词法分析实验报告
实验一、词法分析实验
专业:商业软件工程 姓名:陈蔓嘉 学号:201506110245
一、 实验目的
编制一个词法分析程序。
二、 实验内容和要求
输入:源程序字符串
输出:二元组(种别,单词本身)
内容及要求:
1.对字符串表示的源程序;
2.从左到右进行扫描和分解;
3.根据词法规则;
4.识别出一个一个具有独立意义的单词符号;
5.以供语法分析之用;
6.词法分析程序的功能:
词法分析程序的主要功能是从字符流的程序中识别单词,他主要从左至右逐个字符地扫描源程序,因此他还可以完成其他任务。比如,滤掉源程序中的注释和空白(由空格/控制符或回车换行字符引起的空白);又如,为了使编译程序能将发现的错误信息与源程序的出错位置联系起来,词法分析程序负责记录新读入的字符行的行号,以便行号与出错信息相关联;再如,在支持宏处理功能的源程序中,可以由词法分析程序完成其预处理等。
7.符号与种别码对照表:
|
单词符号 |
种别码 |
单词符号 |
种别码 |
单词符号 |
种别码 |
|
auto |
1 |
short |
21 |
<= |
41 |
|
break |
2 |
signed |
22 |
>= |
42 |
|
case |
3 |
sizeof |
23 |
== |
43 |
|
char |
4 |
static |
24 |
:= |
44 |
|
const |
5 |
struct |
25 |
<> |
45 |
|
continue |
6 |
switch |
26 |
< |
46 |
|
default |
7 |
typedef |
27 |
=> |
47 |
|
do |
8 |
union |
28 |
= |
48 |
|
double |
9 |
unsigned |
29 |
: |
49 |
|
else |
10 |
void |
33 |
+ |
50 |
|
enum |
11 |
include |
34 |
- |
51 |
|
extern |
12 |
stdio |
35 |
* |
52 |
|
float |
13 |
string |
36 |
/ |
53 |
|
for |
14 |
main |
37 |
( |
54 |
|
goto |
15 |
stdlib |
38 |
) |
55 |
|
if |
16 |
d(number) |
40 |
{ |
56 |
|
int 17 |
17 |
l(qita) |
100 |
} |
57 |
|
long |
18 |
|
|
; |
58 |
|
register |
19 |
|
|
. |
59 |
|
return |
20 |
|
|
|
|
8.用文法描述词法规则:
- <字母> →l
- <数字> →d
- <整数常数> →d|d<整数常数>
- <标识符> →l|l〈字母数字〉
- <关键字>→l|l〈字母数字〉
- <运算符> →+|-|*|/|=|〈〈等号〉|〉〈等号〉……
- <界符> →,|;|(|)|……
其中l表示a~z中的任一英文字母,d表示0~9中的任一数字。
三、 实验方法、步骤及结果测试
实验方法:
- 1. 源程序名:压缩包文件(rar或zip)
- 2. 源程序名:词法分析程序.c
![]() 词法分析程序.c
词法分析程序.c1 #include<stdio.h> 2 #include<string.h> 3 #include<stdlib.h> 4 char TOken[10];//分开进行比较 5 char ch; 6 char r1[]={"begin"}; 7 char r2[]={"if"}; 8 char r3[]={"then"}; 9 char r4[]={"while"}; 10 char r5[]={"do"}; 11 char r6[]={"end"}; 12 char r7[]={"break"}; 13 char r8[]={"case"}; 14 char r9[]={"main"}; 15 char r10[]={"l(l|d)*"}; 16 char r11[]={"dd*"}; 17 char r12[]={"="}; 18 char r13[]={"+"}; 19 char r14[]={"-"}; 20 char r15[]={"*"}; 21 char r16[]={"/"}; 22 char r17[]={":"}; 23 char r18[]={"{"}; 24 char r19[]={"}"}; 25 char r20[]={"<"}; 26 char r21[]={"!="}; 27 char r22[]={"<="}; 28 char r23[]={">"}; 29 char r24[]={">="}; 30 char r25[]={"=="}; 31 char r26[]={"("}; 32 char r27[]={")"}; 33 char r28[]={"="}; 34 char r29[]={"--"}; 35 char r30[]={"++"}; 36 char r31[]={"!"