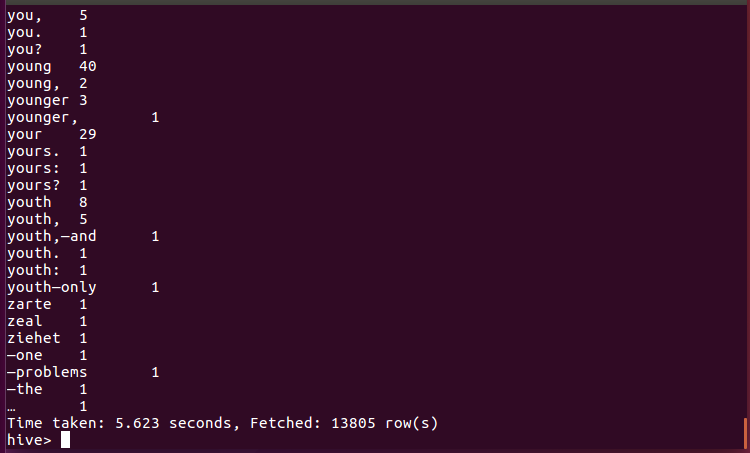
select * from story_count;

2.用Hive对爬虫大作业产生的csv文件进行数据分析,写一篇博客描述你的分析过程和分析结果。
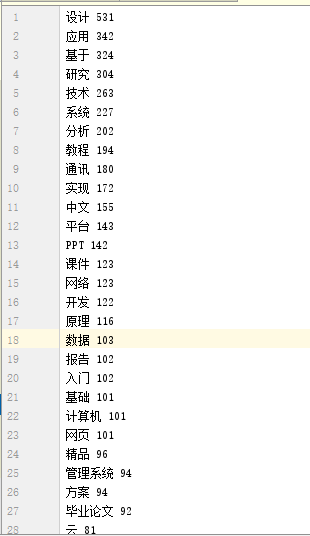
统计豆丁网关于IT计算机题目讨论的主要数据
将文件保存在邮箱,下载到虚拟机中,复制并改为csv模式
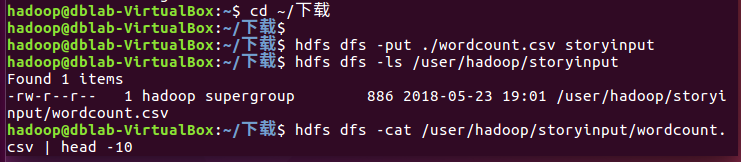
启动hdfs并把wordcount.csv上传到hdfs,并查看前10条数据
cd ~/下载 hdfs dfs -put ./wordcount.csv storyinput hdfs dfs -ls /user/hadoop/storyinput hdfs dfs -cat /user/hadoop/storyinput/wordcount.csv | head -10

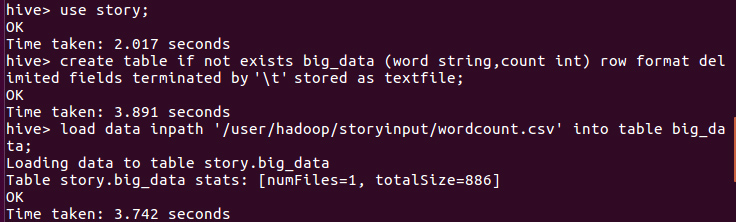
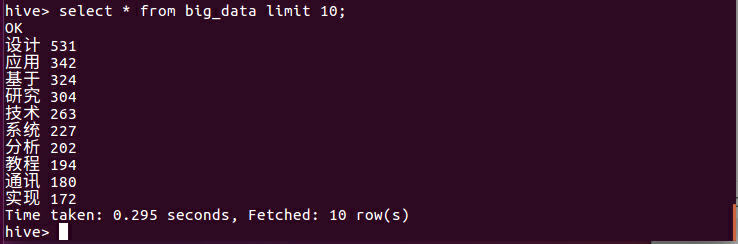
启动hive,进入story数据库,建表格big_data,把wordcount.csv里的数据导进该表并查询前10条记录

 浙公网安备 33010602011771号
浙公网安备 33010602011771号