理解MapReduce计算构架
用Python编写WordCount程序任务
|
程序 |
WordCount |
|
输入 |
一个包含大量单词的文本文件 |
|
输出 |
文件中每个单词及其出现次数(频数),并按照单词字母顺序排序,每个单词和其频数占一行,单词和频数之间有间隔 |
- 编写map函数,reduce函数
cd ~/hadoop mkdir wc cd ~/hadoop/wc gedit mapper.py gedit reducer.py

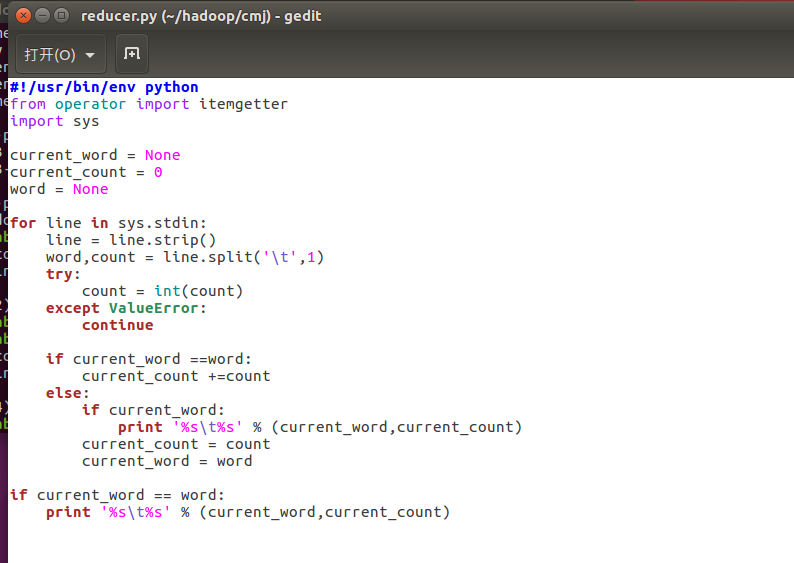
- 将其权限作出相应修改
chmod a+x /home/hadoop/wc/mapper.py chmod a+x /home/hadoop/wc/reducer.py
- 本机上测试运行代码
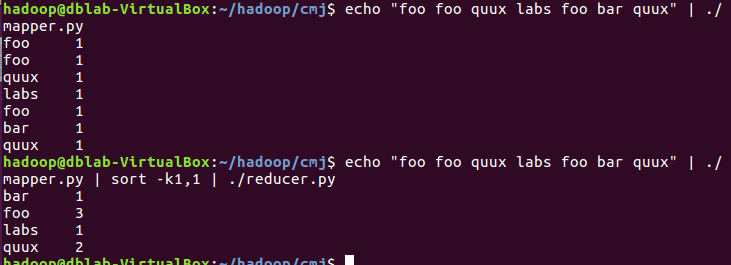
- 放到HDFS上运行,下载并上传文件到hdfs上
cd ~/hadoop/wc wget http://www.gutenberg.org/files/5000/5000-8.txt wget http://www.gutenberg.org/cache/epub/20417/pg20417.txt
- 用Hadoop Streaming命令提交任务
1.找到Streaming的Jar包,配置默认环境变量

gedit ~/.bashrc

2.让配置生效并测试

3.建立一个shell名称为run.sh来运行:
gedit run.sh

4.让配置生效
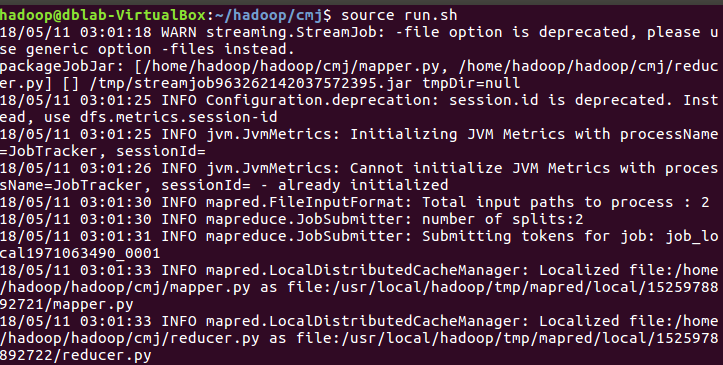
5.查看wcoutput内容


6.结果
![]()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号