}; 37 char r32[]={":="}; 38 char r33[]={";"}; 39 char r34[]={"."}; 40 char A[10000];//输入的所有值 41 int syn,row; 42 int n,m,p,sum,j; 43 static int i = 0; 44 void scaner(); 45 int main() 46 { 47 row = 0 ; 48 p = 0 ; 49 printf("符号与种别码对照表如下:\n"); 50 printf(" 单词符号 种别码 单词符号 种别码\n"); 51 printf(" begin 1 : 17\n"); 52 printf(" if 2 { 18\n"); 53 printf(" then 3 } 19\n"); 54 printf(" while 4 < 20\n"); 55 printf(" do 5 != 21\n"); 56 printf(" end 6 <= 22\n"); 57 printf(" break 7 > 23\n"); 58 printf(" case 8 >= 24\n"); 59 printf(" main 9 == 25\n"); 60 printf(" l(l|d)* 10 ( 26\n"); 61 printf(" dd* 11 ) 27\n"); 62 printf(" = 12 = 28\n"); 63 printf(" + 13 -- 29\n"); 64 printf(" - 14 ++ 30\n"); 65 printf(" * 15 ! 31\n"); 66 printf(" / 16 := 32\n"); 67 printf(" @ 0 ; 33\n\n"); 68 printf(" 请输入您想转换的语句(输入@结束):\n"); 69 do{ 70 scanf("%c",&ch); 71 A[p]=ch; 72 p++; 73 }while(ch!='@');/*将输入的语句分别存入数组A[]中,@出现时结束语句*/ 74 do 75 { 76 scaner();//进入函数进行判定 77 switch(syn) 78 { 79 case 11: printf("(%d,%d)\n",syn,sum); break;//如果是11,那么就是数字 80 case -2: row=row++;break; 81 default: printf("(%d,%s)\n",syn,TOken);break;//否则,就是变量名、关键词 82 } 83 }while (syn!=0); 84 85 } 86 void scaner()/*分别对标示符、数字、符号进行分析*/ 87 { 88 for(n=0;n<5;n++) 89 TOken[n]=0;/*每次循环完就清零*/ 90 ch=A[i]; 91 while(ch==' '||ch=='\n')/*如果字符是空格或者回车,跳过*/ 92 { 93 i++; 94 ch=A[i]; 95 } 96 if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')) /*如果是标示符或者变量名,循环寻找*/ 97 { 98 m=0; 99 while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))/*找到一个变量名或者关键字,直到遇到空格为止*/ 100 { 101 TOken[m]=ch;m++; 102 i++;ch=A[i]; 103 } 104 TOken[m]='\0';/*将识别出来的字符和已定义的标示符作比较,输出其种别码*/ 105 if(strcmp(TOken,r1)==0){syn=1;} 106 else if(strcmp(TOken,r2)==0){syn=2;} 107 else if(strcmp(TOken,r3)==0){syn=3;} 108 else if(strcmp(TOken,r4)==0){syn=4;} 109 else if(strcmp(TOken,r5)==0){syn=5;} 110 else if(strcmp(TOken,r6)==0){syn=6;} 111 else if(strcmp(TOken,r7)==0){syn=7;} 112 else if(strcmp(TOken,r8)==0){syn=8;} 113 else if(strcmp(TOken,r9)==0){syn=9;} 114 115 else{syn=10;} 116 } 117 else if((ch>='0'&&ch<='9')) //数字 118 { 119 sum=0; 120 while((ch>='0'&&ch<='9')) 121 { 122 sum=sum*10+ch-'0';//显示其对应数字sum 123 i++; 124 ch=A[i]; 125 } 126 syn=11; 127 } 128 else switch(ch) //有两个的字符 