使用正则表达式,取得点击次数,函数抽离
学会使用正则表达式
1. 用正则表达式判定邮箱是否输入正确。
r = '^(\w)+(\.\w+)*@(\w)+((\.\w{2,3}){1,3})$'
e = '853585243@qq.com'
if re.match(r,e):
print(re.match(r,e).group(0))
else:
print("error!")
对: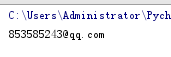 错:
错:
2. 用正则表达式识别出全部电话号码。
str = '''版权所有:广州商学院 地址:广州市黄埔区九龙大道206号
学校办公室:020-82876130 招生电话:020-82872773
粤公网安备 44011602000060号 粤ICP备15103669号'''
li = re.findall('(\d{3,4})-(\d{6,8})',str)
print(li)

3. 用正则表达式进行英文分词。re.split('',news)
news = '''April 5th is the Tomb-sweeping Day in China this year, which is one of the most important traditional festivals. The young people will come back home and sweep tomb with their parents. '''
newscount = re.split('[\s,.?-]+',news)
print(newscount)
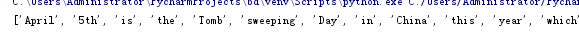
4. 使用正则表达式取得新闻编号
newsUrl = 'http://news.gzcc.cn/html/2017/xiaoyuanxinwen_0925/8249.html'
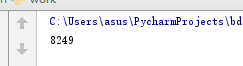
b = re.search('\_(.*).html',newsUrl).group(1).split('/')[-1]
print(b)
5. 生成点击次数的Request URL
newsId = re.search('\_(.*).html',newsUrl).group(1).split('/')[-1]
res = 'http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newsId)
print(res)

6. 获取点击次数
res = requests.get('http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80')
count = res.text.split(".html")[-1].lstrip("(')").rstrip("');")
print(count)

7. 将456步骤定义成一个函数 def getClickCount(newsUrl):
def getClickCount(newUrl):
newsId = re.search('\_(.*).html',newsUrl).group(1).split('/')[-1]
res = requests.get('http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(newsId))
return (int(res.text.split('.html')[-1].lstrip("('").rstrip("');")))
8. 将获取新闻详情的代码定义成一个函数 def getNewDetail(newsUrl):
defgetNewDetail(newsUrl):
ress=requests.get(newsUrl) ress.encoding = 'utf-8' soups = BeautifulSoup(ress.text, 'html.parser') title = soups.select('.show-title')[0].text # 标题 info = soups.select('.show-info')[0].text #连接 dt = datetime.strptime(info.lstrip('发布时间:')[:19], '%Y-%m-%d %H:%M:%S') #发布时间 if info.find('来源:')>0: source=info[info.find('来源:'):].split()[0].lstrip('来源:') else: source='none' # content=soup.select(".show-content")[0].text.strip() click=getClickCount(newsUrl) print(dt, title, newsUrl, source, click)res=requests.get('http://news.gzcc.cn/html/xiaoyuanxinwen/')res.encoding = 'utf-8'soup = BeautifulSoup(res.text, 'html.parser')for news in soup.select('li'): if len(news.select('.news-list-title')) > 0: ness=news.select('a')[0].attrs['href']#继续 getNewDetail(ness)9. 取出一个新闻列表页的全部新闻 包装成函数def getListPage(pageUrl):
pageUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/'
def getListPage(pageUrl): res2=requests.get(pageUrl) res2.encoding='utf-8' soup2=BeautifulSoup(res2.text,'html.parser') for news in soup2.select('li'): if len(news.select('.news-list-title')) > 0: newsUrl=news.select('a')[0].attrs['href']#继续 getNewDetail(newsUrl)10. 获取总的新闻篇数,算出新闻总页数包装成函数def getPageN():
def getPageN(): #新闻列表页的总页数
res = requests.get("http://news.gzcc.cn/html/xiaoyuanxinwen/")
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
n = int(soup.select('.a1')[0].text.rstrip('条'))
return (n // 10 + 1)
11. 获取全部新闻列表页的全部新闻详情。
x=getPageN()
for i in range(1,x+1):
listPageUrl='http://news.gzcc.cn/html/xiaoyuanxinwen/{}.html'.format(i)
getListPage(listPageUrl)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号