129 { 130 case'<':m=0;TOken[m]=ch;m++; 131 i++;ch=A[i]; 132 if(ch=='=') 133 { 134 syn=22;//<= 135 TOken[m]=ch;m++;i++; 136 } 137 else{syn=20;}break;//< 138 139 case'>':m=0;TOken[m]=ch;m++; 140 i++;ch=A[i]; 141 if(ch=='='){ 142 syn=24;//>= 143 TOken[m]=ch;m++;i++; 144 } 145 else{syn=23;}break;//> 146 147 case':':m=0;TOken[m]=ch;m++; 148 i++;ch=A[i]; 149 if(ch=='=') 150 { 151 syn=32;//:= 152 TOken[m]=ch;m++;i++; 153 } 154 else 155 {syn=17;}break;//: 156 157 case'@':syn=0;TOken[0]=ch;i++;break; 158 case'=':syn=12;TOken[0]=ch;i++;break; 159 case'+':syn=13;TOken[0]=ch;i++;break; 160 case'-':syn=14;TOken[0]=ch;i++;break; 161 case'*':syn=15;TOken[0]=ch;i++;break; 162 case'/':syn=16;TOken[0]=ch;i++;break; 163 case'{':syn=18;TOken[0]=ch;i++;break; 164 case'}':syn=19;TOken[0]=ch;i++;break; 165 case'(':syn=26;TOken[0]=ch;i++;break; 166 case')':syn=27;TOken[0]=ch;i++;break; 167 case';':syn=33;TOken[0]=ch;i++;break; 168 case'.':syn=34;TOken[0]=ch;i++;break; 169 case'\n':syn=-2;break; 170 default: syn=-1;break; 171 } 172 }


- 3. 可执行程序名:词法分析程序.exe
- 4. 原理分析及流程图
主要总体设计问题。(包括存储结构,主要算法,关键函数的实现等)
主函数主要算法:
1 do{ 2 3 scanf("%c",&ch); 4 5 A[p]=ch; 6 7 p++; 8 9 }while(ch!='@');/*将输入的语句分别存入数组A[]中,@出现时结束语句*/ 10 11 do 12 13 { 14 15 scaner();//进入函数进行判定 16 17 switch(syn) 18 19 { 20 21 case 11: printf("(%d,%d)\n",syn,sum); break;//如果是11,那么就是数字 22 23 case -2: row=row++;break; 24 25 default: printf("(%d,%s)\n",syn,TOken);break;//否则,就是变量名、关键词 26 27 } 28 29 }while (syn!=0);
流程图:
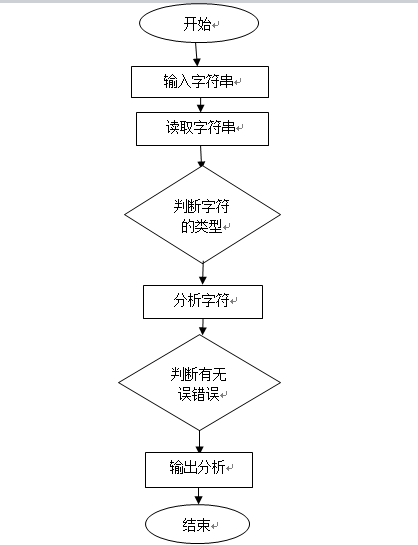
关键函数:
1 void scaner()/*分别对标示符、数字、符号进行分析*/ 2 3 { 4 5 for(n=0;n<5;n++) 6 7 TOken[n]=0;/*每次循环完就清零*/ 8 9 ch=A[i]; 10 11 while(ch==' '||ch=='\n')/*如果字符是空格或者回车,跳过*/ 12 13 { 14 15 i++; 16 17 ch=A[i]; 18 19 } 20 21 if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')) /*如果是标示符或者变量名,循环寻找*/ 22 23 { 24 25 m=0; 26 27 while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))/*找到一个变量名或者关键字,直到遇到空格为止*/ 28 29 { 30 31 TOken[m]=ch;m++; 32 33 i++;ch=A[i]; 34 35 } 36 37 TOken[m]='\0';/*将识别出来的字符和已定义的标示符作比较,输出其种别码*/ 38 39 if(strcmp(TOken,r1)==0){syn=1;} 40 41 else if(strcmp(TOken,r2)==0){syn=2;} 42 43 else if(strcmp(TOken,r3)==0){syn=3;} 44 45 else if(strcmp(TOken,r4)==0){syn=4;} 46 47 else if(strcmp(TOken,r5)==0){syn=5;} 48 49 else if(strcmp(TOken,r6)==0){syn=6;} 50 51 else if(strcmp(TOken,r7)==0){syn=7;} 52 53 else if(strcmp(TOken,r8)==0){syn=8;} 54 55 else if(strcmp(TOken,r9)==0){syn=9;} 56 57 58 59 else{syn=10;}//从for开始到这里结束,是对标示符或者变量名的识别。 60 61 } 62 63 else if((ch>='0'&&ch<='9')) //数字 64 65 { 66 67 sum=0; 68 69 while((ch>='0'&&ch<='9')) 70 71 { 72 73 sum=sum*10+ch-'0';//显示其对应数字sum 74 75 i++; 76 77 ch=A[i]; 78 79 } 80 81 syn=11; 82 83 }//这一段是对数字三识别。 84 85 else switch(ch) //有两个的字符 86 87 { 88 89 case'<':m=0;TOken[m]=ch;m++; 90 91 i++;ch=A[i]; 92 93 if(ch=='=') 94 95 { 96 97 syn=22;//<= 98 99 TOken[m]=ch;m++;i++; 100 101 } 102 103 else{syn=20;}break;//< 104 105 106 107 case'>':m=0;TOken[m]=ch;m++; 108 109 i++;ch=A[i]; 110 111 if(ch=='='){ 112 113 syn=24;//>= 114 115 TOken[m]=ch;m++;i++; 116 117 } 118 119 else{syn=23;}break;//> 120 121 122 123 case':':m=0;TOken[m]=ch;m++; 124 125 i++;ch=A[i]; 126 127 if(ch=='=') 128 129 { 130 131 syn=32;//:= 132 133 TOken[m]=ch;m++;i++; 134 135 } 136 137 else 138 139 {syn=17;}break;//: 140 141 142 143 case'@':syn=0;TOken[0]=ch;i++;break; 144 145 case'=':syn=12;TOken[0]=ch;i++;break; 146 147 case'+':syn=13;TOken[0]=ch;i++;break; 148 149 case'-':syn=14;TOken[0]=ch;i++;break; 150 151 case'*':syn=15;TOken[0]=ch;i++;break; 152 153 case'/':syn=16;TOken[0]=ch;i++;break; 154 155 case'{':syn=18;TOken[0]=ch;i++;break; 156 157 case'}':syn=19;TOken[0]=ch;i++;break; 158 159 case'(':syn=26;TOken[0]=ch;i++;break; 160 161 case')':syn=27;TOken[0]=ch;i++;break; 162 163 case';':syn=33;TOken[0]=ch;i++;break; 164 165 case'.':syn=34;TOken[0]=ch;i++;break; 166 167 case'\n':syn=-2;break; 168 169 default: syn=-1;break; 170 171 }//这一部分是对符号的识别。 172 173 }
关键函数流程图:

- 5. 主要程序段及其解释:
实现主要功能的程序段,重要的是程序的注释解释。
1 void scaner()/*分别对标示符、数字、符号进行分析*/ 2 3 { 4 5 for(n=0;n<7;n++) 6 7 TOken[n]=0;/*每次循环完就清零*/ 8 9 ch=A[i]; 10 11 while(ch==' '||ch=='\n')/*如果字符是空格或者回车,跳过*/ 12 13 { 14 15 i++; 16 17 ch=A[i]; 18 19 } 20 21 if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')) /*如果是标示符或者变量名,循环寻找*/ 22 23 { 24 25 m=0; 26 27 while((ch>='0'&&ch<='9')||(ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z'))/*找到一个变量名或者关键字,直到遇到空格为止*/ 28 29 { 30 31 TOken[m]=ch;m++; 32 33 i++;ch=A[i]; 34 35 } 36 37 TOken[m]='\0';/*将识别出来的字符和已定义的标示符作比较,输出其种别码*/ 38 39 if(strcmp(TOken,r1)==0){syn=1;} 40 41 else if(strcmp(TOken,r2)==0){syn=2;} 42 43 else if(strcmp(TOken,r3)==0){syn=3;} 44 45 else if(strcmp(TOken,r4)==0){syn=4;} 46 47 else if(strcmp(TOken,r5)==0){syn=5;} 48 49 else if(strcmp(TOken,r6)==0){syn=6;} 50 51 else if(strcmp(TOken,r7)==0){syn=7;} 52 53 else if(strcmp(TOken,r8)==0){syn=8;} 54 55 else if(strcmp(TOken,r9)==0){syn=9;} 56 57 58 59 else{syn=10;} 60 61 } 62 63 else if((ch>='0'&&ch<='9')) //数字 64 65 { 66 67 sum=0; 68 69 while((ch>='0'&&ch<='9')) 70 71 { 72 73 sum=sum*10+ch-'0';//显示其对应数字sum 74 75 i++; 76 77 ch=A[i]; 78 79 } 80 81 syn=11; 82 83 } 84 85 else switch(ch) //有两个的字符 86 87 { 88 89 case'<':m=0;TOken[m]=ch;m++; 90 91 i++;ch=A[i]; 92 93 if(ch=='=') 94 95 { 96 97 syn=22;//<= 98 99 TOken[m]=ch;m++;i++; 100 101 } 102 103 else{syn=20;}break;//< 104 105 106 107 case'>':m=0;TOken[m]=ch;m++; 108 109 i++;ch=A[i]; 110 111 if(ch=='='){ 112 113 syn=24;//>= 114 115 TOken[m]=ch;m++;i++; 116 117 } 118 119 else{syn=23;}break;//> 120 121 122 123 case':':m=0;TOken[m]=ch;m++; 124 125 i++;ch=A[i]; 126 127 if(ch=='=') 128 129 { 130 131 syn=32;//:= 132 133 TOken[m]=ch;m++;i++; 134 135 } 136 137 else 138 139 {syn=17;}break;//: 140 141 142 143 case'@':syn=0;TOken[0]=ch;i++;break; 144 145 case'=':syn=12;TOken[0]=ch;i++;break; 146 147 case'+':syn=13;TOken[0]=ch;i++;break; 148 149 case'-':syn=14;TOken[0]=ch;i++;break; 150 151 case'*':syn=15;TOken[0]=ch;i++;break; 152 153 case'/':syn=16;TOken[0]=ch;i++;break; 154 155 case'{':syn=18;TOken[0]=ch;i++;break; 156 157 case'}':syn=19;TOken[0]=ch;i++;break; 158 159 case'(':syn=26;TOken[0]=ch;i++;break; 160 161 case')':syn=27;TOken[0]=ch;i++;break; 162 163 case';':syn=33;TOken[0]=ch;i++;break; 164 165 case'.':syn=34;TOken[0]=ch;i++;break; 166 167 case'\n':syn=-2;break; 168 169 default: syn=-1;break; 170 171 } 172 173 }
- 6. 运行结果及分析
一般必须配运行结果截图,结果是否符合预期及其分析。
(截图需根据实际,截取有代表性的测试例子)


四、 实验总结
心得体会,实验过程的难点问题及其解决的方法。
在写词法分析的过程中,难点问题主要是关键字和变量名的分辨,在循环程序中卡主了,其他问题还好。在分辨期间,我首先让这个词循环,查找,循环完就清零。如果是标示符或者变量名,找到一个变量名或者关键字,直到遇到空格为止,将识别出来的字符和已定义的标示符作比较,输出其种别码。这是我这一实验学到的最大的东西。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号